문제 상황
‘201 CREATED’ 어플리케이션은 스터디원 모집 및 스터디 진행을 돕는 서비스이다.
스터디 진행을 돕는 기능 중 스터디가 현재 몇 주차인지, X요일까지 어떤 과제를 해야 하는지 확인할 수 있는 기능이 있다. 이를 위해서는 매일 변하는 날짜를 어플리케이션의 서버에도 동기화해야 한다.
이 과정에서 매우 많은 양의 쿼리가 실행되는 문제가 있었고, 이를 개선하고자 한다.
도메인 이해
도메인 상에서 최상위 계층에 있는 스터디라는 개념이 있다. 각각의 스터디에는 회차가 존재한다. 회차는 스터디원들이 스터디를 진행하는 날이라고 생각하면 된다. 예시는 다음과 같다.
- A 스터디: 주 3회, 월/수/금 요일
- B 스터디: 주 1회, 화요일
스터디를 진행하면서 회차는 계속해서 쌓일 것이다. 이미 끝난 회차도 중요하지만, 우리 어플리케이션에서는 ‘현재 회차’를 중심으로 사용자에게 기능을 제공한다. 날짜가 변경됨에 따라 회차가 변경되고, 사용자에게 보여지는 ‘현재 회차’도 달라져야 한다.
위의 B 스터디를 예로, 2주차 화요일이 12월 5일이라고 가정하자. 유저는 12월 5일까지 2주차 회차를 진행한다. 그리고 회차를 마치고 12월 6일이 되면, 3주차의 회차를 보게 될 것이다.
우리 팀은 이를 스케줄링으로 구현했다. 매일 자정(00시), 전날에 진행한 회차를 종료 처리하고 새로운 회차를 현재 회차로 업데이트한다.
소스코드 및 구현 내용
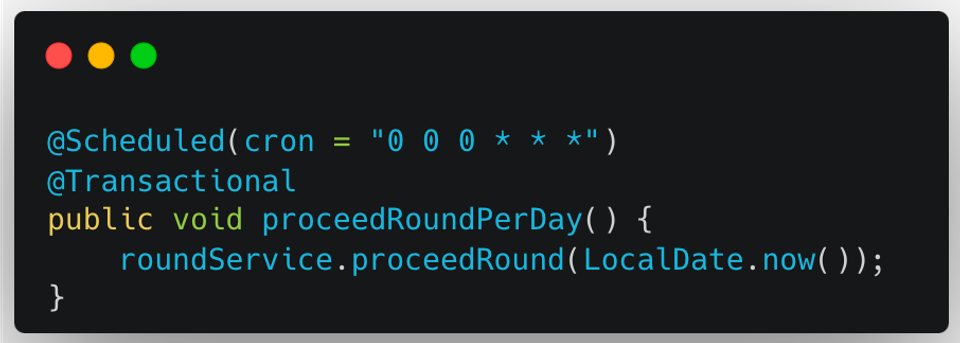
Spring의 @Scheduled 어노테이션을 활용하여 매일 0시 0분 0초에 RoundService.proceedRound() 메서드를 호출한다.
(위에서 설명한 회차를 Round라고 칭한다.)
RoundService.proceedRound()의 구현 내용은 다음과 같다.
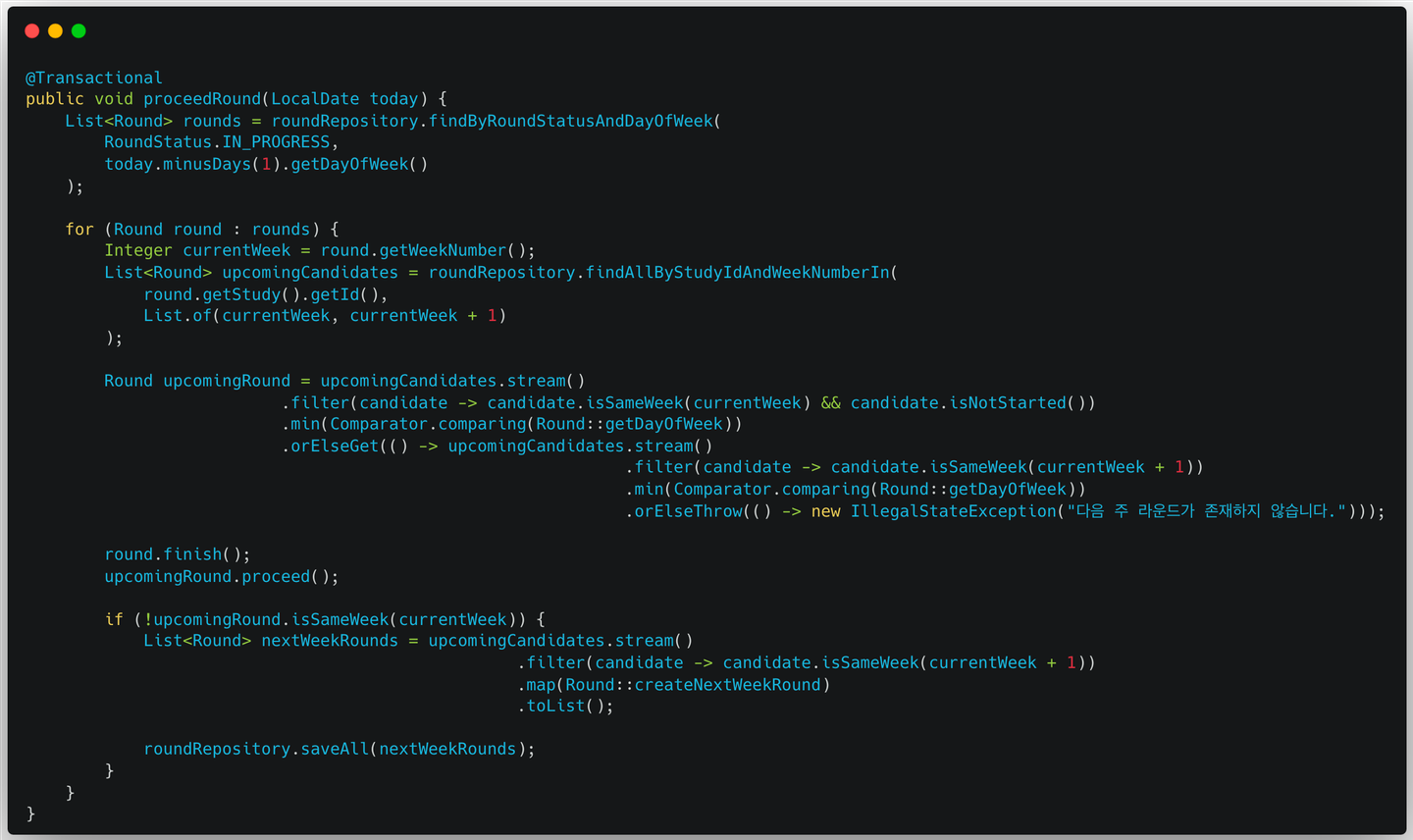
매우 긴 라인의 메서드이다. 이를 보기 쉽게 나눠서 설명하면,

-
현재 진행 중(IN_PROGRESS)이면서, 어제 진행한 Round를 모두 가져온다.
이렇게 찾아온 Round들은 날짜가 변경됨에 따라, 오늘 업데이트해줘야 하는 대상인 것이다.
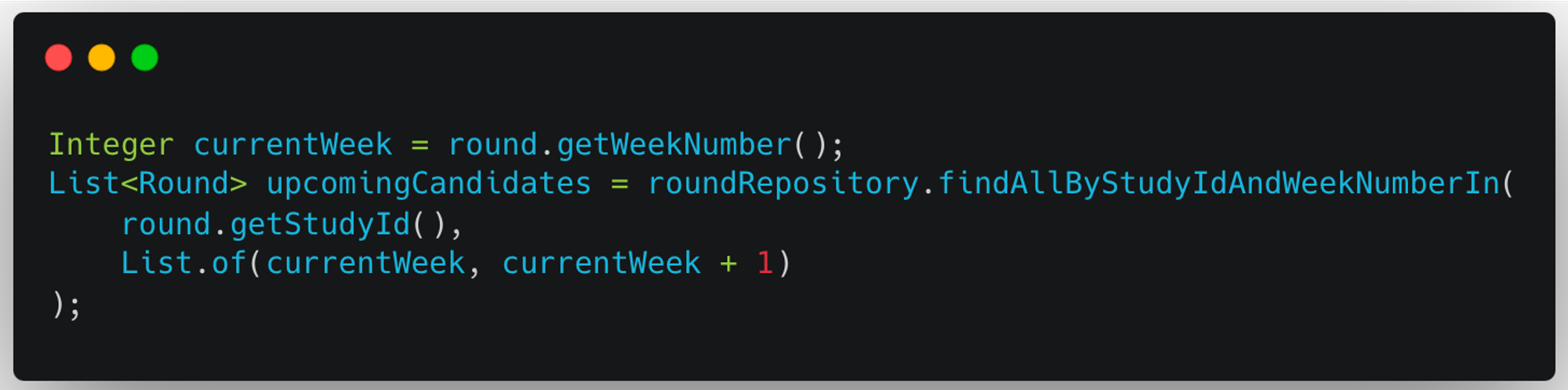
-
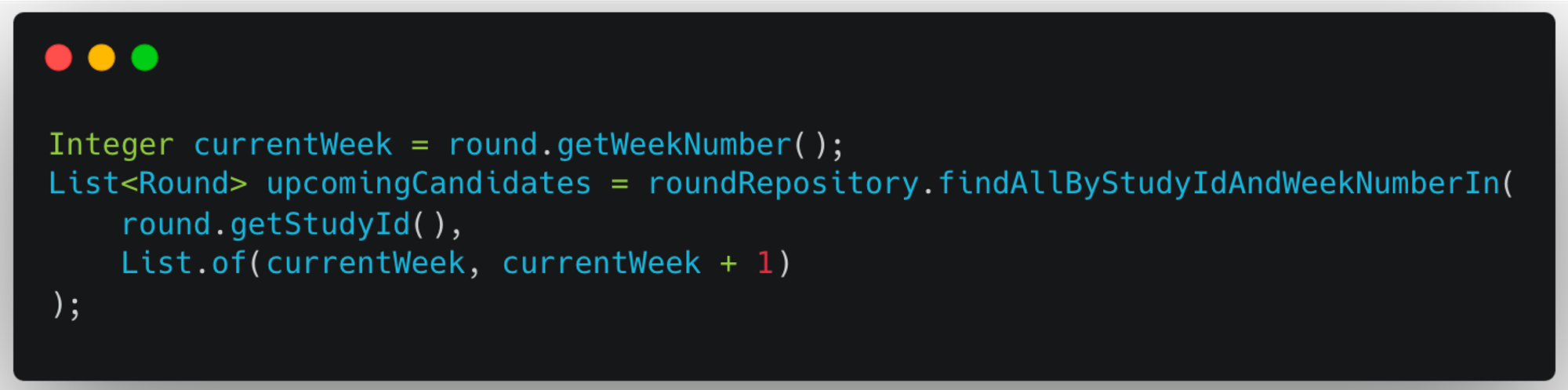
Round가 속해 있는 Study의 Id와 weekNumber를 기반으로 다음 Round가 될 수 있는 후보 Round들을 조회한다.
후보를 조회할 때, 현재 주차와 다음 주차의 Round들을 조회하고 있다. 이는 도메인 규칙에 근거한다.
- 다음 주차까지의 회차만 조회할 수 있다는 규칙
- → 기존에 n주차를 진행하고 있을 때는 n+1주차까지의 회차들이 존재한다.
- 즉, 다음 Round가 될 수 있는 후보는 현재 주차 또는 다음 주차 안에 무조건 속한다.
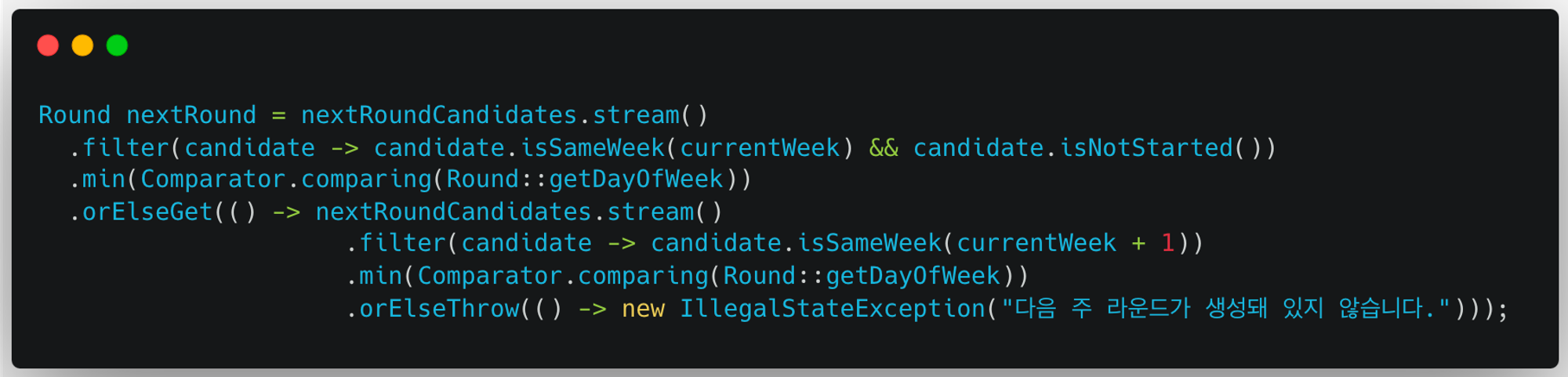
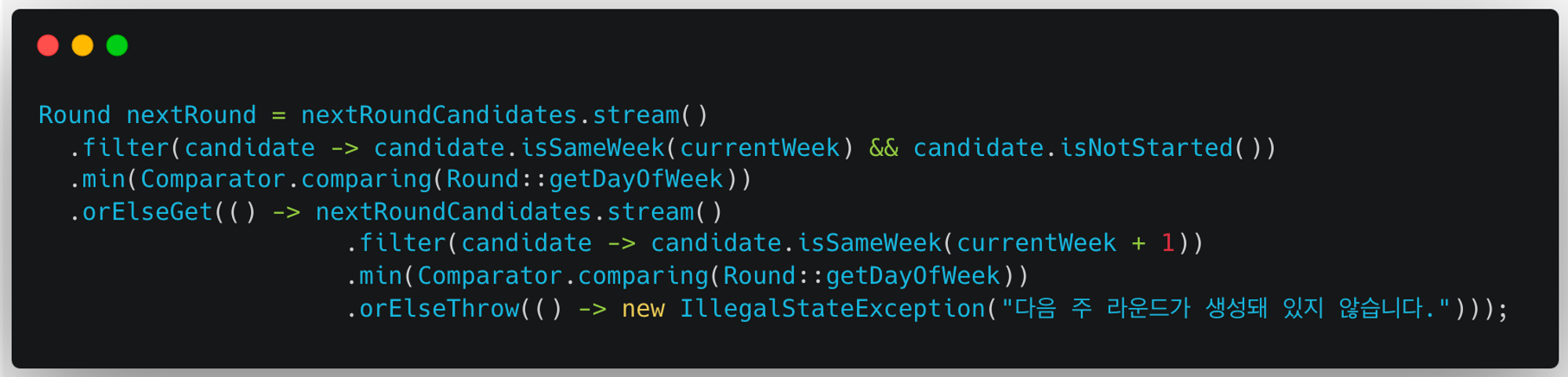
- 후보 Round들 중, 다음 Round가 무엇인지 찾아낸다.
- 현재 주차의 시작되지 않은 Round들을 필터링한다.
- 필터링한 Round들 중, 요일(DayOfWeek)의 값이 가장 작은 Round를 찾는다. 이는 월/수/금 진행하는 스터디의 월요일 Round가 끝났을 때, 다음 Round를 금요일이 아닌 수요일로 설정하기 위함이다.
- (1), (2) 과정을 통해 찾은 Round가 존재하지 않는다면 다음 주차를 기준으로 (1), (2) 과정을 반복한다. 월/수/금 진행하는 스터디의 1주차 금요일 Round가 끝났다면, 2주차 월요일이 다음 Round가 되어야 하기 때문이다.
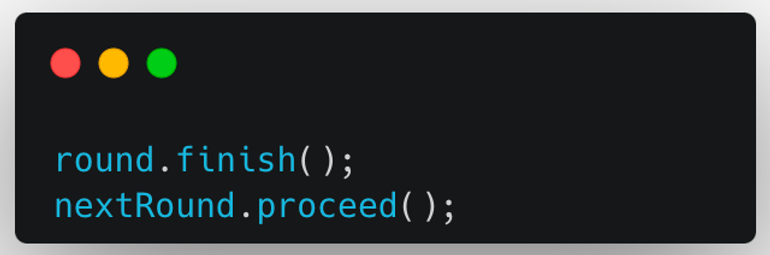
-
기존의 Round를 끝내고, 다음 Round를 진행한다.
이 과정에서 기존의 Round는 상태가 FINISHED로 변경되며, nextRound의 상태는 IN_PROGRESS로 변경된다. 즉, 두 개의 Round 객체에 대해 상태 변경이 발생한다.
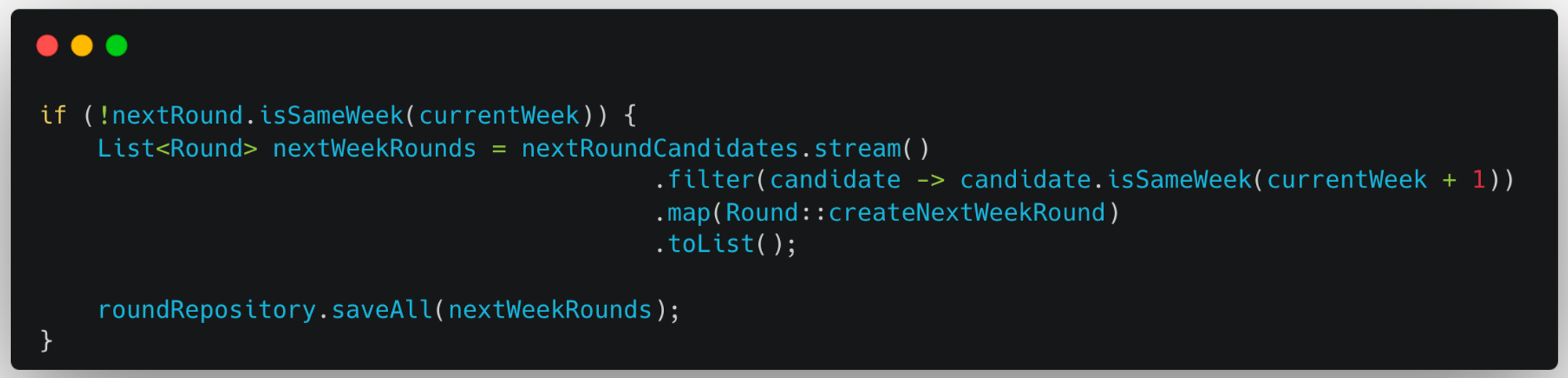
-
다음 Round가 다음 주차에 속해 있다면, 다다음주차의 Round를 모두 생성해서 저장한다.
2번 로직에서 설명한 도메인 규칙에 근거하여, 스터디의 현재 주차가 n+1주차로 넘어가면서 n+2주차의 Round들을 모두 생성하는 과정이다.
여기까지가 Study에 날짜를 반영하는 스케줄링 기능의 기존 코드이다.
이 기능의 흐름을 이해했다면, 여기서 어떤 문제가 발생했는지 살펴보자.
대량의 쿼리 실행
매우 많은 양의 쿼리를 실행하는 문제에 대해서 알아볼 것이다. 이때 쿼리의 수는 우리 어플리케이션에 존재하는 데이터 양에 따라 변경된다.
현재 글에서는 다음과 같은 환경이라고 가정하고 설명하겠다.
- 진행 중인 스터디 100개
- 각 스터디는 주 2회 수/일 요일 진행
- 한 스터디에 6명의 인원이 참여 → StudyMember 6명
- n주차 일요일 → n+1주차 월요일로 날짜가 변경되며 스케줄링 실행
위에서 설명한 1~5번 과정을 기반으로, 각 과정에서의 쿼리 횟수를 정리해보자.

- 현재 진행 중(IN_PROGRESS)이면서, 어제 진행한 Round를 모두 가져온다. → 1회
- Round가 속해 있는 Study와 weekNumber를 기반으로 다음 Round가 될 수 있는 후보 Round들을 조회한다. → 1회
-
후보 Round들 중, 다음 Round가 무엇인지 찾아낸다. → 0회
한 번에 조회해온 후보 Round들을 Stream으로 필터링하기 때문에 쿼리는 발생하지 않는다.
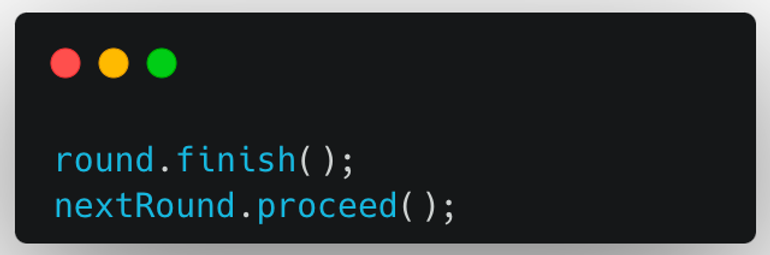
-
기존의 Round를 끝내고, 다음 Round를 진행한다. → 1회
기존 Round의 상태 변화 1회 + 다음 Round의 상태 변화 1회로, 두 번의 update가 이뤄진다.
하지만, JPA의 쓰기 지연 저장소를 통해 Batch Update하므로, 실제로는 1회의 쿼리만 발생한다.
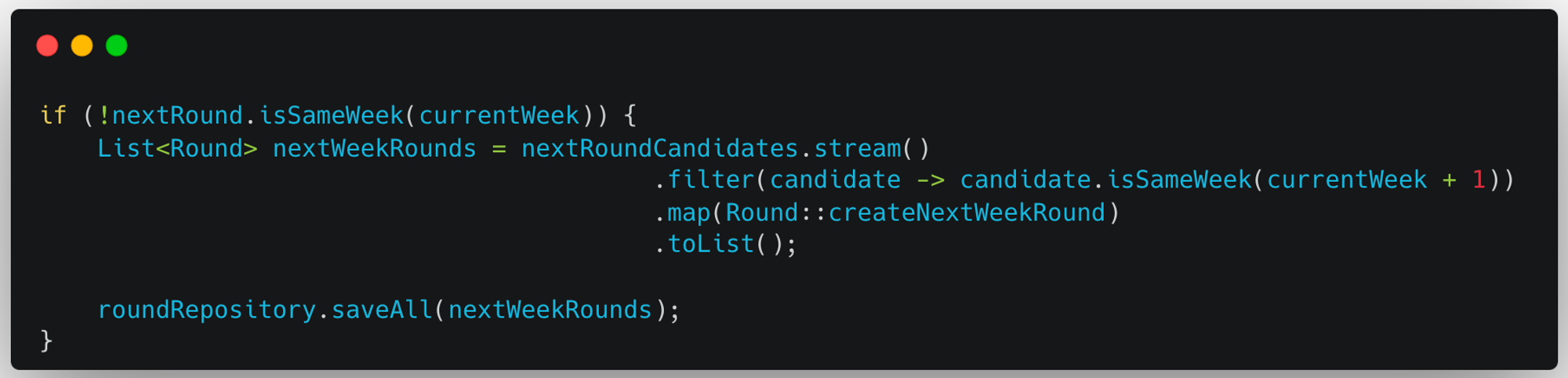
-
다음 Round가 다음 주차라면, 다다음주차의 Round를 모두 생성해서 저장한다. → 16회
Round.createNextWeekRound()의 구현은 다음과 같다.
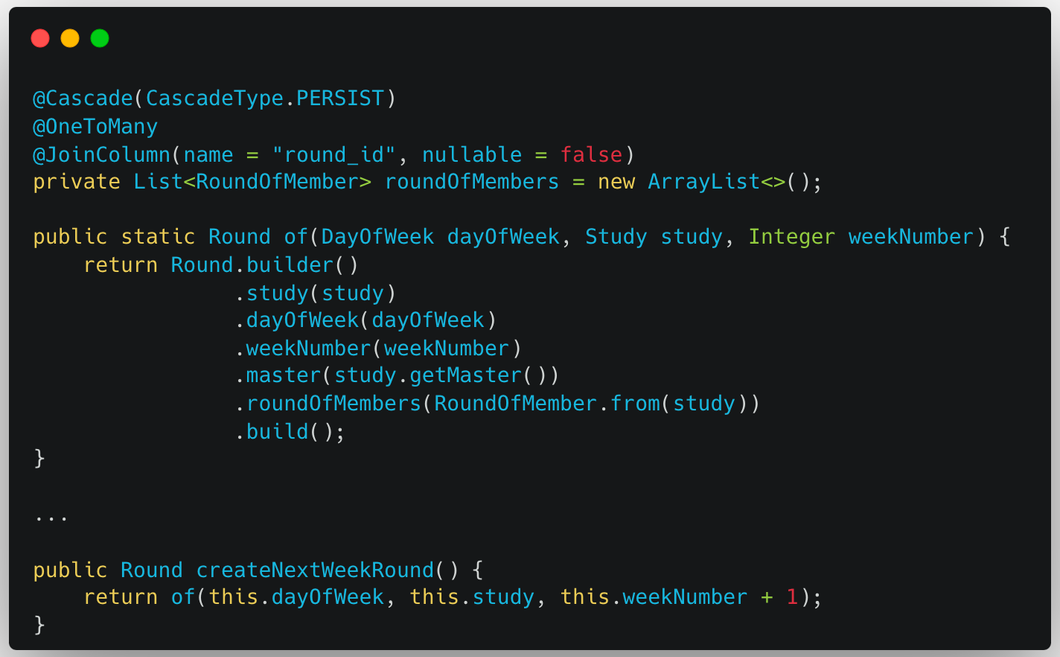
기존 Round의 내용을 복사하고, 주차 정보만 다음 주차로 변경한다. 이때 Round 내부에 있던 RoundOfMembers도 복사하게 되는데, 해당 필드는 OneToMany 관계의 RoundOfMember 리스트이다.
- RoundOfMember는 Round와 Member를 매핑하는 엔티티이다.
한 주에 2번 진행하는 스터디이기 때문에 Round를 2번 저장한다. 그리고 Round를 한 번 저장할 때 발생하는 쿼리는,
- Round가 RoundOfMember를 Lazy Loading하는 쿼리 1회
- 스터디에 참여한 인원은 6명이기 때문에 각각의 RoundOfMember를 저장하는 쿼리 6회
- Round insert 쿼리 1회
즉, 1+6+1회의 쿼리가 발생하는 Round를 2번 생성한다. 8*2=16회의 쿼리가 발생
정리
2~5번의 과정은 1번 과정에서 찾아온 Rounds를 반복하면서 진행하기 때문에, 100이 곱해진 수의 쿼리가 발생한다. 정리하자면 다음과 같다.
- 현재 진행 중(IN_PROGRESS)이면서, 어제 진행한 Round(100개)를 모두 가져온다. → 1회
- Round가 속해 있는 Study와 weekNumber를 기반으로 다음 Round가 될 수 있는 후보 Round들을 조회한다. → 1 * 100 = 100회
- 후보 Round들 중, 다음 Round가 무엇인지 찾아낸다. → 0회
- 기존의 Round를 끝내고, 다음 Round를 진행한다. → 1 * 100 = 100회
- 다음 Round가 다음 주차라면, 다다음주차의 Round를 모두 생성해서 저장한다. → 16 * 100 = 1600회
총 1801회의 쿼리가 발생한다.
// proceedRound() 메서드 실행 시간
// Java의 System.currentTimeMillis()를 이용하여 계산
time spent to proceed Round
study size: 100
total time spent: 360
The JVM is using 150 MB of memory.

쿼리 최적화
Batch Insert
먼저 1801회의 쿼리 중 무려 1600회의 쿼리를 발생시키는 Round 생성을 개선해보자.
Round를 저장할 때 쿼리가 발생하는 지점을 다시 짚어보면, 다음과 같다.
n = 업데이트하는 Round의 수, m = 스터디에 참여한 Member의 수라고 하겠다.
- Round 저장 → n회의 쿼리
- Round의 Lazy Loading(RoundOfMember) → n회의 쿼리
- Round 저장 시에 함께 저장되는 RoundOfMember 저장 → n * m회의 쿼리
여기서 가장 쉽고 빠르게, 많은 쿼리를 줄이는 방법은 Round와 RoundOfMember를 Batch Insert하는 것이라고 생각했다. 단순 저장을 매우 많은 양의 쿼리로 처리하고 있기 때문이다.
Round의 내부, 즉 객체 그래프 중 깊은 곳에 위치한 RoundOfMember를 먼저 Batch Insert 해보자.
근데 Batch Insert를 하기 전에 고려해야 할 부분이 있었다. 그것은 Round와 RoundOfMember의 연관관계였다. 두 엔티티는 1:N의 관계를 가진다. 즉 DB에서는 RoundOfMemeber 테이블이 외래키를 가지게 된다.
그렇기 때문에 RoundOfMember를 저장하기 위해서는 Round의 PK가 필요하다. Round의 PK 생성 전략은 AUTO_GENERATED이기 때문에 Round를 미리 저장해야 한다. 그리고 미리 저장한 Round의 id를 각각 가지고 있어야 한다.
위와 같은 제한 사항에 따라, 기존의 방식으로 Round를 저장하고 나온 id를 통해 RoundOfMember를 Batch Insert하는 방향으로 개선해보자.
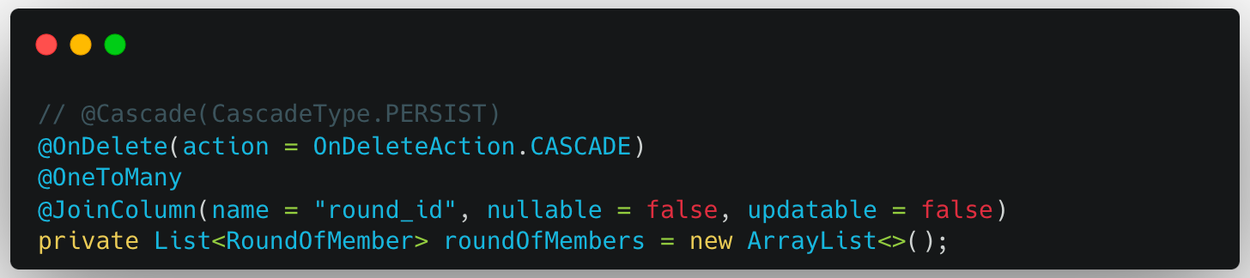
먼저, Round를 저장할 때 RoundOfMember도 곧바로 함께 저장하지 않기 위해 기존의 Cascade Persist 전략을 제거한다.
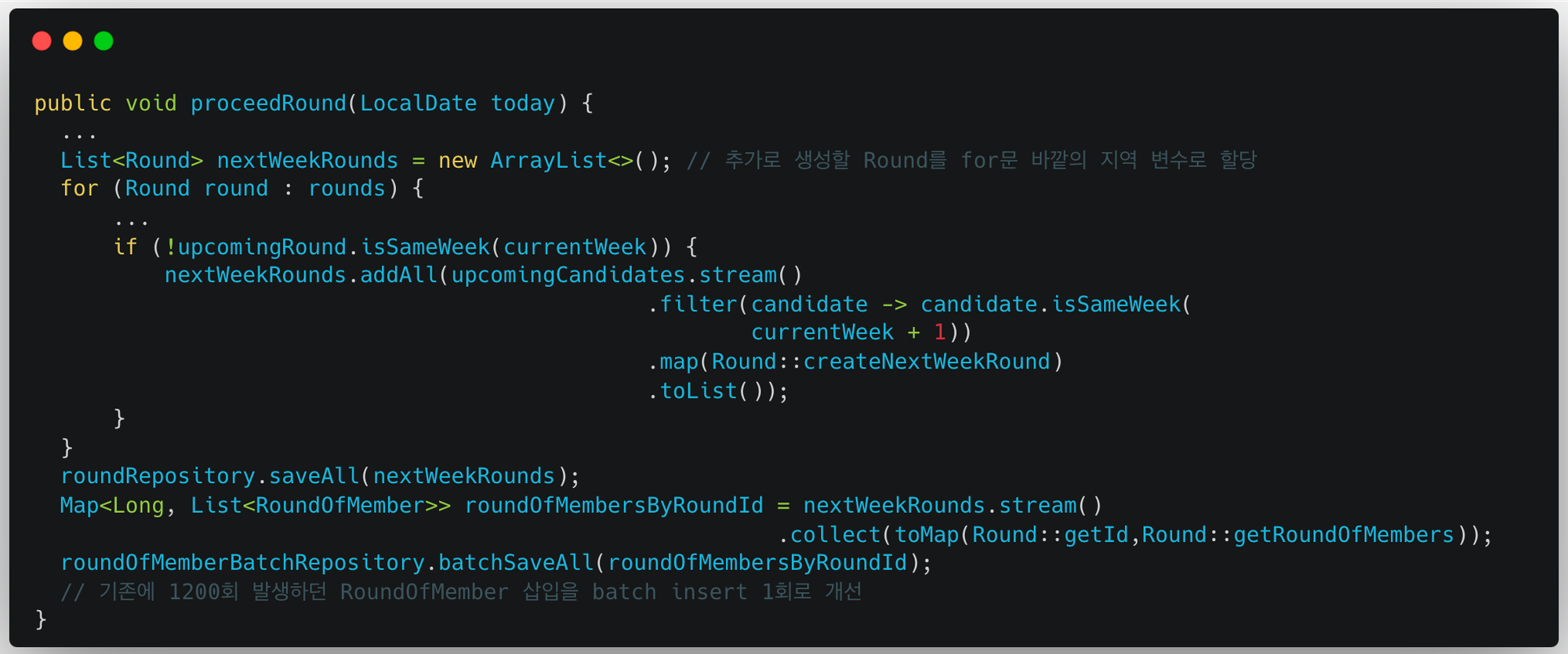
RoundOfMember는 원래 Cascade 전략을 통해 저장했다. 하지만 이제 Round와 따로 저장할 것이기 때문에 BatchRepository를 통해 저장한다. 원래 n*m회의 쿼리로 저장하던 RoundOfMember를 이제 1회의 쿼리로 저장 가능하다.
RoundOfMember Batch Insert는 JdbcTemplate을 통해 구현했다.
이제 Round 저장 시에 401개의 쿼리가 나간다. Round 저장 로직의 성능을 최적화하는 가장 이상적인 방법은 n회의 Round 저장과, n*m회의 RoundOfMember 저장을 모두 Batch로 처리하여 각각 1회의 쿼리로 해결하는 것이다. 이제 Round 저장 역시 개선해보자.
위에서 언급했듯이 RoundOfMember를 저장하기 위해서는 Round를 먼저 저장하고, 그 id들 역시 가지고 있어야 한다. 하지만, RoundOfMember를 개선했듯이 JdbcTemplate을 통해 Batch Insert를 할 수는 없었다. 왜냐하면 AUTO_GENERATED PK 생성 전략을 쓰고 있는 Round는 Batch Insert 후에 저장된 Round들의 id를 알 수 없기 때문이다.
팀에서 고려한 다른 방법은 다음과 같다.
- DB에서 채번하는 PK 대신 UUID를 식별자로 사용한다. → 이는 index의 크기가 커지면서 DB 성능 저하를 야기할 수도 있다고 생각했다.
- PK 생성 전략 변경을 Sequence로 변경한다. → 우리 팀은 MySQL을 사용하고 있는데, MySQL은 Sequence 전략을 지원하지 않는다.
- PK 생성 전략 변경을 Table로 변경한다.
세 가지 방법 중 위 2가지 방법은 제한되는 부분이 있다고 느껴져서 결국 Table PK 생성 전략을 사용하는 것으로 결정했다.
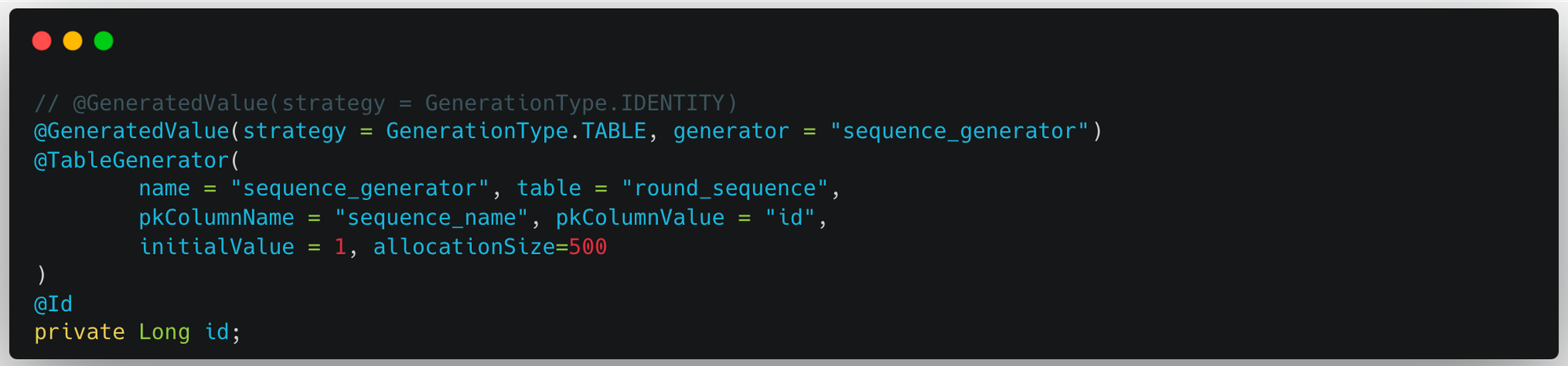
PK 생성 전략을 Table로 변경한다. Table 전략은 id를 관리하는 하나의 테이블이 존재한다. 해당 테이블은 시퀀스 테이블과 같은 동작을 하고, 이를 조회함으로써 다음 id 값을 알 수 있다. 그렇다고 Round를 삽입할 때 마다 id를 알아내기 위해 매번 시퀀스 테이블을 조회하는 것은 성능 저하가 이어질 것이다.
이를 해결하기 위해 allocationSize를 설정할 수 있다. allocationSize는 시퀀스 테이블에 한 번 접근할 때 가져올 값의 크기이자, 시퀀스 테이블의 값을 얼마나 증가시켜줄지를 의미하기도 한다.
allocationSize가 500이라면, 시퀀스 테이블에 접근할 때 1부터 500까지의 값을 한 번에 가져오고 메모리에서 관리한다. 그리고 Round를 삽입할 때 순서대로 id를 부여한다. 동시에 시퀀스 테이블의 다음 시퀀스 값은 501으로 업데이트된다. 즉 시퀀스 테이블로부터 id를 채번해 올 때, 시퀀스를 조회하는 쿼리 1번, 업데이트하는 쿼리 1번으로 총 2번의 쿼리가 발생한다. 이를 알고 넘어가자.
우리 팀은 JDBC batch size를 500으로 설정했고, 이에 맞춰 allocationSize를 설정했다.
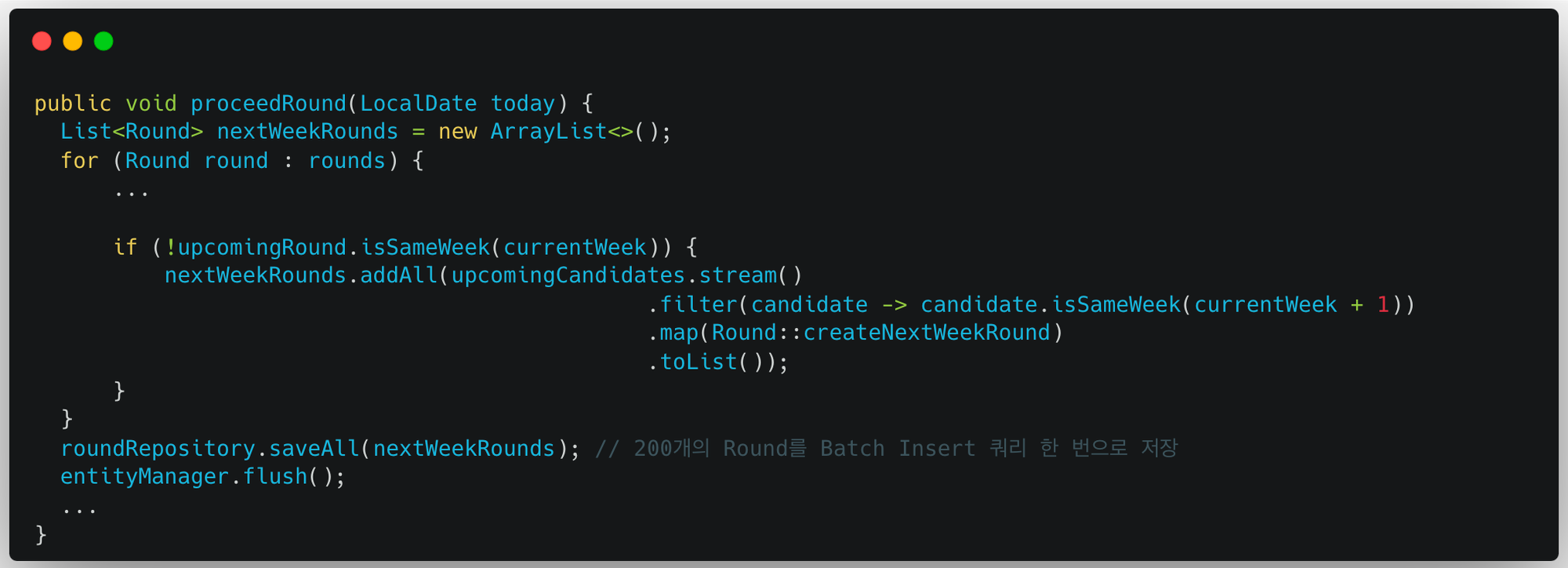
이제 200개의 Round를 Batch Insert 한 번으로 저장한다. 대신 시퀀스를 채번해오면서 발생하는 쿼리 2번이 추가된다.
- 의문점: 메서드 최하단에 entityManager.flush()를 호출하고 있다. 이를 호출하지 않으면 proceedRound()가 두 번 호출되면서 에러가 발생하는데, 아직 원인을 파악하지 못 한 상태이다.

마지막으로 Round 정보를 복사할 때 발생하는 Lazy Loading(RoundOfMember)을 EntityGraph로 해결한다. 이제 N개의 Round를 저장할 때 따라왔던 N개의 Lazy Loading이 발생하지 않는다.
이로써 1600번의 쿼리가 발생하던 Round 저장 로직을 Batch Insert와 @EntityGraph를 통해 2+@번의 쿼리로 개선했다.
- @: allocationSIze에 따라 시퀀스 채번 쿼리가 발생한다.
쓰기 지연 저장소를 활용한 효율적인 Batch Update
이제 4번 과정에 해당하는, 기존 Round 종료 및 다음 Round 시작에서 발생하는 N(100)번의 업데이트 쿼리를 개선하자.
현재는 2번의 round update 쿼리를 쓰기 지연 저장소에서 모아서 쿼리 1번으로 실행하고 있다. 그리고 이를 100번의 for문 내에서 반복하여 총 100번의 쿼리가 실행된다. 즉 2번의 쿼리를 1번으로 줄여서 100번 반복다.
쓰기 지연 저장소를 더 잘 활용한다면 200번의 쿼리를 1번으로 줄여서 실행할 수 있을 것이라고 생각했다.
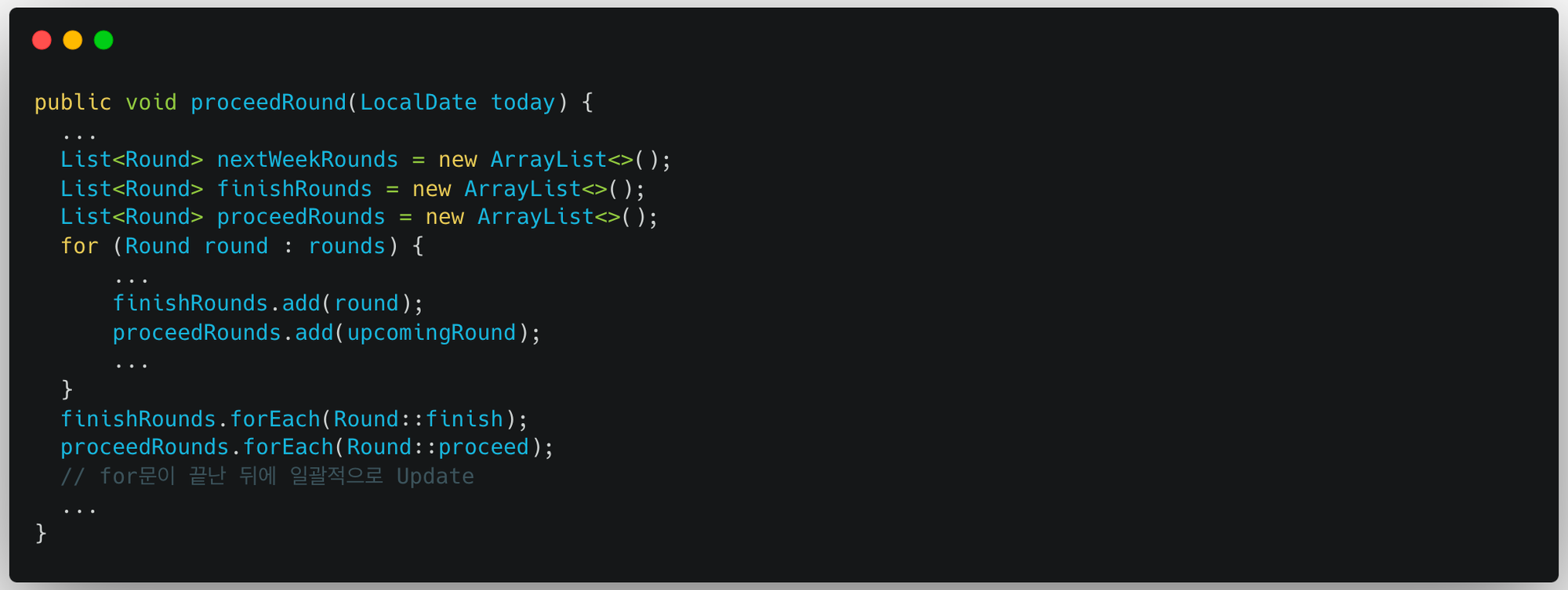
for문 밖에 리스트를 선언하고, 기존에 for문 내에서 update하던 두 라운드를 리스트에 넣는다. 그리고 for문이 끝난 뒤에 일괄적으로 update함으로써 100개의 쿼리가 한 번에 나가도록 수정했다.
도메인 규칙 활용 및 조회 순서 변경
이제 2번에 해당하는, 다음 Round가 될 수 있는 후보 Round 조회 로직을 개선해보자.
현재는 다음과 같은 흐름이다.
- 어제 끝나는 Round들을 모두 조회
- 조회한 Round들에 대해서 반복문을 돌면서, Round가 가지고 있는 studyId와 weekNumber를 기반으로 다음 Round 후보 조회 → 1번에서 조회한 Round 개수 만큼 쿼리 발생!
Round 각각의 studyId와 weekNumber를 활용하기 위해 반복문에서 조회를 하는 게 문제인 상황이다. 그러므로 반복문 안에서 매번 쿼리를 실행하는 게 아니라, 반복문 밖에서 전체 조회를 한 뒤에 for문 안에서는 Java API만을 활용하여 처리하는 것이 좋아 보인다.
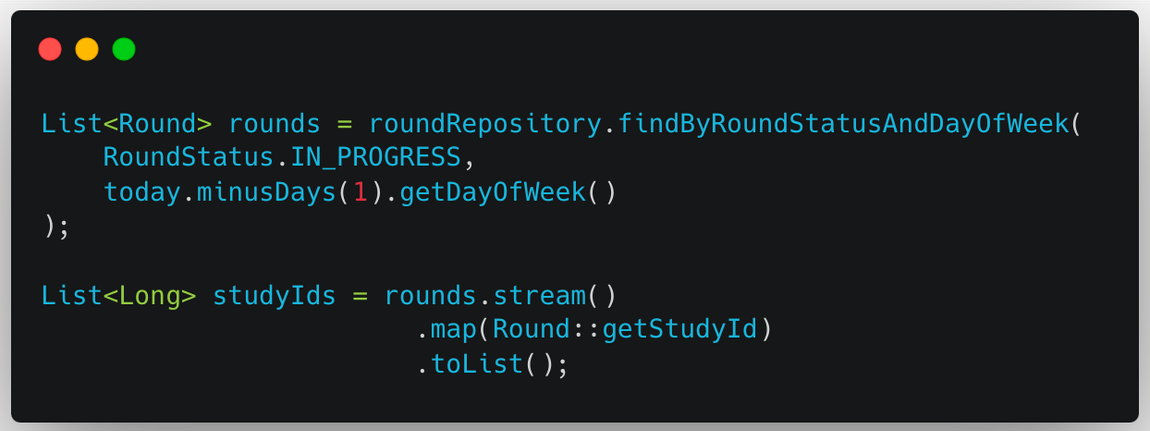
2번 과정에서 필요한 studyId는 1번 과정에서 조회한 Round들로부터 얻어낼 수 있다. 이제 weekNumber까지 밖으로 빼내고, studyId와 weekNumber를 매핑하면 된다. 하지만 문제가 있다.
- 3주차 회차가 끝난 1번 스터디 → studyId = 1, weekNumber = 3
- 6주차 회차가 끝난 2번 스터디 → studyId = 2, weekNumber = 6
- 5주차 회차가 끝난 3번 스터디 → studyId = 3, weekNumber = 5
- … → studyId = 5, weekNumber = 10
위와 같이 studyId와 weekNumber 쌍은 스터디마다 제각각일 수 있다. 반복문 내부에서 한 번씩 실행하던 쿼리를 외부에서 한 번에 처리하려면 IN 쿼리를 사용하게 될 텐데, studyId와 weekNumber에 대해 IN 쿼리를 사용한다면 어마어마한 양의 레코드를 조회하게 될 수도 있다.
우리 팀은 이를 도메인 규칙을 활용해서 해결했다. 조회의 목표는 ‘라운드가 끝난 특정 스터디의 다음 Round 후보를 조회하는 것’이다. 그리고 위에서 언급했듯이, 우리 팀에는 다음과 같은 도메인 규칙이 있다.
- 기존에 n주차를 진행하고 있을 때는 n+1주차까지의 회차들이 존재한다.
즉, 현재까지 진행한 Round는 모두 누적되어 DB에 쌓이지만 아직 진행하지 않은 Round는 아무리 많아봤자 다음주까지만 존재한다는 것이다. 아직 진행되지 않은 Round는 RoundStatus라는 컬럼을 통해 쉽게 알 수 있었다.
그러므로 studyId와 RoundStatus라는 컬럼을 통해 조회한다면 weekNumber 컬럼으로 IN 쿼리를 사용하지 않아도 된다.
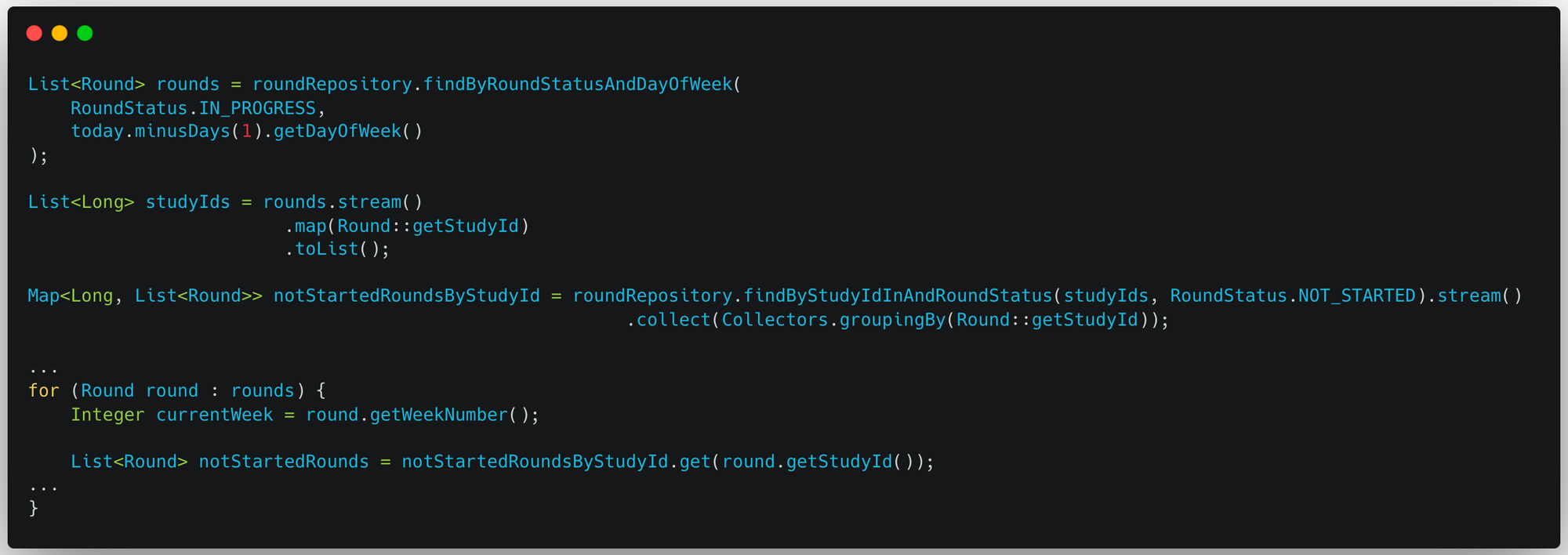
studyId와 RoundStatus를 통해 조회한 Round를 studyId로 grouping한다. 그리고 기존의 반복문 내에서는 쿼리를 실행하는 대신 grouping한 Map에서 studyId를 통해 후보 Round들을 조회한다.
이제 후보 Round 조회도 한 번의 쿼리로 처리하면서 성능 최적화가 끝났다.
최적화 결과
// before
time spent to proceed Round
study size: 100
total time spent: 360
The JVM is using 150 MB of memory.
// after
time spent to proceed Round
study size: 100
total time spent: 85
The JVM is using 153 MB of memory.

스케줄링 시에 실행되는 쿼리의 수가 1,801개에서 5개로 줄었고, proceedRound() 메서드의 실행 시간을 4배 이상 개선했다.
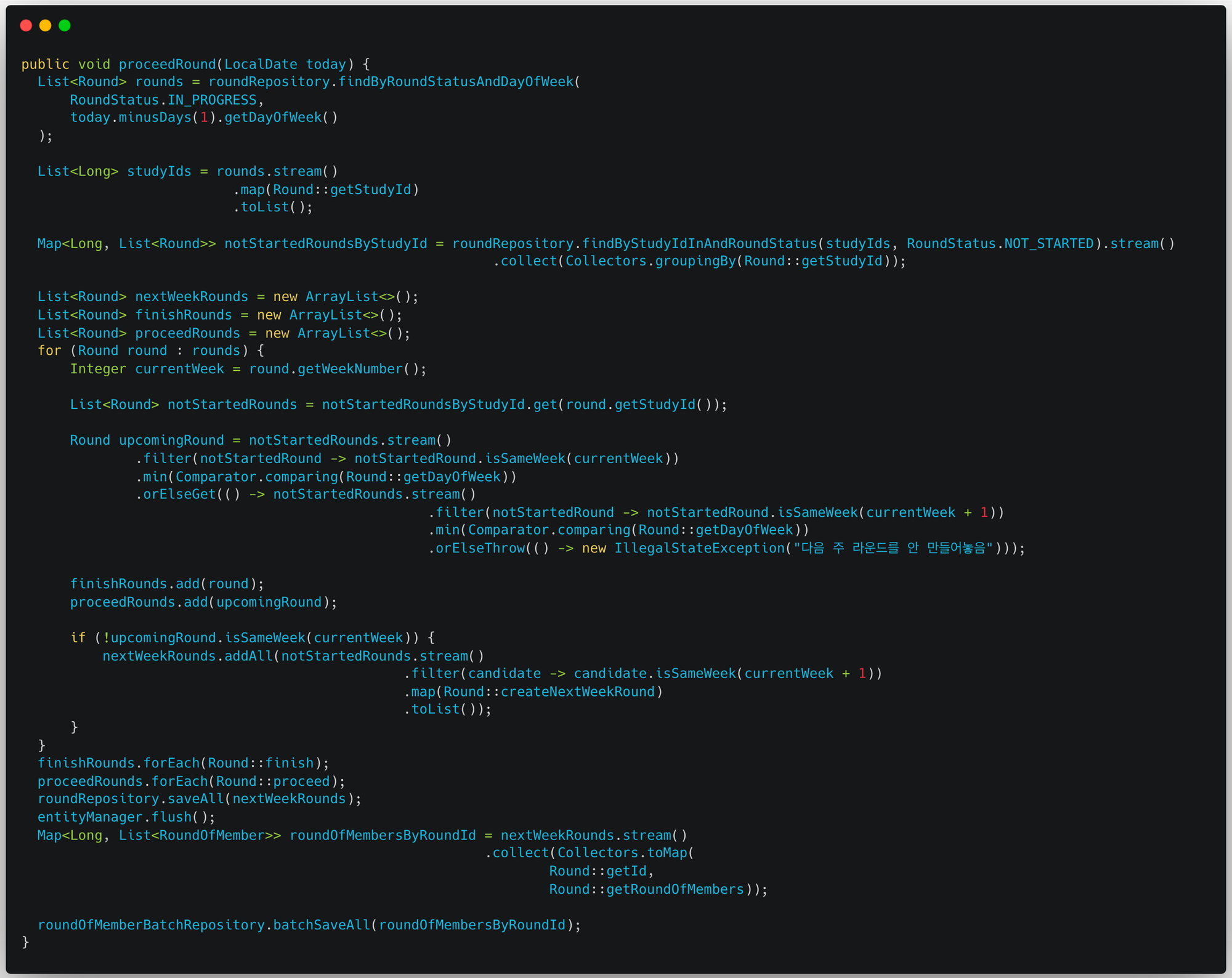
최적화가 완료된 최종 코드는 위와 같다. 이제 리팩터링이 필요해 보인다.
느낀 점
- JPA를 사용하면서 쓰기 지연 저장소, flush 시점 등에 대해 제대로 이해하지 못하고 있었다는 걸 느꼈다.
- 특정 기술을 사용할 때, 필요한 기능을 구현하는 것은 생각보다 쉽다. 하지만 문제가 발생했을 때 빠르게 트러블슈팅을 하는 것은 그 기술의 동작 원리를 잘 이해하고 있을 때 가능한 것 같다. 핵심에 집중하자.
