ASCII
Amesican Standard Code for Information Interchange
미국에서 정의한 표준 부호체계
ASCII 코드는 데이터 7비트 + 1비트(Parity Bit) 로 구성되어 있다.
- Parity Bit : 통신 에러 검출을 위해 데이터 비트에서 1의 개수를 계산하여 짝수일 경우 홀수 일 경우를 체크해준다.
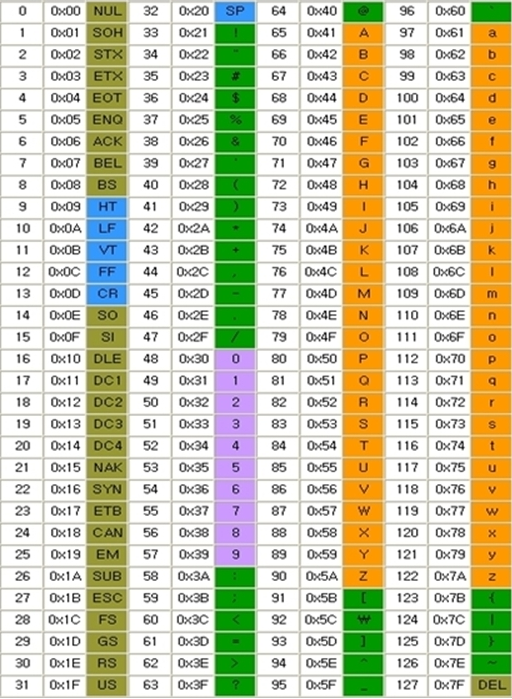
표를 보면 특수문자 몇개와 알파벳으로 이루어져 있기 때문에 다른 나라의 언어를 표현할 수가 없었다.
때문에 Parity Bit를 빼고 데이터 비트를 늘린 ANSI 코드가 나온다.
ANSI
데이터 비트가 2^8개, 256개로 늘어나게 된 ANSI 코드 ... 지만
여전히 다른 나라의 문자를 표현하기에는 턱없이 부족하다.
Unicode
기존 ASCII 코드가 1 byte인 것과 다르게, Unicode는 2 byte다.
2^8 = 126
2^16 = 65536
전세계의 모든 문자를 표현하겠다는 의도대로 용량이 많이 커졌다.
그러나 ... 이마저도 부족해져 유니코드 3.0 부터는 4 byte 까지 늘어나게 되었다
( 최신 버전 : 2021년에 유니코드 14.0 버전이 발표되었다고 함 )
Unicode도 ASCII 처럼 테이블 표가 있다.
표현할 수 있는 양이 많이 차이가 나서 테이블을 구역별로 나누어져 있으며 한글은 3byte 영역에 있다.
...
이렇게 각 문자들의 byte 크기가 다르다보니, 전송을 하기 위해 인코딩을 할 때 가변적 길이를 처리하기가 곤란하다.
이 때문에 사용되는 것이 UTF이다.
UTF는 가변적인 길이를 갖는 Unicode를 encoding 하는 방식이다.
전세계적으로 약속된 encoding 방식을 사용하기 때문에 ( UTF-8, UTF-16 ... ) 전세계 다른 언어로 된 웹페이지를 가도 정상적으로 decoding 되어서 보인다.
( 가끔 깨지는 것들은 다른 encoding 방식을 써서 그런듯 ? )
--> https://rdsong.com/1453
