최근 Gossip protocol을 구현하고 있다.
Pull 기반으로 구현하고 있기 때문에, 각 노드들은 주기적으로 랜덤한 주변 노드에게 새로운 메세지를 요청해야 한다. 따라서 나는, 새로운 메세지 요청을 받으면 자신이 새롭게 받은 메세지를 전부 다 한 패킷에 담아 응답을 하도록 구현 했었다(UDP 이용).
그 후, 스트레스 테스트를 하며 많은 수의 메세지를 전파하려 하자 패킷을 보내는 과정에서 아래와 같은 에러가 발생했다.
write udp 127.0.0.1:8547->127.0.0.1:8548: sendto: message too long왜 에러가 발생한지 알겠고, 이것을 해결하려면 패킷을 나누어 보내야 한다는 것도 직감적으로는 알겠다. 고민해봐야 하는 것은,
- 패킷을 나눌 때, Marshalling 한 byte array 쪼개서 보낼지, 패킷을 여러 개 만들어 보낼지?
- 그러면 크기를 몇으로 나눠야 보내야 할까? 최대 사이즈는 몇일까? too long이라는 것은 기준이 있다는 것인데...
첫번째 고민은 쉽게 답을 내렸다. Marshalling한 데이터를 나누어 보내면 중간에 하나라도 유실될 경우 정상적인 데이터 처리가 불가능하게 된다. 차라리 여러 패킷으로 나눠 전송하면 동일한 헤더를 게속 붙여 보내야 하는 오버헤드는 있겠지만, 유실되더라도 정상적으로 수신된 패킷에 대한 처리는 가능할 것이다.
하지만 두번째 고민은 조사가 필요한 부분이다. 검색해보자.
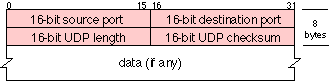
일단 패킷의 구조부터 본다. 총 8바이트의 헤더를 사용하고 있다(20바이트의 헤더를 사용하는 TCP보다 간단). 이 중, UDP length를 보면 65535바이트(2^16 - 1)로 최대 크기를 구할 수 있다. 표준 헤더를 가정하면 IPv4는 20바이트를 사용하고 UDP는 8바이트를 사용하니, 결과적으로 최대 UDP 페이로드 크기는 65507바이트가 되겠다.
그러면 65507바이트 정도로 패킷을 잘라서 보내면 될까? 고려해야 할 것이 더 있다.
MTU는 네트워크에 연결된 장치가 받아 들일 수 있는 최대 데이터 크기를 말한다. 데이터링크 계층, 인터넷 계층의 각 MTU에 대해 살펴보자.
인터넷 프로토콜에서는 호스트가 최소 576바이트(IPv4의 경우) 또는 1280바이트(IPv6의 경우)의 IP 데이터그램을 처리할 수 있어야 한다고 명시하고 있다(RFC1122).

(내부 호스트끼리 3000 byte UDP 패킷을 전송했을 경우 와이어샤크 캡쳐 결과 - 라우터뿐만아니라 각 호스트도 인터넷 프로토콜을 따르고 있음, 목적지에서 reassemble 수행, 중간에 작은 MTU의 라우터를 만날 경우 또 다시 단편화 발생)
Ethernet의 MTU는 최소46, 권장 1500바이트이며, 46바이트보다 작으면 패딩된 후 전달된다(RFC894).
인터넷 프로토콜의 MTU는 Ethernet에 설정된 MTU 값보다 클 수 없으며, 만약 어플리케이션으로 부터 인터넷 프로토콜 MTU보다 큰 크기의 패킷 전송 요청이 들어오면, 이를 MTU크기 이하로 분할하여 전달하게 된다. 이를 패킷 단편화라고 한다. 검색해본 결과, MTU보다 작은 패킷을 보내 패킷 단편화를 최대한 피하라고 하는데 그 이유는 아래와 같다.
- 발신자 측에서 자원을 낭비합니다(패킷을 쪼개야 함).
- 수신자 측에서 리소스를 낭비합니다(패킷을 합쳐야 함).
- 동일한 양의 페이로드 데이터에 대한 프로토콜 오버헤드가 증가합니다.
- 단일 조각이 손실되면 전체 패킷이 손실됩니다.
- 단일 조각이 손상되면 전체 패킷이 손상됩니다.
- 재전송의 경우 모든 조각을 재전송해야 합니다.
모든 네트워크 장비의 MTU가 동일하다면 더 쉬운 문제가 되었겠지만, 아쉽게도 MTU 크기가 다를 수 있다. TCP 같은 경우는 MTU의 크기를 미리 알아내어 해당 크기로 Segment를 만들어 보내기 때문에 따로 단편화가 발생하지는 않는다. 그러나 UDP는 MTU를 파악할 수 없기 때문에 단편화(Fragmentation)가 발생하게 된다.
단편화의 예시를 살펴보자.
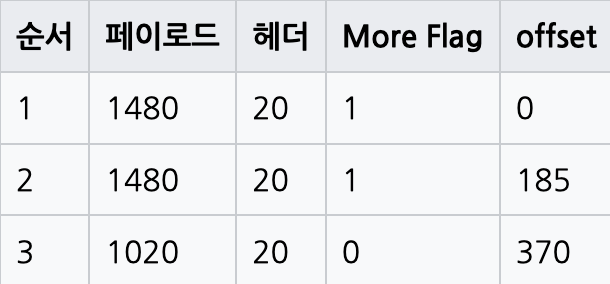
위와 같이 각 조각들은 헤더를 가지게 된다. 첫번째, 두번째 단편은 뒤에 이어질 단편이 있으므로 more flag가 1이며 offset은 8바이트 단위로 표시된다. 1480 / 8 = 185, 2960 / 8 = 370
(https://itwiki.kr/w/IP_%EB%8B%A8%ED%8E%B8%ED%99%94)
따라서 보수적으로 사이즈를 정한다면, 인터넷 프로토콜 MTU 최솟값인 576바이트에서 IP, UDP헤더의 크기를 뺀 576-20-8 = 548바이트, 혹은 IP헤더는 옵션 영역까지 사용한다면 최대 60바이트까지 늘어날 수 있는 가변 길이를 갖고 있기 때문에 576-60-8 = 508바이트가 되겠다.
여기서 주의해야 할 점은, 위 크기로 보낸다고 UDP 패킷 자체가 안전하다고는 할 수 없다. 단순히 단편화를 피할 수 있을 뿐이다.
하지만 어플리케이션에서 아주 작은 단위로 패킷을 쪼개 보내는 것과, IP프로토콜에서 패킷 단편화가 일어나는 것, 둘 중에 뭐가 정말 리소스에 이득이 될까? 테스트할 수 있으면 직접 해보고, 아니라면 다른 사람들이 테스트한 결과들을 모아보자.
(추가 예정)
1
// https://stackoverflow.com/questions/14993000/the-most-reliable-and-efficient-udp-packet-size
Would sending lots a small packets by UDP take more resources ?
Yes, it would, definitely! I just did an experiment with a streaming app. The app sends 2000 frames of data each second, precisely timed. The data payload for each frame is 24 bytes. I used UDP with sendto() to send this data to a listener app on another node.
What I found was interesting. This level of activity took my sending CPU to its knees! I went from having about 64% free CPU time, to having about 5%! That was disastrous for my application, so I had to fix that. I decided to experiment with variations.
First, I simply commented out the sendto() call, to see what the packet assembly overhead looked like. About a 1% hit on CPU time. Not bad. OK... must be the sendto() call!
Then, I did a quick fakeout test... I called the sendto() API only once in every 10 iterations, but I padded the data record to 10 times its previous length, to simulate the effect of assembling a collection of smaller records into a larger one, sent less often. The results were quite satisfactory: 7% CPU hit, as compared to 59% previously. It would seem that, at least on my *NIX-like system, the operation of sending a packet is costly just in the overhead of making the call.
Just in case anyone doubts whether the test was working properly, I verified all the results with Wireshark observation of the actual UDP transmissions to confirm all was working as it should.
Conclusion: it uses MUCH less CPU time to send larger packets less often, then the same amount of data in the form of smaller packets sent more frequently. Admittedly, I do not know what happens if UDP starts fragging your overly-large UDP datagram... I mean, I don't know how much CPU overhead this adds. I will try to find out (I'd like to know myself) and update this answer.