개요
안녕하세요. 이번에는 APIGateWay와 ServiceDiscovery에 대한 내용을 작성하려고 합니다. APIGateWay는 MSA 아키텍쳐에서 주로 사용되는 개념입니다. 이와 동시에 ServiceDiscovery도 함께 사용되는 방식인데 둘 다 MSA의 연결에 관련되어 있는 내용이라 대략적으로 함께 살펴보겠습니다.
APIGateWay가 생소했던 이유
저는 APIGateWay라는 단어와 그 내용들이 이해하기 어려웠습니다. 라우팅 한다는 것도 리액트에서 써본 리액트 라우터, 네트워크 라우터? 정도만 생각이 나니... 어쩔 수 없습니다. 직접 쓰면서 공부하니 APIGateWay에서 말하는 라우팅은 서버를 연결해준다는 의미입니다. 그리고 APIGateWay라길래 특별히 네트워크 지식이 필요할까 싶은 느낌도 들었는데 당장 공부해서 사용할 목적이라면, 그저 클라이언트와 서버를 연결해주는 프록시 서버 정도로만 이해해도 될 것 같습니다. 하지만 시간이 있다면 그렇게 지나가지말고 나중에 조금 더 들여다 보세요... 이렇게만 공부하다 피본 경우가 너무 많습니다
라우팅은 서버를 연결해준다는 것.
설계적으로 보면, 서버의 가장 앞단에 위치한 프록시 서버 느낌
AWS에서 말하는 APIGateWay
Amazon API Gateway는 규모와 관계없이 REST 및 WebSocket API를 생성, 게시, 유지, 모니터링 및 보호하기 위한 AWS 서비스입니다. API 개발자는 AWS 또는 다른 웹 서비스를 비롯해 AWS 클라우드에 저장된 데이터에 액세스하는 API를 생성할 수 있습니다. API Gateway API 개발자는 자체 클라이언트 애플리케이션에서 사용할 API를 생성할 수 있습니다. 또는 타사 앱 개발자가 API를 사용하도록 제공할 수도 있습니다. 자세한 내용은 API Gateway를 누가 사용하는가? 단원을 참조하세요.
HTTP, WebSocket 기반 네트워크 통신을 생성, 게시, 유지, 보호를 해주는 서비스라는 것이다. 어쨌든 MSA 아키텍쳐상의 많은 MicroService들을 관리해주는 역할을 하는 것.
감자의 APIGateWay
APIGateWay는 MSA에 존재하는 많은 서버들의 엔드포인트를 가지는 MSA의 한 컴포넌트 입니다. 말 그대로 많은 서비스의 엔드포인트를 가지고 있는 API이며 서비스의 가장 앞에 위치해서 클라이언트의 요청과 응답의 수문장 같은 역할을 하는 서버입니다. 아래는 SpringCloudGateWay yml 설정파일 입니다.
spring:
application:
name: apigateway-service
cloud:
gateway:
routes:
- id: catalog-service
uri: lb://CATALOG-SERVICE
predicates:
- Path=/catalog-service/
- id: user-service
uri: lb://USER-SERVICE
predicates:
- Path=/user-service/
- id: first-service
uri: lb://MY-FIRST-SERVICE
predicates:
- Path=/first-service/
filters:
- CustomFilter
- id: second-service
uri: lb://MY-SECOND-SERVICE
predicates:
- Path=/second-service/
filters:
- name: CustomFilter
- name: LoggingFilter
args:
baseMessage: Hi, there
preLogger: true
postLogger: true
위 코드는 SpringCloudGateWay에서 호스팅하는 서버를 설정한 yml파일입니다. 위에서 6번째 줄 routes 부터 보시면 제가 여러 서버에 대한 아이디와 경로 정보를 담아둔걸 확인할 수 있습니다.
routes:
- id: user-service
uri: lb://USER-SERVICE
predicates:
- Path=/user-service/id : 해당 서버의 고유 아이디
( 해당 서버에서 각자 설정해둔 서버의 name 입니다. 3번째 줄과 같이 각 서버의 설정값 입니다. )uri : 해당 서버의 uri
여기 쓰여있느 내용은 조금 특별합니다. lb = LoadBalancer를 뜻하고, 로드밸랜서에서 또 MY-SECOND-SERVICE라는 이름을 가지는 서버를 찾겠다는 이야기입니다.predicates : 해당 서버를 찾는 조건
여기에서는 PATH라고 쓰여있는 것 처럼 gateway로 들어오는 요청의 경로가 이 패스와 같다면, 위 서버를 찾아서 실행하겠다~ 하는 것입니다.
이걸 왜 보여드리나 싶겠지만, 전 개인적으로 실제 코드가 어떻게 구성되어 있는지 보면 좀 더 와닿는 느낌이 들어서 첨부 해봤습니다. 백문이 불여일타이듯 시스템도 글로 보는니 차라리 코드를 보는게 낫지 않나 싶습니다.
APIGateWay를 쓰는 이유
이렇게만 보면 그저 단일 지점에서 여러 서버를 연결하는 것이라고만 생각할 수 있는데 그렇지 않습니다. 이런 물리적 위치 때문에 APIGateWay를 활용하여 구축할 수 있는 아래와 같은 부가적인 역할이 많습니다.
- logging 처리
- 보안, 인증 관리
- 마이크로 서비스들의 연결 관리
등등 여러가지 이유가 있습니다.
1. Logging 처리
만약에 모든 서비스에서 로그를 남기고 그 로그를 관리하는건 쉽지 않습니다. 쇼핑몰에서 어떤 사용자가 주문하고 결제를 했다면, 아마 상품 서버, 결제 서버 등등 적어도 두개에서 많으면 4~5개 정도의 서버가 연관되어 처리합니다. 그래서 apigateway에서 관제를 하는 방식으로 보완해주는 것입니다.
2. 보안 및 인증 관리
보통 많은 GateWay 서버에서는 이 인증과 인가처리를 맡아서 합니다. 인증은 요청당 한 번, 인가는 한 번 받아두면 서비스에 따라서 오랫동안 쓸 수 있기도 합니다. 어쨌든 인증이 필요한 서비스는 어떤 아키텍쳐든 지속적으로 인증 처리를 해야합니다. GateWay는 수문장처럼 모든 서비스의 엔드포인트를 관리하기 때문에 인증 및 인가 처리를 하기에 적합한 위치에 있습니다. 보안 서버를 따로 두는 아키텍쳐를 설계할 수도 있습니다.
3. 마이크로 서비스들의 연결 관리
만약에 고객이 상품을 결제하고 마이크로 서비스별로 요청을 주고 받아야 한다면 성능도 안 나오고, 리소스도 낭비입니다. 직접적으로 하기는 힘들지만 GateWay에서 이런 역할을 해줄 수 있습니다. RabbitMQ나 Kafka같은 메세지 브로커를 연결하고, 설정하기 적합한 위치에 있습니다.
상황에 맞춰 다르게
MSA의 가장 큰 특징은 어디선가는 MongoDB를 쓰고, 어디선가는 Kafka를 쓰고, 어디서는 Redis를 쓰고 등등 사용하는 기술스택이 다르다는 것입니다. 저도 당장은 SpringCloudGateWay를 사용해서 한 두번의 프로젝트를 겪어볼 예정이지만 앞으로 공부를 해나가면서 어떤 API를 사용하게 될지는 모릅니다. 그렇기에 그때 그때 GateWay의 역할은 늘어날 수도 줄어들 수도 있습니다. 그게 MSA의 특징이고 GateWay의 특징입니다.
ServiceDiscovery
ServiceDeiscovery는 MSA아키텍처에서 마이크로 서비스들의 ip,port 등을 파악해주고, 몇 개의 인스턴스의 갯수 등등 마이크로 서비스들에 대한 정보를 캐싱하는 곳이다. gateway에 id와 name만 정확하게 있다면, 인스턴스를 늘려도 ServiceDeiscovery를 통해서 여러 인스턴스를 찾을 수 있고 나눠서 요청을 보내게 할 수 있다. 실제로 MSA를 구현하다보면, 각 인스턴스들이 scale-out되는 상황들을 종종 만날테고, 그랬을 때마다 해당 포트번호와 ip를 gateway에서 직접 관리하지 않아도 되게 해주는 것이다.
ClientSide vs ServerSide
이런 ServiceDiscovery는 두 가지 방식이 있다. 단어 뜻 그대로 Cliendt Side (클라이언트 측)에서 관리하는가, ServerSide (서버 측)에서 관리하는가의 차이다. 정확한 설명을 위해서 NGINX의 문서를 봤다.
Client‑Side Discovery Pattern
client가 service registry에 물어서 서비스 위치를 찾은 후에 로드밸런싱 알고리즘을 통해 호출하는 방식이다. Service registry에는 실시간으로 상태가 기록된다.
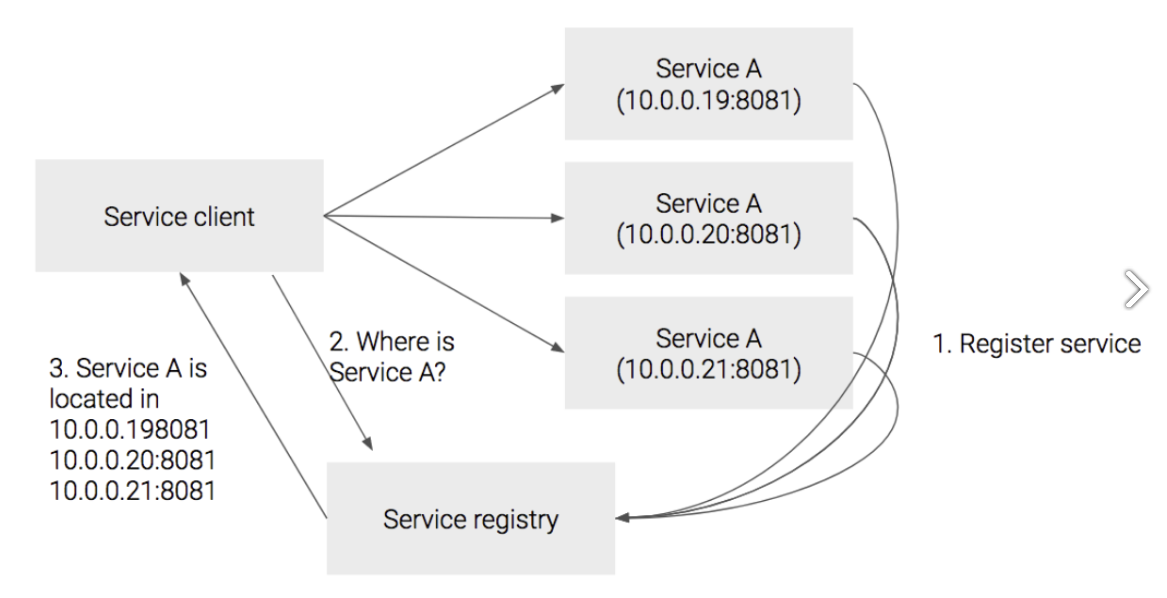
ClientSidePattern은 클라이언트가 요청의 완전한 주체가 되는 것이다. 요청을 보내려는 서비스가 어디에 있는지, 상태는 어떤지를 파악하고 그 정보를 활용해서 전략을 설정할 수 있다.
장점
- 비교적 간단하다.
- 각 서비스에 맞게 로드밸런싱 전략을 구현할 수 있다.
단점
- 각 서비스마다 서비스 레지스트리를 구현해야한다.
- 만약 서비스마다 다른 언어를 사용하고 있다면 언어별 또는 프레임워크별로 구현해야한다.
조금 더 생각해보면,,
확장성이 높은 것 같다. 여기서 부터는 철저히 내 생각인데 좀 더 섬세한 시스템 개발을 위해서, 그리고 확장성 높은 개발을 위해서는 이 방법이 좋겠다는 느낌이다. 그리고 서비스의 규모에 따라 ServerSidePattern과 혼용하여 사용할 수도 있지 않을까 싶다.
ServerSide Pattern
클라이언트가 라우터로 서비스를 호출하여 달라고 요청을 보내는 방식이다. 여기서 플랫폼 라우터는 awsELB, 구글 로드 밸런서가 대표적이다. 이 플랫폼 라우터는 서비스 레지스트리에 문의하여 서비스의 위치를 찾은 후 이를 기반으로 라우팅을 한다.
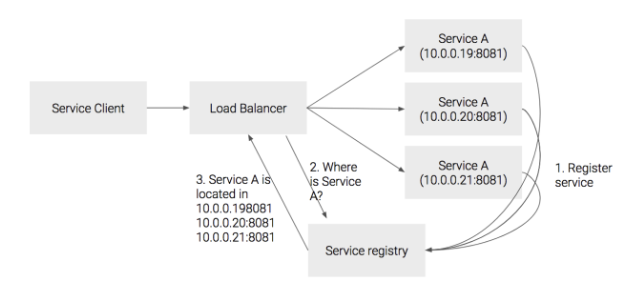
장점
- 디스커버리 로직을 클라이언트에서 분리할 수 있다.
- 클라이언트 쪽에선 이런 로직을 몰라도 되고 따로 구현할 필요도 없다.
단점
- 로드밸런서는 배포 환경에 구축이 되어야 한다 .
- public cloud에서 로드 밸런서를 생성하면 각 환경에 맞는 로드밸런서 등이 자동 생성되지만, private cloud에서는 로드 밸런서를 직접 생성해야 한다.
- 서비스 디스커버리에 의존적이다.
조금 더 생각해보면,,
ServiceDiscovery 서버가 죽는 일이 얼마나 있을까 싶다만 그리고 죽으면 바로 살리는 시스템을 구축해놓으면 상관없다만, 좀 치명적인 단점일 수도 있찌 않을까 하는 생각이 든다. 아마 현업 경험이 없어서 이 정도로 생각하는듯?,,,
마무리
gateway는 물리적으로 가장 앞단에서 모든 서비스로 요청을 전달하는 곳. ServiceDiscovery에게 물어서 요청을 보내는 방식으로 사용된다.
ServiceDiscovery는 마이크로 서비스의 정보를 관리해주는 곳. 다운 되었는지 실행중인지 등의 정보들을 가지고 있다. 그리고 두 가지 방식으로 많이 구현한다. 어렵다. 프로젝트 진행 후에 2탄을 쓰면 더 좋지 않을까 싶다.
