크롤링(crawling)이란?
● Web상에 존재하는 Contents를 수집하는 작업(프로그래밍으로 자동화 가능)
○ HTML 페이지를 가져와서, HTML/CSS등을 파싱하고, 필요한 데이터만 추출하는 기법
○ Open API(Rest API)를 제공하는 서비스에 Open API를 호출해서,
받은 데이터 중 필요한 데이터만 추출하는 기법
○ Selenium등 브라우저를 프로그래밍으로 조작해서, 필요한 데이터만 추출하는 기법
● 웹상의 정보들을 탐색하고 수집하는 작업을 의미한다. 규칙에 따라 자동으로 웹 문서를
탐색하는 컴퓨터 프로그램, 웹 크롤러(Craweler)를 만들었다.
크롤러는 인터넷을 돌아다니며 여러 웹 사이트에 접속합니다. 그리고 페이지의 내용과
링크의 복사본을 생성하여 다운로드하고 요약본을 만듭니다. 그리고 검색 시 유용한
정보만을 노출하도록 검색 색인을 붙이죠. 이는 도서관에서 책을 찾기 위해 도서의 주제,
제목 등에 따라 분류 기준을 구성하는 것과 비슷한 작업입니다.Web Crawler
- 웹 크롤러란 자동화된 방법으로 웹(Web)에서 다양한 정보를 수집하는 소프트웨어
- 원하는 서비스에서 원하는 정보를 편하게 얻어올 수 있다.
- 언어를 막론하고 구현할 수 있지만, 주로 Python을 이용한다.
웹 스크래핑(Web Scraping)
웹 스크래핑은 특정 웹 사이트나 페이지에서 필요한 데이터를 자동으로 추출해 내는 것을
의미합니다. 웹 스크래핑은 다음과 같이 작동합니다. 원하는 정보를 추출하기 위해
'스크래퍼 봇'이 특정 웹 사이트에 콘텐츠를 다운로드하기 위한 HTTP GET요청을 보냅니다.
사이트가 이에 응답하면 스크래퍼는 HTML 문서를 분석하여 특정 패턴을 지닌 데이터를 뽑아
냅니다. 그리고 추출된 데이터를 원하는 대로 사용할 수 있도록 데이터베이스에 저장합니다.
웹 스크래핑은 자동으로 수집된 특정 정보가 필요한 분야에서 다양하게 활용되고 있습니다.
금융 및 주식 시장의 경우, 스크래핑 기술을 활용하여 뉴스 정보를 모으기도 하고,
애널리스트들이 투자 자문을 위해 활용할 수 있는 기업 재무제표 정보를 자동으로
수집하기도 합니다. 전자상거래 시장의 경우 경쟁력 확보를 위해 경쟁사 상품의 정보를
수집하고 가격 변동 이슈를 빠르게 파악하기 위해 스크래핑 기술을 활용하기도 합니다.웹 크롤링과 웹 스크래핑의 장점
심층 분석과 실시간 정보 제공에 유용한 "웹 크롤링"
웹 크롤링은 웹상을 돌아다니며 방대한 양의 정보를 수직하기 때문에 특정 키워드에 대한 심층 분석이 필요할 때 유용합니다. 또한 크롤러는 실시간 정보 수집을 위해 계속해서 작동하므로 자주 변화하는 데이터를 파악하기 좋습니다.
정확한 정보를 요구할 때 쓰이는 "웹 스크래핑"
웹 스크래핑은 특정 사이트나 페이지에 대한 정보를 찾는데 집중하므로 데이터 포인터를 정확히 잡고 확실한 정보만을 수집할 수 있다는 점에서 유용합니다. 장기적으로 서비스 대역폭이나 비용을 절약할 수 있다는 장점이 있습니다.
크롤링(crawling)과 스크래핑(scraping)의 차이
○ 웹 크롤링 : 웹 크롤러(자동화 봇)가 일정 규칙으로 웹페이지를 브라우징 하는 것
○ 웹 스크래핑 : 웹 사이트 상에서 원하는 정보를 추출하는 기술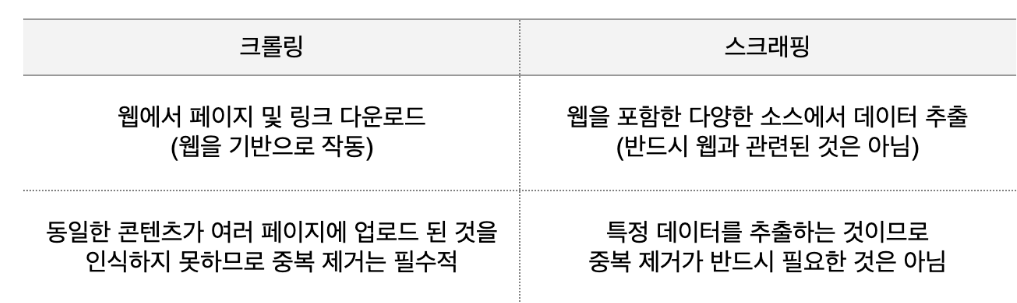

최선을 다하자!!