Auto_increment
- table에 값이 추가될 때마다 증가하는 값을 미리 설계할 수 있다.
- PK의 자료형이 int라면 설정 가능
create table 테이블명( 컬럼명 int primary key auto_increment, ... );
```sql
create table product(
# auto_increment를 사용하면 숫자가 하나씩 증가
prodnum int primary key auto_increment,
prodname varchar(300) not null,
prodprice int not null,
# regdate 등록시간
regdate datetime
);product 테이블에 '구찌 지우개, 구찌 연필', 100000, 100000만 추가
insert into product(prodname, prodprice)
values('구찌 지우개', 100000);
insert into product(prodname, prodprice)
values('구찌 연필', 100000);검색 select * from product;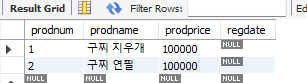
date, datetime 타입
- date
YYYY-MM-DD형태로 삽입 - datetime
YYYY-MM-DD HH:MI:SS형태로 삽입
insert into product(prodname, prodprice, regdate)
values('구찌 공책', 300000, '2022-04-13 19:25:37');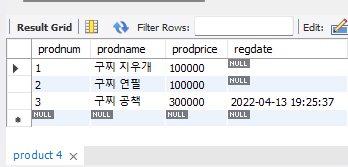
현재시간
now() : 현재시간이 나옴
# 현재시간으로 등록을 나타낼 때
insert into product(prodname, prodprice, regdate)
values('구찌 필통', 250000, now());like 조건식
뒤에 오는 와일드카드 문자열과 비교하여 같다면 참, 다르면 거짓
컬럼 like('와일드카드문자열')와일드 카드
_ : 한글자 ex) '_다솔' : 성은 상관없이 이름이 '다솔'이면 참 % : 모든 것 (%는 0글자도 포함) ex) '정%' : 이름은 상관없이 성이 '정'이면 참 '%A' : 글자수에 상관없이 끝이 'A'이면 참 '_A' : 두글자 중에 끝이 'A'면 참 '_이_' : 세글자중 가운데가 '이'면 참 '_이%' : 두번째 글자가 '이'면 참 '%이_' : 뒤에서 두번째 글자가 '이'면 참 '__이%' : 세번째 글자가 '이'면 참 '_이_%' : 두번째 글자가 '이'이며 3글자 이상이면 참
# Like 조건식
select * from product where prodname like('%구찌%');
select * from product where prodname like('%필%');
함수
단일행 함수
-
행 하나당 결과를 하나 만들어나내는 함수
-
문자함수, 숫자함수, 형변환함수, NULL처리 함수
# 단일행 함수 # 문자함수 # 문자열 연결, 문자열 길이 select concat('He', 'llo'), length('flower') from dual;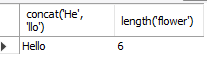
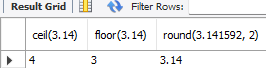
# 숫자함수 # 올림, 버림, 반올림 select ceil(3.14), floor(3.14), round(3.141592, 2) from dual;
```sql
# 널처리 함수( Null 값을 0 등으로 바꾸고 싶을 때)
select ifnull(regdate, '등록날짜 없음') "등록시간"
from product where prodname = '구찌 지우개';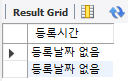
그룹함수
- 여러 행의 데이터들을 받아서 하나의 결과로 도출해주는 함수
- 반드시 하나의 값만을 반환한다.
- NULL 값은 무시된다.
- group by 설정 없이 일반 컬럼들과 기술될 수 없다.
- SUM, MIN, MAX, AVG, COUNT
행을 세는 것들임

# 그룹함수
use world;
select count(Population) from country;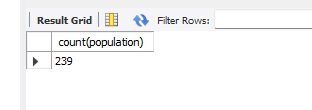
# ifnull을 안쓰면 null은 count하지 않는다.
# null 값도 세고 싶어서 사용
# '????'는 null대신 숫자가 아닌 아무 값넣어서 데이터 갯수 확인
select count(ifnull(IndepYear, '????')) from country;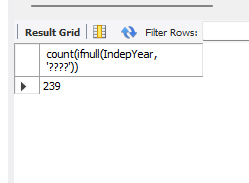
select sum(Population), avg(population),
max(population), min(population) from country;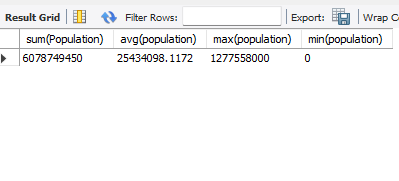
● 단축키 : Ctrl + D : 바로 아래로 복사 # 대륙별 총 인구수
select Continent 대륙, sum(population) "총 인구수"
from country group by Continent; 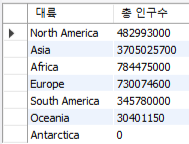
# 대륙별로 정렬
# 여기서 order by 1, 2는 검색된 결과의 1번째 컬럼, 2번째 컬름을 뜻한다.
# 즉, 그 컬럼들을 기준으로 정렬한다는 뜻이다.
select Continent 대륙, Region 지역, sum(population) "총 인구수"
from country group by Continent, Region order by 1,2 desc;group by
-
그룹함수를 적용시킬
파트(범위)를 나누는 문법 -
GROUP BY절의 의미는 그룹 함수를 GROUP BY절에 지정된 컬럼의 값이 같은 행에 대해서 통계 정보를 계산하라는 의미
group by 컬럼1, 컬럼2, ... → 컬럼1로 그룹짓고, 그 내부에서 컬럼2로 그룹짓고, ...select Continent 대륙, Region 지역, sum(population) "총 인구수" from country group by Continent, Region;
having 조건절
● group by를 통해 그룹을 짓고 구해진 결과가 있을 때 각 그룹에
조건을 부여할 때 사용하는 문법
● where과 비슷한 개념으로 조건 제한
● 집계 함수에 대해서 조건 제한하는 편리한 개념
● having절은 반드시 group by절 다음에 나와야 한다.where절과 having절의 차이
- where절은 각 데이터들에게 적용되는 조건을 설정, 조건식에 그룹함수 사용불가
- having절은 각 그룹에게 적용되는 조건을 설정, 조건식에 그룹함수 사용가능
select countrycode, max(population) from city
group by countrycode having max(population) > 8000000;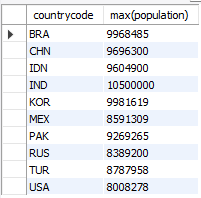
order by
● 검색 결과를 정렬하는 문법
● SELECT로 데이터를 조회할 때, ORDER BY를 추가하여 지정된 컬럼을 기준으로 정렬 order by 컬럼1 [정렬기준], 컬럼2 [정렬기준], ...
→ 컬럼1 기준으로 정렬, 그 내부에서 컬럼2 기준으로 정렬, ...[정렬기준]
생략시 오름차순
ASC : 오름차순
DESC : 내림차순
● 오름차순 정렬 SELECT * FROM 테이블 ORDER BY 컬럼1 ASC;● 오름차순 정렬(ASC 생략) select * from 테이블 order by 컬럼1;● 내림차순 정렬 select * from 테이블 order by 컬럼1 DESC;● 여러 컬럼으로 정렬 select * from 테이블명 order by 컬럼1 [, 컬럼2, 컬럼3, ...];select문
● select 컬럼1, 컬럼2, ... from 테이블명
● where 조건식 group by 컬럼1, 컬럼2, ...
● having 조건식 order by 컬럼1, 컬럼2, ...limit
● 검색된 결과의 개수와 위치를 제한하는 문법
● Oracle에는 존재하지 않는다.
select문 limit 정수(n);
→ 검색된 결과 맨 위에서 n개만 추출
select문 limit(n), 정수(m);
→ 검색된 결과의 n번째부터 m개만 추출 # 행 데이터 10개만 조회하기
SELECT title, content, writer FROM board LIMIT 10; # 11번째 ~ 20번째 행 데이터 조회
SELECT title, content, writer FROM board LIMIT 10, 10;연습
● 대륙별로 평균 gnp 검색select avg(gnp) from country group by Continent; 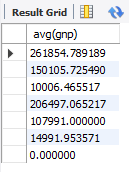
● gnp 평균이 100000 이상인 지역들의 지역명, gnp 최대값, gnp 최소값, gnp 평균 검색# group by를 사용하고 조건문을 사용할거면 having을 사용해야 한다.
select Region 지역명, max(gnp), min(gnp), avg(gnp) from country
group by Region having avg(gnp) > 100000;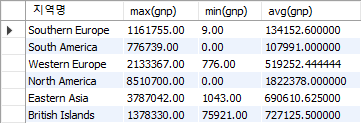
● 대륙별 평균 인구를 출력하되 15000000명을 넘는 대륙만 검색 select Continent 대륙, avg(Population) "평균 인구"
from country where population > 150000000 group by Continent order by 1 asc;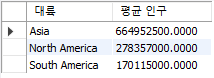
● 인구수가 2000만명을 넘는 나라들의 평균 넓이가 2000000 제곱km를 넘는 대륙들만 검색 select Continent 대륙 from country where population > 20000000
group by Continent having avg(SurfaceArea) > 2000000;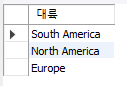
● 대륙별, 그리고 지역별로 나라들의 평균 수명 검색 select Continent 대륙별, Region 지역별, avg(LifeExpectancy) "평균 수명"
from country group by Continent, Region order by 1,2;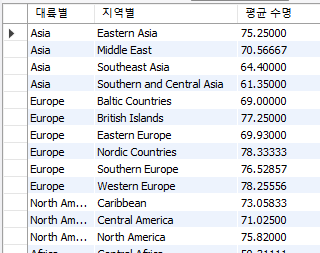

최선을 다하자!!