
Generic(제네릭) class
- 자료형을 선언할 때 정하지 않고, 객체를 생성할 때 정하는 기법
즉,클래스그리고메소드에서 사용할 때 데이터 타입을 나중에 확정하는 기법이다. 인스턴스를 생성할 때나 메소드를 호출할 때 정한다는의미이다. - 매개변수가 값과 관련되어 있다면 제네릭은 데이터의 타입과 관련이 있다.
- 제네릭을 사용하면 객체의 타입을 컴파일 타임에 체크할 수 있어서
타입 안정성을 높이고 형변환의 번거로움이 줄어든다는 장점이 있다.
타입 안정성
- 의도하지 않은
타입의 객체가 저장되는 것을 막는다.- 저장된 객체를 꺼내올 때
다른 타입으로 잘못 형변환하면 발생할 수 있는 오류를 줄인다.
목적
- 이 클래스를 사용할 사람에게 <>안에 있는거를 사용하라고 알려주는 것
- 이걸보고 요소관련된걸 써야는지 알고 요소로 사용될 타입을 결정
<키워드>
E : Element
N : Number
T : Type
K : Key
V : Value1. 제네릭 클래스
클래스 내부에서 사용될 자료형을 지정한다.
class 클래스명<키워드> {
내부에서 키워드를 타입으로 사용 Wrapper 클래스를 사용하는 이유
기본형 타입의 값을 객체로 다루어야 할 때
기본형 타입이 아닌 객체로 값을 저장해야 할 때
매개변수로 객체를 넘길 때(특히 Object o)
객체간의 비교가 필요할 때가능
}
public class GClassTest<T> {
T data;
T getData() {
return data;
}
}
메인==>
// GClassTest<T> ← 타입
GClassTest<Integer> obj = new GClassTest<Integer>();
obj.data = 10; // 오토박싱
System.out.println(obj.getData() + 5); // 15가 나옴(Integer이지만 연산이 가능)2. 제네릭 메소드
메소드 내부에서 사용될 자료형을 지정한다.
<키워드>리턴타입 메소드명(){
내부에서 키워드를 타입으로 사용 가능
}
public class GMethod_Test {
// 제네릭 메소드
// <키워드> 리턴타입 메소드명()
<T>T f(T data) {
System.out.println(data);
return data;
}
}
메인==>
GMethod_Test obj2 = new GMethod_Test();
// <T>T f(T data) → 굳이 할 필요가 없다.
obj2.<String>f("Hello");
// 제네릭 메소드는 보통 키워드를 유추할 수 있기 때문에
따로 명시적으로 작성해주지 않아도 된다.
obj2.f(10);3. 제네릭 인터페이스
인터페이스 내부에서 사용될 자료형을 지정한다.
interface 인터페이스명<키워드>{
내부에서 키워드를 타입으로 사용 가능
}
public interface GInter_Test<N1, N2> {
public abstract N1 add(N1 num1, N1 num2);
// 제네릭은 타입이 다르다고 확신할 수 없기 때문에 오버로딩 불가능
// public abstract N2 add(N2 num1, N2 num2);
public abstract N2 div(N2 num1, N2 num2);
메인==>
GInter_Test<Integer, Double> obj3 = new GInter_Test<Integer, Double>() {
@Override
public Double div(Double num1, Double num2) {
return num1 / num2;
}
@Override
public Integer add(Integer num1, Integer num2) {
return num1 + num2;
}
}; <BTOB>는 임시로 정해놓은 키워드
// generic 1-1
public class Storage<BTOB> {
// 아직은 타입을 알 수 없지만 나중에 만들때 알 수 있다.
// 지금은 임시로 만들어놓은 상태
BTOB data;
} // 1-2
// 이 클래스를 사용할 사람에게 <>안에 있는거를 사용하라고 알려주는것
// 제네릭 클래스
public class GClassTest<T> {
T data;
T getData() {
return data;
}
} // Generic 1-3
public class GMethod_Test {
// 제네릭 메소드
// <키워드> 리턴타입 메소드명()
<T>T f(T data) {
System.out.println(data);
return data;
}
} // generic 1-4
public interface GInter_Test<N1, N2> {
public abstract N1 add(N1 num1, N1 num2);
// 제네릭은 타입이 다르다고 확신할 수 없기 때문에 오버로딩 불가능
// public abstract N2 add(N2 num1, N2 num2);
public abstract N2 div(N2 num1, N2 num2);
} import java.util.Scanner;
// generic 1-5
public class Generic_Main {
public static void main(String[] args) {
// Storage를 생성하면 자동으로 <BTOB>가 붙어서 나온다.
// Storage<BTOB> obj = new Storage<BTOB>();
// 여기서 <BTOB> → <String>으로 바꿔주면 변한다.
// Storage<String> obj = new Storage<String>();
// obj.data = "두번째 고백";
// Storage<Scanner> obj2 = new Storage<Scanner>();
// 아예 Scanner타입으로 바뀌기 때문에 다운 케스팅이 필요가 없다.
// 1-2
// GClassTest<T> ← 타입
GClassTest<Integer> obj = new GClassTest<Integer>();
obj.data = 10; // 오토박싱
System.out.println(obj.getData() + 5); // 15가 나옴(Integer이지만 연산이 가능)
// 1-3
GMethod_Test obj2 = new GMethod_Test();
// <T>T f(T data) → 굳이 할 필요가 없다.
obj2.<String>f("Hello");
// 제네릭 메소드는 보통 키워드를 유추할 수 있기 때문에 따로 명시적으로 작성해주지 않아도 된다.
obj2.f(10);
// 1-4
GInter_Test<Integer, Double> obj3 = new GInter_Test<Integer, Double>() {
@Override
public Double div(Double num1, Double num2) {
return num1 / num2;
}
@Override
public Integer add(Integer num1, Integer num2) {
return num1 + num2;
}
};
}
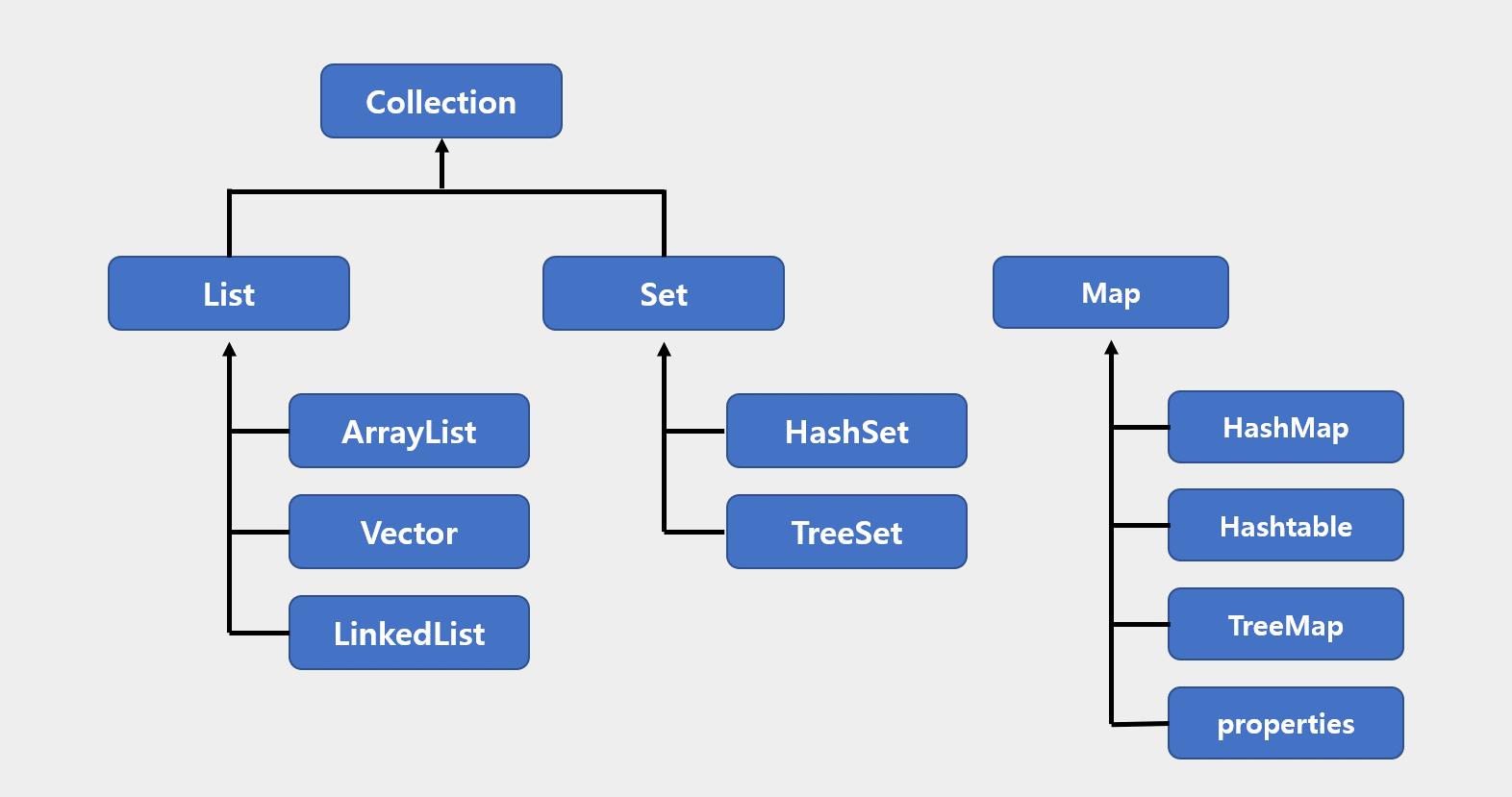
}컬렉션 프레임워크
많은 데이터들을 쉽고 효과적으로 관리할 수 있는 표준화된 방법을 제공하는 클래스 및 인터페이스의 집합, 자바에서 대표적인 컬렉션 인터페이스
→ 자료구조
자료구조
데이터의 집합을 효율적으로 관리하기 위한 데이터 구조
자료구조의 종류
선형 구조
- 배열(Array)
아파트 호수 구조(101동, 102동)
가장 일반적인 자료구조로 인덱스에 대응하는 데이터 구조
- 연결 리스트(LinkedList)
지하철 연결칸 구조
각 노드가 데이터와 포틴트를 가지고 한 줄로 연결되어 있는 구조
- 스택(Stack)
밑이 막혀있는 통구조
후입선출(LIFO: Last Input First Output) 자료구조
나중에 들어온 자료를 먼저 사용하는 자료구조
- 큐(Queue)
앞 뒤가 뚫려있는 터널 구조
선입선출(FIFO: First Input First Output) 자료구조
먼저 들어온 자료를 먼저 사용하는 자료구조
비선형 구조
- 트리(Tree)
회사 조직도
부모 노드 밑에 여러개의 자식 노드가 연결되고 또 연결되는 구조
List
순서가 있는 데이터의 집합으로 데이터 중복을 허용한다.
구현 클래스 : ArrayList, LinkedList, Stack, Vector 등
Set
순서를 유지하지 않는 데이터 집합으로 데이터 중복 허용하지 않는다.
구현 클래스 : HashSet, LinkedHashSet, TreeSet 등
Map
키(key)와 값(value)의 쌍으로 이루어진 데이터 집합으로 순서는 유지되지 않으며, 키는 중복을 허용하지 않고, 값은 중복을 허용한다.
구현 클래스 : HashMap, TreeMap, LinkedHashMap 등
컬렉션 프레임워크를 사용하는 가장 큰 이유
실행중에 크기를 변경할 수 없는 배열과 달리 실행중에 데이터의 크기를 동적으로 마음 데로 변경이 가능하다. 즉, 이것은 실행중 데이터의 삽입/수정/삭제/추가에 대한유연성이 높다는 것
List
- 순서가 있는 데이터의 집합으로 데이터 중복을 허용한다.
- List는 중복을 허용하고 순서를 보장하며 데이터를 보관할 때 사용된다.
List extends Collectoion
구현 클래스
- ArrayList
- LinkedList
- Vector
Set extends Collection
구현클래스
- HashSet
- TreeSet
언제 Set 또는 List를 사용해야 할까요?
- 저장되는 데이터의 순서를 보장해야한다면 List를 사용해야 합니다.
- contains(element)는 Collection에 데이터가 존재하는지 확인하는 메소드입니다.
- List의 contains 실행 속도는 O(n)이지만, Set는 O(1)으로 매우 빠릅니다.
- 탐색이 잦다면 Set를 고려해볼 수 있습니다. 데이터가 많지 않다면 성능보다, 구조가 간단한 List를 고려해볼 수 있습니다.
- 중복을 허용하지 않는 Collection이 필요하다면 Set를 고려해볼 수 있습니다.
ArrayList
- 컬렉션 클래스 중 가장 많이 사용되는 클래스
- 배열을 이용해서 값을 저장한다.
- 인덱스를 이용해서 각 요소에 빠르게 접근 가능하지만 크기를 변경시키기 위해서는 새로운 배열을 생성하고 기존의 값들을 옮겨야 하므로 느리다.
- 배열은 처음에 몇 칸을 할당할지 고정해야 하지만 ArrayList는 값을 넣는 만큼 자동으로 늘어난다.
사용방법 및 메소드 정리
// 객체 생성(List는 인터페이스이므로 상속한 자식 클래스로 객체를 생성해야 한다.)
ArrayList<Integer> list = new ArrayList<>();
// 마지막에 데이터 추가
list.add(1);
// 해당 인덱스 위치에 데이터를 삽입한다(중간삽입).
list.add(0, 20);
list.addAll(다른컬렉션명(List, Set..); // 다른 리스트 더하기
list.addAll(Arrays.asList(배열명)); // 배열 더하기
list.set(0, 10); // 해당 인덱스 위치의 값 수정
list.get(0); // 해당 인덱스의 값 읽기
list.remove(0); // 해당 인덱스의 데이터 삭제
list.size(); // 컬렉션의 요소(아이템) 개수 확인
list.clear(); // 모든 데이터 삭제(클리어)
list.toString(); // 컬렉션의 값을 문자열로 출력
list.isEmpty(); // List가 비었는지 확인ArrayList<데이터형> 리스트명 = new ArrayList<데이터형>();
ArrayList는 대량의 데이터 검색에 유리하다.
LinkedList<데이터형> 리스트명 = new LinkedList<데이터형>();
LinkedList는 대량의 데이터 삽입, 삭제에 유리하다.
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
public class List {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>(); // List 선언(ArrayList)
LinkedList<String> list2 = new LinkedList<String>();// List 선언(LinkedList)
list2.add("E");
list.add("A");
list.add("B");
list.add("C"); // List 추가
list.add(0, "D"); // 0번째에 D값을 추가(동일한 것이 있을 경우 밀어냄)
System.out.println("List 값 확인 : " + list);
System.out.println("List 인덱스 값 확인 : " + list.get(0));
list.remove(2); // List 삭제(인덱스)
list.remove("B"); // List 삭제(값으로)
list.set(0, "Z"); // List 값 변경(인덱스, "변경할 값")
System.out.println("List 크기 확인 : " + list.size());
System.out.println("List 안에 특정 값 들었는지 확인 : " + list.contains("B"));
System.out.println("List 안에 아무것도 들지 않았는지 확인 : " + list.isEmpty());
list.addAll(list2); // List에 다른 List 더하기
String[] arr = {"ARRAY"};
list.addAll(Arrays.asList(arr)); // 배열을 리스트로 더하기
System.out.println("List 안에 다른 리스트 더하기 : " + list);
}
} import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
public class ListExam {
public static void main(String[] args) {
// 기본 배열을 살펴보자
int[] arr = new int[5];
arr = new int[] {1,2,3,4,5};
System.out.println(Arrays.toString(arr));
// 위와 같이 5개의 배열을 실행중에 추가하고 싶어도 불가
// arr[5] = 10;
// 자료구조가 생겨났다. 원시타입 변수는 자료구조로 사용할 수 없다.
// 클래스 자료만 넣을 수 있다.
// ArrayList<int> list = new ArrayList<>();
// 그래서 원시타입 변수를 사용하고 싶으면 대신 Wrapper 클래스를 이용한다.
ArrayList<Integer> list = new ArrayList<>();
System.out.println(list.size()); // 출력 : 0 ← 데이터는 없음
// 리스트에 값을 추가하여 크기가 자동으로 늘어난다.
list.add(Integer.valueOf(10)); // 정석
list.add(20); // 자동형변환
System.out.println(list.size()); // 출력 : 2
System.out.println(list.toString());// 출력 : [10, 20]
// 현재 크기 내의 인덱스 값을 변경하는 것이 가능하다.
list.set(0, 50); // 첫번째 값을 50으로 바꾼다.
System.out.println(list.toString());
// list.set(2, 100); // 범위를 벗어나서 오류
System.out.println(list.toString());
// 리스트의 특정 index의 값을 읽어오는 방법
System.out.println(list.get(0));
System.out.println("====================");
// 리스트의 값을 순서대로 읽기
// 컬렉션을 반복하는 방법1
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
// 컬렉션을 반복하는 방법2(Iterator 이용한 방법)
for (Iterator iterator = list.iterator(); iterator.hasNext() == true;) {
Integer item = (Integer) iterator.next();
System.out.println(item);
}
// 컬렉션을 반복하는 방법3(for each)
for(Integer item : list) {
System.out.println(item);
}
// 그리고 삭제도 가능하다.
list.remove(1);
System.out.println(list);
// 마지막으로 저장된 모든 객체를 삭제(클리어)
list.add(30);
System.out.println(list);
list.clear();
System.out.println(list);
}
}- 오름차순, 내림차순
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
public class ArrayListExam {
public static void main(String[] args) {
// ArrayList 준비
ArrayList<String> list = new ArrayList<>(Arrays.asList("C", "A", "B", "a"));
System.out.println("원본 : " + list); // [C, A, B, a]
// Collections.sort() 정렬
// 오름차순으로 정렬
Collections.sort(list);
System.out.println("오름차순 : " + list); // [A, B, C, a]
// 내림차순으로 정렬
Collections.sort(list, Collections.reverseOrder());
System.out.println("내림차순 : " + list); // [a, C, B, A]
// 대소문자 구분없이 오름차순
Collections.sort(list, String.CASE_INSENSITIVE_ORDER);
System.out.println("대소문자 구분없이 오름차순 : " + list); // [a, A, B, C]
// 대소문자 구분없이 내림차순
Collections.sort(list, Collections.reverseOrder(String.CASE_INSENSITIVE_ORDER));
System.out.println("대소문자 구분없이 내림차순 : " + list); // [C, B, a, A]
}
}반복문
// list 컬렉션을 반복하는 방법 1 (거의 사용안함)
for (int i = 0; i < list.size(); i++) {
Integer item = list.get(i);
System.out.println(item);
} // list 컬렉션을 반복하는 방법 2 → Iterator사용해서 하는 방법
for (Iterator<Integer> iter = list.iterator(); iter.hasNext();) {
Integer item = (Integer)iter.next();
System.out.println(item);
} → 순회하며 대입할 대상을 Iterator의 hasNext()를 이용하여 순회
Iterator을 구현하면 사용 가능(Iterator를 구현한 객체만 가능함)
단, 예외로 배열(Array)의 경우, 향상된 For문을 입력하면 컴파일러가
기존의 For문으로 변환시켜줌
Iterator<String> iterator = cars.iterator();
while(iterator.hasNext()) {
String str = iterator.next();
System.out.println(str);
}
// list 컬렉션을 반복하는 방법 3
● Enhanced For Loop
for(대입받을 변수 정의 : 배열) {}
○ 배열 값이 대입받는 변수에 대입되어 For Loop의 Body 코드가 실행됨.
■ 장점 : 배열의 크기를 조사할 필요가 없다.
반복문 본연의 반복문 구현에 집중하여 구현 할 수 있다.
■ 단점 : 배열에서만 사용 가능하고, 배열의 값을 변경하지 못하는 단점이 있습니다.
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class IteratorExam {
public static void main(String[] args) {
ArrayList<String> cars = new ArrayList<>();
cars.add("벤츠");
cars.add("람보르기니");
cars.add("롤스로이드");
cars.add("페라리");
// for문 이용
for (Iterator<String> iterator = cars.iterator(); iterator.hasNext();) {
String hi = (String) iterator.next();
System.out.println(hi);
}
System.out.println("====================");
// iterator 획득
Iterator<String> iterator = cars.iterator();
// while문을 사용한 경우
while(iterator.hasNext()) {
String str = iterator.next();
System.out.println(str);
}
System.out.println("====================");
// for-each문을 사용한 경우
for(String str : cars) {
System.out.println(str);
}
System.out.println("====================");
Set<String> phone = new HashSet<>();
phone.add("s10");
phone.add("z플랩");
phone.add("v30");
phone.add("아이폰");
// while문을 사용한 경우
Iterator<String> iterator2 = phone.iterator();
while(iterator2.hasNext()) {
System.out.println("phone : " + iterator2.next());
}
System.out.println("====================");
// for-each문을 사용한 경우(보통 이걸 사용)
for(String handphone : phone) {
System.out.println("phone : " + handphone);
}
System.out.println("====================");
}
}import java.util.ArrayList;
import java.util.Iterator;
public class Array_Test1 {
public static void main(String[] args) {
ArrayList<String> arr1 = new ArrayList<String>();
// 요소 추가하기
arr1.add("Hello");
arr1.add("Java!");
arr1.add("Very");
arr1.add("Sleepy");
// 이 내부에서 toString을 재정의가 되어 있다.
// ArrayList 구조 간단히 파악하기
System.out.println(arr1);
System.out.println(arr1.get(0));
// 수정하기
arr1.set(3, "Happy");
System.out.println(arr1);
// ArrayList의 요소 개수(길이)
for (int i = 0; i < arr1.size(); i++) {
// 요소 가져오기
System.out.println(arr1.get(i));
}
System.out.println("=======================");
// 삭제
arr1.remove(2);
System.out.println(arr1);
System.out.println("========================");
// for-Iterator문 사용
for (Iterator<String> iterator = arr1.iterator(); iterator.hasNext();) {
String item = (String) iterator.next();
System.out.println(item);
}
// for-each문
for(String item2 : arr1) {
System.out.println(item2);
}
}
} ● ArrayList에 객체를 생성할 경우 import java.util.ArrayList;
import java.util.Iterator;
class User {
String userId;
public User(String userId) {
this.userId = userId;
}
@Override
public String toString() {
return "아이디 : " + this.userId ;
}
@Override
public boolean equals(Object obj) {
if(obj instanceof User) {
User target = (User)obj;
if(this.userId.equals(target.userId)) {
return true;
}
return false;
}
return false;
}
@Override
public int hashCode() {
return this.userId.length();
}
}
public class ArrayList_Test2 {
public static void main(String[] args) {
ArrayList<Integer> arr1 = new ArrayList<>();
arr1.add(10);
arr1.add(20);
arr1.add(30);
arr1.add(40);
arr1.add(50);
// 40을 remove(40)으로 삭제하려면 remove(int index)가 아니라
// remove(Object o)로 해줘야 객체로 받아서 삭제해야 한다.
// remove(int index)는 40이 int타입이라 int index가 와야 하는데
// 40이 int니 자동으로 int index로 되서 없는 index를 불러오니 오류발생
// arr1.remove(40);
// System.out.println(arr1);
// Object o에서 객체를 가져오라고 했으니
// 40을 박싱해서 객체화 시켜준다.
arr1.remove((Integer)40);
System.out.println(arr1);
// 클래스 User도 하나의 타입이라고 볼 수 있어서 ArrayList<User> 가능하다.
ArrayList<User> arr2 = new ArrayList<User>();
arr2.add(new User("apple"));
arr2.add(new User("banana"));
arr2.add(new User("cherry"));
// class User에 toString하지 않으면 해쉬코드가 나온다.
// class User에 toString에서 오버라이딩해주면 제대로 나온다.
System.out.println(arr2);
for (Iterator<User> iterator = arr2.iterator(); iterator.hasNext();) {
User user = (User) iterator.next();
System.out.println(user);
}
// 여기서 User(banana)라는 객체를 받아서 삭제하려고 해서
// arr2.remove(new User("banana"));로 해주면
// remove(new User("babana"))는 add(new User("banana")는
// 아직 여기서는 equals가 주소값을 물어보고 있어서
// 동위객체로써 같은 취급을 해주지만 다른 객체라서 삭제는 안된다.
// 여기서 class User에 equals를 오버라이딩해서 ("banana")를 값을 보고
// 논리적 동일시해서 같은 취급해줘서 삭제가 된다.
arr2.remove(new User("banana"));
System.out.println(arr2);
}
}Stack
- 먼저 들어간 자료가 나중에 나옴 LIFO(Last In First Out) 구조
- 인터럽트처리, 수식의 계산, 서브루틴의 복귀 번지 저장 등에 쓰임
- 그래프의 깊이 우선 탐색(DFS)에서 사용
- 재귀적(Recursion) 함수를 호출 할 때 사용
Stack 선언
import java.util.Stack; //import
Stack<Integer> stack = new Stack<>(); // int형 스택 선언
Stack<String> stack = new Stack<>(); // String형 스택 선언Stack 값 추가
stack.push(1); // stack에 값 1 추가
stack.push(2); // stack에 값 2 추가
stack.push(3); // stack에 값 3 추가Stack 값 삭제
stack.push(1); // stack에 값 1 추가
stack.push(2); // stack에 값 2 추가
stack.push(3); // stack에 값 3 추가
stack.pop(); // stack에 값 제거
// 뒤에서 부터 한개씩 사라짐
// 후입선출이라서 나중에 들어온 것이 먼저 나간다.
stack.pop();
System.out.println(stack); // 출력 : [1, 2, 3, 4]
stack.pop();
System.out.println(stack); // 출력 : [1, 2, 3]
stack.clear(); // stack의 전체 값 제거 (초기화)Stack의 가장 상단의 값 출력
stack.push(1); // stack에 값 1 추가
stack.push(2); // stack에 값 2 추가
stack.push(3); // stack에 값 3 추가
stack.peek(); // stack의 가장 상단의 값 출력
System.out.println(stack.peek());
→ 먼저 push로 집어 넣은것은 가장 아래로 가고 가장 마지막에 넣은게 상단에 있는다.Stack의 기타 메서드
stack.push(1); // stack에 값 1 추가
stack.push(2); // stack에 값 2 추가
stack.size(); // stack의 크기 출력 : 2
stack.empty(); // stack이 비어있는제 check (비어있다면 true)
stack.contains(1) // stack에 1이 있는지 check (있다면 true) import java.util.Stack;
public class Stack_Exam {
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
// Stack 값 추가
stack.push(1);
stack.push(2);
stack.push(3);
stack.push(4);
stack.push(5);
// Stack 값 삭제
// 뒤에서 부터 한개씩 사라짐
// 후입선출이라서 나중에 들어온 것이 먼저 나간다.
stack.pop();
System.out.println(stack); // 출력 : [1, 2, 3, 4]
stack.pop();
System.out.println(stack); // 출력 : [1, 2, 3]
// stack.clear();
// Stack의 상단의 값 출력
// 밑으로 쌓이는 구조이기 때문에 1이 가장먼저 들어가고, 그 다음이 2, 그 다음이 3
// 4, 5는 삭제해서 3이 출력된다.
System.out.println(stack.peek());
// Stack의 기타 메소드
System.out.println(stack.size());
System.out.println(stack.isEmpty());
System.out.println(stack.contains(1));
}
}큐(Queue)
Queue의 사전적 의미는 무엇을 기다리는 사람, 차량 등의 줄 혹은 줄을 서서
기다리는 것을 의미하는데 이처럼 줄을 지어 순서대로 처리되는 것이 큐라는 자료구조입니다.
큐는 데이터를 일시적으로 쌓아두기 위한 자료구조로 스택과는 다르게
FIFO(First In First Out)의 형태를 가집니다. FIFO 형태는 뜻 그대로 먼저 들어온 데이터가
가장 먼저 나가는 구조를 말합니다.
Queue 사용법
Queue 선언
import java.util.LinkedList; // import
import java.util.Queue; // import
Queue<Integer> queue = new LinkedList<>(); // int형 queue 선언, linkedlist 이용
Queue<String> queue = new LinkedList<>(); // String형 queue 선언, linkedlist 이용
자바에서 큐는 LinkedList를 활용하여 생성해야 합니다.
그렇기에 Queue와 LinkedList가 다 import되어 있어야 사용이 가능합니다.
Queue<Element> queue = new LinkedList<>()와 같이 선언해주면 됩니다.Queue 값 추가
Queue<Integer> stack = new LinkedList<>(); //int형 queue 선언
queue.add(1); // queue에 값 1 추가
queue.add(2); // queue에 값 2 추가
queue.offer(3); // queue에 값 3 추가 Queue 값 삭제
queue.offer(1); // queue에 값 1 추가
queue.offer(2); // queue에 값 2 추가
queue.offer(3); // queue에 값 3 추가
queue.poll(); // queue에 첫번째 값을 반환하고 제거, 비어있다면 null
queue.remove(); // queue에 첫번째 값 제거
queue.clear(); // queue 초기화Queue 에서 가장 먼저 들어간 값 출력
queue.offer(1); // queue에 값 1 추가
queue.offer(2); // queue에 값 2 추가
queue.offer(3); // queue에 값 3 추가
queue.peek(); // queue의 첫번째 값 참조 import java.util.LinkedList;
import java.util.Queue;
public class Queue_Exam {
public static void main(String[] args) {
// Queue는 LinkedList하고 같이 객체를 생성해야 한다.
Queue<Integer> qu = new LinkedList<>();
// Queue 값 추가
qu.add(1);
qu.add(2);
qu.add(3);
qu.offer(4);
qu.offer(5);
// qu에 첫번째 값을 반환하고 제거, 비어있다면 null
System.out.println(qu.poll());
System.out.println(qu.poll());
System.out.println(qu.peek());
qu.remove();
qu.clear();
}
}