쿼리문을 정리하기에 앞서 SELECT 명령어에서 자칫 헷갈릴 뻔 했던 개념이 있어 기록해본다. SELECT는 필요한 정보를 선택해서 가시적인 (임시의)표를 만들어서 사용자에게 보여주는 선택어라는 것! SELECT-조건문의 연속인 기나긴 쿼리를 보며 '그래서 이걸 뭐 어쩌겠다는거지..?' 라는 생각이 한 번 씩 들었던 것 같다ㅋㅋㅋ 물론 SELECT의 개념을 몰랐던 건 아니지만 스크롤을 한~참을 내리며 쿼리를 해석하다보면 한 번씩 SELECT의 본분?을 잊고ㅋㅋㅋ 혼란에 빠질때가 있었기에 그 개념을 한 번 더 짚고 넘어가는 바이다.
1) HAVING
WHERE과 같은 조건문의 역할을 하지만 WHERE은 집계기능을 사용할 수 없는 반면, HAVING은 가능하다.
SELECT COUNT(CUSTOMERID), COUNTRY
FROM CUSTOMERS
GROUP BY COUNTRY --국가를 기준으로 customerID의 갯수를 나타냄
HAVING COUNT(CUSTOMERID) > 5 --단, cumstomerID의 갯수가 5개 초과하는 것만
ORDER BY COUNT(CUTOMERID) DESC; --customerID 갯수의 내림차순으로 2) MAX(), MIN()
MAX(컬럼이름), MIN(컬럼이름)
-해당 컬럼에서 젤 큰 값, 작은 값을 추출해 보여줌
SELECT MIN(Price) AS SmallestPrice --SELECT 해서 출력 시 다른 컬럼 이름으로 출력
FROM Products;
SELECT MAX(Price) AS LargestPrice
FROM Products;3) IN
이것도 WHERE과 비슷한 조건문인데, 조건에 '속해있는' 값을 도출할 때 유용
SELECT * FROM Customers
WHERE Country IN (SELECT Country FROM Suppliers);
--SUPPLIERS 테이블의 COUNTRY 컬럼에 속해있는(해당 컬럼에도 존재하는)
--COUNTRY 데이터를 가진 CUSTOMER 데이터 추출4) JOIN
두 테이블 간 집합 데이터 추출
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON --교집합 데이터 추출
Orders.CustomerID=Customers.CustomerID;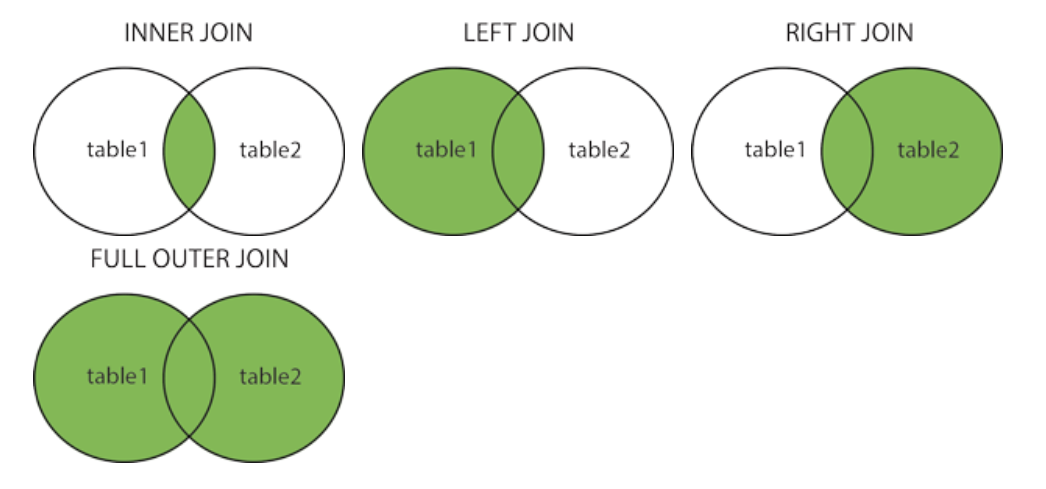
5) SELF JOIN
그냥 join이랑 차이가 뭘까?
SELECT A.CustomerName AS CustomerName1, B.CustomerName AS CustomerName2, A.City
FROM Customers A, Customers B
WHERE A.CustomerID <> B.CustomerID
AND A.City = B.City
ORDER BY A.City;6) UNION
각각의 쿼리에서 나온 데이터를 하나로 합쳐주는 역할이며 중복값은 한 번만 출력된다.
UNION ALL을 사용하면 중복되는 값도 그대로 출력된다.
사용조건
(1) 모든 SELECT 대상은 컬럼의 수가 같아야한다.
(2) 해당 컬럼의 데이터 타입 또한, 비슷해야한다.
(3) ORDER 도 마찬가지
SELECT City, Country FROM Customers
WHERE Country='Germany'
UNION
SELECT City, Country FROM Suppliers
WHERE Country='Germany'
ORDER BY City;7) GROUP BY
데이터를 그룹(컬럼)으로 나눠 추출할 때 사용.
주로 집계 함수와 함께 사용된다. - COUNT(), MAX(), MIN(), SUM(), AVG()
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
ORDER BY COUNT(CustomerID) DESC;위 쿼리를 해석하자면,
Customers 테이블에서 국가별로 CuntomerID의 갯수와 국가이름을 추출하여 CustomerID의 내림차순으로 정렬하라.
8) PARTITION BY
GROUP BY 와 같이 그룹으로 묶어 데이터를 집계하는 함수이지만, 조회된 각 행에 그룹으로 집계된 값을 각각 표시할 때 OVER 절과 함께 PARTITION BY 절을 사용하면 된다.
SELECT empno
, ename
, job
, sal
, SUM(sal) OVER(PARTITION BY job)
FROM emp
WHERE job IN ('MANAGER', 'SALESMAN')
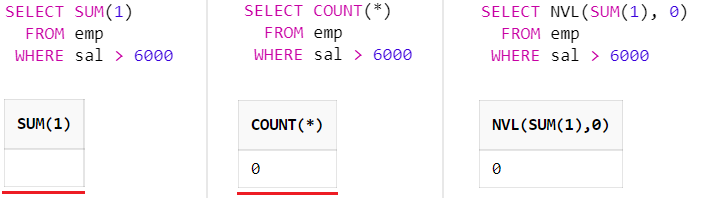
ORDER BY job9) SUM(1)과 SUM(*)의 차이
SUM(1)과 COUNT() 모두 동일하게 조회된 데이터 건수를 반환한다.
데이터가 없을 때 SUM(1)은 NULL을 반환하고 COUNT()는 0을 반환한다.
조회된 데이터가 없을 경우 NULL을 반환받기 원한다면 SUM(1)을 사용하는 것도 효율적이다.
10) DECODE
오라클에서만 지원하는 함수
DECODE (MAIL-컬럼이름, 'N', '네이버', 'G', '구글', '카카오')이걸 JAVA로 바꾸면 아래와 같다.
if(MAIL.equals("N")){
return "네이버";
}else if(MAIL.equals("G")){
return "구글";
}else{
return "카카오";
}11) CASE
DECODE와 달리 비교연산이 가능하다.
CASE [대상값] WHEN [비교값1] THEN [결과1]
WHEN [비교값2] THEN [결과2]
WHEN [비교값3] THEN [결과3]
ELSE [결과4]
END;위 SQL을 DECODE로 바꿔 표현해보면..
DECODE(대상갑,비교값1,결과1,비교값2,결과2,비교값3,결과3,결과4);
또한, 비교연산을 넣은 조건문은 아래와 같다.
SELECT GRADE
CASE WHEN GRADE>=90 THEN 'A+'
WHEN GRADE>=80 THEN AND GRADE<90 THEN 'B+'
WHEN GRADE>=70 THEN AND GRADE<80 THEN 'C+'
ELSE 'F'
FROM SUBJECT12) CONVERT()
데이터 형변환해주는 함수
SELECT CONVERT(NVARCHAR(10),칼럼) AS 칼럼명 FROM MY_TABLE --VARCHAR로 변환
SELECT CONVERT(INT,칼럼) AS 칼럼명 FROM MY_TABLE --INT로 변환
SELECT CONVERT(CHAR,칼럼) AS 칼럼명 FROM MY_TABLE --CHAR로 변환13) REPLACE()
특정 문자열을 원하는 문자로 바꿔주는 함수
REPLACE('문자열' or 열 이름, '바꾸려는 문자열', '바뀔 문자열')그 외 자주 쓰는 함수
LOWER(A) --소문자로 변환
UPPER(a) --대문자로 변환
SUBSTR(x,n,m) --x문자를 n번째부터 m개 추출
INSTR(x,y,n,m) --x문자에서 y를 찾는데, n번째부터 m까지 범위에서 찾고 인덱스 값을 반환한다.
LENGTH(x) --x문자의 길이를 반환
CONCAT(x,y) --x문자와 y문자를 합친다.
RPAD("대상값", "총 문자길이", "채움문자") --문자길이를 기준으로 대상값의 오른쪽으로 문자를 채운다.
LPAD("대상값", "총 문자길이", "채움문자") --문자길이를 기준으로 대상값의 왼쪽으로 문자를 채운다.
TRIM("문자열") --문자열의 양쪽 공백(스페이스바)를 제거한다.
ROUND(x,n) --x숫자를 n+1번째에서 반올림한다.
TRUNC(x,n) --x숫자를 n+1번째 부터 버린다.
TO_NUMBER('문자열') --문자열을 숫자로 변환/실수도 가능
CAST('문자열', AS NUMBER(5)) --문자열을 숫자로 변환/실수 자릿수/올림 지정 가능|| 의 활용
"||"(Concatenation) -> 두 개의 컬럼을 하나로 합쳐서 표현하고자 할 때 쓰는 도구, 두 개의 컬럼 값 사이에 인위의 값을 넣고 싶을 때는 "작은따옴표"를 추가한다.
SELECT LAST_NAME || FIRST_NAME
FROM EMPLOYEES AS "NAME";
SELECT LAST_NAME ||' '|| FIRST_NAME
FROM EMPLOYEES AS "NAME"; -- 성과 이름 사이에 공백 추가할 경우Query 처리순서
(8) SELECT (9) DISTINCT (11) <TOP_specification><select_list>
(1)FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) WITH {CUBE|ROLLUP}
(7) HAVING <having_condition>
(10) ORDER BY <order_by_list>CONFERENCES
- https://www.w3schools.com/sql/sql_having.asp
- https://www.w3schools.com/sql/sql_min_max.asp
- https://www.w3schools.com/sql/sql_in.asp
- https://www.w3schools.com/sql/sql_join.asp
- https://www.w3schools.com/sql/sql_join_self.asp
- https://www.w3schools.com/sql/sql_union.asp
- https://www.w3schools.com/sql/sql_groupby.asp
- https://gent.tistory.com/442
- https://gent.tistory.com/457
- https://hgserver.tistory.com/43 : 여기 쿼리함수 정리 잘돼있음!!!
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=hwanyoy&logNo=140121088630
