
최종정리
Basic 시험이 있는 날이다. 미리 공부를 끝내놓고 드문드문 공부를 하기는 했지만, 합격을 하기 위해서는 이번 정리를 통해서 확실하게 다져놓으려 한다.
그러기 위해서는 무조건 시험위주의 정리를 해보자.
AI분석단계
내가 생각하는 AICE의 Basic 레벨을 AI분석단계를 얼마나 잘 이해하고 이를 활용하는가를 보는 게 중요하다고 생각한다. 그래서 크게 이 부분을 정리하면서 이해하고 다음으로 세세하게 봐야겠다.
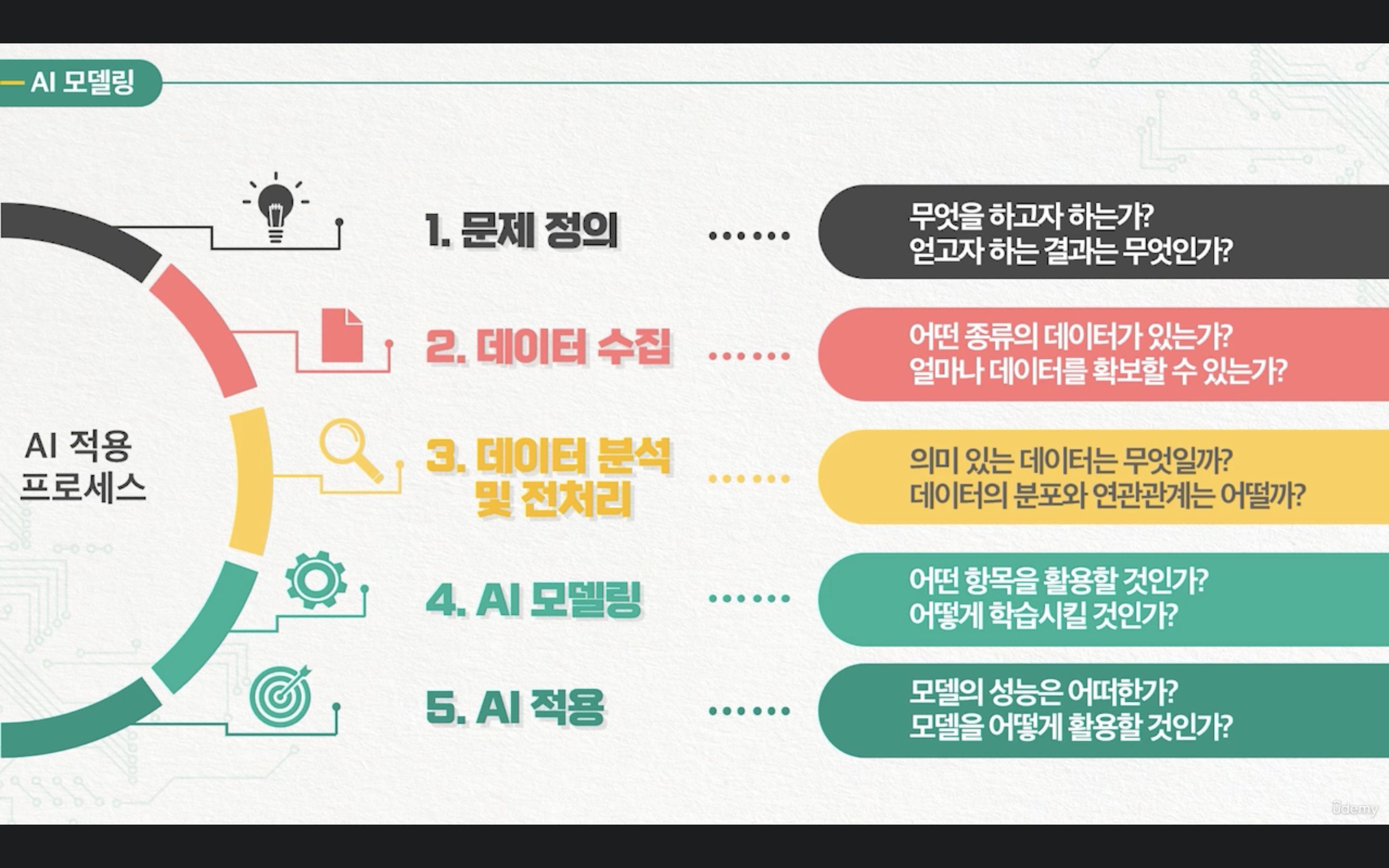
1. 문제정의
문제 정의 단계이다. 문제정의는 문제로 주어진다. 예를 들면
AI 모델링을 통해 무엇을 얻고자 하는지?
어떤 결과를 얻고 싶은지?
와 같은 것들을 문제로 제시하여 우리는 그 결과를 도출하는 과정에 있는 문제들을 풀면 된다. 그렇기 때문에 시험에 들어가면, 문제를 찬찬히 읽어보고, 컬럼들은 어떤 것들이 있는지 확인하고, label이 어떤 컬럼인지까지 이해해야 하는 단계이다.
또한 확인해야 할 것이 문제를 분류해야 한다. 문제가 회귀형(수치형)인지, 분류형인지를 파악하는 것이 중요하다. 회귀형일 경우 원하는 값이 숫자(수치)로 나와야 한다. 분류형일 경우는 말 그대로 값이 어느 분류에 속하는지를 알아야 한다.
2. 데이터 수집
데이터 수집은 다 되어 있다. Basic시험을 볼 때에는 AIDU ez에서 파일만 가져오면 되는 단계라서 어렵지는 않다. 데이터가 어떤 형태로 얼마나 있는지 정도 파악하면 될 거 같다.

원래는 데이터를 가져올 때 위의 사진과 같이 가져온다. 그러나 시험볼 때는 이미 다 셋팅이 되어 있는 상태다.
3. 데이터 분석
데이터 분석 단계에서부터가 시험에서 본격적으로 진행되는 부분이다. 이 단계에서는 의미있는 데이터가 무엇인지를 파악해야 하고, 데이터의 분포나 연간관계에 대해 고민해야 한다.
주로 기본 데이터 분석을 통해 데이터에는 어떤 것들이 있는지 본다. 또한 데이터의 시각화로 히트맵을 통해, 데이터 간의 연간관계를 파악하거나, 박스 차트를 통해 데이터의 이상치나 일반적인 분포를 알 수 있다.
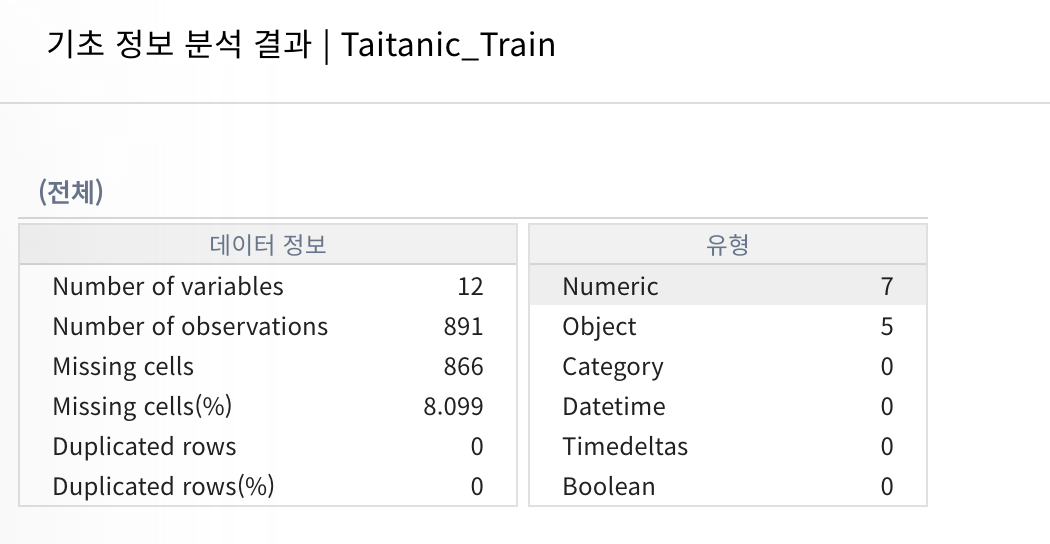
이 사진은 데이터를 기초분석한 사진이다. 컬럼과 컬럼유형, 결측값을 빠르게 파악하는 것이 중요하다.
시험에서는 주로 결측값이나, 중간값 등을 요구하기 때문에 각각의 단어를 나타내는 게 무엇인지 알아야 한다.
+) 데이터 가공
AI 모델링을 하기 전에는 데이터 가공을 해야 한다. 데이터 가공이랑 결측치, 즉 비어있는 값이 없도록 해야 하고, 값이 이상하게 나오지 않도록 조정하는 단계이다. 데이터를 가공하지 않고 모델링을 진행하면 원하는 결과를 도출하기 어렵기 때문이다.
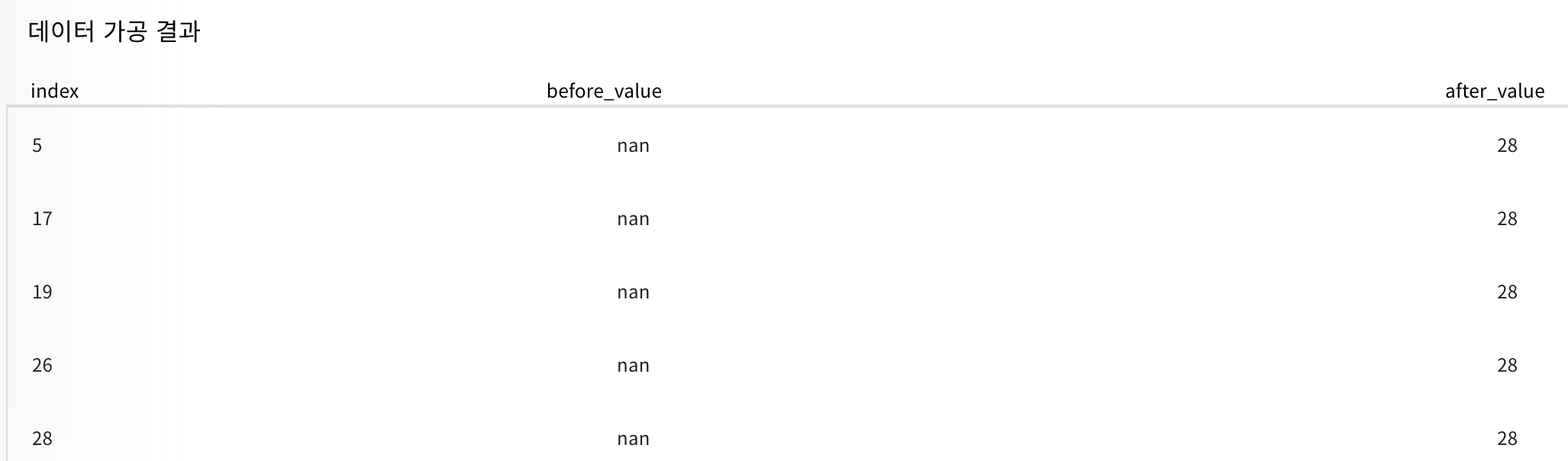
이 사진은 데이터의 결측값을 중간값으로 가공한 사진이다. before_value에 nan이 after_value에서 28로 변했다. 데이터를 가공해서 중간값의 양이 많아짐으로 이 부분을 인지하고 있어야 한다.
4. AI 모델링
AI 모델링에는 여러 학습이 존재한다. 지도학습, 비지도학습, 강화학습이 존재하는데, Basic에서는 지도학습을 통한 모델링을 실시한다. 그래서 과거의 데이터들을 통해서 어떤 결과가 나와야 하는지를 예측해야 한다.
AI 모델링 단계에서는 어떤 항목을 활용하여 딥러닝으로 학습할 것인지, 머신러닝으로 학습할 것인지를 정하는 단계다. 주로 문제정의에서 원하는 label 항목을 적용하여 학습한다.
시험에서는 파라미터는 기본값으로 하고 input 칼럼이나 output 컬럼을 주의하면 될 것 같다. 또한 오차율이나 정확성에 대해 나올 수 있기 때문에 확인을 필수고, 가장 높은 정확성을 띤 epoch에 대해 물어볼 수도 있기 때문에 log를 꼭 읽어봐야 한다.

데이터를 모델링한 차트다. epoch를 진행하면 할수록 오차율이 낮아지고, 정확성은 올라가고 있다.
5. AI 적용
AI 적용은 말 그대로 AI 모델링을 한 것을 적용하는 단계이다. 예를 들면 값을 예측하거나, 값을 넣고 시뮬레이션을 돌려보던가 하여 문제 정의에 대해 원하는 결과를 도출했는지를 확인한다.
시험에서는 주로 시뮬레이션을 돌려보던가, 임의의 값을 넣어 예측을 하던가 한다.

모델링한 AI에 테스트 데이터를 넣고 결과를 예측했다. 이때 Test데이터와 모델링한 데이터의 컬럼이 같아야 함을 알고 있어야 한다.
추가
1. 히트맵
히트맵은 앞서 언급한 것처럼 칼럼 간의 연간관계를 파악하는데 아주 중요한 시각화 자료다. 보는 것은 크게 어렵지 않고, 우하향하는 컬럼을 기준으로 대칭을 이루고 있는 걸 알고 보면 된다.
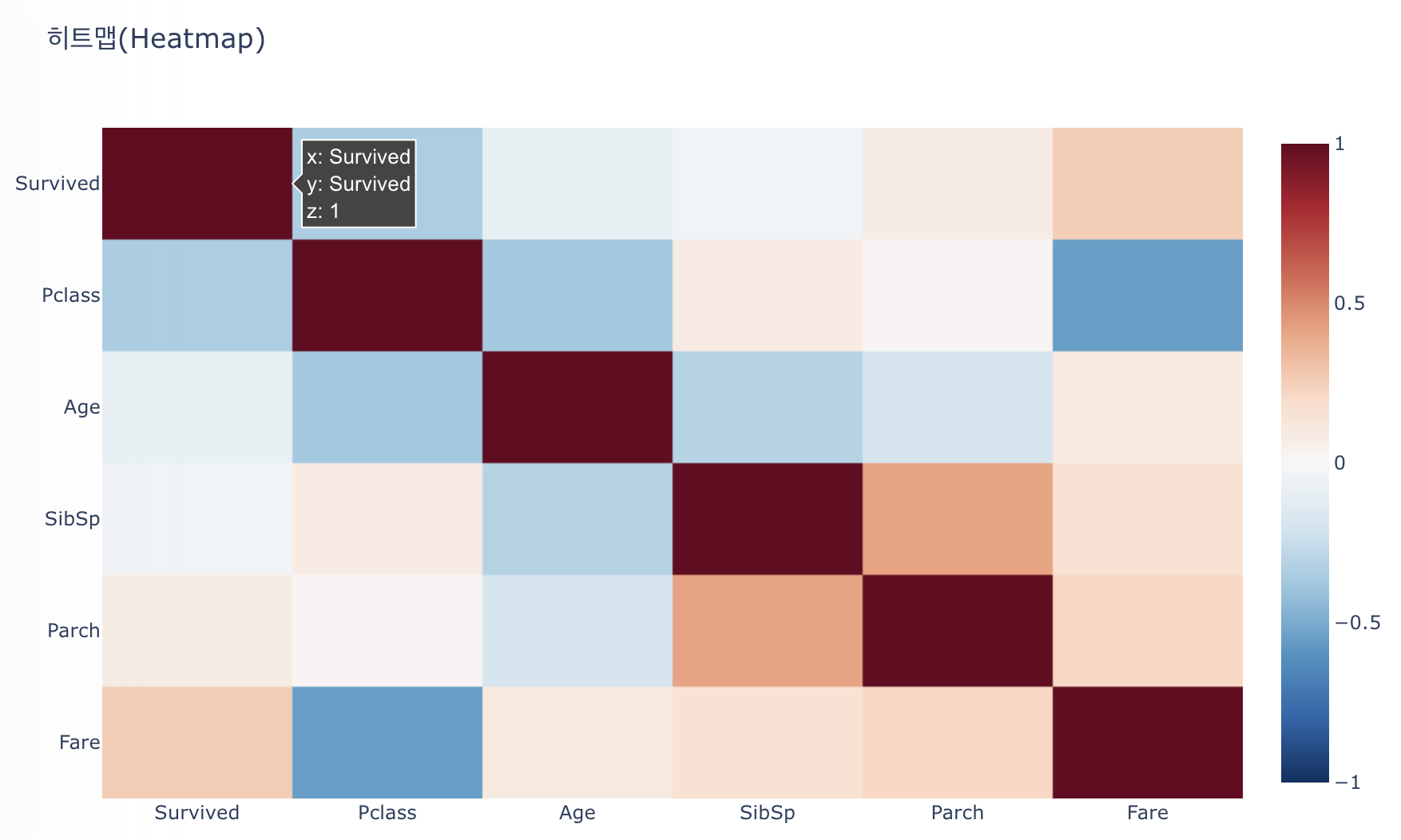
히트맵은 사진과 같다. 붉은 색일수록 컬럼 간의 연간관계가 깊다는 의미다. 이때는 도출하려는 label를 중심으로 붉은 색의 컬럼을 보는 것이 중요하다.
2. 박스차트
박스차트는 값의 평균값들을 보는데 아주 유용한 시각화 자료다. 박스차트는 아래 사진과 같다.

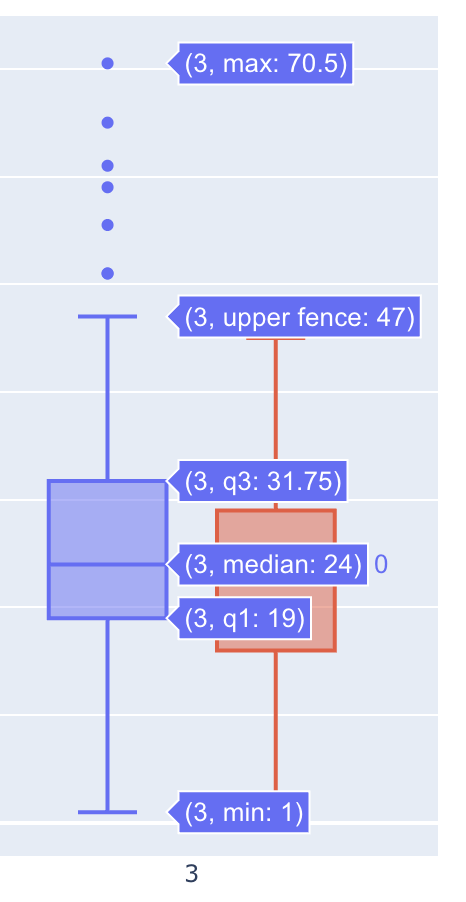
보는 방법은 히트맵에 비해서는 조금 어렵기는 한데 그렇다고 너무 어려운 건 아니다. 우선 첫 번째 사진에서 x, y좌표가 어떤 걸 의미하는 지 파악하는 것이 우선이다. 그 후 박스에 마우스를 올리면 두 번째 사진과 같이 값들이 나온다.
1. 가장 아래인 Min은 가장 작은 값
2. q1은 박스를 이루는 가장 작은 값이고
3. q2 = median으로 중간값
4. q3는 박스를 이루는 가장 큰 값
5. upper fence는 이상 값중 가장 큰 값이다
6. max는 가전체에서 가장 큰 값이다.
7. 또한 IQR이라고 존재하는데, q3-q1은 뺀 값이다. 이는 박스의 몸통길이를 나타내기도 한다.
3. 분포차트
마지막으로 분포차트다. 분포차트는 x축 컬럼의 값들이 얼마나 분포되어 있는지를 알 수 있다.
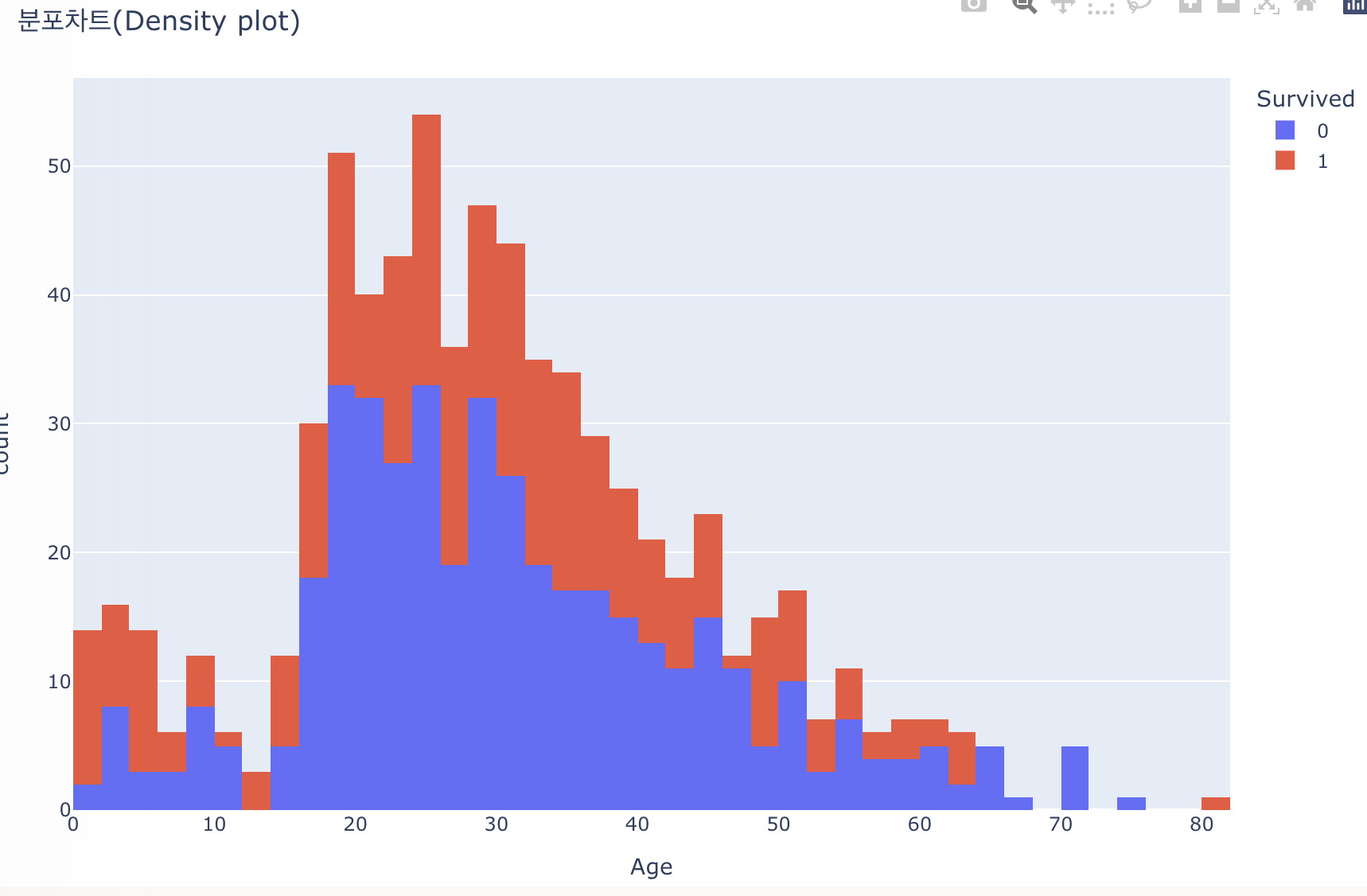
마우스를 올리면 각 축당 어떤 값을 갖고 있는지 상세하게 알 수 있다.
마무리
후회없이 했다면, 그것 또한 값진 결과
하루 1시간씩 일주일 정도 공부를 한 것 같다. 너무 어려운 시험은 아니라고 했지만, 한 번 정리하는 건 좋은 습관이고 재미있다. 이번 AI를 공부하면서 괜찮은 흥미를 가졌고, 기회가 된다면 Basic 다음은 Associate도 도전해보고 싶다.
꼭 좋은 결과까지는 아니더라도 마지막까지 최선을 다해보자.

음악을 좋아하는 사람이 음악을 만들 듯, 개발을 좋아하게 될 사람이 쓰는 개발이야기