Custom Data 기본개념
DataSet (Split Data 형태로)
train set
학습에 사용되는 훈련용 데이터
valid set
모델의 일반화 능력을 높이기 위해 학습 중에 평가에 사용되는 검증 데이터
test set
학습 후에 모델의 성능을 평가하기 위해서만 사용되는 테스트용 데이터
만약 데이타세트가 나눠야 한다면 splitfolders 라이브러리를 이용하여 데이타세트를 나눠주면 됨
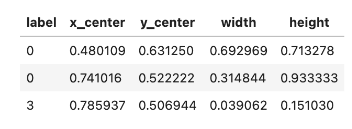
라벨 형식
1. roboflow에서 제공하는 데이타에는 label 파일이 존재하기때문에 별도 labeling은 필요 없음
2. 각 줄은 label, 중심 X좌표, 중심 Y좌표, 너비, 높이 순서로 공백으로 구분해서 정보를 입력하며 좌표와 너비는 0~1 사이의 범위로 입력

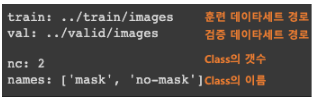
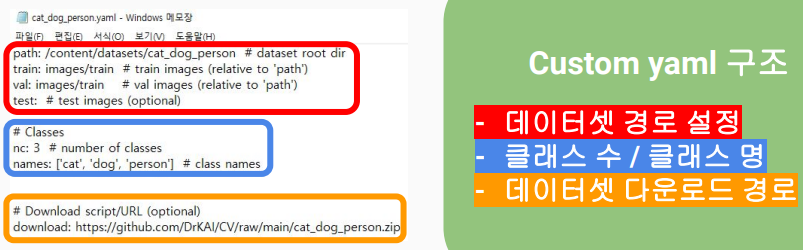
yaml 파일 수정
yaml 파일 수정 예시
-
주의! 데이터셋 경로를 적을 때, txt 파일 형식으로 적어줘야함
-
이유는 yolo5모델은 데이터셋을 로드할 때 경로 내의 모든 txt 파일을 읽어서 사용하기때문

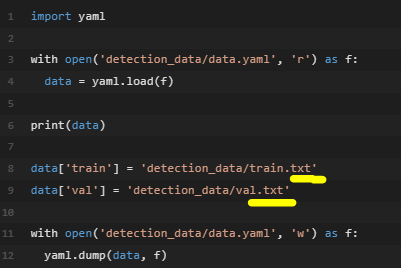
즉, train과 valid 각각의 이미지에 대한 경로를 담은 train.txt 파일과 valid.txt 파일을 만들어줘야함
CustomData_ImageDetection
UltraLytics YOLO v5 설치
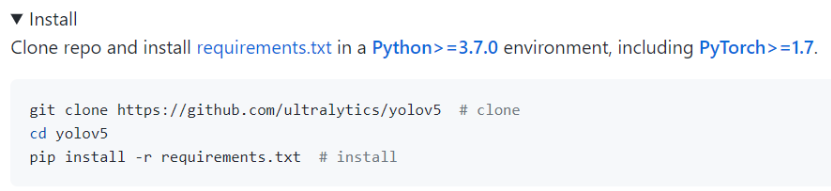
1. UltraLytics git에서 복사하기


2. yolov5 폴더 이동 및 requirements.txt 내부 패키지 설치

Image Detection 과정 정리

1. 사전 작업된 CustomData yaml 다운로드(CustomData yaml 사전 작업 필요)




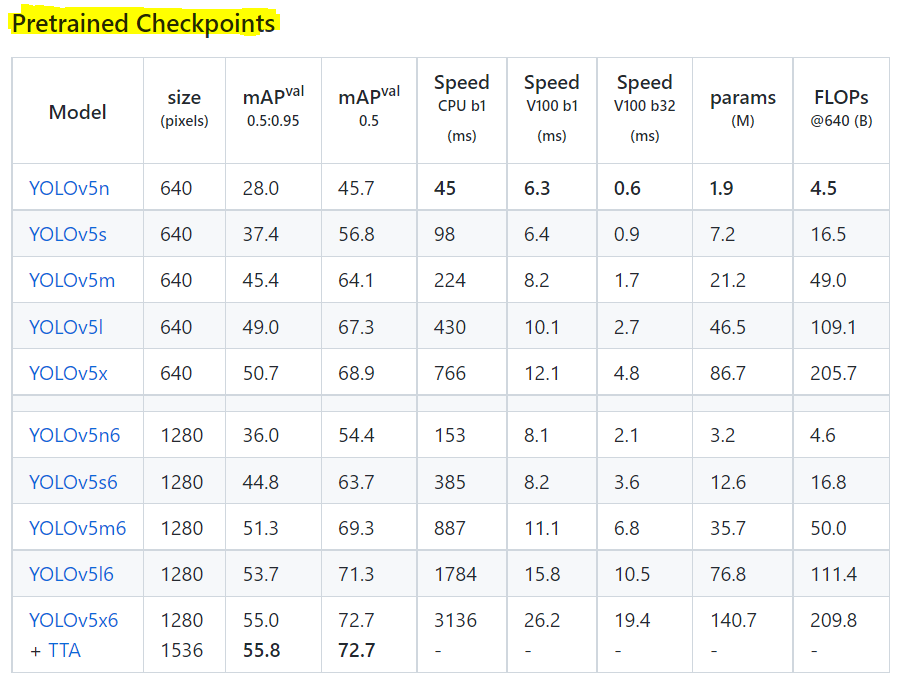
2. Pretrained weights 다운로드
2.1 pretrained weights 저장 폴더 생성


2.3 pretrained weights 다운로드

3. train용 이미지 다운로드
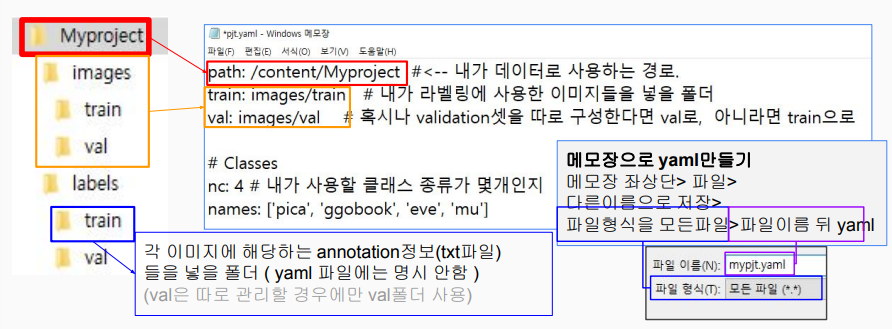
3.1 datasets(생성 후 안에 street폴더도 생성), images(생성 후 안에 train폴더도 생성), lables(생성 후 안에 train폴더도 생성)

3.2 images, labels 각 3개씩 다운로드
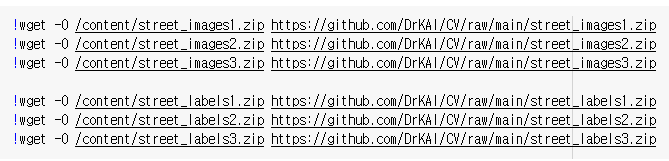
3.3 다운받은 파일들 압축 해제 후 각 train폴더에 넣기
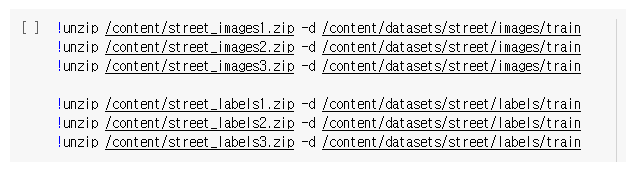
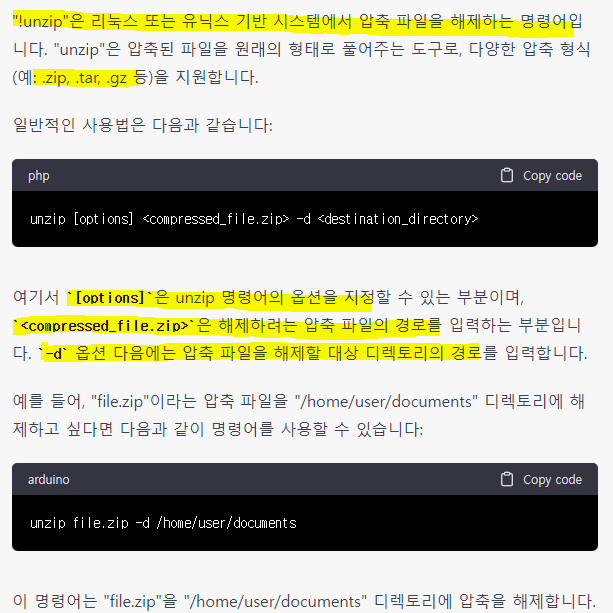
4. train.py 실행
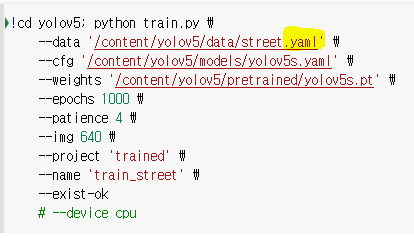
4.1 명령어 도움말 : python train.py -h
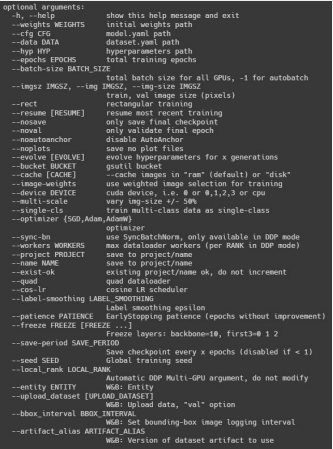
4.2 train.py 형식 맞게 입력 후 실행
5. detect용 이미지 다운로드

디텍팅할 원본 이미지 다운로드
6. detect.py 실행
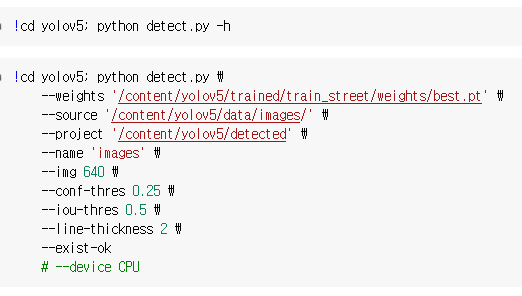
결과

CustomData_ImageDetection 실습하기1 (라쿤)
참고 블로그
전체 과정
1. 데이터셋 다운받기(어떤 종류의 데이터셋이든 괜찮음)
-
Roboflow 퍼블릭 데이터셋 :https://public.roboflow.com/object-detection
-
데이터셋 포맷은 TXT - YOLOv5 pytorch 포맷 으로 다운받으면 됨
=> YOLO 모델을 구글 코랩이라는 환경에서 학습시킬 예정
=> 구글 코랩을 사용 시 개발 환경을 따로 세팅해줄 필요없음
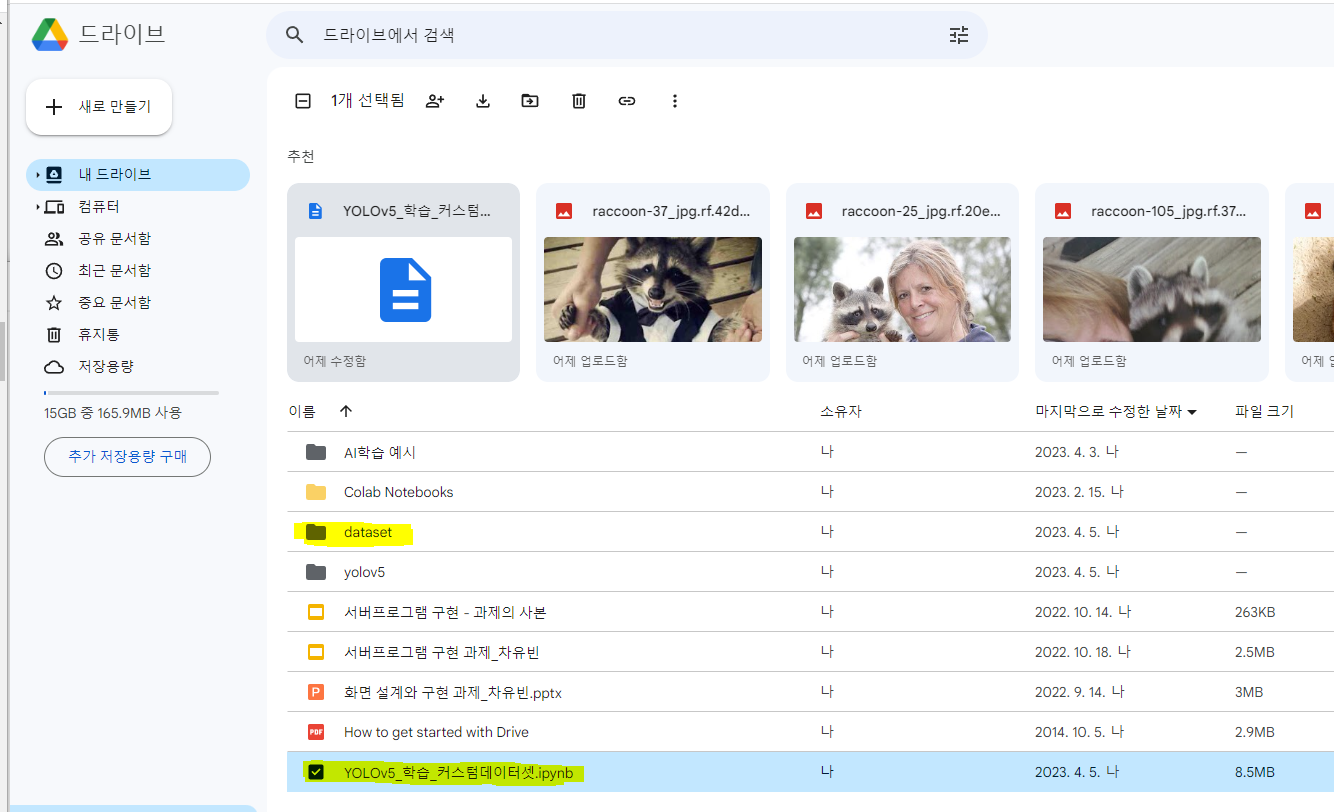
2. 다운받은 데이터셋을 본인 구글드라이브에 업로드시킴(dataset 폴더에 data 넣기)
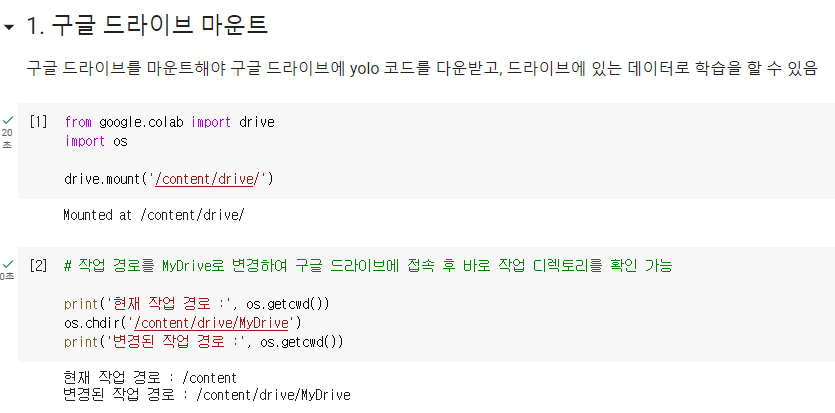
코드실행
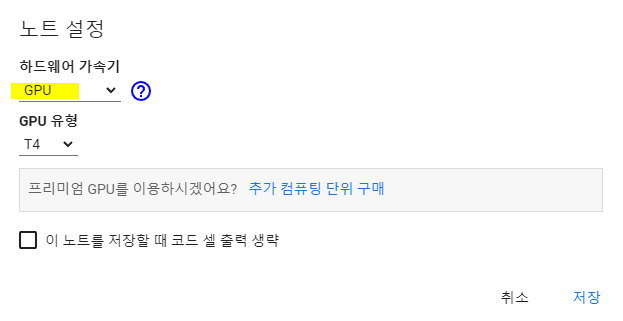
3. 빠른 학습을 위해 GPU를 사용 (런타임 - 런타임 유형 변경 - 하드웨어 가속기 → GPU)
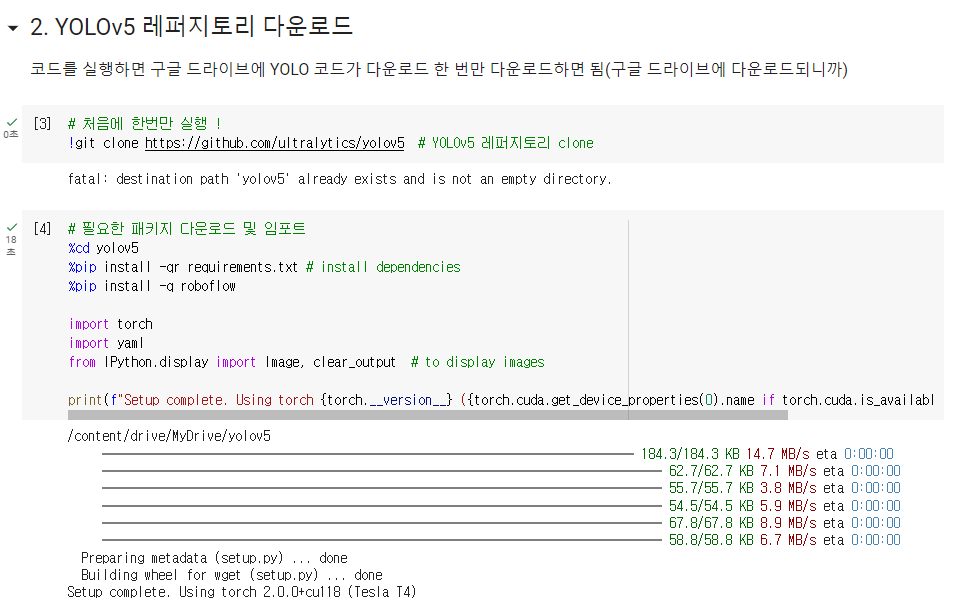
4. yolo5 레퍼지토리 다운로드
-
data의 경로와 yaml파일의 경로를 변수로 설정

-
yaml파일 내용 확인 : 처음에는 yaml파일에서 train과 val 폴더 경로가 정해져있지 않음

-
yaml파일 정보 수정
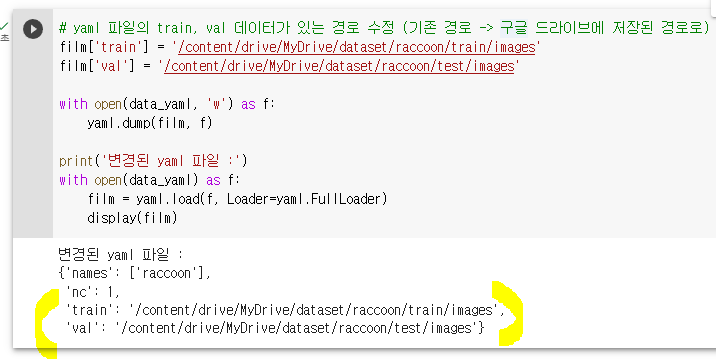
yaml파일 : 학습/평가 데이터와 어노테이션(라벨), 데이터셋에 대한 정보가 담긴 파일
- 다른 데이터셋 이용시에도, 라벨, yaml 파일을 모두 퍼블릭 데이터셋의 규격에 맞게 통일
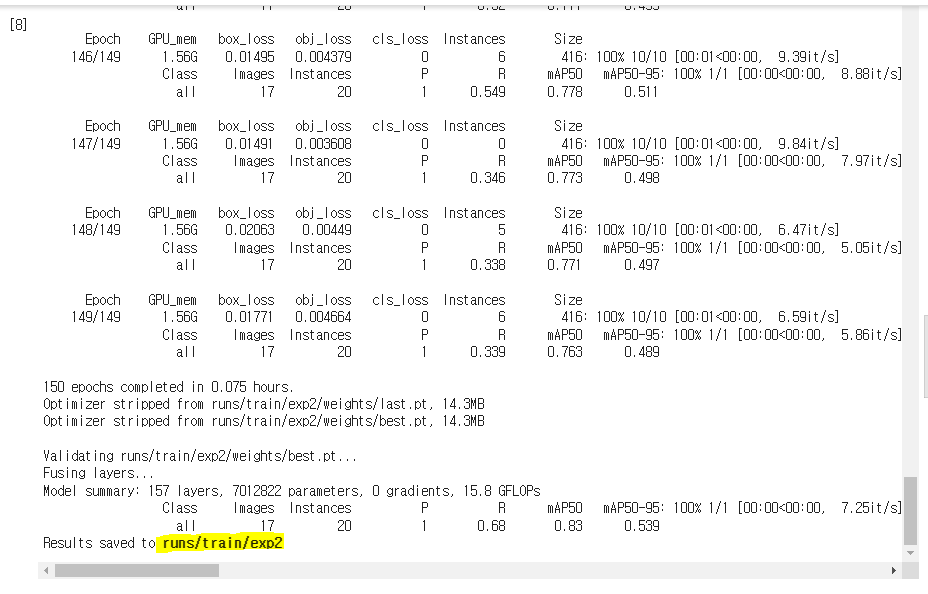
5. 모델 학습

6. 텐서보드로 학습 성능 확인(딥러닝 모델이 잘 학습되는지 확인하는 어플리케이션)
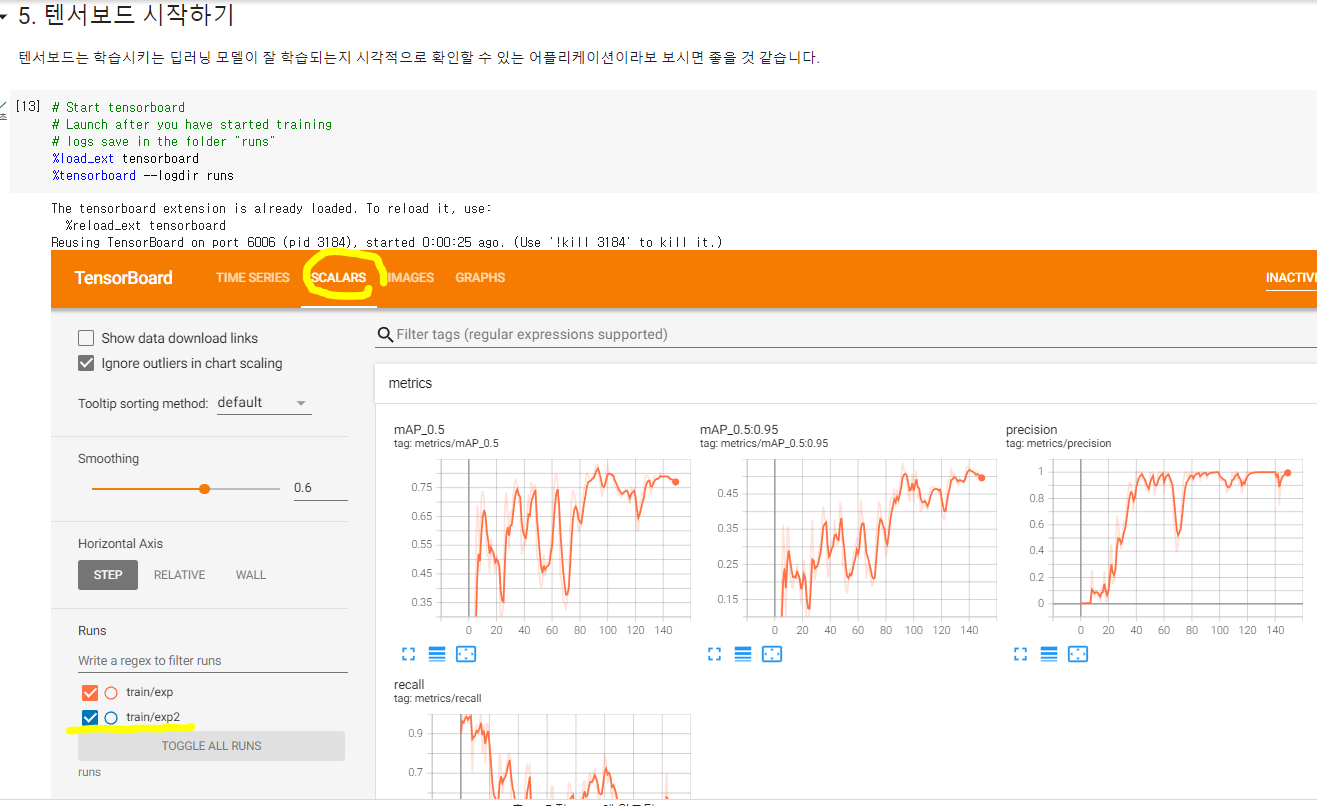
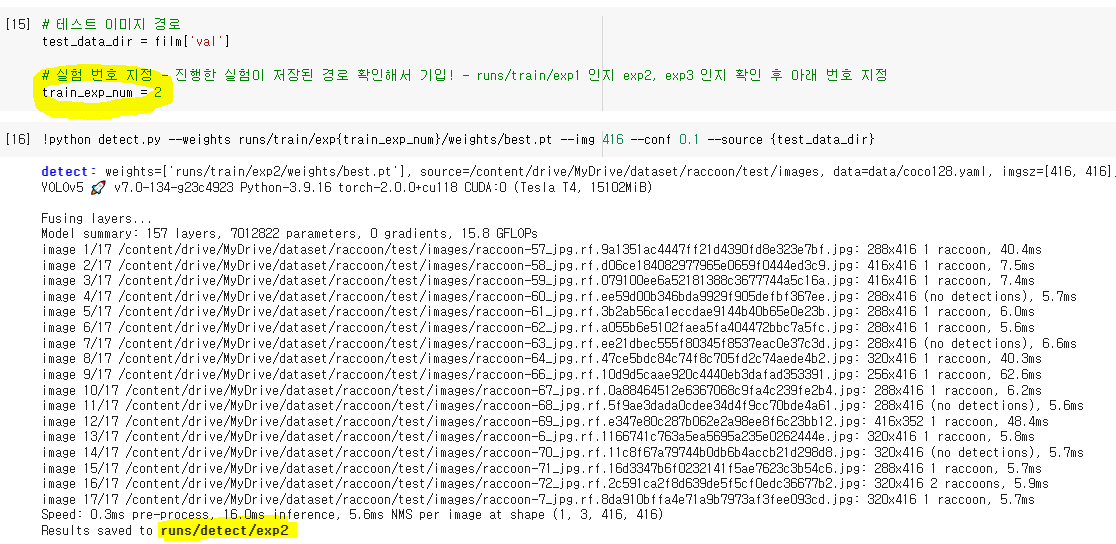
7. 학습한 모델로 이미지 검출 테스트
- 학습한 모델을 테스트 데이터셋에서 테스트
- 학습한 모델이 저장된(모델학습에서 result/train/exp2) exp번호 train_exp_num에 저장해두고 테스트를 실행
- 테스트도 끝난 후 테스트 정보가 저장된 경로가 나오는데 이 exp 번호로 결과 확인
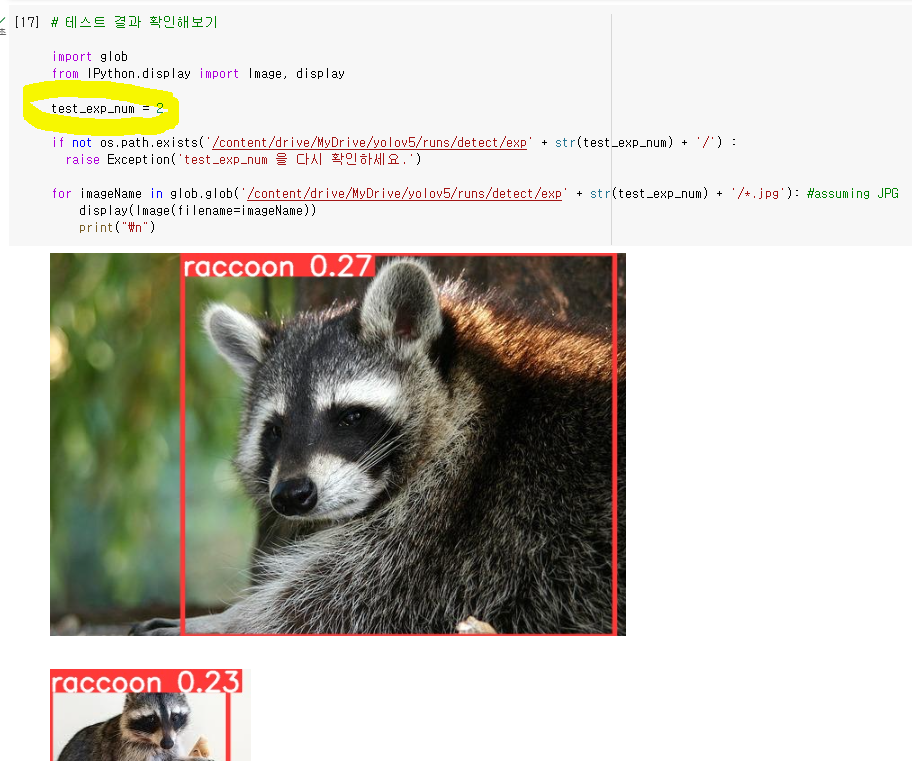
8. 테스트 결과 확인
9. 베스트 모델 저장

기타 정보
COCO 데이터로 디텍팅 하기 참고 블로그

colab 12시간유지코드(자바스크립트 코드로써 30분마다 코랩에 클릭이벤트 주는 코드)
전원을 끄거나 절전모드를 하면 안됨
function ClickConnect(){
console.log("Working");
document.querySelector("colab-toolbar-button#connect").click()
}setInterval(ClickConnect, 1800000)CustomData_ImageDetection 실습하기2 (office)
1. yolov5 레포지토리 git clone으로 다운로드
requirements.txt 파일로 필요 모듈 설치
torch, os import 시키기

2. 데이터셋 다운
이 방법은 roboflow에서 코드로 다운받는 방법
3. train, valid, test 각각의 image폴더 내 이미지들 경로 txt 파일로 생성
- yaml파일에서 각 폴더 경로를 읽어올 때 yolo는 txt형식으로 읽어오므로
train.txt, valid.txt, text.txt 파일 필요함
- 각 이미지에 대한 경로를 list로 만들고 각 txt 파일에 경로 저장

4. 이미지 트레이닝 (train.py 파일 사용)
!python train.py --img 416 --batch 16 --epochs 100 --data /content/datasets/office1-1/data.yaml --weights yolov5s.pt --cache --name office_result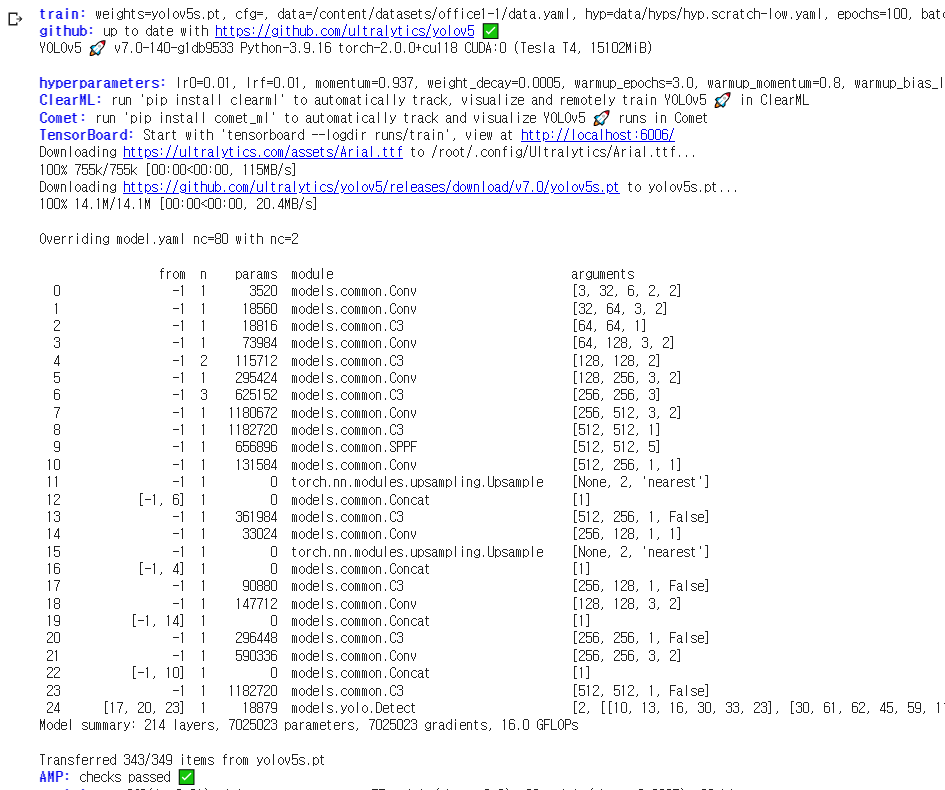
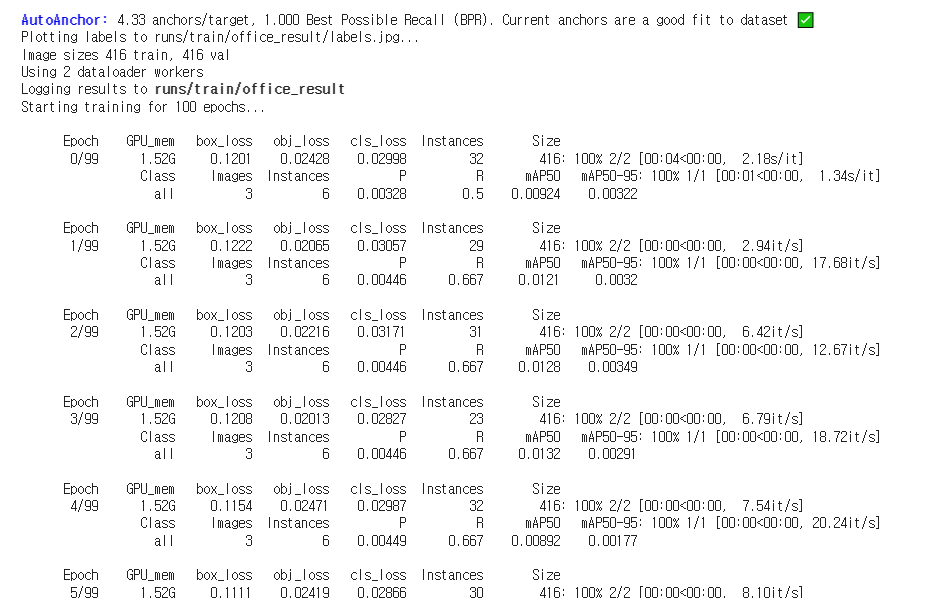
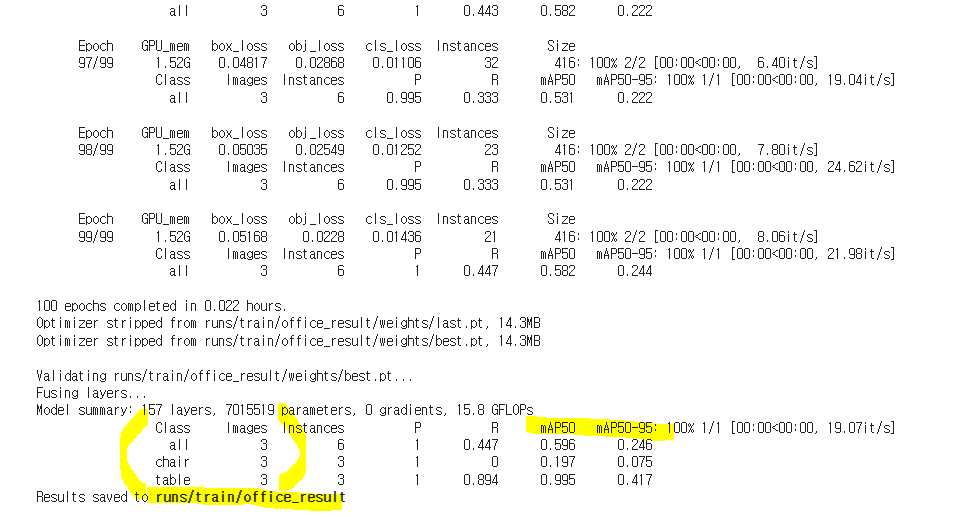
5. 텐서보드로 모델 성능 확인
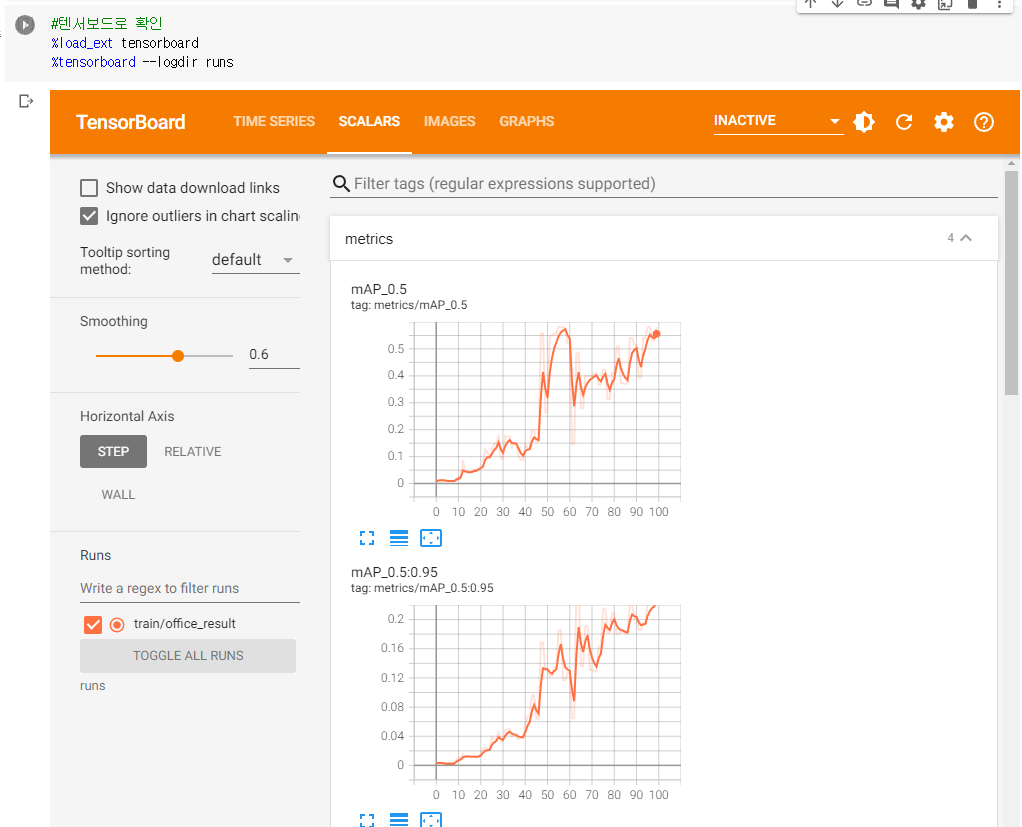
6. 이미지 디텍팅 시키기 (detect.py 파일 사용)
#이미지 디텍팅 시키기
!python detect.py --weights runs/train/office_result/weights/best.pt --img 416 --conf 0.1 --source /content/datasets/office1-1/test/images
7. 디텍팅 된 이미지 출력해서 확인해보기
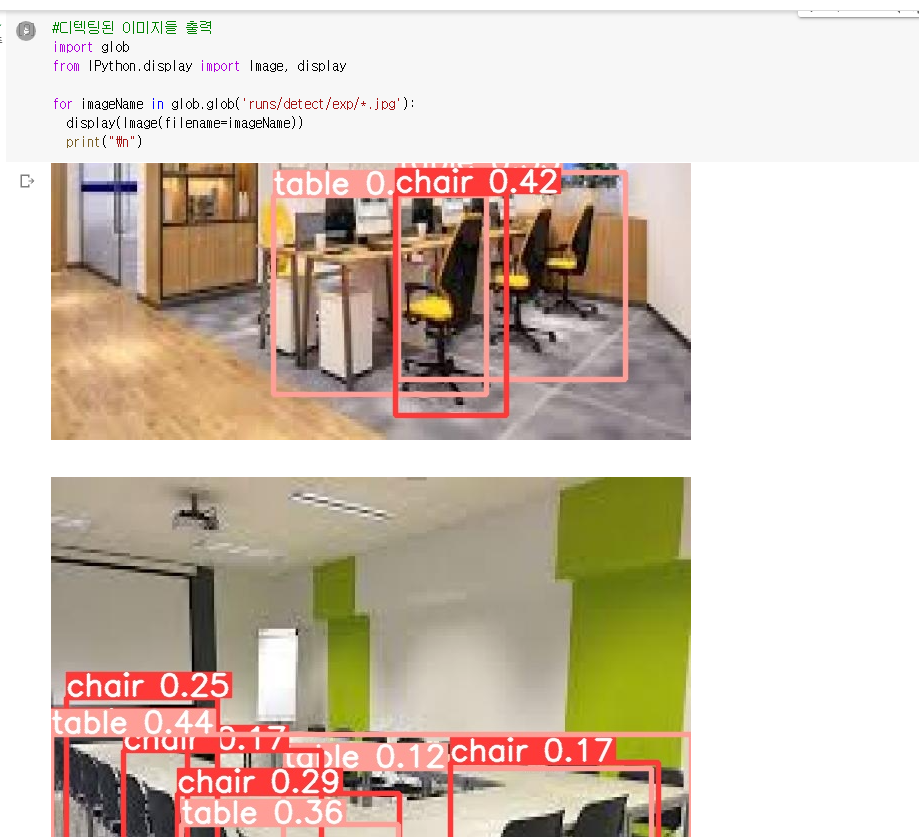
8. 이미지 검증하기 (val.py 파일 사용)
#이미지 검증하기
!python val.py --weights /content/yolov5/runs/train/office_result/weights/best.pt --data /content/datasets/office1-1/data.yaml --img 416 --iou 0.65 --half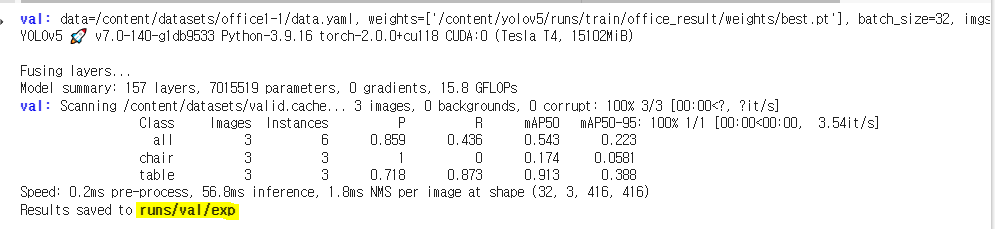
결과 디텍토리 폴더에 생성된 결과들 확인해보기
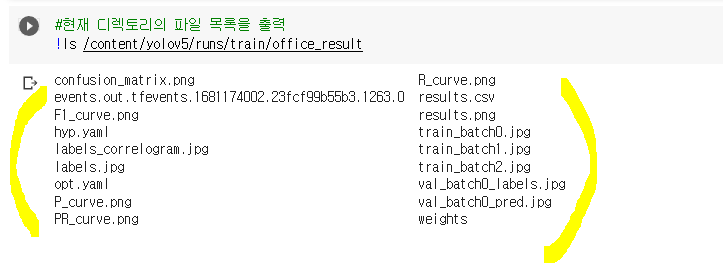
bsst.pt (가장 학습이 잘 된 모델) & last.pt(가장 마지막 학습된 모델)
9. 학습한 모델 결과 다운로드

