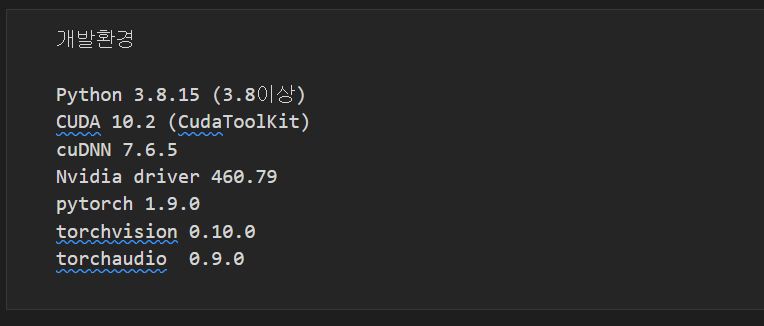
GPU 사용을 위한 나의 세팅 환경 버전
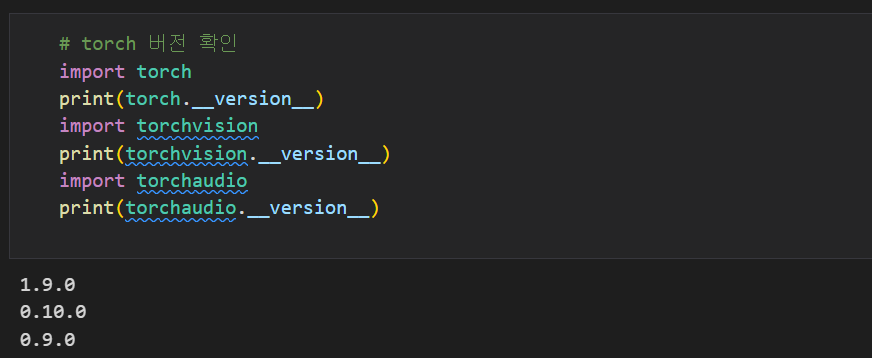
gtx 960 기준 python, cuda, cudnn, pytorch, torchvision, torchaudio, nvidia 그래픽드라이버 버전
본인의 로컬 환경에 따라 다르기 때문에 gpu가 실행되는 버전으로 계속 시도해봐야함
- Python 3.8.15 (3.8이상)
- CUDA 10.2 (CudaToolKit)
- cuDNN 7.6.5
- Nvidia driver 460.79
- pytorch 1.9.0
- torchvision 0.10.0
- torchaudio 0.9.0
train.py 실행
CUDA out of memory (메모리 부족 에러)
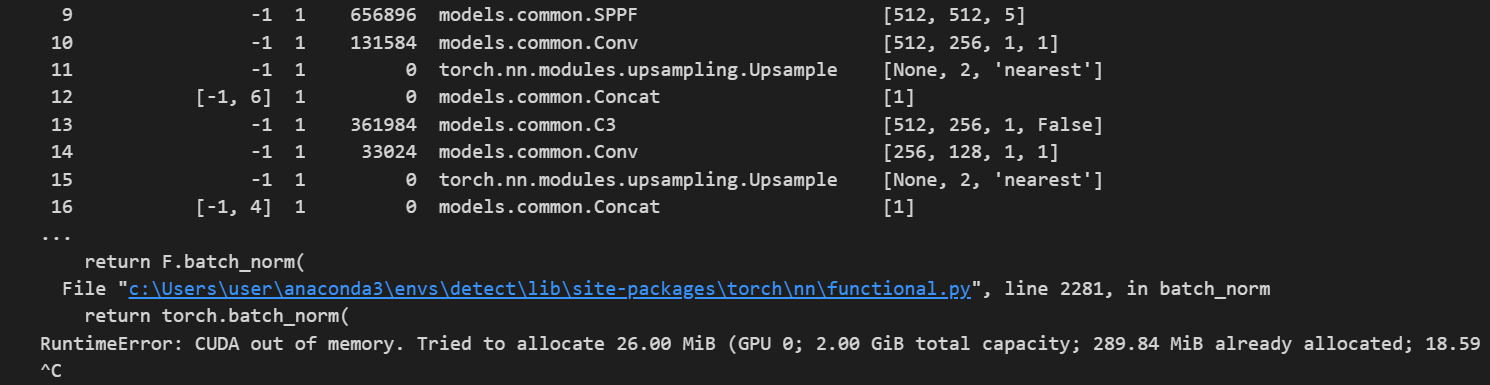
RuntimeError: CUDA out of memory. Tried to allocate 26.00 MiB (GPU 0; 2.00 GiB total capacity; 289.84 MiB already allocated; 18.59 MiB free; 304.00 MiB reserved in total by PyTorch)
=> 원인 : GPU 가용 메모리가 부족해서 train 하지 못하는 상태
★해결 방안 : 데이터셋(이미지/동영상 용량), batch 사이즈, img크기, epochs 크기 낮추고 다시 진행
Pillow 라이브러리 버전 업그레이드
데이터셋 용량 낮추고 train 실행시켜도 pillow 라이브러리에서 에러 발생
-> Pillow 라이브러리 버전 업데이트 해야하는 상태였음
https://pypi.org/project/Pillow/
정상 출력 됨
train.py 실행 시 인자 분석
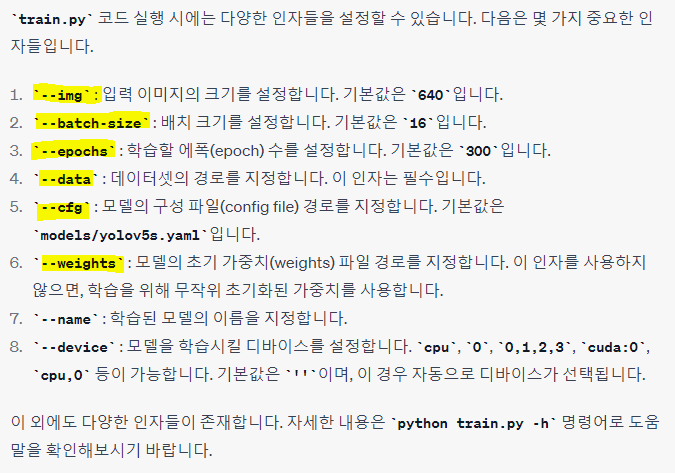
--epochs
한 번의 epoch는 인공 신경망에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것
즉, 전체 데이터 셋에 대해 한 번 학습을 완료한 상태
--img
604, 1280 .. 640씩 더한 형태로 이미지 크기를 지정
이미지 크기가 클수록 정확도는 올라가지만 그만큼 속도 감소

--batch-size
학습 과정에서 한 번에 처리되는 데이터의 개수 (default는 16)

--data
데이터셋 정보를 작성한 yaml파일 경로
--weights
모델의 가중치 파일 경로
--project 그리고 --name
학습후 최종 weights파일과 모델 성능 평가 데이터를 저장할 위치를 지정
--project 는 상위폴더 --name 은 하위폴더
detect.py 실행 시 인자 분석

train.py 실행 소요 시간 지연 문제
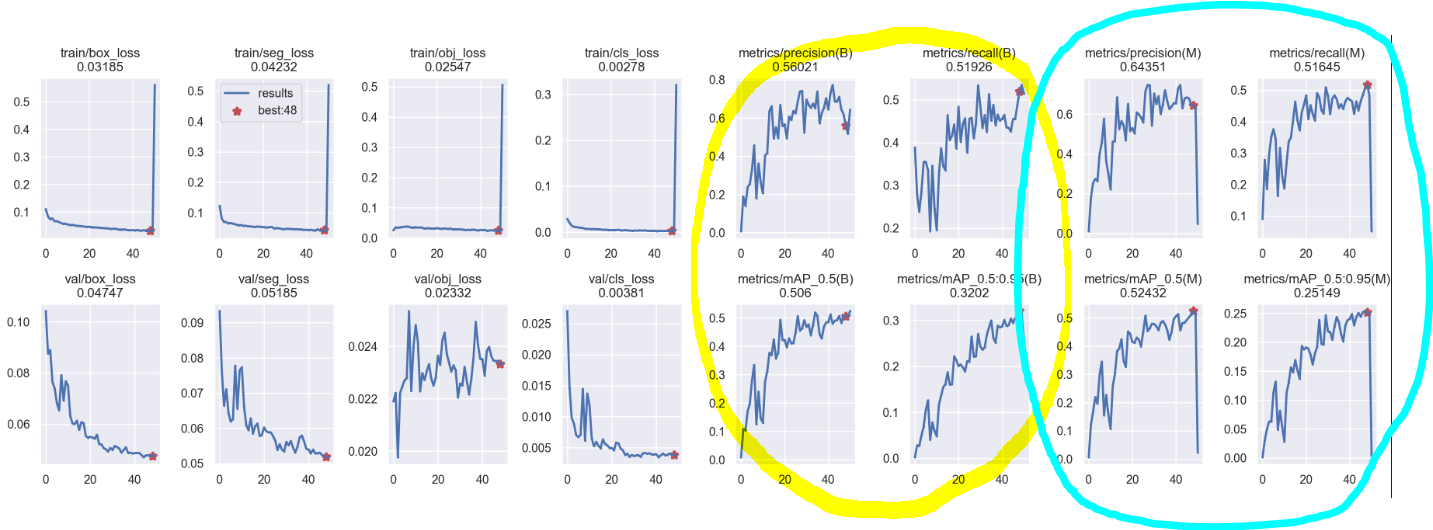
모델 성능 평가
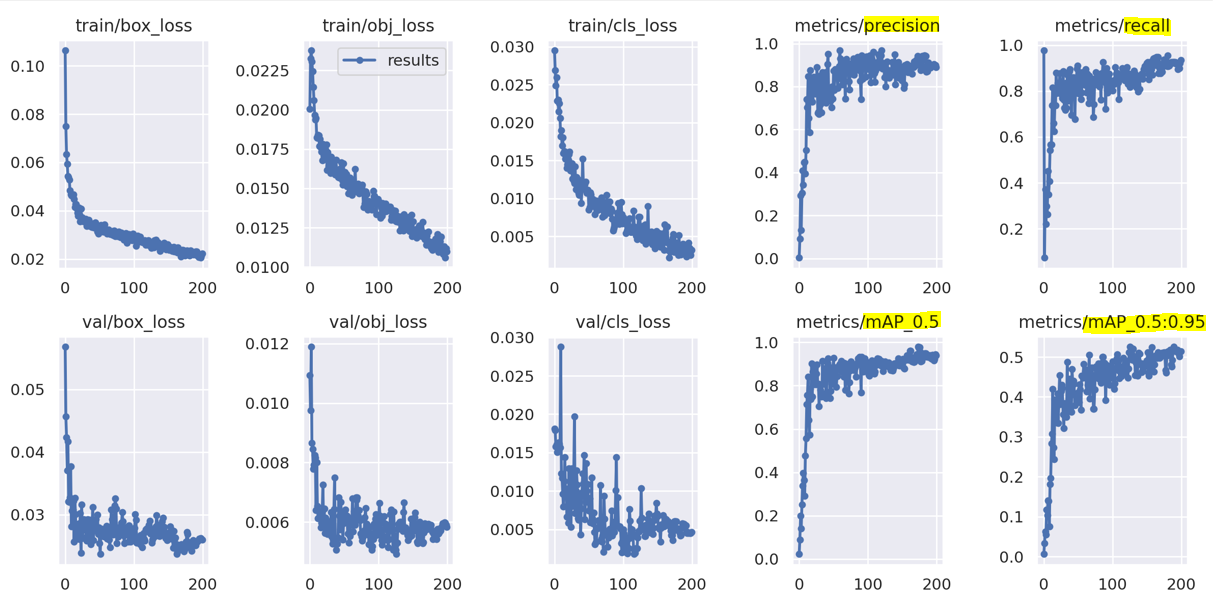
result 파일 해석하기
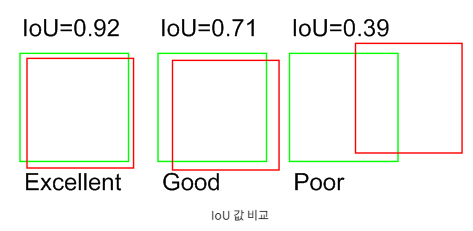
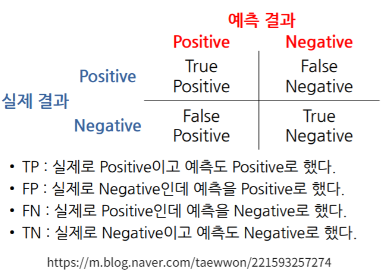
IOU 란?

기계가 예측한 박스와 사람이 라벨링한 박스의 겹치는 영역이 클수록 IOU가 높고 정확하게 예측했다는 뜻
두 box의 크기가 동일할 경우 두 box의 2/3는 겹쳐줘야 0.5의 값이 나옴
- Pascal VOC
IoU > 0.5 인 detection은 true, 그 이하는 false로 평가하는 방식
- COCO
0.5에서 0.95까지 0.05 간격으로 IoU 임계값을 변화시키면서 IoU>0.5, IoU>0.55, IoU>0.6, …, IoU>0.95 각각을 기준으로 AP를 계산한 후 이들의 평균을 취하는 방식
Precision & Recall
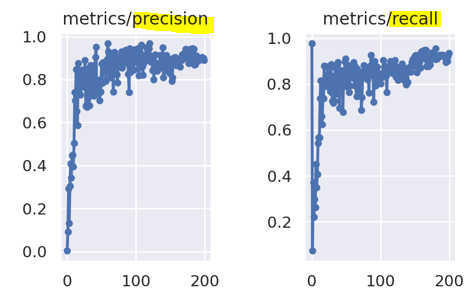
★ Precision (정밀도)
모델이 예측한 결과의 Positive 결과가 얼마나 정확한지 나타내는 값
=> 모델이 정답이라고 한 것 중에 진짜 정답의 비율(검출 결과들 중 옳게 검출한 비율)
★ recall (재현율)
모델의 예측한 결과기 얼마나 Positive 값들을 잘 찾는지를 측정하는 것
=> 진짜 정답 중에 모델이 정답이라고 한 것의 비율(실제 옳게 검출된 결과물 중에서 옳다고 예측한 것의 비율)
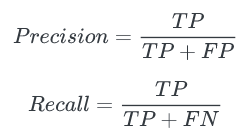
Precision이 높으면 Recall은 낮은 경향이 있고, Precision이 낮으면 Recall이 높은 경향이 있다.
약간 반비례 관계, 따라서 두 값을 종합해서 알고리즘의 성능을 평가
Precision-recall 곡선(PR 곡선)

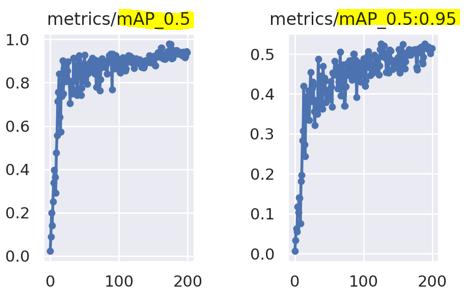
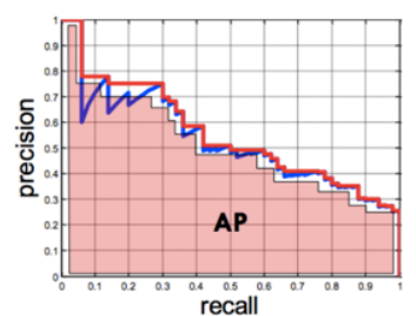
Average Precision (AP)
Precision-recall 그래프에서 그래프 선 아래쪽의 면적(AP)을 계산하는 방식
면적의 값, 즉, AP가 클수록 성능이 좋은 모델임
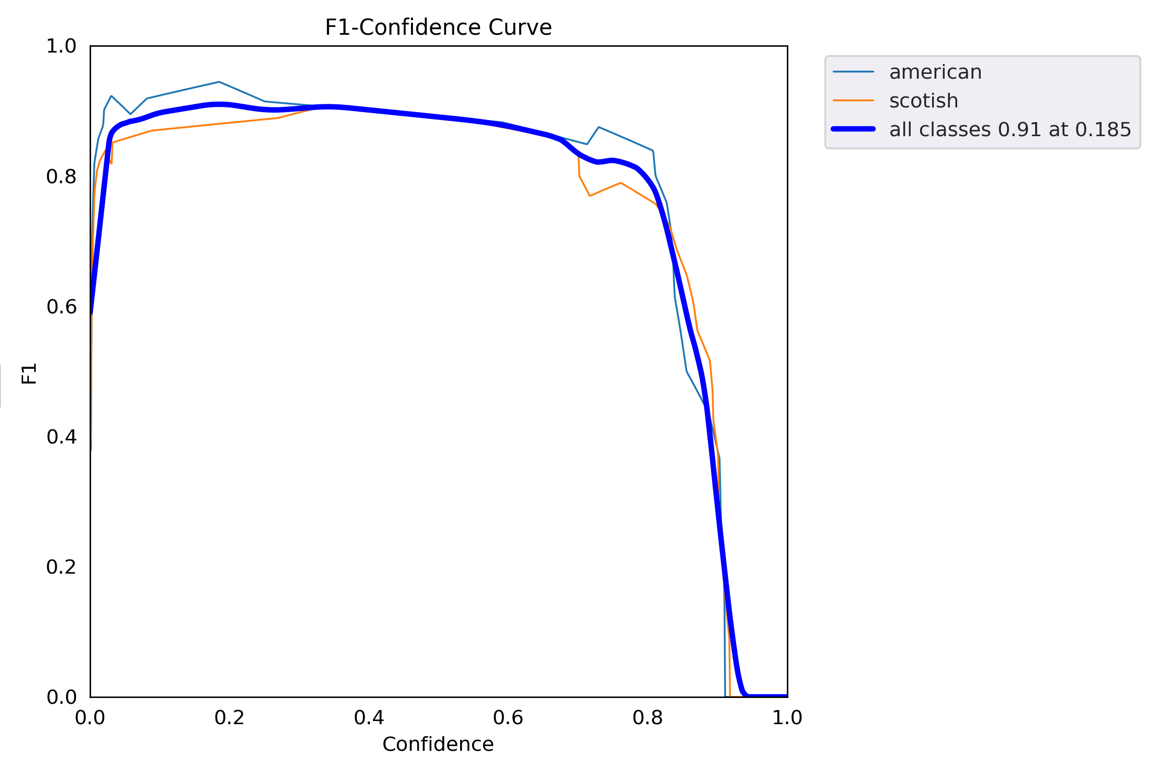
F1 score
Precision과 Recall의 조화평균 정밀도와 재현율이 비슷할 수록 F1 score도 높아짐
0~1의 값을 가지며 일반적으로 f1 score가 높을수록 모델 성능 Good
데이터 label이 불균형 구조일때 성능평가 가능

object detection와 Instance segmentation 차이점
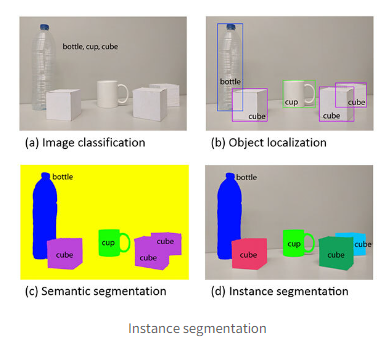
Instance segentation은 이미지 내에 존재하는 모든 객체를 탐지하는 동시에 각각의 경우(instance)를 정확하게 픽셀 단위로 분류 가능 (Semantic segmentation에선 동일한 카테고리만 인식함)
즉 객체를 탐지하는 object detection task와 각각의 픽셀의 카테고리를 분류하는 semantic segmentation task가 결합된 것
Instance segmentation 결과 해석

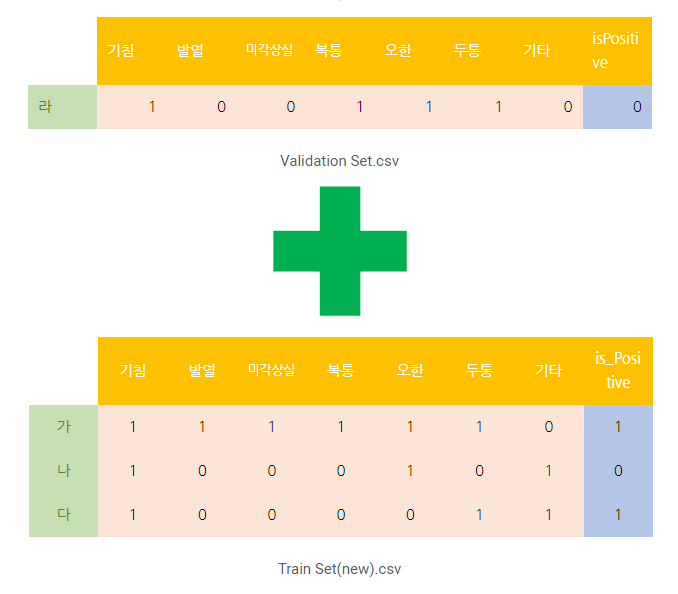
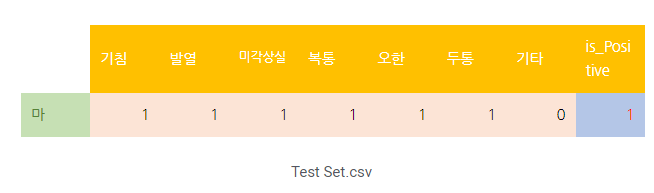
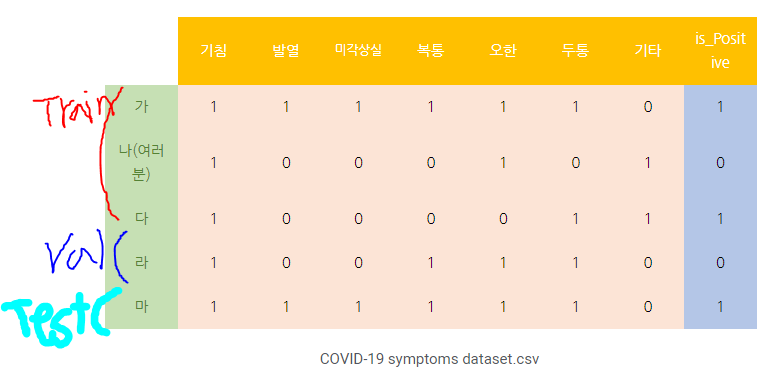
Validation(검증) 하는 이유
-검증 세트는 Train 세트과 Test 세트 사이의 괴리를 보완
-학습한 내용을 말 그대로 검증하며, 머신러닝 모델에 있어서 성능을 검증하는 기회를 제공
-한 번의 test 결과를 100% 신뢰할 순 없으니깐 validation을 통해 한번 더 테스트해보는 것
이미지 디텍팅 실행
1. 개발 환경
아래 프로그램 및 라이브러리 설치
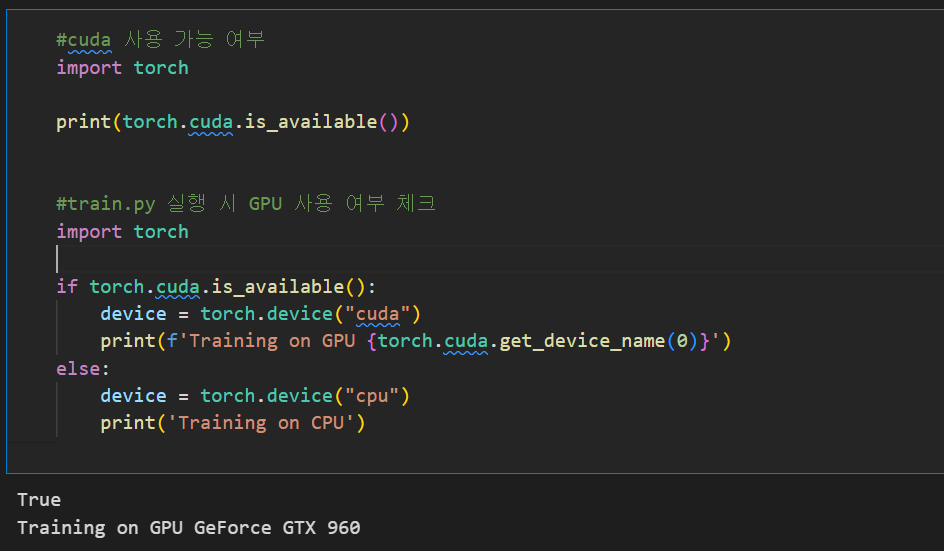
1.1 라이브러리 버전 & GPU 사용 확인
2. UltraLytics YOLO v5 설치
yolov5 폴더 이동 및 requirements.txt 내부 패키지 설치

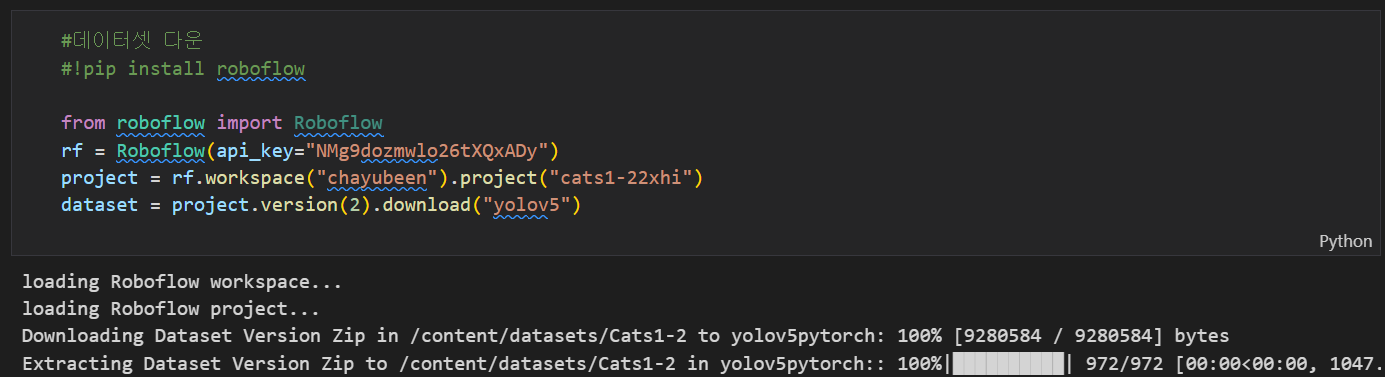
3. 라벨링 된 Datasets 다운
데이터셋 필수 항목
- train, test, valid 각 images폴더와 label폴더
- data.yaml 파일
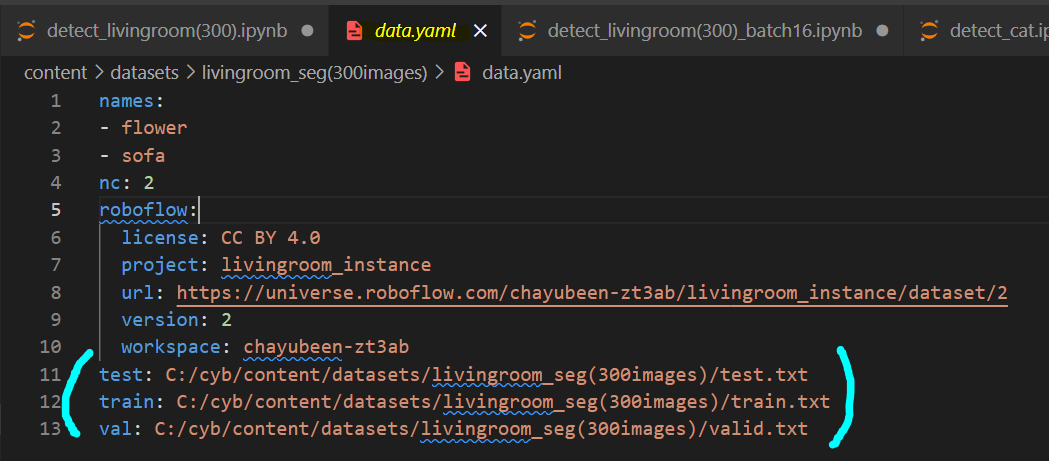
4. data.yaml에 각 폴더의 images 파일 경로 지정
images 경로 파일 목록 (각 images 파일의 경로를 txt 파일에 쓰기)
- train.txt
- test.txt
- valid.txt
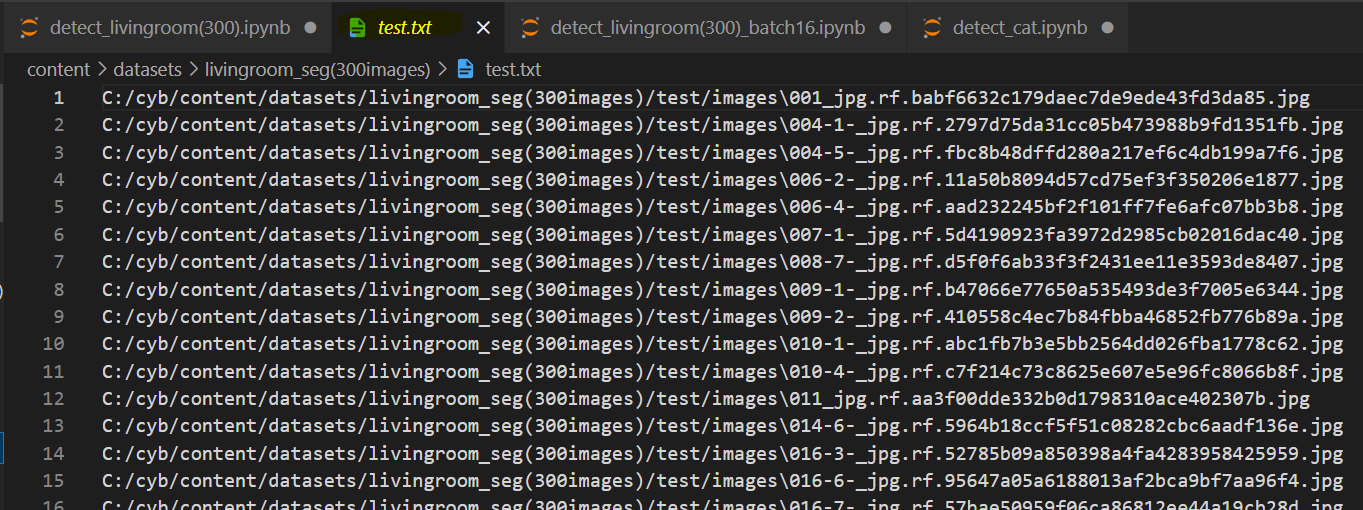
아래와 같이 경로가 적힌 txt 파일이 생성됨
data.yaml에서 test.txt, train.txt, val.txt 파일 경로를 설정
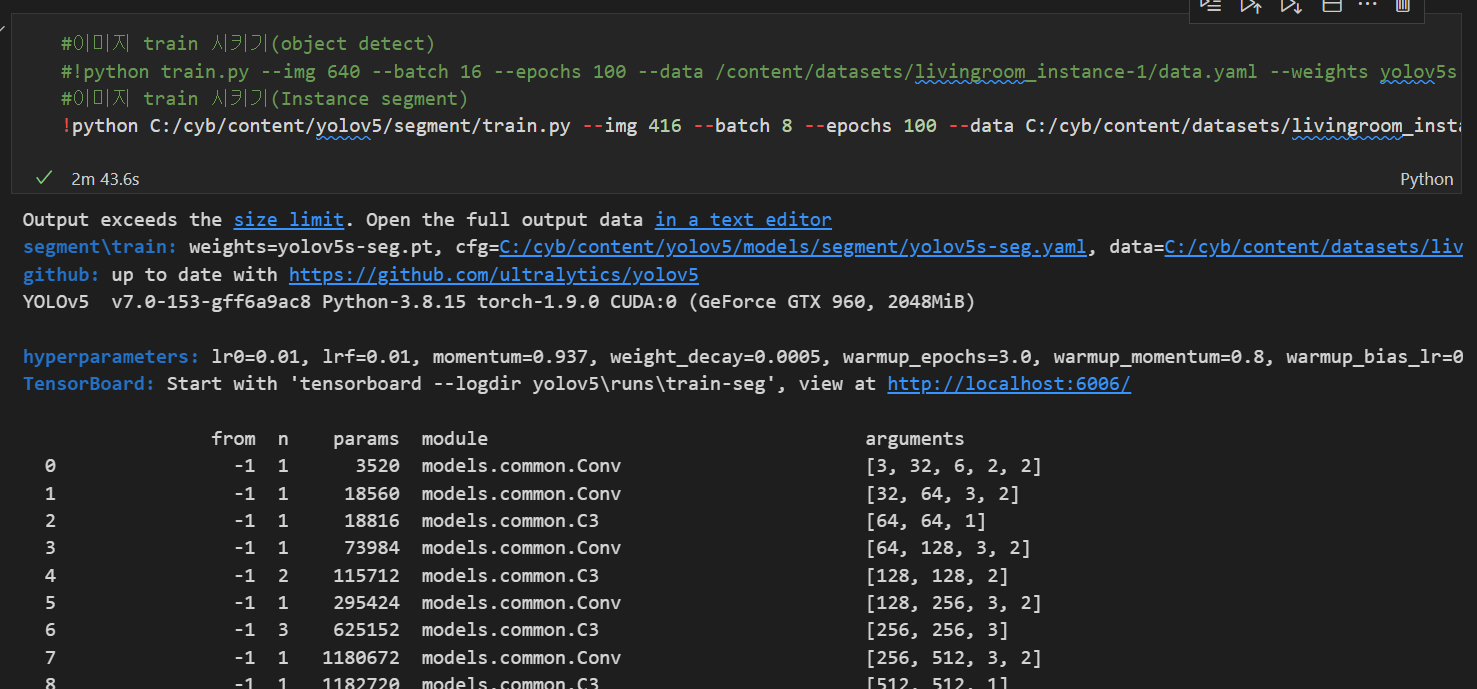
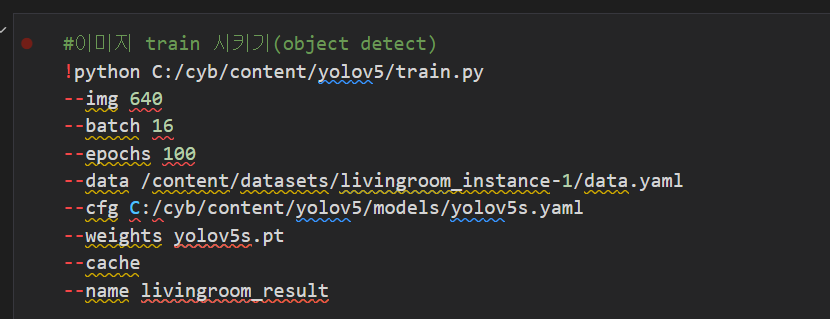
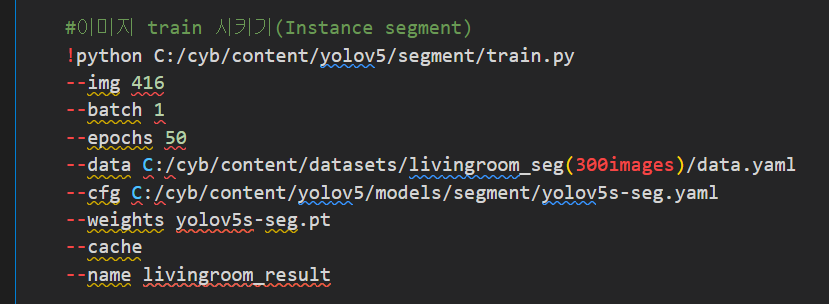
5. train.py 실행 (이미지 학습 단계)
object detect일땐 yolov5s.yaml 파일 사용
instance segment일땐 yolov5s-seg.yaml 파일 사용
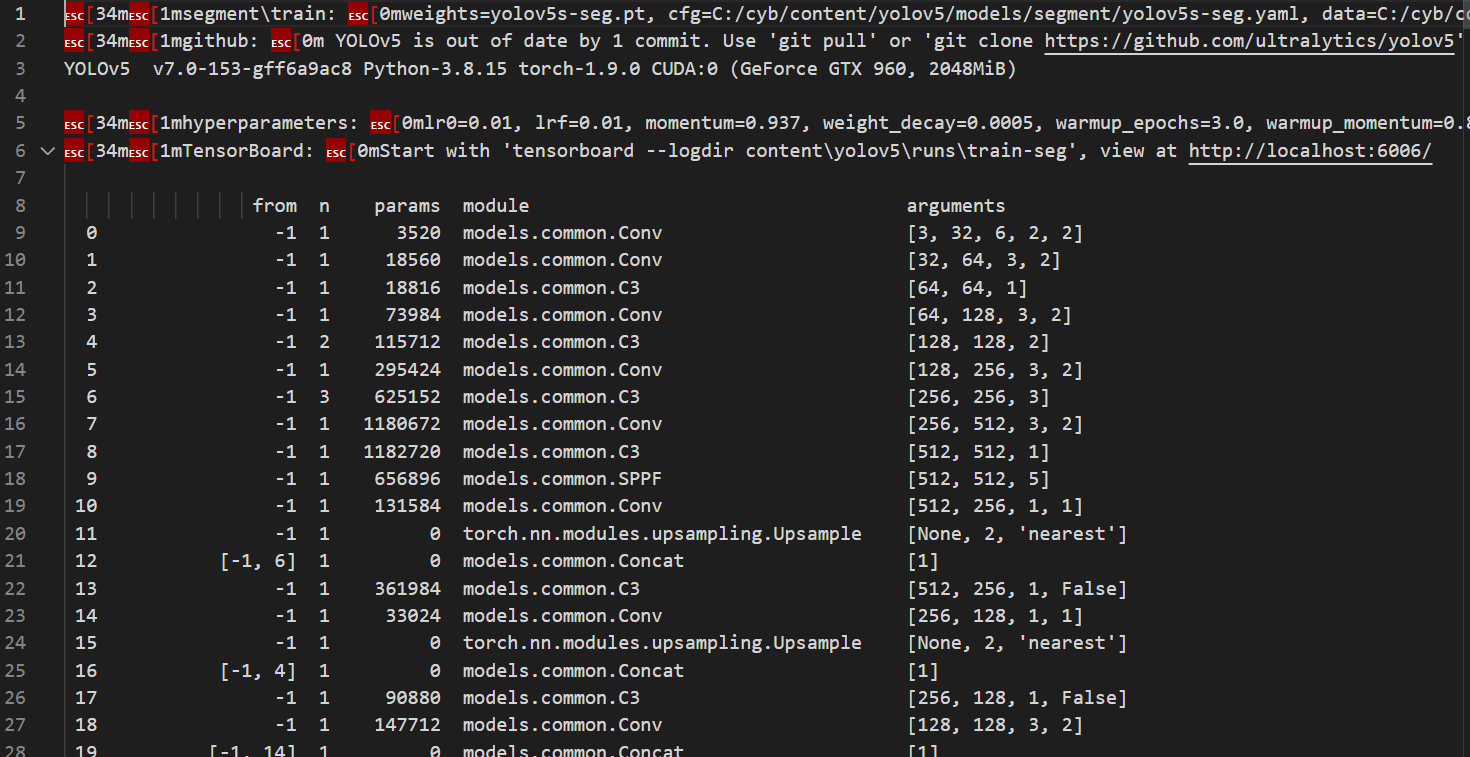
train 결과
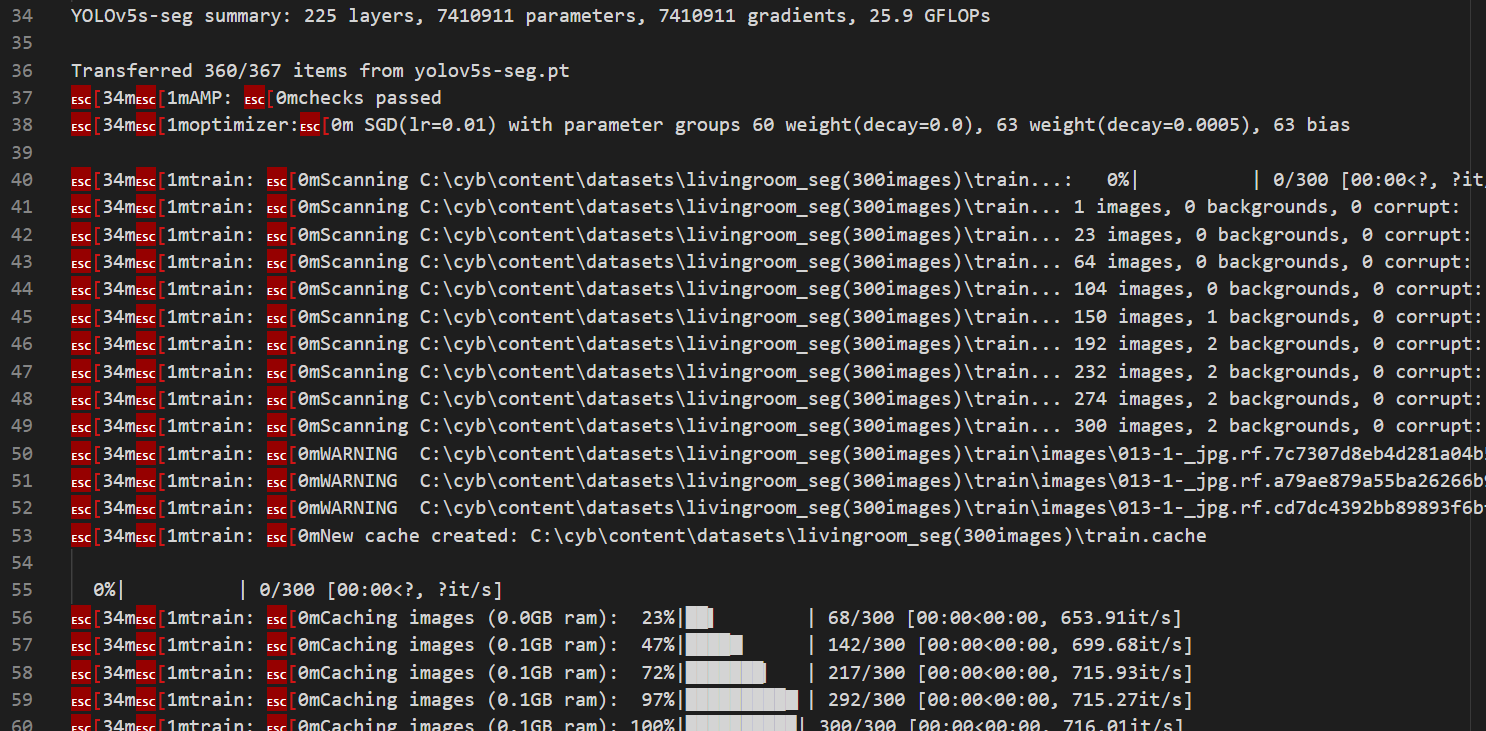
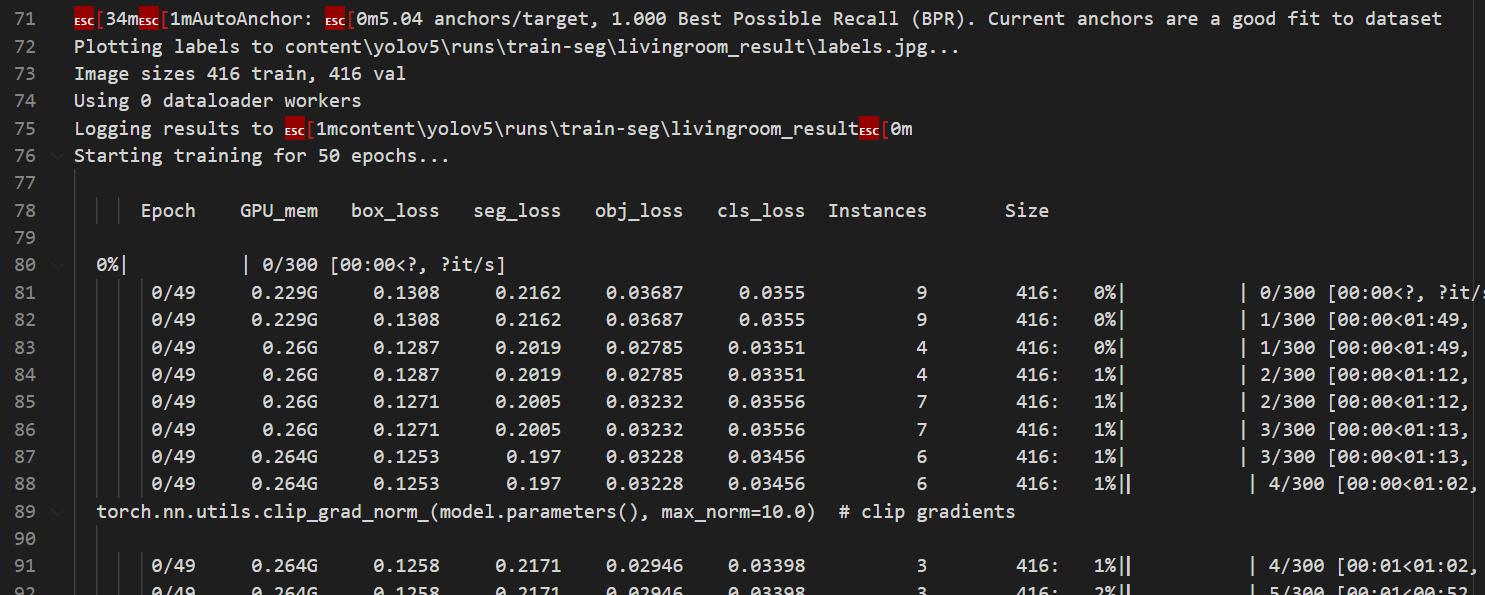
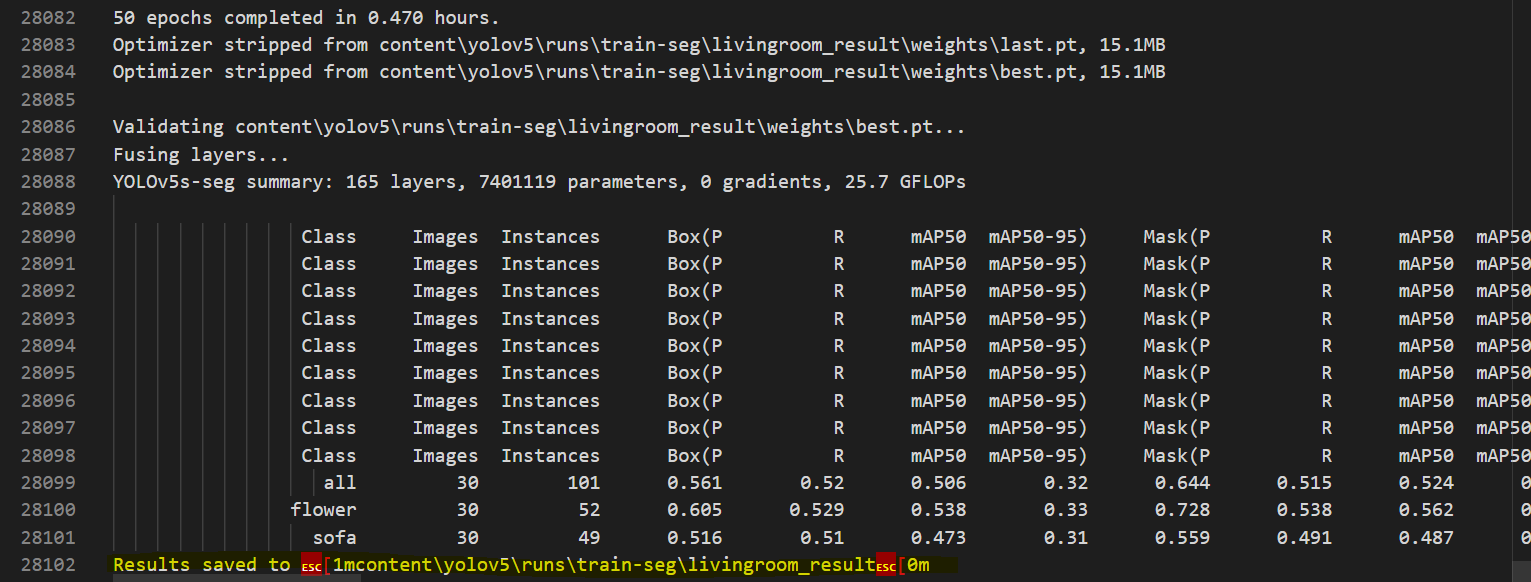

6. detect.py 실행 (이미지 검출 단계)
object detect일때
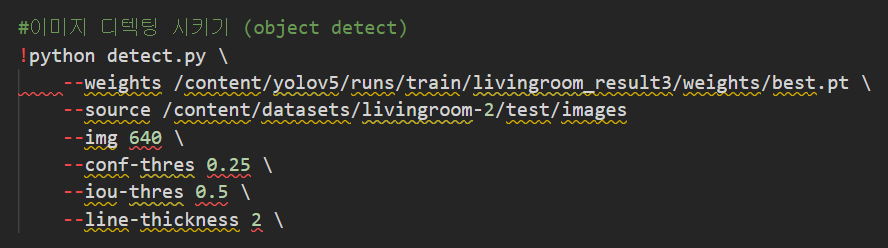
instance segment일때
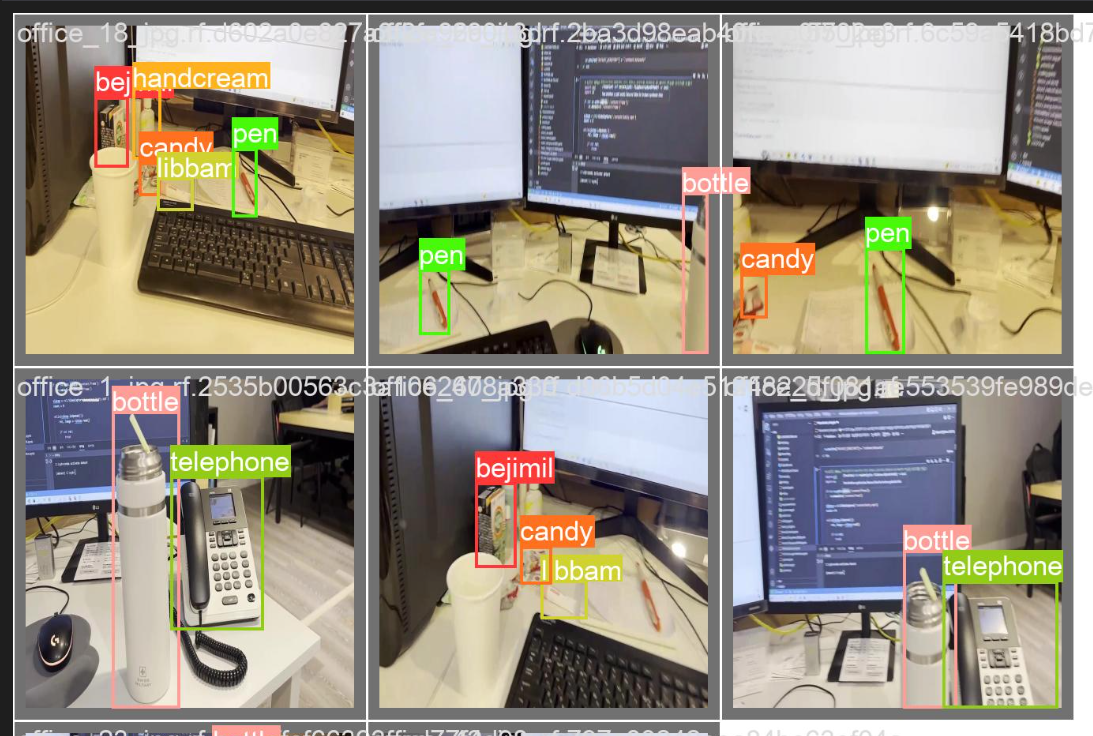
detect 결과
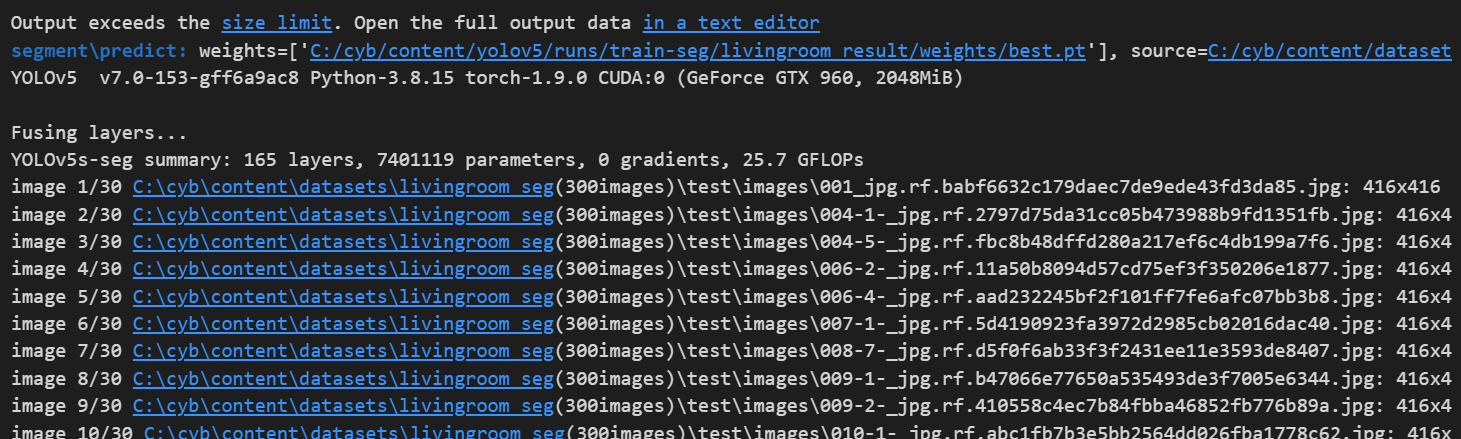

7. detecting된 이미지 출력하여 확인

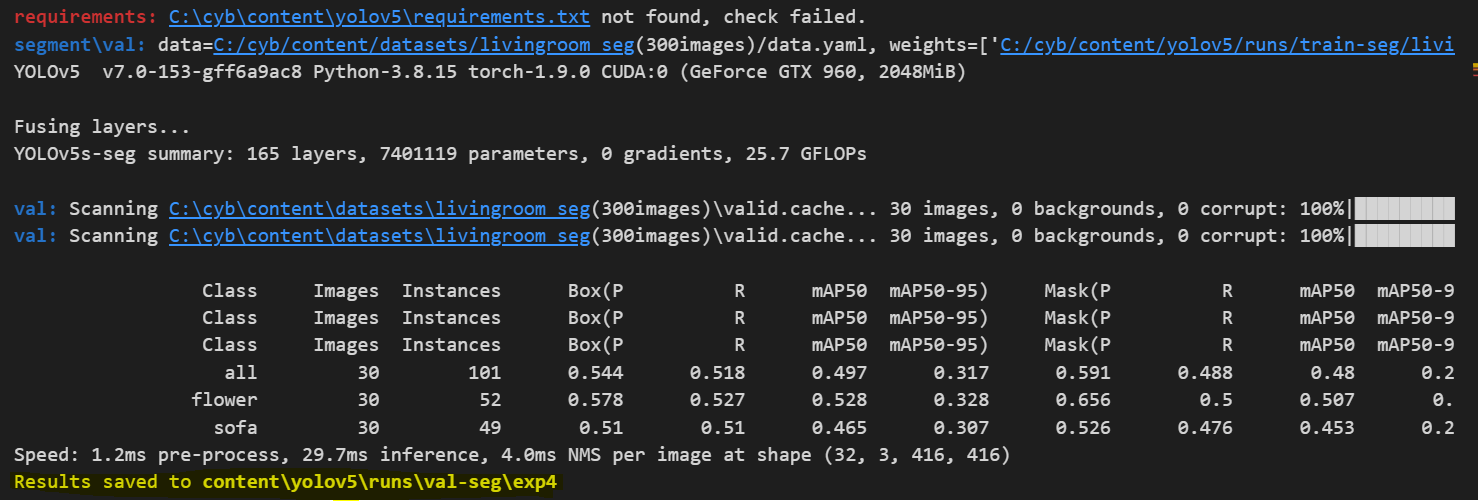
8. val.py 실행 (이미지 검증하기)
기존 test데이터 말고도 한번 더 test하여 검증해보는 단계
object detect일때
instance segment일때
validation 결과
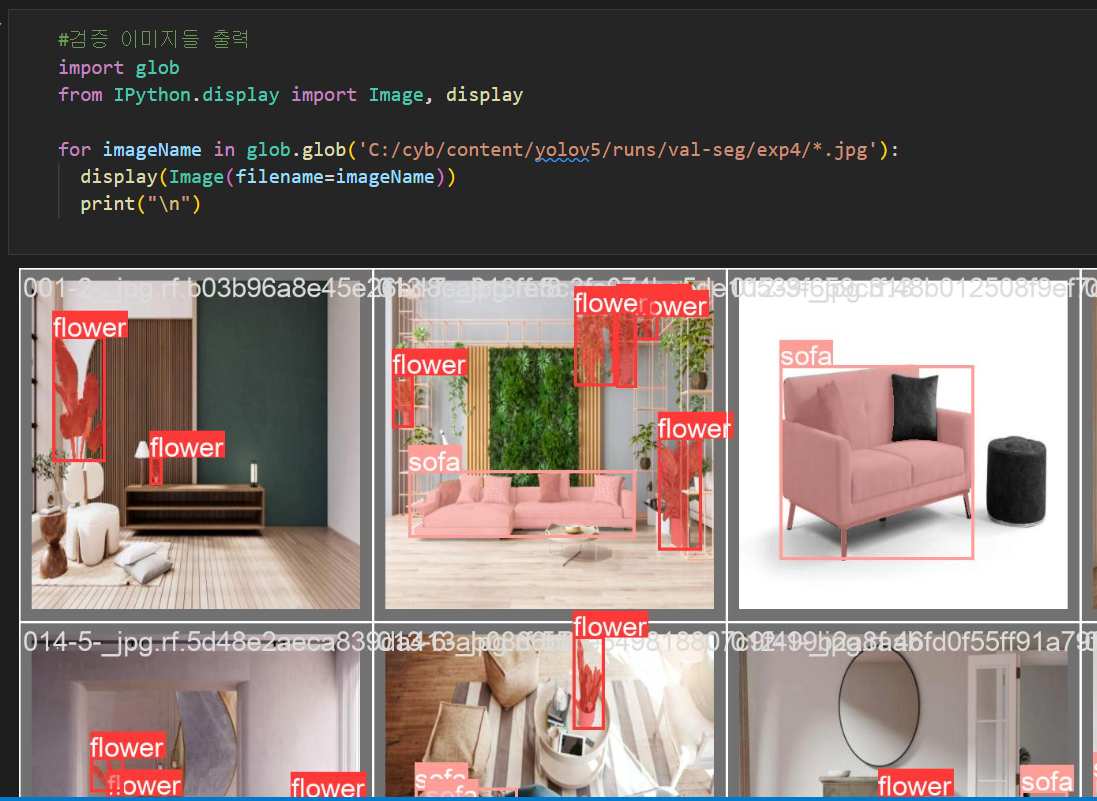
동영상 디텍팅
동영상 디텍팅은 위의 과정과 전부 동일한데, 3번 데이터셋 다운 받기 전 과정 하나 추가
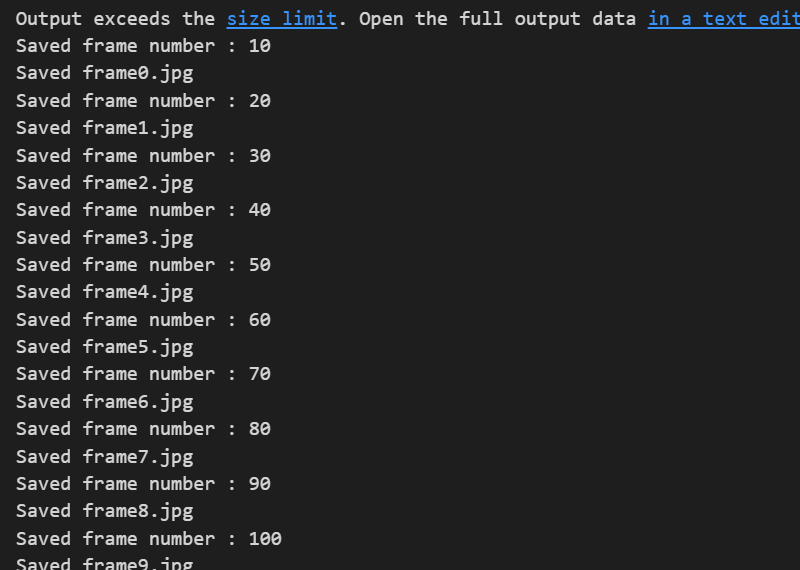
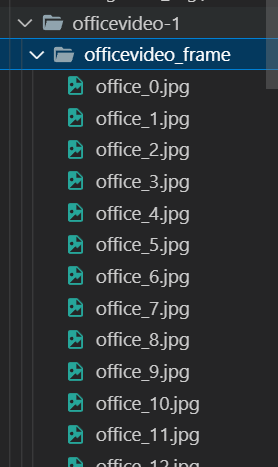
동영상 프레임 저장하여 이미지 생성하기
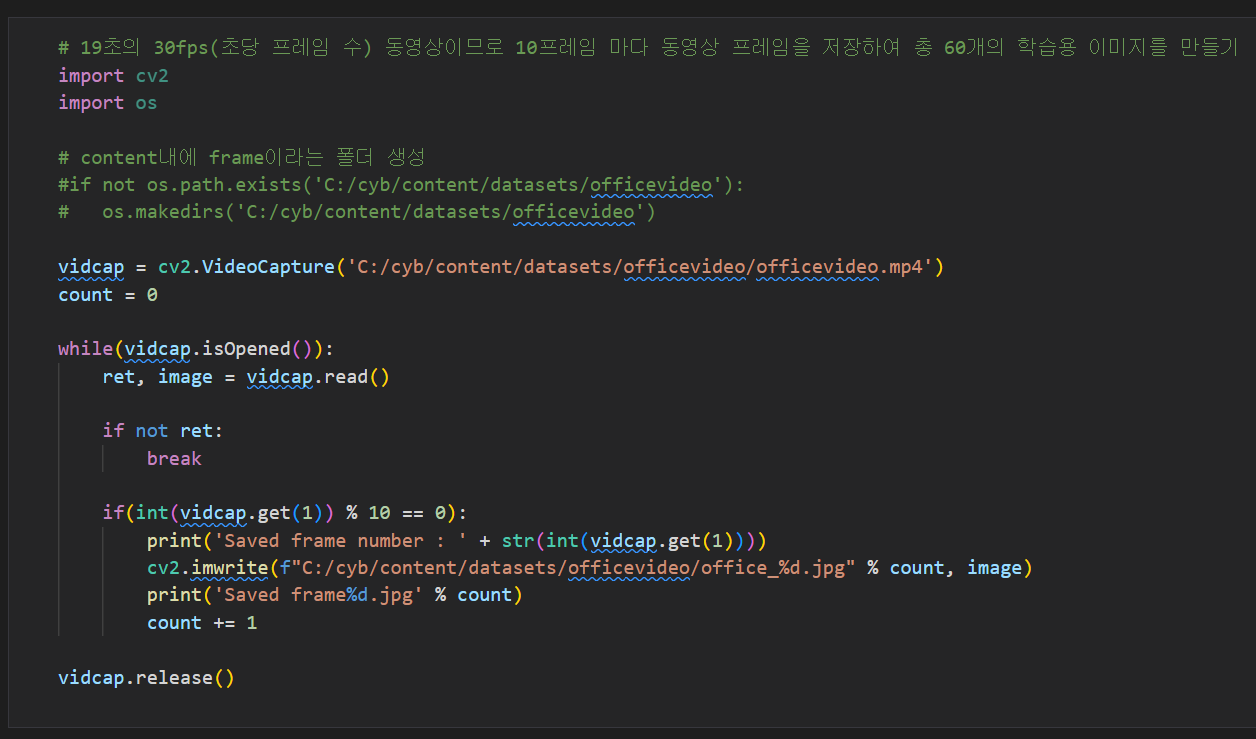
결과 (동영상이 10프레임마다 이미지로 저장됨)