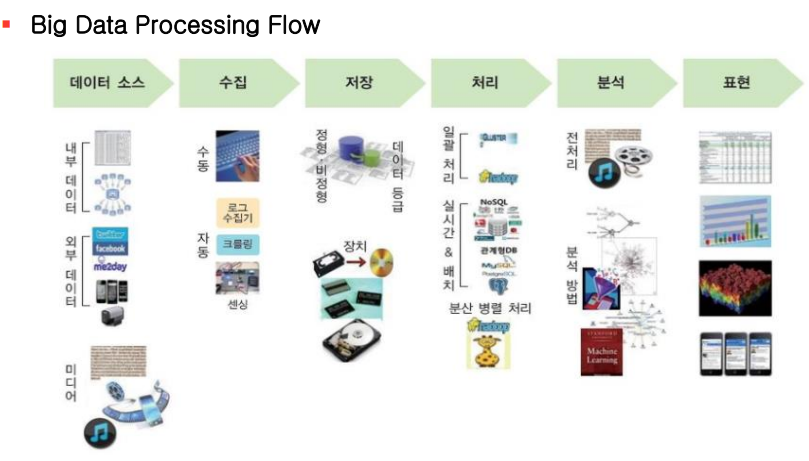
빅데이터 수집 및 저장
1.2023.01.11 파이썬
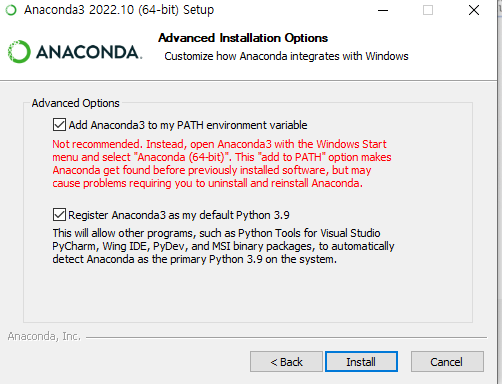
라이브러리 자동 설치하려면 위에꺼도 체크(path 자동 설정해줌)anaconda : 빅데이터, 과학 기술 데이터 처리하는데 필요한 파이썬 라이브러리를 갖고있음개발환경과 수학·과학·데이터분석분야에서 필요한 거의 모든 패키지(NumPy, SciPy, Pandas, Matp
2.2023.01.12 파이썬(함수&문자열)

어떤 일을 수행하는 코드의 덩어리, 또는 코드의 묶음딕셔너리 자료형(dictionary type)으로 표기됨하나하나 꺼내오고 싶을때리스트랑 흡사함예를 들어, 문자열 변수 ‘a’와 정수형인 2의 ‘a+2’와 같은 연산은 동작하지 않지만 ‘a\*2’와 같은 연산은 지원함문
3.2023.01.13 파이썬(스타일 코딩&객체 지향)
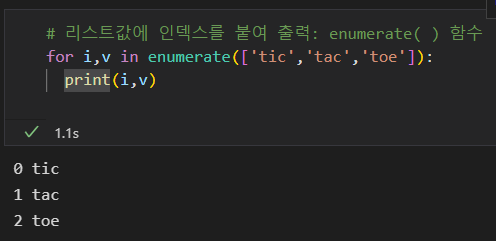
enumerate( ) 함수는 리스트값을 추출할 때 인덱스를 붙여 함께 출력zip( ) 함수는 1개 이상의 리스트값이 같은 인덱스에 있을 때 병렬로 묶는 함수\_ str \_( ) 함수는 클래스로 인스턴스를 생성했을 때, 그 인스턴스 자체를 print( ) 함수로 화면
4.2023.01.16 데이터 분석 라이브러리
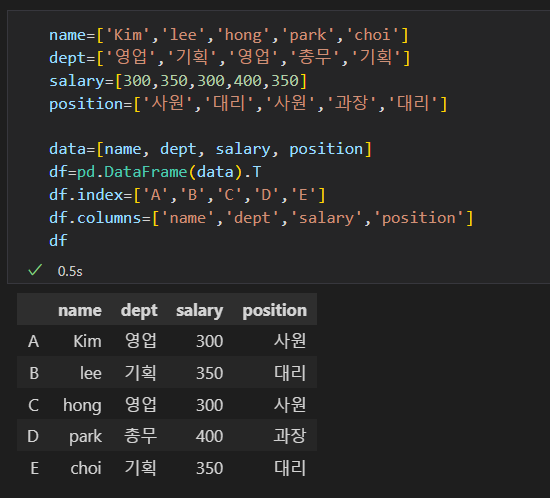
행 데이터 삽입하기실제 data값에는 삭제되어 있지 않음(데이터가 보존됨)df=dr.dropna(how='any') 로 지우면 완전 삭제됨input.csv 파일을 읽어서 output1.csv파일로 저장하기간단하게 판다스를 이용하여 저장하기데이터 수정하기(Cost가 fl
5.2023.01.17 빅데이터
HTTP(HyperText Transfer Protocol) : 웹상에서 클라이언트와 서버간에 정보를 주고 받을 수 있는 통신규약(프로토콜)RSSurl 복사해서 여기서 데이터 수집정적 크롤링아무것도 누르지 않아도 댓글 데이터가 전부 보임동적 크롤링더보기 버튼 눌러야만
6.2023.01.18 정적 크롤링
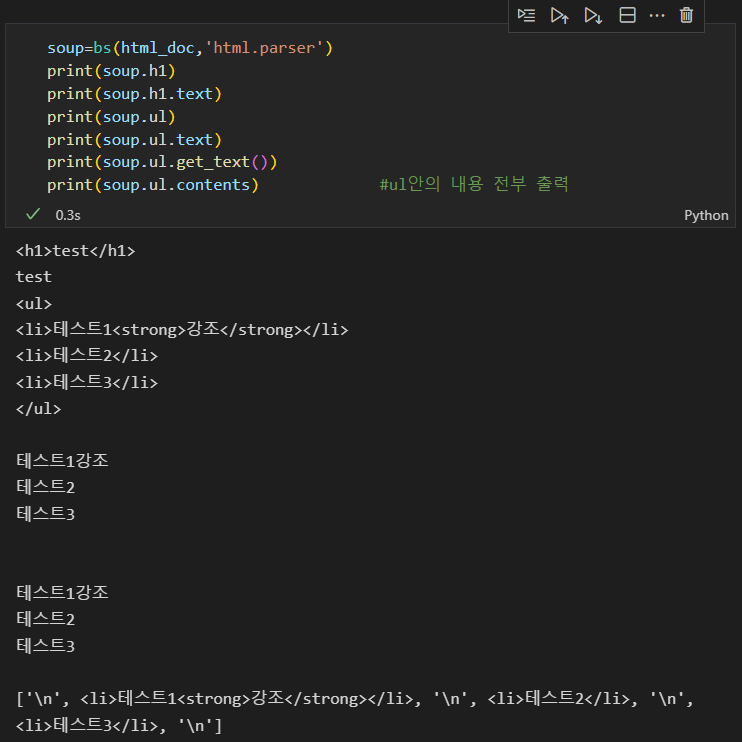
앞에서는 전체 페이지를 스캔해오는 것이고 이제 부분만 스크랩해오는 것일반적으론 첫번째꺼 사용함html이나 body는 생략 가능(보통 다 있기때문에)string과 text 또는 get_text구분태그 여러개 불러올 수 있음100 페이지까지 결과 출력해보기1페이지에 댓글
7.2023.01.19 동적 크롤링
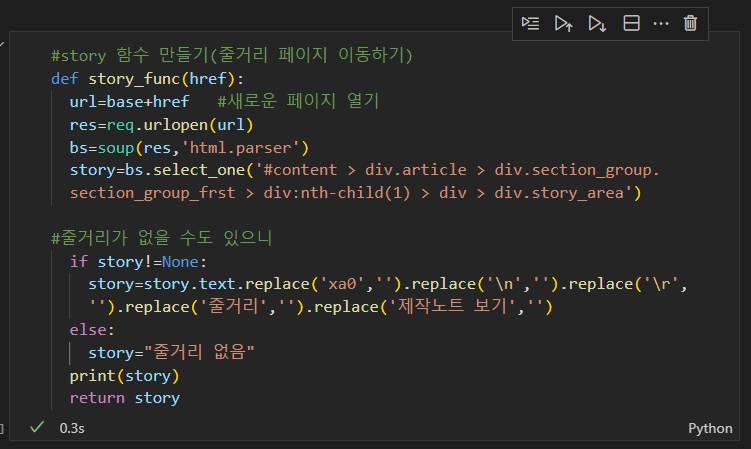
• 화면에 렌더링된 일부 태그의 콘텐츠를 페이지의 소스에서 찾아볼 수 없음• < div > 태그나< span > 태그처럼 소스코드에서 그내용을 찾아볼 수 없음간결한 프로그래밍 인터페이스를 제공 하도록 설계동적 웹 페이지를 보다 잘 지원할 수 있도록 개발도움말
8.2023.01.20 Open API활용 데이터 수집
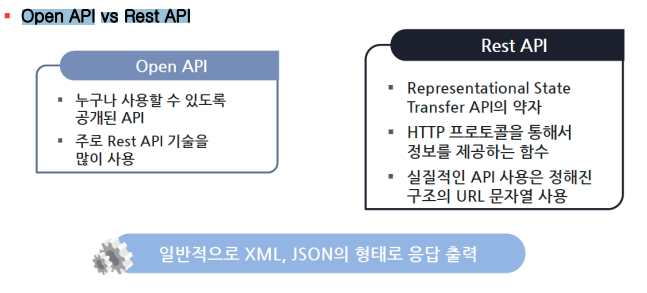
여러 오픈 API를 사용할 수 있음여기서 코드복붙https://developers.naver.com/docs/serviceapi/search/blog/blog.md1\. 전체 작업 설계하기2\. 프로그램 구성 설계하기블로그 검색뉴스 검색\*\*파파고 API A
9.2023.01.25 Open API활용 데이터 수집
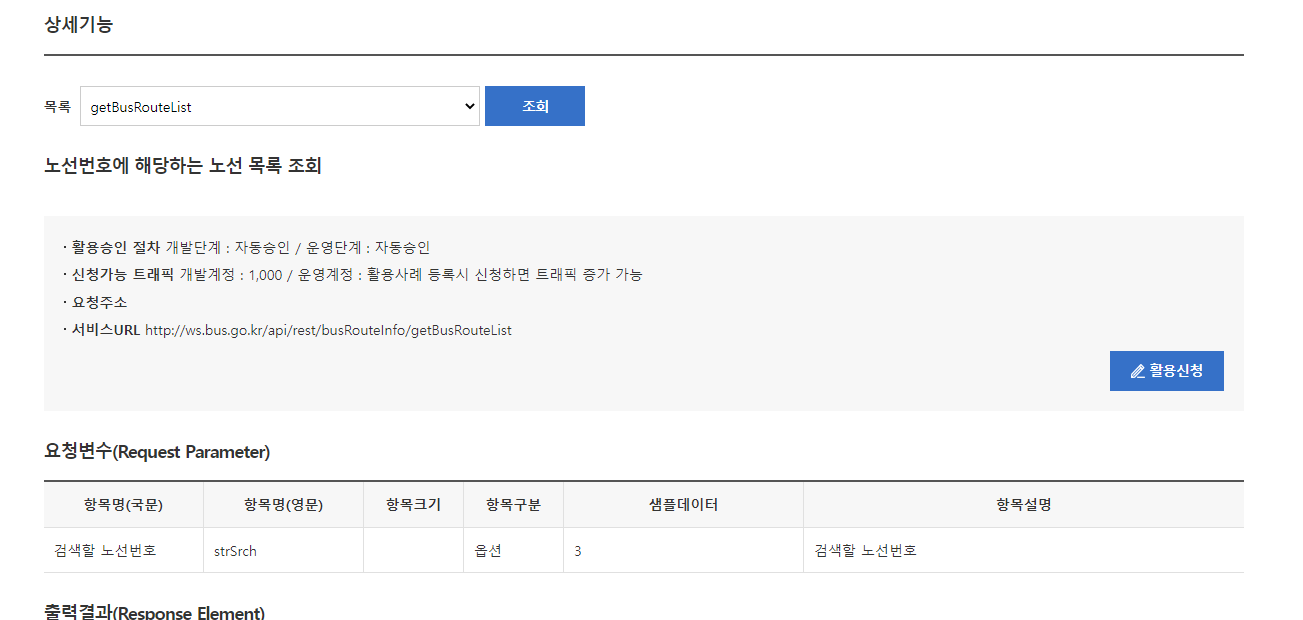
url뒤에 요청변수(Request Parameter) 추가NoSQL 데이터베이스는 전통적인 관계형 데이터베이스보다 덜 제한적인 일관성 모델을 이용하는 데이터의 저장 및 검색을 위한 매커니즘을 제공No SQL(X), Not Only SQL(O)트랜잭션 : 계좌이체와 같이
10.2023.01.26 MongoDB CRUD

db안에 collections을 만들기 전에는 db가 검색되지 않음test라는 db안에 emp라는 collection 만든것무료 클라우드 모니터링• 명령이 수행되는 시간• 메모리 사용률• CPU 사용를• 수행된 명령 수현재 데이터베이스 collection 정보를 리스트
11.2023.01.30 MapReduce
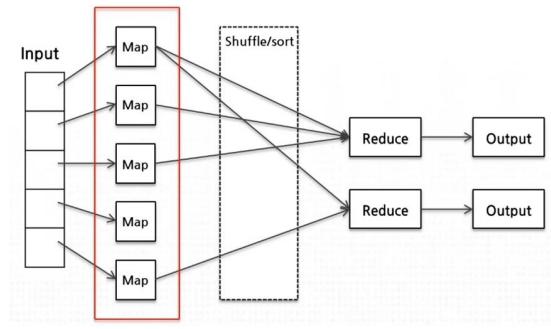
대용량의 데이터를 안전하고 빠르게 처리하기 위한 방법한 대 이상의 하드웨어를 활용하는 분산 프로그래밍 모델Hadoop은 HDFS(Hadoop File System)이라는 대규모 분산 파일시스템을 구출하여 탁월한 성능과 안정성을 보여줌맵리듀스는 대용량 파일에 대한 로그분