
❓개요
프로젝트 요구사항에는 전체 사용자가 보는 교환 목록 페이지가 존재하였습니다. 해당 페이지는 검색도 가능한 페이지입니다. 해당 페이지에 대한 제대로 된 테스트를 진행하기위해 100만건의 데이터를 넣고 진행하였습니다. 데이터를 넣어두었으니 쿼리를 개선한 과정을 작성해보려합니다.
🚨 평범한 페이징 쿼리
@Override
public Page<FindExchangeItemListRepositoryDto> findAllExchangeItemV0(
String keyword,
Long categoryId,
TradeStatus tradeStatus,
Pageable pageable
) {
List<FindExchangeItemListRepositoryDto> contents = queryFactory
.select(Projections.constructor(
FindExchangeItemListRepositoryDto.class,
exchangeItem.id,
exchangeItem.name,
exchangeItem.tradeStatus,
exchangeItem.itemQuality,
exchangeItem.desiredItem,
getFirstImage(),
exchangeItem.user.id,
exchangeItem.user.nickname,
avgStar(),
exchangeItem.description,
exchangeItem.category.name,
exchangeItem.deposit,
exchangeItem.createdAt
))
.from(exchangeItem)
.leftJoin(exchangeItem.user)
.leftJoin(image).on(image.entityId.eq(exchangeItem.id))
.where(
nameEq(keyword),
categoryIdEq(categoryId),
tradeStatusEq(tradeStatus)
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(getOrderSpecifier(pageable.getSort()))
.fetch();
JPAQuery<Long> totalCount = queryFactory
.select(exchangeItem.count())
.from(exchangeItem);
return PageableExecutionUtils.getPage(contents, pageable, totalCount::fetchOne);
}- 상품 리스트들을 출력하는 일반적인 페이징 쿼리입니다.
- 조건문으로는 키워드, 카테고리, 교환 상태를 통해 검색을 할 수 있도록 구현하였습니다.
실제 발생 쿼리
SELECT item.id,
item.name,
item.trade_status,
item.item_quality,
item.desired_item,
(SELECT img.image_url
FROM image img
WHERE img.entity_id = item.id
AND img.entity_type = 'EXCHANGE_ITEM') AS item_image,
item.user_id,
user.nickname,
(SELECT AVG(r.star)
FROM review r
JOIN exchange_item ei ON ei.id = r.exchange_item_id
WHERE ei.user_id = item.user_id) AS user_rating,
item.description,
category.name AS category_name,
item.deposit,
item.created_at
FROM exchange_item item
LEFT JOIN users user ON user.id = item.user_id
LEFT JOIN image img ON img.entity_id = item.id
JOIN category ON category.id = item.category_id
WHERE item.trade_status = 'AVAILABLE'
AND item.name like '%Ni%'
ORDER BY item.created_at DESC,
item.id DESC
LIMIT 0, 20;실행계획
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | DEPENDENT SUBQUERY | ei | ref | PRIMARY,FKr3esc8ba4x0n7nmewe1a4bfok | FKr3esc8ba4x0n7nmewe1a4bfok | 9 | relink.item.user_id | 1 | 100 | Using index | |
| 3 | DEPENDENT SUBQUERY | r | eq_ref | UK4iknanlf7r4u8mqrf6y37rl0r | UK4iknanlf7r4u8mqrf6y37rl0r | 9 | relink.ei.id | 1 | 100 | ||
| 2 | DEPENDENT SUBQUERY | img | ALL | 1 | 100 | Using where | |||||
| 1 | PRIMARY | item | ALL | idx_exchange_item_category_id | 1157431 | 1.85 | Using where; Using temporary; Using filesort | ||||
| 1 | PRIMARY | category | ALL | PRIMARY | 1 | 100 | Using where; Using join buffer (hash join) | ||||
| 1 | PRIMARY | user | eq_ref | PRIMARY | PRIMARY | 8 | relink.item.user_id | 1 | 100 | ||
| 1 | PRIMARY | img | ALL | 1 | 100 | Using where; Using join buffer (hash join) |
- item 테이블에 대한 인덱스 최적화가 필요하다고 판단됩니다. 현재 많은 레코드를 스캔하고 있습니다.
- category와 img 테이블에 적절한 인덱스가 없어 전체 스캔이 발생하고 있습니다.
- 서브 쿼리에 대해 실행 비용이 높으므로 물리적인 테이블을 두어 Join 을 통해 실행 비용을 낮추는 것을 고려해볼 수 있겠습니다.
Postman API Test
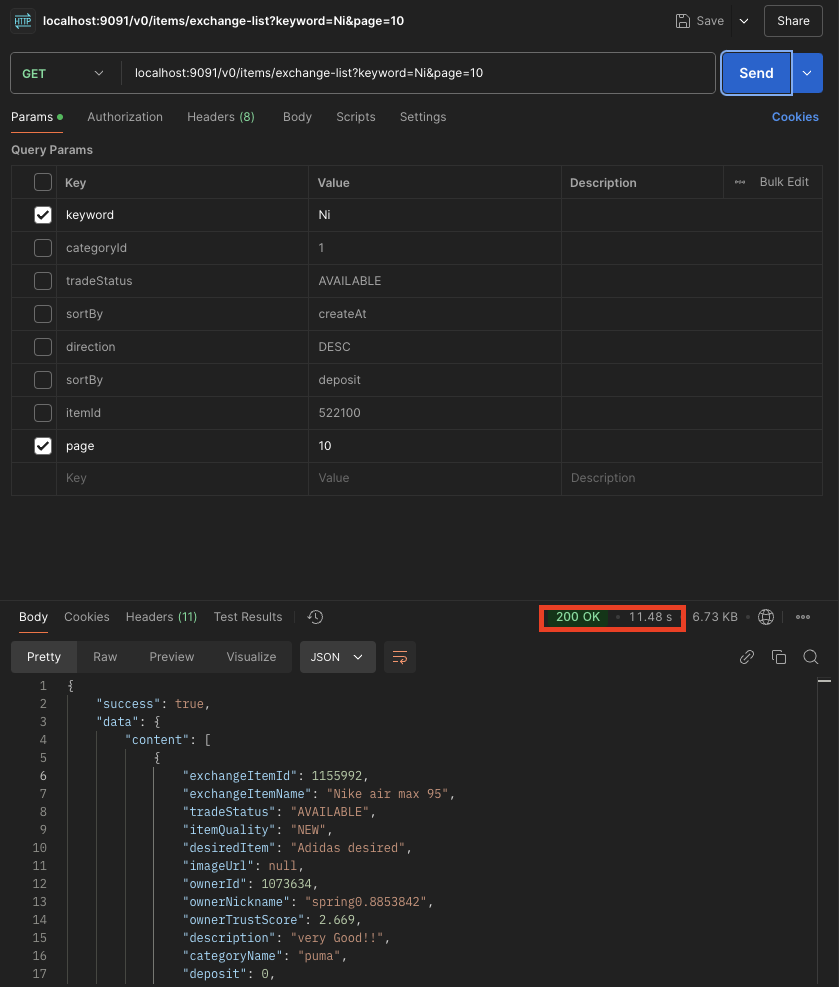
- 11초가 걸리는것을 확인할 수 있습니다.
해당 실행계획을 통해 알 수 있는 사실은 Like 절로 인해 Filesort 가 발생하고 서브쿼리의 대한 비용이 발생한다는 점입니다. 현재 상황에서 모든 점에 대한 성능을 개선하는 것이 아닌 일부만 개선하려고 합니다. 이미지와 카테고리 테이블은 데이터 수가 현재 상황에서 얼마 없기때문에 이미지와 카테고리에 대한 성능개선은 다루지 않겠습니다. 또한 Like 절에 대한 인덱스를 사용할 수 없어 제한적인 성능 개선이 될것으로 예상됩니다.
🛠 커버링 인덱스에 대해
해당 쿼리 실행은 인덱스가 적용되어있지 않다 또한 쿼리 최적화가 이루어지지 않은 상태입니다. 그렇기에 페이지 하나를 조회할 때 11초가 걸리는것을 확인할 수 있습니다. 그렇다면 어떻게 하면 쿼리를 최적화할 수 있을까에 대한 방법을 찾다가 커버링인덱스에 대해 알게되었습니다. 커버링 인덱스는 쿼리를 실행하는데 필요한 모든 데이터가 인덱스에 포함되어있어 실제 테이블 레코드에 접급할 필요가 없는 인덱스를 커버링 인덱스라고 합니다. 제대로 사용하려면 SELECT, WHERE, JOIN 절에서 사용되는 컬럼들에 인덱스를 포함하여야 합니다. 또한 커버링 인덱스를 위해 like 절의 keyword% 로 변경하였습니다. like 절에 대한 인덱스를 탈 수 있도록 수정하였습니다.
일단 필요한 컬럼들의 복합 인덱스를 걸어줍니다.
create index index_exchange_item_search on exchange_item (name, trade_status, created_at desc, id desc);List<Long> ids = queryFactory
.select(exchangeItem.id)
.from(exchangeItem)
.where(
nameEq(keyword),
tradeStatusEq(tradeStatus),
categoryIdEq(categoryId)
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(getOrderSpecifier(pageable.getSort()))
.fetch();
if (CollectionUtils.isEmpty(ids)) {
return new PageImpl<>(new ArrayList<>(), pageable, 0);
}- 메인 쿼리를 실행하기 전에 먼저 ID 값들을 찾아줍니다. 커버링 인덱스가 적용되는 컬럼들이기때문에 쿼리를 나눠서 조회하는게 성능이 더 뛰어납니다.
- 찾은 ID 값을 기준으로 메인쿼리를 실행하게되면 성능 최적화가 적용이 됩니다.
실행 결과
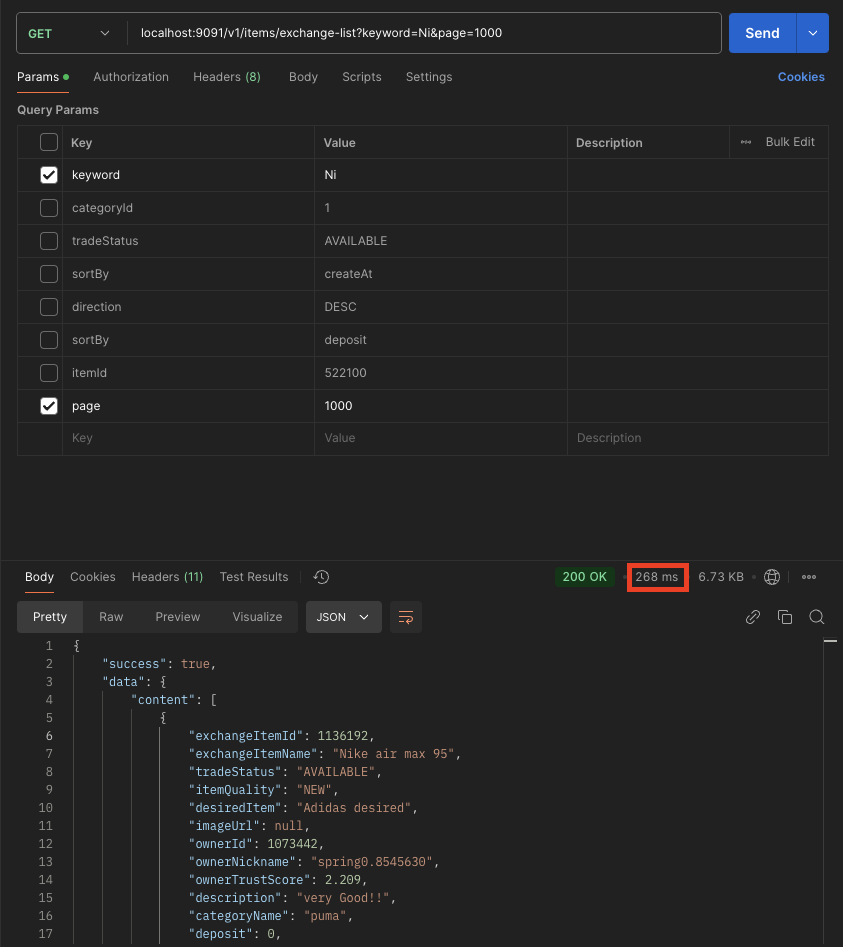
- 268ms 로 확실히 11초에 비해 성능이 개선된것을 확인할 수 있습니다.
📖 톺아보기
where 문에 조건이 여러개 붙으면 복합인덱스를 사용하기 난감해지는 것을 확인했습니다. 경우의 수에 따라 복합인덱스를 여러개를 생성하는 방법도 존재하지만 인덱스 개수만큼 데이터 또한 그만큼 복사되기에 좋지만은 않은 방법입니다. 현재까지 최적화한 부분에대해서 많은 성능개선을 이루어냈지만 여전히 문제점이 있는것은 뒷 페이지로 갈수록 응답속도가 미미하지만 느려지는 것을 확인했습니다. 이 부분 또한 개선이 필요해보이면 더 나아가 캐싱 적용도 고려해볼 수 있습니다. 하지만 캐싱을 적용하기에 여러 캐시전략을 공부하고 프로젝트에 녹여내기 위한 러닝커브가 발생한다는 점에서 해당 프로젝트에서는 적용하지 않을 계획입니다. 캐싱까지 적용을 한다고 한들 검색을 쿼리로 해결하기에는 한계가 있다고 판단했습니다.
