Kirillov, Alexander, et al. "Panoptic segmentation." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
human consistency : 데이터가 미리 정의된 규칙에 의해서만 수정이 가능한 특성
Abstract
우리는 panoptic segmentation(PS)라는 작업을 제안하고 연구한다. Panoptic Segmentation은 일반적으로 분류되는 semantic segmentation(각 픽셀에 클래스 레이블 할당)과 instance segmentation (각 객체 인스턴스를 감지하고 분할) 작업을 통합한다. 제안된 작업은 완전하고 일관된 scene segmentation 을 생성해야 한다. 컴퓨터비전의 초기 연구에서는 image/scene parsing task와 관련된 연구를 다뤘지만, 적절한 metrics 또는 recognition challenge의 부족으로 인해 그 작업은 현재는 인기가 없다. 이를 해결하기 위해 우리는 해석 가능 하고 통합된 방식으로 모든 클래스(stuff & things)를 캡처 가능한 새로운 Panoptic Quality(PQ)라는 metric을 제안한다. 제안된 메트릭을 사용해, 우리는 세 개의 데이터에 대해 panoptic segmentation의 인간 및 기계 성능을 철저하게 연구하였고, 흥미로운 통찰력을 제공한다. 우리 연구의 목표는 이미지 세그멘테이션에 대해 더욱 통합된 관점으로 커뮤니티의 흥미를 되살리는 것이다.
1. Introduction

컴퓨터 비전의 초기에는 , 사람, 동물 등과 같이 셀 수 있는 things가 주목받았다. 이러한 trend에 의문을 제기한, Adelson은 잔디, 하늘, 도로와 같이 비슷한 영역 또는 무정형의 영역인 stuff 를 인식하는 연구의 중요성을 강조했다. stuff와 things 간의 이분법은 오늘날까지 지속되며, 시각 인식 작업의 분할 뿐만 아니라 스터프와 물체 작업에 대한 전문화된 알고리즘에서도 반영된다.
Stuff를 연구하는 것은 일반적으로 semantic segmentation이라고 알려진 작업이다. Stuff는 비형태적이고 셀 수 없어, 이 작업은 이미지의 각 픽셀에 클래스 레이블을 할당하는 것으로 정의된다 (주의 : semantic segmentation은 물체 클래스를 stuff로 다룬다.) (Fig1(b)). 반면, things에 대해 연구하는 것은 object detection 또는 instance segmentation작업으로 제안된다. 해당 연구의 목표는 각 object를 detect하고, bbox나 segmentation mask로 표현하는 것이다(Fig1 (c)). 겉으로는 관련이 있는 것처럼 보이지만, 두 visual recognition task에서 dataset, detail, metric 은 매우 다르다.
semantic 과 instance segmentation의 사이의 불일치는 두 작업에 대한 방법론의 분리로 이어졌다. Stuff Classifier는 일반적으로 fully convolution nets의 확장(dilations) 으로 만들어지지만, object detector(Thing Classifier)는 종종 object proposal을 사용하고, region-based로 구성된다. 지난 10년 동안 이러한 작업의 알고리즘 발전은 많이 이루어졌지만, 아직 분리되어 있는 작업의 중요한 부분이 간과되고 있다.
자연스러운 질문이 발생한다: stuff와 thing 사이의 조화는 없을까? 그리고, 풍부하고 일관된 scene segmentation을 생성하는 통합 vision system을 디자인하는 더욱 효과적인 방법은 없을까? 이러한 질문들은 자율주행 또는 증강 현실과 같은 현실세계 응용 분야의 관련성 때문에 특히 중요하다.
흥미롭게도, semanctic과 isntance segmentation이 현재 지배적이지만, 딥러닝 이전에는 scene parsing, image parsing 또는 전체적인 장면 이해(holistic scene understaing)와 같은 다양한 이름으로 표현되는 joint task에 관심이 있었다. 이런 연구는 실용적임에도 현재는 인기가 없는데, 아마도 적절한 metrics의 부족 또는 recognition challenge 때문일 것이다.
우리의 연구는 이러한 방향(direction)을 부활시키는 것을 목표로 한다. 우리는 다음의 task를 제안한다.
(1) stuff와 thing class를 모두 포함
(2) 간단하지만 일반적인 출력 형식을 사용
(3) 균일한 평가 매트릭을 제안
이전 연구와 명확하게 구별하기 위해, 우리는 결과적으로 얻어지는 작업을 “panoptic segmentation (PS)” 이라고 한다. panoptic의 정의는 “한 뷰에서 보이는 모든 것”이다. 현 연구의 맥락에서, panoptic은 segmentation의 통합되고(unified), 전체적인(global) 관점을 의미한다.
우리가 panoptic segmentation에서 채택한 task format은 간단하다: 이미지의 각 픽셀은 의미 라벨과 instance id를 할당해야 한다. 동일한 label과 ID를 가진 픽셀은 같은 object에 속한다. Stuff label의 경우 instance ID가 무시된다. (Figure 1(d)) 이러한 포맷은 전에도 채택되어왔다. 특히, 중첩되지 않은 instance segmentation을 생성하는 방법들에 의해 사용되었다. 우리는 Stuff와 things를 모두 포함하는 joint task를 위해 이러한 형식을 채택한다.
Panoptic Segmentation의 기초적인 부분은 평가에 사용될 task metric 이다. 이미 많은 기존의 metric이 semantic 또는 instance segmentation에 대해 인기를 끌고 있지만, 이러한 metric은 주로 Stuff 또는 Things에 가장 적합하다. 하지만, 둘 다에 적합하지는 않다. 우리는 개별적인 Metric을 사용하는 것이 Stuff와 Things segmentation을 독립적으로 연구하는 주요 이유라고 생각한다. 이를 해결하기 위해, 우리는 Panoptic Quality(PQ) Metric를 소개한다(Sec 4). PQ는 간단하고 유익하며 가장 중요한 것은 stuff와 things 모두에 대한 성능을 균일한 방식으로 측정할 수 있다는 것이다. 우리의 희망은(?) 제안된 joint metric이 joint task에 좀 더 광범위한 채택(?연구수행?)에 도움이 될 것이라는 것이다.
Panoptic Segmentation task는 semantic과 instance segmentation을 모두 포함하지만, 새로운 알고리즘 challenge 도 도입한다. semantic segmentation과는 달리, 이는 개별 object instance를 구별해야 한다. 이는 fully convolution net에게 도전과제이다. instance segmentation과 달리, object segments는 반드시 non-overlapping이어야 한다. 이는 각 object를 독립적으로 수행하는 region-based method에 도전과제이다. stuff와 things 사이의 불일치를 해결하는 일관된 image segmentation을 생성하는 것은 현실세계에 사용하기 위한 중요한 단계이다.
PS를 위한 gt와 알고리즘 포맷이 동일함으로서, 우리는 panoptic segmentation에서 human consistency(인간 일관성??)을 상세히 연구할 수 있다. 이는 recognition vs. segmentation과 stuff vs. things와 같은 세부적인 문제(?)을 포함해 PQ metric을 더욱 자세히 이해하게 해준다. 또한, human PQ를 측정하는 것은 machine performance의 이해를 돕는다. 이는 PS에 대한 다양한 데이터셋에서 성능 포화를 모니터링하게 해주기 때문에 중요하다.
마지막으로, 우리는 PS에 대한 machine performance에 대한 초기 연구를 수행한다. 이를 위해, 우리는 후처리 과정을 통해 semantic 과 instance segmentation 두 독립적인 시스템의 출력을 결합하는 간단한, 사실 차선책인… 휴리스틱을 정의한다(해석하기가 좀 까다롭네). 우리의 휴리스틱은 PS를 위한 baseline을 구축하고, 매인 알고리즘 챌린지에 대한 insight를 제공한다.
우리는 stuff와 things 모두가 annotation 되어있는 3개의 유명한 데이터셋으로 human과 machine performance을 연구했다. 이는 Cityscapes, ADE20k, Mapillary Vistas dataset을 포함한다. 각 데이터셋에 대해, 우리는 SOTA를 달성했다. 추후에는 우리의 분석을 stuff에 대해 annotation된 COCO 데이터셋에 대해 확장할 예정이다. 이러한 데이터셋에 대한 우리의 결과는 panoptic segmentation에 대한 human, machine performance 연구에 견고한 기반을 형성한다.
2. Related Work (간단히)
Intro
새로운 데이터셋과 작업은 컴퓨터비전 역사의 중요한 역할을 해왔다. 그들은 발전을 촉진시키고, 우리 분야에서 돌파구를 만들며, 무엇보다 중요한 것은 우리의 커뮤니티(연구분야?)가 만들어지는 과정을 측정(measure)하고 인식하는 것에 도움을 준다. 예를 들어, ImageNet은 visual recognition을 위한 딥러닝 기술의 인기화를 이끌었고, 데이터셋과 작업이 가진 잠재적인 힘을 보여줬다. Panoptic segmentation을 소개하는 우리의 목표도 비슷하다 : 우리의 연구분야를 도전과제화(라고 해석해야할까)하고, 새로운 방향성에 대한 연구를 이끌어내고, 생각치 못한 혁신을 기대하는 것이다. 다음에 우리는 관련 연구를 리뷰한다.
Object detection task
- 초기 : face detection, dataset : ad-hoc → bbox object detection을 알림
- 이후 : pedestrian detection
- PSCAL VOC → upgrade task
- 최근, COCO dataset
→ instance segmentation까지 확장, high-quality dataset인 COCO는 새로운 연구뱡향을 찾는데 도움을 줬고, 최근까지고 instance segmentation에 대한 해결책을 이끌고 있다.
→ 우리 연구의 목표도 이와 비슷!
Semantic segmentation task
-
역사가 많다.
-
FCN 등에서 사용된 데이터셋은 stuff와 thing 클래스를 모두 담고있다. 하지만, 인스턴스의 개별적인 object는 구별하지 못한다.
-
최근에는, 새로운 segmentation dataset이 발견되었다. - Cityscapes, ADE20k, Mapillary Vistas
→ 이는 semantic과 instance segmentation 둘 다 지원한다.
→ 중요한건, PS에 필요한 모든 information이 포함되어있다!
⇒ 즉, panoptic segmentation을 위해 새로운 데이터 수집 없이도 작업을 수행할 수 있다는 것!!
Multitask Learning
- 많은 visual recognition task를 위한 딥러닝의 성공으로, 하나의 프레임워크에서 다양한 vision problem을 수행할 수 있는 광범위한 능력을 가진 Multitask Learning에 관심이 쏠리고 있다.
- UberNet - 단일의 프레임워크로 object detection과 semantic detection을 포함한 저수준에서부터 고수준의 visual task를 수행한다.
- 해당 분야가 상당히 흥미롭지만, panoptic segmentation은 multi-task problem이 아니라 오히려 하나의 통합된 image segmentation이다.
- 특히, multitask는 stuff와 things에 대해 독립적이고 일관성이 없는 출력이 가능하지만, PS는 단일의 일관성있는 scene segmentation을 요구한다.
Joint segmentation task
- 딥러닝 이전 시대에는, scene에 대한 일관성있는 해석에 상당히 관심이 있었다.
- Image Parsing의 초기 연구 - segmentation, detection, recognition을 공동으로 모델링하기 위한 베이지안 프레임워크를 제안
- 이후, 그래픽 모델을 기반으로한 일관성있는 stuff와 things segmentation에 대한 연구 진행 → 이러한 방법은 공통된 연구 동기를 가졌으나, task definition에 대한 합의가 없었고, stuff와 things를 평가하는데 분리된 metrics을 쓰는 등의 다양한 metric을 사용해 출력 결과가 달랐다. ⇒ 최근에 이러한 방향성의 연구가 인기 없는 주된 이유
- 우리는 해당 연구의 방향성을 부활시키고자 하지만, 전의 연구와는 달리 우리는 작업 그자체에 초점을 둔다.
- 특히, PS는 다음과 같은 특징을 갖추고 있다. (1) stuff 와 thing class를 모두 포함 (2) 간단하지만 일반적인 출력 형식을 사용 (3) 균일한 평가 매트릭을 제안
- Joint segmentation에 대한 이전의 연구는 다양한 포맷과 stuff와 things를 위한 disjoint metric을 사용했다.
- 서로 겹치지 않는 instance segmentations를 생성하는 방법들은 PS와 비슷한 포맷을 가지지만, 그 방법들은 thing class만을 위한 것이다.
- stuff와 things 두개를 해결하기 위해 우리는 간단한 포맷을 사용하고, 통합된 메트릭을 제안함으로서, joint task에 대한 다양한 연구수행을 기대한다.
Amodal segmentation task
“semantic amodal segmentation(CVPR 2017)”은 시각적으로 관측 가능한 부분 뿐만이 아니라, 물체나 영역의 완전한 범위를 포함하는 것을 말한다. 우리의 모든 관측 가능한 영역에 대해서만 집중하고 있지만, panoptic segmentation에서 amodal setting으로 확장은 흥미로워보인다.
3. Panoptic Segmentation Format
Task Format
panoptic segmentation의 포맷은 매우 간단하다. 로 인코딩된 L개의 semantic class 셋이 주어지면, 작업은 이미지의 각 픽셀 를 ( : 각 픽셀 i의 semantic class, : instance id)에 매핑하는 panoptic segmentation 알고리즘을 요구한다. 는 동일한 클래스의 픽셀을 다른(구별되는) 세그먼트로 그룹화한다(아마도 인스턴스 단위로?). GT 어노테이션은 동일하게 인코딩되었다. 모호하거나 클래스 밖에 있는 픽셀은 특수한 void label을 할당할 수 있다. (즉, 모든 픽셀에 semantic label이 있는 것은 아니다)
Stuff and things label
semantic label은 의 부분집합으로 구성되어있다. 즉, 이다. 이러한 부분집합은 stuff와 things 라벨에 해당한다. 픽셀이 라벨이라면, instance id 는 관련이 없다. 즉, stuff class는 모든 픽셀이 같은 instance(예시. 동일한 하늘)에 속한다. 반면에, 인 경우, 가 할당된 모든 픽셀은 같은 instance(예시. 동일한 차)이다. 반대로, single instance에 속한 모든 픽셀은 반드시 동일한 (를 가져야 한다.
Relationship to semenatic segmentation
PS 작업의 포맷은 semantic segmentation의 단순한(?) 일반화이다. 실제로, 두 작업 모두 각 픽셀에 semantic label을 할당해야한다. 만약 gt가 instance를 지정하지 않거나, 모든 클래스가 stuff일 경우에도 형식은 동일하다(task metric은 다르다). 덧붙여, (우리의 연구는) 이미지 당 여러 인스턴스가 있는 thing class를 포함하는 것이 (기존의) semantic segmentation 작업과의 차이다.
Relationship to semantic segmentation
PS 작업의 포맷은 semantic segmentation의 단순한(?) 일반화이다. 실제로, 두 작업 모두 각 픽셀에 semantic label을 할당해야한다. 만약 gt가 instance를 지정하지 않거나, 모든 클래스가 stuff일 경우에도 형식은 동일하다(task metric은 다르다). 덧붙여, (우리의 연구는) 이미지 당 여러 인스턴스가 있는 thing class를 포함하는 것이 (기존의) semantic segmentation 작업과의 차이다.
Relationship to instance segmentation
instance segmentation 작업은 이미지에서 각 객체 instance를 세분화하는 방법을 요구한다. 그러나, 이는 overlap segmentation을 허용하는 반면, panoptic segmentation은 각 픽셀에 하나의 semantic label과 하나의 instance id만 지정할 수 있다. 때문에 PS의 경우, 한 픽셀에 클래스가 겹치는게 불가능하다! 이 차이는 성능 평가에 중요한 역할을 한다.
Confidence scores
semantic segmentation과 유사하지만, instance segmentation과는 다르게, PS에는 각 segment에 대한 confidence score가 필요하지 않다. 이는 Panoptic segment를 human(gt 따는 사람을 말하는듯)과 machine 모두에 대해 조화된(???) task로 만든다: 둘 다 동일한 유형의 이미지 annotation을 생성해야 한다. 이는 PS에 대한 human consistency 평가를 간단하게 만든다. 이는 human annotator가 명시적인 신뢰도 점수를 제공하지 않기 때문에 쉽게 연구할 수 없는 instance segmentation과는 비교된다. 물론, confidence score는 downstream system에 더 많은 유용한 정보를 주기 때문에 , PS 알고리즘이 confidence score를 갖는 것이 여전히 바람직할 수는 있다. (하지만 안쓴다.)
4. Panoptic Segmentation Metric
기존 Metric의 문제점
-
기존 semantic segmentation, instance segmetation에서 사용된 metric은 Stuff 클래스(셀 수 없는 클래스. e.g., 하늘, 길)와 Thing 클래스(셀 수 있는 클래스. e.g., 자동차) 모두를 포함한 joint task에 사용할 수가 없었다.
-
기존에 수행된 joint task에서는 stuff, thing에 대해 독립적인 metric을 사용해 평가했지만, 이는 비교를 더 어렵게 만들고 개발을 방해한다.
→ stuff와 thing 모두를 통합하는 metric을 제안.
Panoptic Quality 원칙
- Completeness : stuff와 thing 클래스를 통합하여 다루며, task의 모든 부분을 capturing 한다.
- Interpretability : 의미를 명확히 알 수 있는 Metric.
- Simplicity : 빠른 평가를 가능케 하는 효율적인 Metric
Panoptic Quality 과정 (4.1. ~ 4.2.)
- Segment Matching
- PQ computation given matching
4.1. Segment Matching 단계
Predicted seg와 GT seg가 IoU 0.5보다 큰 경우 서로 매칭 가능하고, 이때 각 GT는 이에 대응한 최대 하나의 predicted seg에 대해서만 매칭한다. (왜 하나만 매칭할 수 있는지 증명함.)
증명. g를 GT로, p1, p2를 두 Predicted seg로 가정한다. 이 때, p1과 p2는 겹치지 않는다.
이기 때문에, 아래를 따른다.
→ i in 1, 2는 p1, p2를 말하는 것.
→ p1과 p2는 겹치지 않기 때문에 이고, 이에 아래를 만족한다.
→ 때문에, 라면, 보다 작기 때문에, 0.5보다 큰 predicted seg는 하나만 나온다.
예시
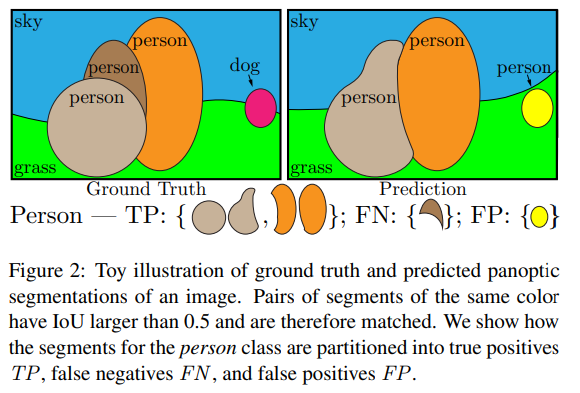
→ GT, Pred에서 동일한 색상의 Segment Pair는 IoU가 0.5보다 커서 매칭된 것이다.
4.2. PQ Computation
- 각 클래스에 대해 독립적으로 PQ를 계산하고 모든 클래스에 대해 평균을 낸다.
- 각 클래스의 매칭은 predicted seg와 GT seg는 TP - matched pairs of seg, FP - unmatched predicted segs, FN - unmatched gt segs 으로 나뉜다. 이 세 집합을 고려해서 PQ를 정의한다.
→ 은 단순히 matched seg의 평균 텀이다.
→ 은 매칭되지 않은 세그먼트에 페널티를 주기 위해 추가했다.
→ 이때, 모든 segments는 segment 영역과 관계 없이 동등한 중요도를 가진다.
⇒ PQ를 TP의 크기로 곱하거나 나누면, PQ는 Segmentation Quality(SQ, 왼쪽)와 Recognition Quality(RQ, 오른쪽) 텀의 곱으로 볼 수 있다.
→ SQ는 단순히 매칭된 세그먼트의 평균 IoU이다.
→ RQ는 detection에서 평가 지표로 많이 사용되는 score 이다.
→ 단, SQ가 매칭된 세그먼트에 대해서만 측정되기에 두 값은 독립적이지 않다.
⇒ 그러면, 빈 영역과(Void labels)과 인스턴스들의 그룹은 어떻게 다루는가?
4.2. Handling Void Labels & Group Labels
Void Labels
이는 두가지로 나눌 수 있다!
- 클래스 외의 픽셀들
- 모호하거나 모르는 픽셀
→ 사실 이 경우를 구별할 수 없는 경우도 종종 있다. 때문에, void pixel에 대한 예측은 따로 평가하지 않는다.
구체적으로,
- 매칭 중에 GT에서 빈 영역으로 처리된 predicted GT segment는 prediction 과정에서 제거되어, IoU computation에 영향을 미치지 않는다.
- 매칭 후에는
matching threshold 이상인,void pixel을 포함하고 있는 unmatched predicted segment는 제거되기 때문에 FP로 카운트 되지 않는다.
Group Labels
그룹 레이블은 같은 클래스인 인접 클래스를 정확하게 구분하기 어려운 경우이다.
- PQ 계산 중에는 그룹 영역이 사용되지 않는다.
- 매칭 후에는 제거되어 FP로 계산되지 않는다. (Void Label와 같은 이유)
4.3. 기존 Metric과 비교
-
Semantic Segmentation Metric : pixel accuracy, mean accuracy, IoU
→ 이는 픽셀 레벨에서만 작동하고, 객체 수준의 레이블은 무시한다.
-
Instance Segmentation Metric : AP
→ AP는 각 객체 Segment에 대해 confidence score 를 요구하는데, 이는 Semantic Segmentation에서는 사용되지 않는 단점이 있다.
→ 때문에 Semantic Segmentation나 Panoptic Segmentation을 측정할 수 없다.
-
Panoptic Segmentaion : PQ
→ PQ는 모든 클래스를 동등하게 다루고, SQ, RQ로 분해 가능하다.
→ PQ는 모든 클래스에 대한 평가를 통합하여 제공한다.
5. Panoptic Segmentation Dataset
Intro
- semantic, instance segmentation annotation이 수행된 3개의 public dataset 이용.
- 이후에는 COCO dataset으로 확장할 예정 (현재 COCO dataset은 overlap을 허용하기 때문에 이를 해결할 것)
Cityscapes
5000 개의 이미지 (2975 train, 500 val, 1525 test)
- 19개의 class (8개는 instance level segmentation)
ADE20k
25000 이상의 이미지(20000 train, 2000 val, 3000 test)
- things : 100개 class
- stuff : 50개 class
Mapillary Vistas
25000개의 street-view 이미지(18000 train, 2000 val, 5000 test)
- things : 37개 class
- stuff : 28개 class
6. Human Consistency Study
Intro
Panoptic Segmentation의 장점 중 하나는 human annoatation 일관성을 측정 가능하다는 것이다. 이 자체로도 흥미롭지만, human consistency 연구는 우리가 제안한 메트릭의 human consistency 의 다양한 분야의 돌파구(해결책?) 포함한 디테일을 이해하는데 도움이된다. 이는 알고리즘 선택에 따른 분석을 편향시키지 않으면서도 task에 의해 제기된 challenge에 통찰력을 제공한다. 게다가, 인간 연구는 machine performance(Sec. 7.) 기초를 내리는데 도움이되고, task에 대한 이해를 도와(보정)줄 수 있도록 한다.
Human annotations
human consistency 분석을 가능하게 하기 위해서, dataset creator는 Cityscape 이미지에 30개의 중복 주석, ADE20k에 64개의 중복 주석, Vistas에 46개의 중복 주석을 제공했다. Cityscape와 vistas의 경우 이미지는 서로 다른 annotator에 의해 독립적으로 주석이 달렸다. ADE20k는 훈련이 잘 된 주석자 한 명에 의해 주석이 달렸다. human annotator의 PQ를 측정하기 위해 각 이미지의 한 annotation을 gt로, 나머지는 prediction으로 다뤘다. PQ는 gt와 prediction에 대해 대칭적(순서에 무관하다는 뜻)이기 때문에, 순서는 중요하지 않다.
Human consistency

→ 위의 차량 segmentation은 차를 annotation하려했지만, 하나가 두 개로 나뉘었다. (가운데)
→ 아래의 segmentation 이미지는 여전히 모호하다. (약간식 다름) - 두 명이 함

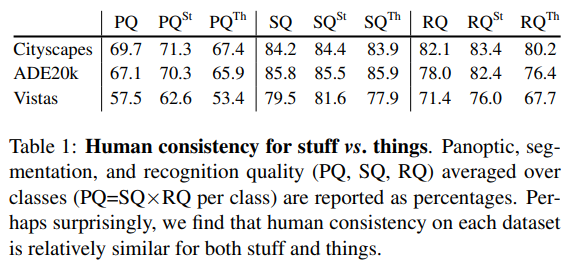
Table 1은 각 데이터셋에 대한 human consistency를 보여주며, PQ를 semantic quality, recognition quality로 분해한 결과를 보여준다. 생각했던 것과 같이, human은 이 task에서 완벽하지 않다. human segmentation의 시각화와 분류 오류는 Figure 3과 4에서 볼 수 있다.
테이블 1은 각 데이터셋에서 annotator의 합의를 측정한 것이지, human consistency의 상한선을 측정한 것은 아니다! 또한, 위의 숫자는 데이터셋 간에 비교할 수 없으며, dataset의 품질을 평가하는데 사용해서는 안된다. 클래스 수, annotate 된 픽셀의 비율, scene의 복잡성은 데이터셋 간에 다양하고, 각 요소가 annotation의 어려움에 큰 영향을 끼친다.
Stuff vs. things
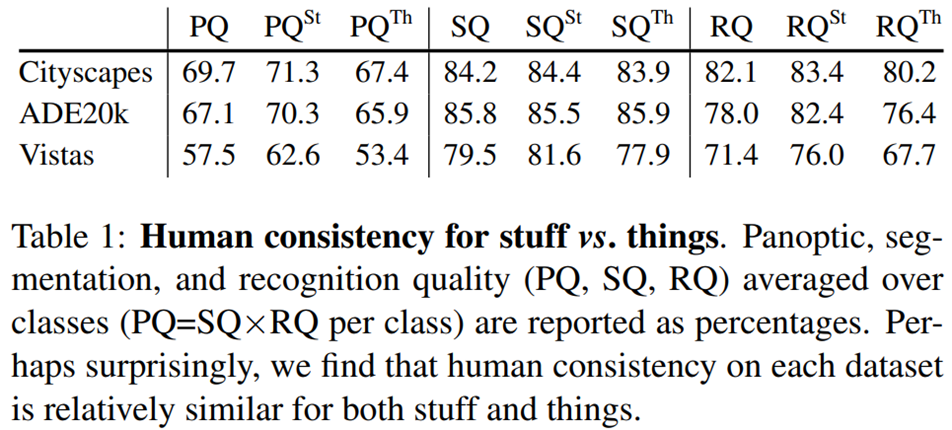
PS는 stuff와 things 모두에 segmentation을 요구한다. 테이블 1은 와 를 보여주는데, 이는 각각 stuff 클래스 및 thing 클래스에 대한 PQ의 평균이다. CItyscapes 및 ADE20k에서는 stuff와 things간 human consistency가 비슷하지만, Vistas에서는 차이가 약간 더 크다. 이는 stuff와 things가 비슷한 어려움을 가지고 있고, things class가 조금 더 어렵다는 것을 나타낸다. (아카이브에 더 많은 정보 담김)
Small vs. large object
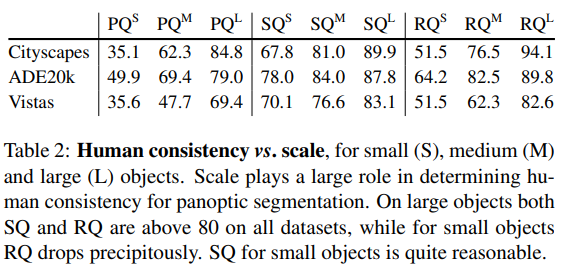
PQ가 물체 크기에 따라 어떻게 변하는지 분석하기 위해서 우리는 데이터셋을 small(S - 가장 작은 것의 25%), medium(M-50%), large(L-큰것의 25%)로 분리했다. (즉, S : 0~25%, M : 25~75%, L : 75%~) 테이블 2에서는 큰 object가 모든 데이터셋에서 human consistenc;y가 꽤 좋았던것을 확인가능하다. small object에서는 RQ가 크게 감소하고, 이는 human annotator가 작은 물체를 찾는데 어려움을 겪는 경우가 많음을 의미한다. 그러나, 작은 물체를 발견한 경우에는 상대적으로 잘 세분화된다. (??)
7. Machine Performance Baselines
Intro
우리는 panoptic segmentation에 대한 간단한 machine baseline을 제시한다. 우리는 3가지의 질문에 흥미가 있다.
(1) panoptic segmentation에서 최고 성능의 instance와 semantic segmentation system의 휴리스틱 조합은 어떻게 수행되나?
(2) PQ는 AP, IoU 처럼 이미 존재하는 metric과 어떻게 비교하나?
(3) 이전에 제시한 human result와 비교해서 machine result는 어떤가?
Algorithms and data.
우리는 기존에 잘 알려진 방법들을 기반으로 panoptic segmentation을 이해하고자 한다. 따라서, 우리는 기존의 최고 성능 instance / semantic segmentation system의 출력과 합리적인 휴리스틱을 적용해(간단히 묘사됨…) 간단한 PS system을 만들었다.
우리는 3가지 데이터셋의 알고리즘 출력을 얻었다. Cityscapes 경우, 현재 선두 알고리즘(PSPNet - semantic seg, Mask R-CNN - instance seg)에서 생성된 val 세트 출력을 사용했다. ADE20k 경우, 2017 Places Challenge에서 instance, segmentation track에서 각각 우승한 팀에게 1000개의 테스트 이미지 집합에 대한 결과를 받았다. LSUN’17 Segmentation Challenge에서 사용되는 Vistas 경우, 주최자가 instance와 semantic segmentation track에서 우승한 모델에 대해 1000개의 테스트 이미지와 결과를 제공했다.
이 데이터를 사용해서, 우리는 instance와 semantic segmentation task에 대해 각각 PQ 분석을 시작한다. 그 후, 전체적인 panoptic segmentation task에 대해 탐구한다. 우리의 “baseline”은 매우 매우 강력하고, PS 논문에서 공정한 비교를 위해 간단한 baseline이 더 합리적일 수 있음을 명시해라.
Instance segmentation
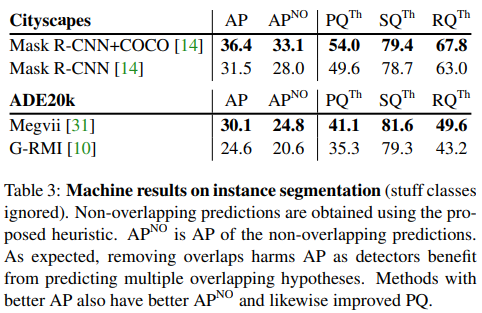
→ stuff class는 무시.
→ non-overlapping pred는 제안된 휴리스틱을 사용해 얻어졌다.
→ : non-overlapping prediction의 AP
→ 예상한 것처럼 (마지막 문장), 중첩을 제거하면 detector가 여러 겹치는 가설(?)을 예측하는 것으로부터의 장점(TP가 많아지겠지) 으로서 AP에 해를 끼친다. (즉, 중첩을 제거하면, 한 픽셀에 클래스가 한 개 뿐이므로, 다중 클래스를 매기는 것보다 성능이 떨어질 수 있다.)
instance segmentation 알고리즘은 overlapping segments를 제공한다. PQ를 측정하기 위해 우리는 반드시 이 overlap을 해결해야한다. 이를 위해 우리는 간단한 NMS와 비슷한 과정을 개발했다. 첫째로, 우리는 예측된 segments를 confidence score에 따라서 정렬하고, 낮은 score을 가진 instance는 제거한다. 그 후, 우리는 정렬된 인스터스에 대해 반복한다. 각 instance에 대해 우리는 먼저 이전 세그먼트에 할당된 픽셀을 제거한 다음, 세그먼트의 충분한 부분이 남아있는 경우에 non-overlapping 부분을 제거하고, 그렇지 않은 경우 전체 세그먼트를 버린다(왜????). 모든 threshold는 PQ를 최적화하기 위한 grid search에 의해 선택되었다. Cityscape, ADE20k의 결과를 Table 3에서 볼 수 있다. 가장 중요한 것은 AP와 PQ track은 밀접하고, 우리는 detector의 AP 개선이 PQ를 개선할 것으로 예상한 것이다.
Semantic segmentation
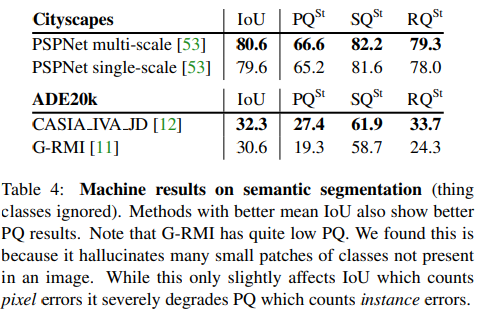
→ mean IoU가 높은 방법(?)은 PQ 결과도 좋게 보인다.
→ G-RMI의 PQ가 상당히 낮다는 것에 주목
→ G-RMI는 이미지에 없는 클래스의 작은 패치를 많이 생산한다. (도대체 어떻게…)
→ 이는 픽셀 오류를 계산하는 IoU에는 약간만 영향을 미치지만, 인스턴스 오류를 계산하는 PQ에는 큰 영향을 끼치기 때문이다.
semantic segmentation은 설계상 ovelapping segments가 없기 때문에, PQ를 직접 계산할 수 있다. Table 4를 보면, 우리는 이 작업(semantic seg)의 표준 metric인 mean IoU를 PQ와 비교한다. Cityscpe의 경우 메소드간 PQ gap이 IoU gap과 일치한다. ADE20K의 경우, gap은 더 크다. 이는 IoU가 올바르게 예측된 픽셀을 계산하는 반면, PQ는 instance 수준에서 작동하기 때문이다.
Panoptic segmentation

→ 좌측 2개 Cityscape, 우측 3개 ADE20k.
→ 예측은 instance와 semantic의 SOTA 알고리즘의 병합된 출력에 기반한다. (Table 3, 4)
→ 매치된 세그먼트에 대한 색상(IoU> 0.5)은 일치한다????????
→ (교차 무늬 패턴은 일치하지 않는 영역, 검정은 레이블이 지정되지 않은 영역)
PS에 대한 알고리즘 출력을 생성하기 위해, 이전에 설명한 NMS와 유사한 절차를 거쳐 non-overlapping instance segmentation에서 시작한다. 그 후, 우리는 이러한 segments를 semantic segmentation 결과(stuff class와 thing class 간 overlap이 해결된 - 이런 경우 thing 클래스로 할당하고, instance id 를 부여)와 결합한다. 이러한 휴리스틱 방법은 완벽하진 않지만, baseline으로서 충분하다.
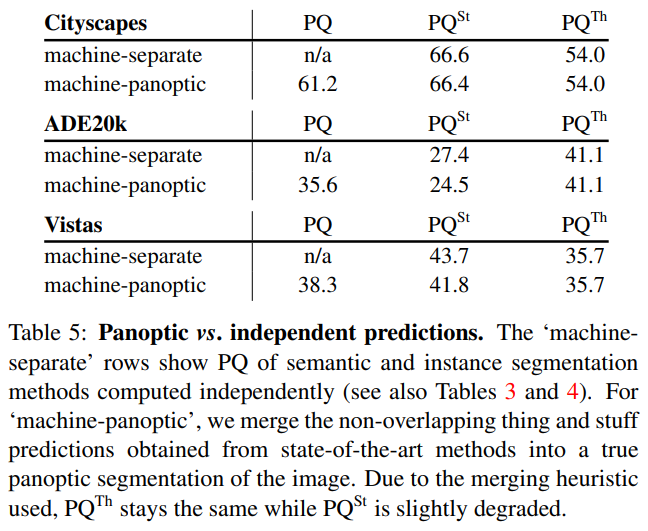
table 5는 병합된(”panoptic”) 결과로서 계산된 , 와 이전에 논의한 개별 예측으로부터 얻은 성능을 비교한다. 이 결과에 대해서는 instance, segmentation 각 대회의 우승작을 사용한다. 물체의 유사도를 고려하여 겹침을 해결하기 때문에 가 panoptic prediction에서 약간 낮은 것에 반해 는 일정하다(그 반대가 되야하는거 아니야?). panoptic output의 시각화는 Fig 5 참조!
Human vs. machine panoptic segmentation
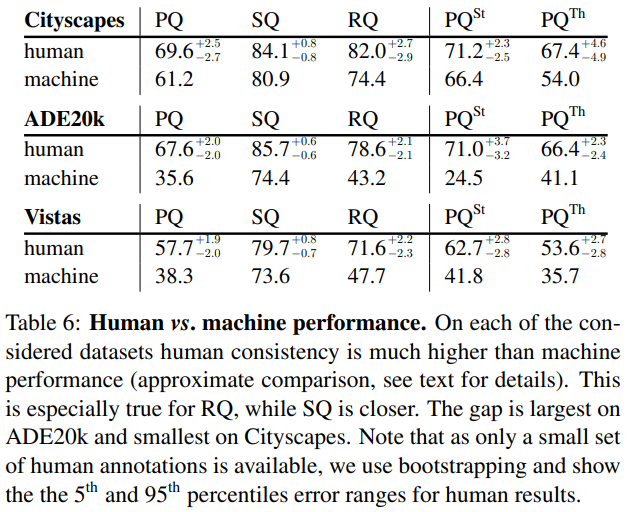
→ 각 데이터셋에서 human consistency는 machine performance에 비해 훨씬 높다. 이는 특히 RQ에서 더 그렇다. 격차는 ADE20k에서 가장 크고, Cityscapes에서 가장 작다.
→ human annotation은 아주 작은 세트에만 있기 때문에, bootstrapping을 이용했다.
human과 machine PQ를 비교하기 위해서, 우리는 위에 소개된 machine panoptic prediction을 사용한다. human result에서 우리는 Sec.6에 소개된 dual-annotated images를 사용하고, 이미지 세트가 적기 때문에 bootstrapping을 사용해 confidence interval를 얻는다. 이러한 비교는 서로 다른 테스트 이미지를 사용하고, 서로 다른 클래스에 대해 평균을 내기 때문에 완벽하지는 않지만, 이는 본 연구에서 의미있는 결과를 준다.
Table 6에서 비교를 볼 수 있다. SQ의 경우, 기계는 인간에 비해 약간 뒤처진다. 반면, 기계 RQ의 경우 human RQ에 비해 현저히 낮다. (ADE20k, Vistas) 이는 현재 방법에서 recognition(다시 말해 classification)이 주요 도전과제임을 시사한다. 즉, human과 machine performance사이에 상당한 갭이 있다. 우리는 이러한 gap이 제안된 panoptic segmentation task에서 추후 연구에 많은 영감을 줄 것이라 생각한다.
8. Future of Panoptic Segmentation
우리의 목표는 community에 초대하여 새로운 panoptic segmentation 과제를 탐구하도록 이끄는 것이다. 우리는 제안된 과제가 예상되거나 예상되지 않는 혁신을 이끌 것이라고 생각한다. 우리는 이러한 가능성과 우리의 미래 계획에 대해 논의하며 마무리 하겠다.
이 논문에서 PS “알고리즘”은 최고의 instance, semantic segmentation system의 출력을 휴리스틱하게 결합하는 것이다. 이 접근 방식은 아주 기본적인 첫 단계이지만, 더 흥미로운 알고리즘들이 소개될 것이로 기대된다. 특히, 우리는 PS가 최소 두가지 분야에서 혁신을 가져올 것이라고 생각한다.
(1) PS의 stuff와 things 두 성격을 동시에 다루는 매우 통합된 end-to-end model
→ instance segmentation을 다루는 여러 논문이 non-overlapping instance 예측을 제공하기 때문에 이러한 시스템의 기초가 될 수 있다.
(2) PS가 겹치는 segment를 가질 수 없기 때문에, 어떤 형태의 고수준 “ reasoning(추론?)”에 대해 유용할 수 있다(예를 들어, PS에 학습 가능한 NMS를 확장하는 등).
우리는 panoptic segmentation 과제가 이러한 분야의 연구를 활성화하여 시각 분야에서 새로운 흥미로운 발견으로 이어질 것을 희망한다.
마지막으로, COCO와 Mapillary Vistas recognition challenge에서도 panoptic segmentation 과제가 나타났고, 제안된 과제는 이미 커뮤니티에서 주목을 받기 시작했다는 점을 언급한다.
