🤖 머신러닝과 프로그래밍의 차이
어떤 주어진 데이터를 가지고 사람이 직접 기준을 찾아 컴퓨터에게 그 기준을 알려주면 프로그래밍이고 컴퓨터가 알아서 기준을 찾아내면 머신러닝이라고 할 수 있다.
💻 코랩 사용하기
코랩은 로컬이 아니라 클라우드에서 주피터 노트북을 사용한다고 생각하면 된다.
주피터 노트북을 로컬에서 사용하면 내 컴퓨터의 자원을 사용하는 거지만,
클라우드 서비스인 코랩을 사용하면 12기가 메모리에 100기가 디스크인 가상 자원을 사용할 수 있다!
셀 하나를 실행하면 셀 바로 아래에 출력 되는데 맥을 사용하는 나는 cmd+enter 키를 누르면 해당 셀이 실행된다.
🐟 마켓과 머신러닝(ch.01-3)
문제 정의
도미와 빙어를 구분하는 머신러닝 모델을 만들자
이런 문제를 분류(classification) 문제라고 한다.
이진 분류(binary classification)
분류 문제 중에서도 2개의 클래스(class) 중 한가지를 골라내는 문제를 이진 분류라고 한다. 반대로 클래스가 3개 이상일 경우 다중 분류라고 한다.
데이터 준비
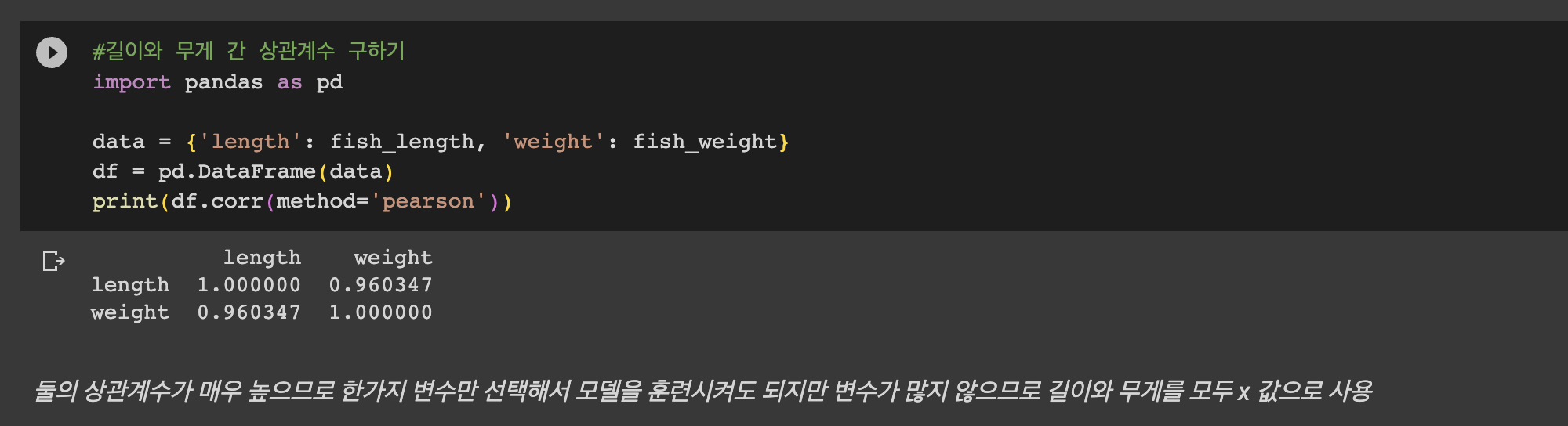
이용할 데이터는 도미와 빙어의 무게와 길이 데이터이다.
이때, 무게와 길이처럼 어떤 데이터의 특징을 나타내는 데이터를 특성(feature)이라고 한다.
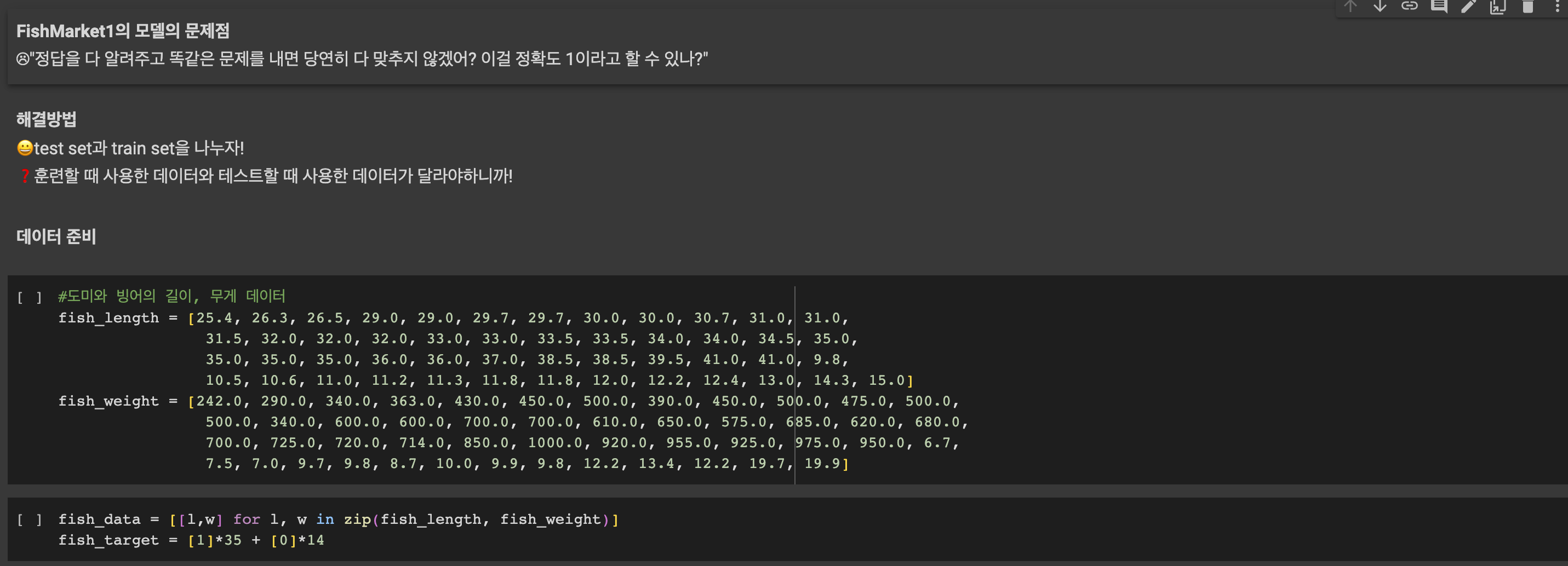
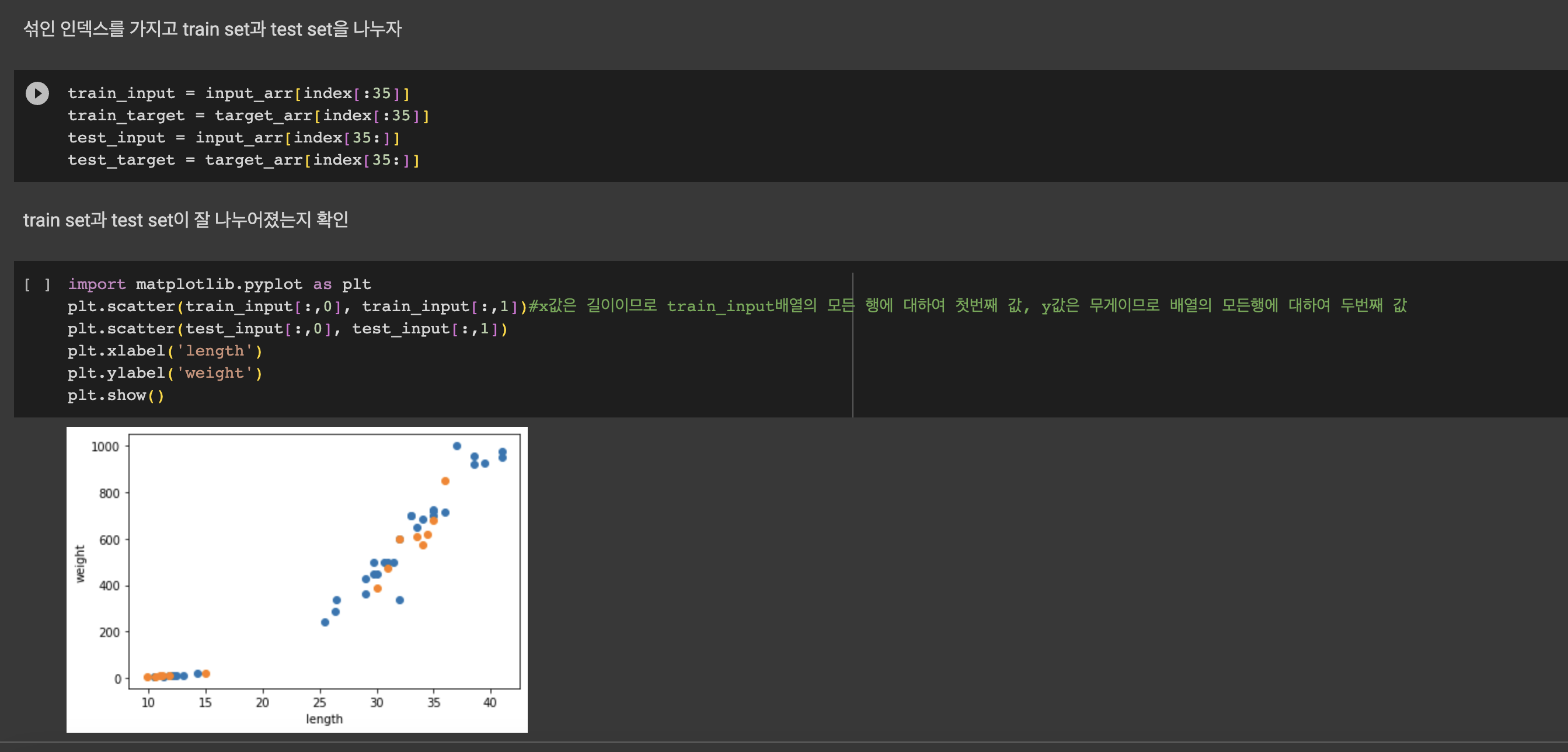
다음은 35마리의 도미 데이터이다.
#도미의 길이, 무게
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
print(bream_length)
print(bream_weight)
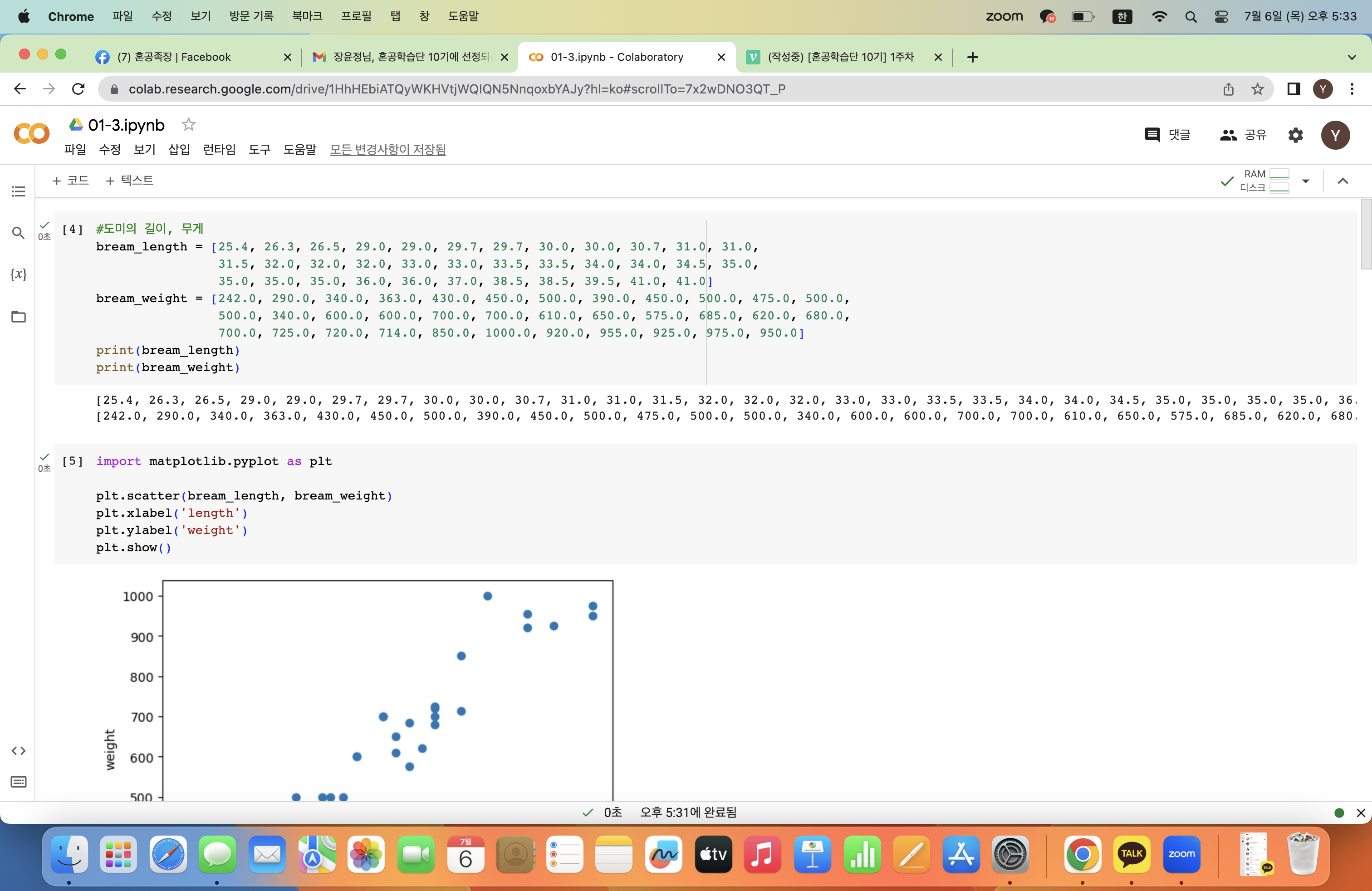
도미의 길이와 무게 데이터가 각각 리스트 형태로 출력된다.

산점도(scatter plot)를 이용하면 데이터의 분포나 특성간 관계를 파악하는데 용이하다!
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
그래프를 보면 길이와 무게 길이가 대체로 비례한다는 것을 알 수 있다.
특히 이 그래프처럼 산점도 그래프가 일직선과 가까운 형태로 나타나는 경우를 선형적(linear)이라고 한다.
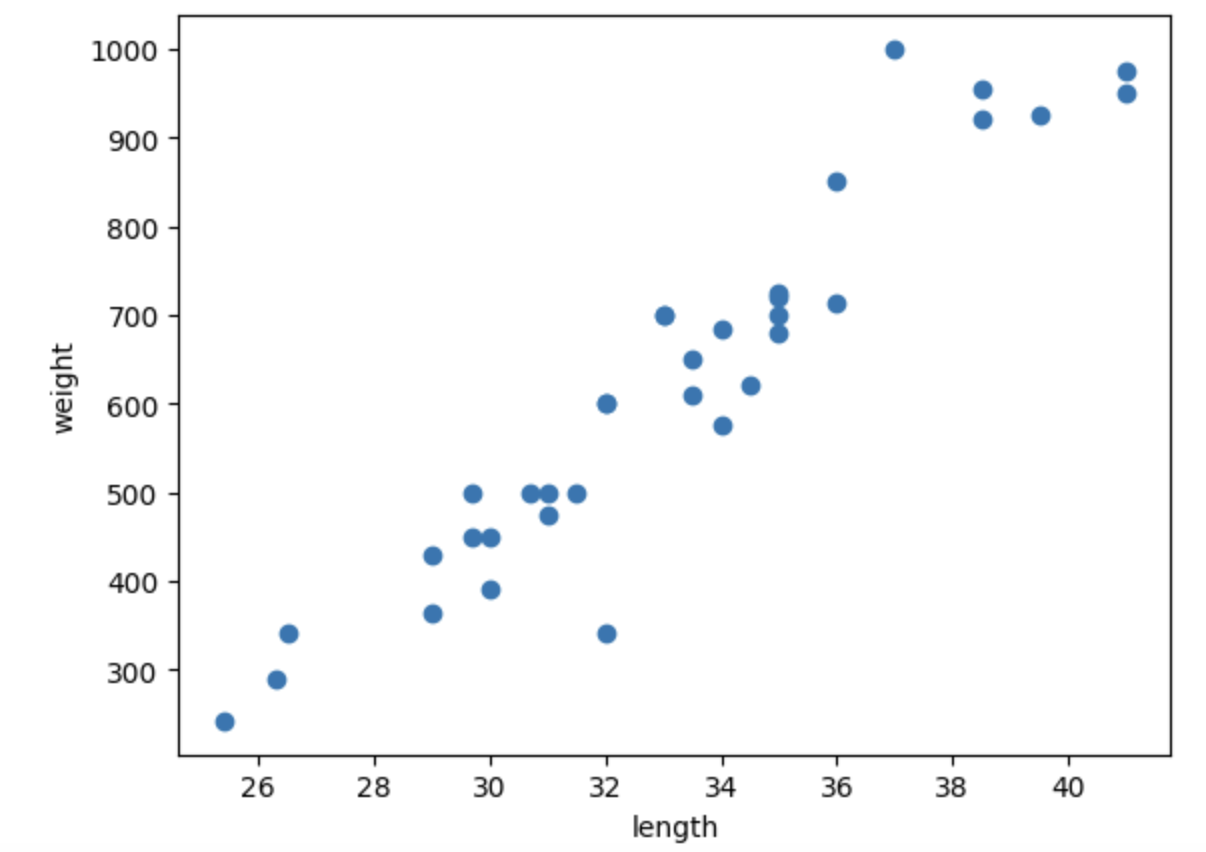
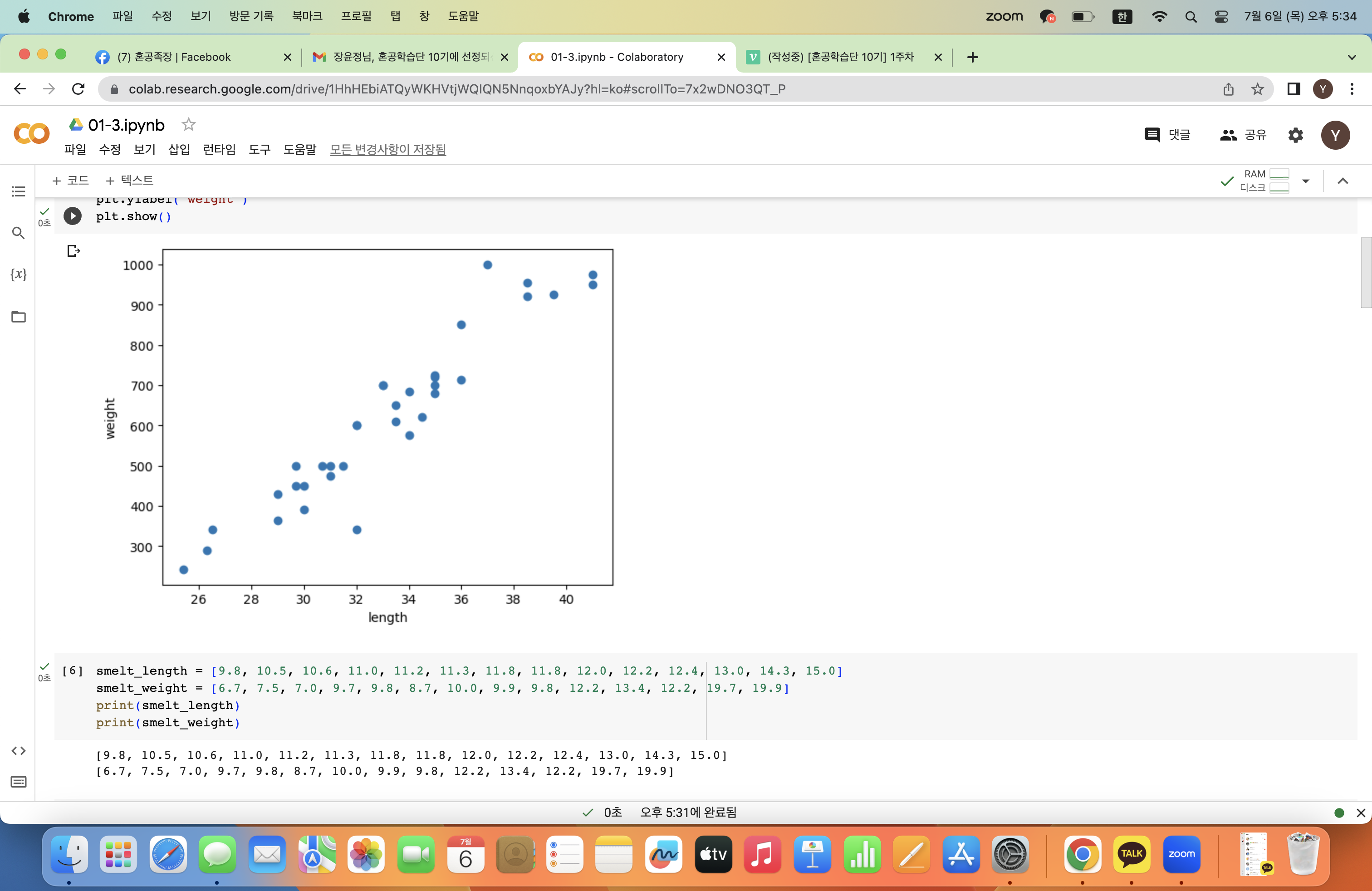
마찬가지로 14마리의 빙어데이터는 다음과 같다.
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
print(smelt_length)
print(smelt_weight)
마찬가지로 리스트 형태 데이터로 불러온다.

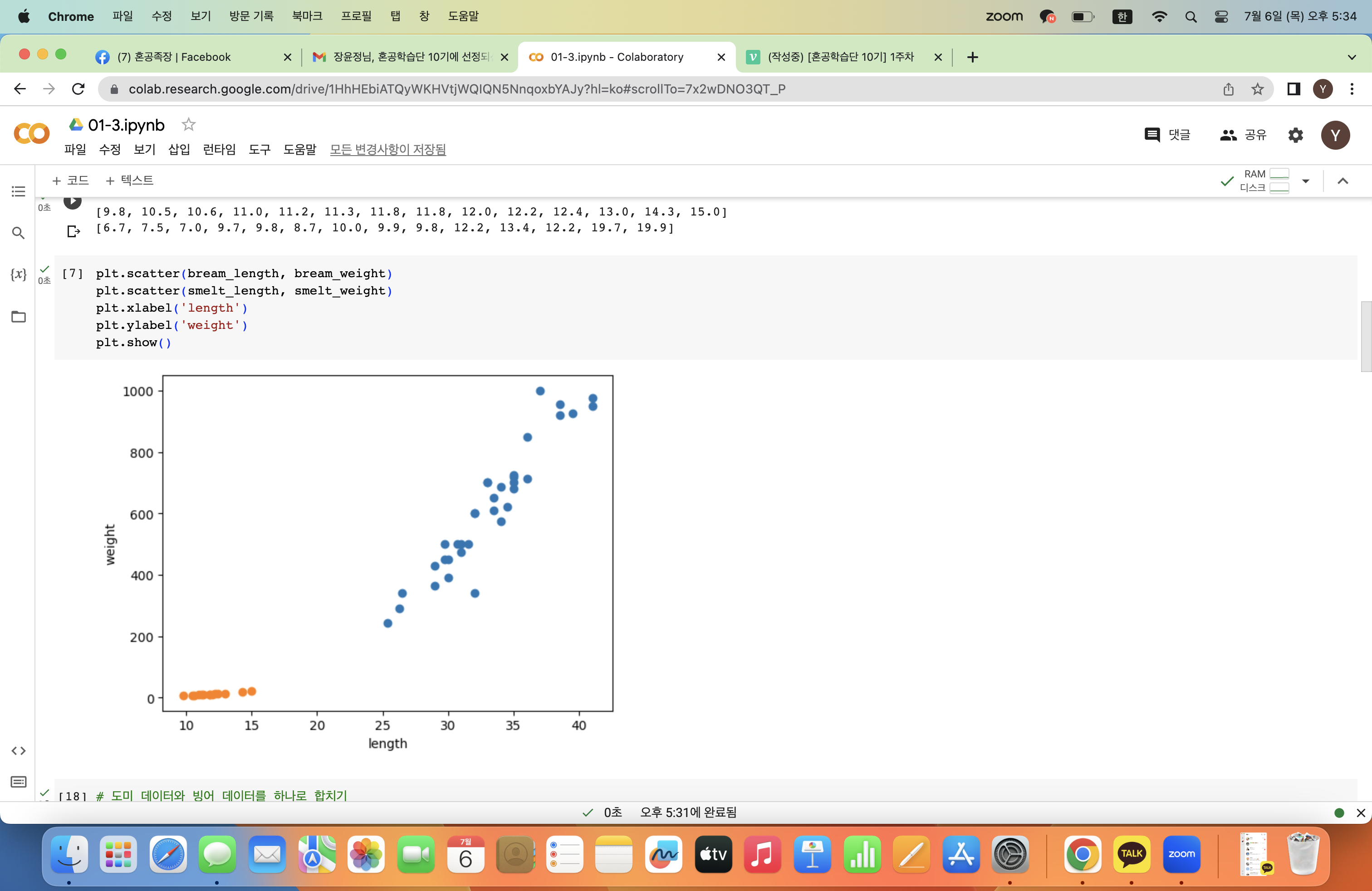
산점도를 연달아 2개를 그리면 두 데이터를 하나의 산점도로 그릴 수 있다!
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
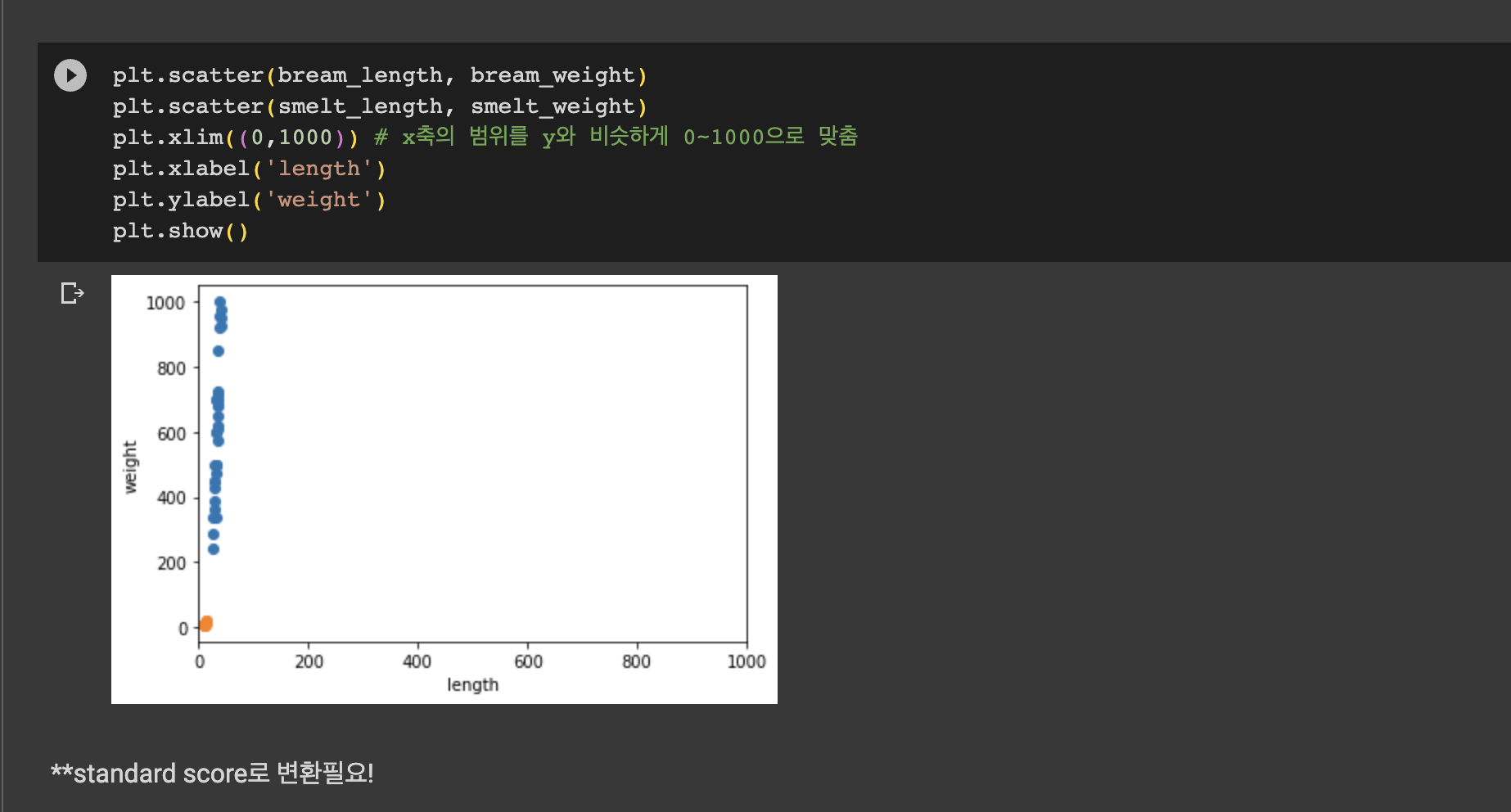
그래프에서 파란색이 도미, 주황색이 빙어 데이터인 것을 알 수 있다.
빙어가 도미보다 길이도 작고 무게도 가벼운 것을 확인할 수 있다.
빙어 데이터 또한 길이가 증가할수록 무게도 증가하는 양의 선형적 관계이지만 도미보다는 그 경향성이 약한 것을 알 수 있다.
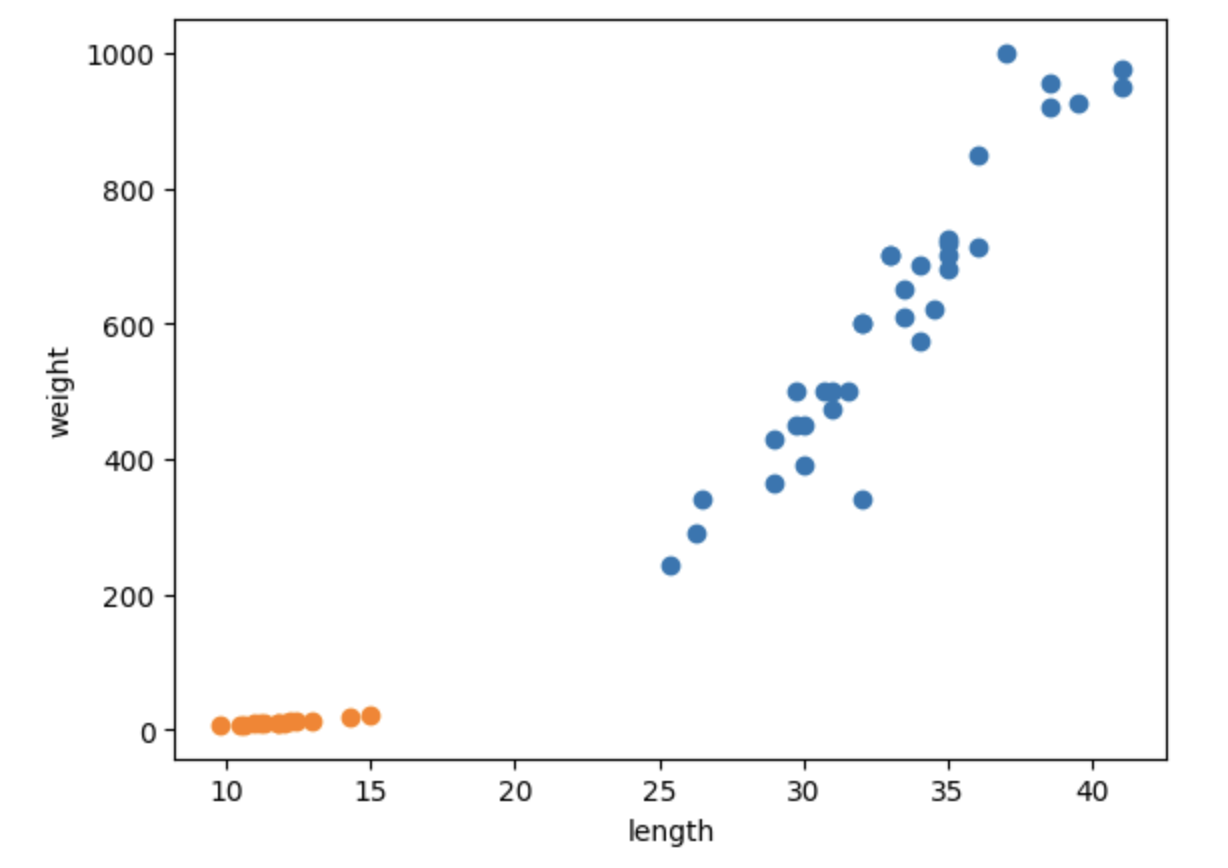
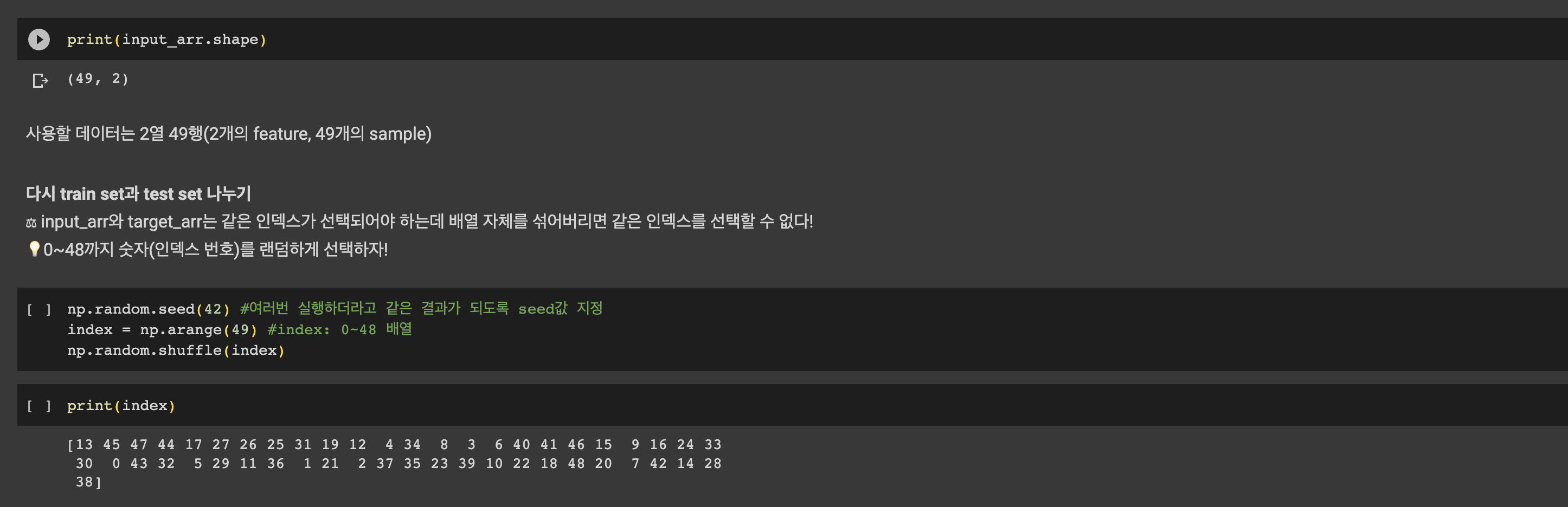
데이터 준비
데이터를 모델에 넣기 위해서는 데이터를 2차원 리스트로 만들어야하기 때문에 각각 다른 리스트로 선언해줬던 도미, 빙어 데이터를 조금 손봐야 한다.
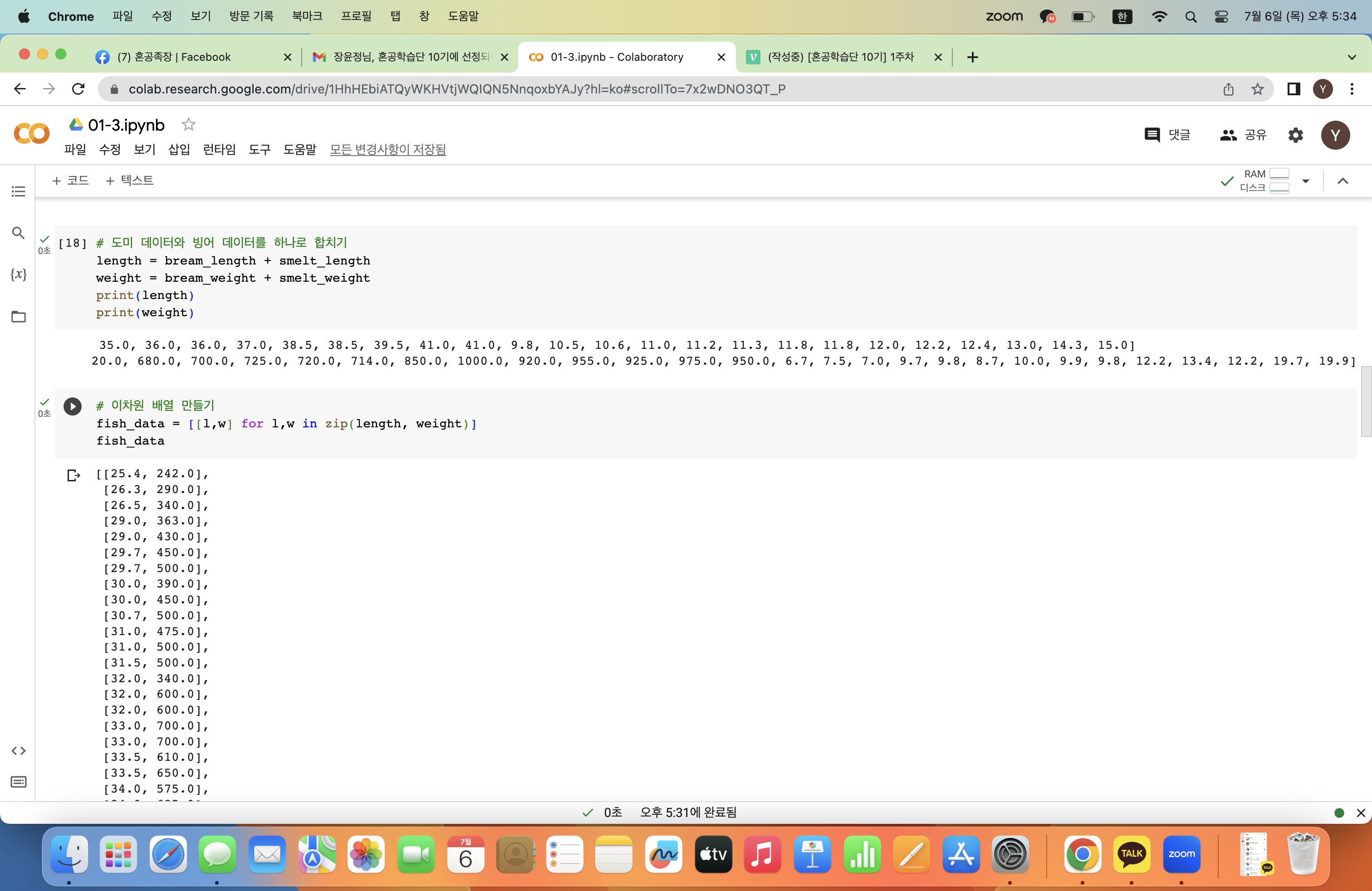
우선 도미 데이터와 빙어데이터를 합치기로 한다.
# 도미 데이터와 빙어 데이터를 하나로 합치기
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
print(length)
print(weight)
상대적으로 길이가 길고 무거운 도미데이터와 작고 가벼운 빙어 데이터가 각각 length, weight 리스트로 합쳐진 것을 확인할 수 있다.

이제 length 리스트와 weight 리스트를 합쳐서 이차원 리스트를 만들자.
zip()함수와 리스트 내포 구문을 이용하면 쉽게 만들 수 있다.
zip()함수는 나열된 리스트에서 원소를 하나씩 꺼내 반환한다.
# 이차원 배열 만들기
fish_data = [[l,w] for l,w in zip(length, weight)]
fish_data
zip함수는 length 리스트와 weight 리스트에서 원소를 하나씩 꺼내서 l, w에 대입해 주고 리스트 내포 구문을 통해서 리스트 안에 리스트 형태로 담기게 된다.
따라서 출력은 위와 같은 형태!
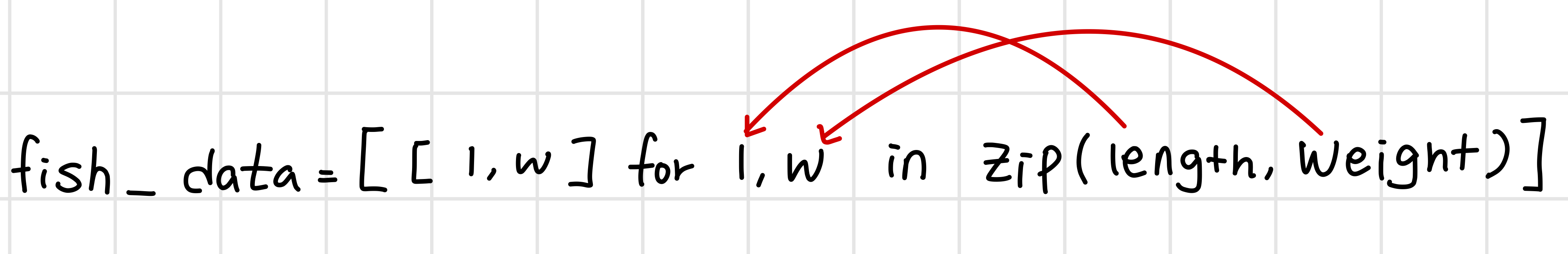

특성 데이터는 준비되었으니 정답 데이터를 준비해야 한다.
만드려는 모델의 목적이 도미와 빙어를 가능한 한 정확하게 분류하는 것이기 때문이다.
classification은 지도학습으로 분류되기 때문에 정답지가 있어야 학습이 가능하기 때문에 정답지 리스트를 만들어 주도록 한다.
컴퓨터에게 "도미", "빙어"로 알려줄 수 없으므로 임의로 도미를 1, 빙어를 0으로 설정하여 알려주도록 한다.
# 앞에서부터 35개 데이터는 도미, 뒤에 14개 데이터는 빙어 데이터임
fish_target = [1] * 35 + [0] * 14
print(fish_target)
tip) 보통 찾으려는 대상을 1로 놓는다
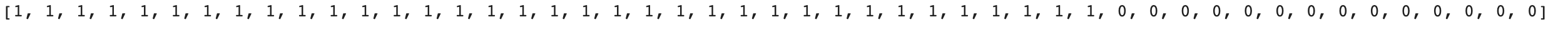
모델 훈련 및 평가
K-최근접 이웃 알고리즘(K-Nearest Neighbors, KNN)
어떤 데이터를 분류하는 문제에서 분류하고 싶은 데이터와 가장 가까운 K개의 데이터를 보고 다수를 차지하는 클래스를 정답으로 간주하는 분류 알고리즘.
당연히 K가 무엇인지에 따라 정답이 달라질 수 있다.
이때, 가까운 데이터라 함은 유클리드 거리가 가까운 데이터를 의미한다.
따라서 해당 알고리즘은 예측을 시행할 때마다 각각의 직선거리를 계산하고 가장 가까운 k개의 데이터를 골라내기 때문에 데이터가 아주 많은 경우 적절하지 않을 수 있다.
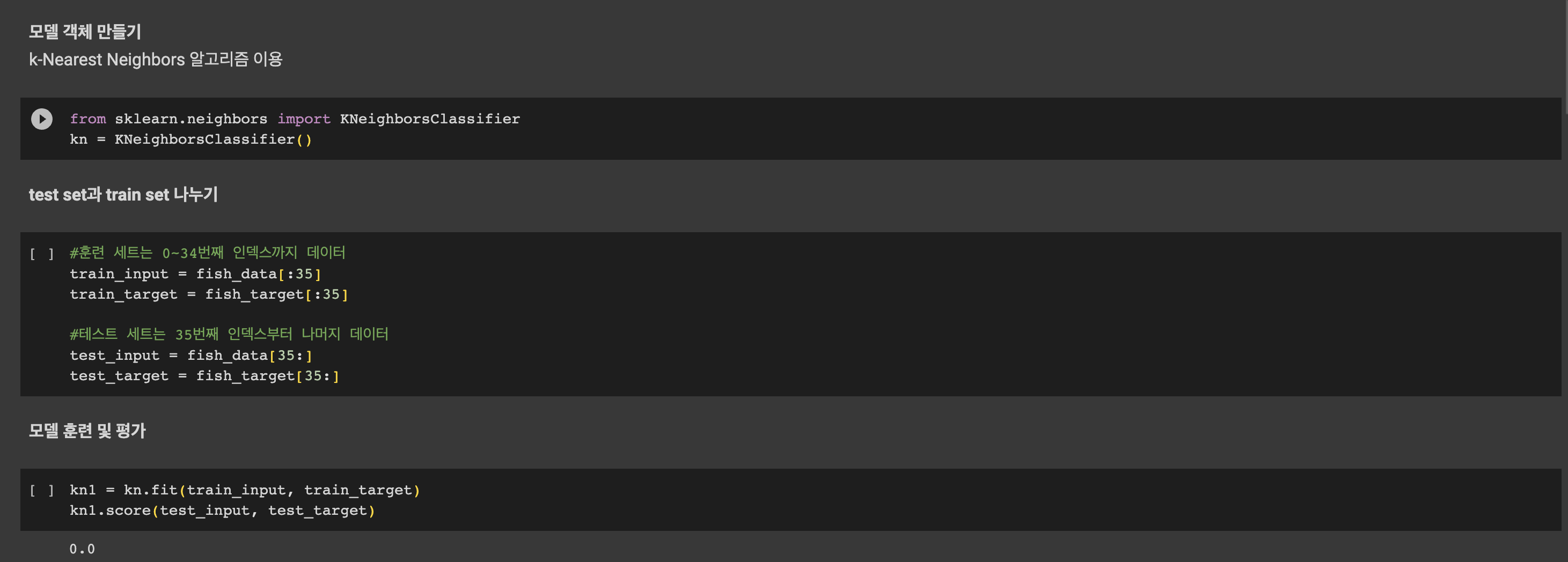
알고리즘 구현을 위해 KNeighborsClassifier를 임포트하고 객체를 선언한다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()이 다음부턴 같은 메서드들이 반복적으로 사용되는데
머신러닝 모델을 훈련시킬 때는 fit() 메서드
모델을 평가할 때는 score() 메서드: 평가 값은 정확도(accuracy)이다.
어떤 데이터를 예측하고 싶을 때는 predict() 메서드를 사용한다.
꼭 기억할 것!!!
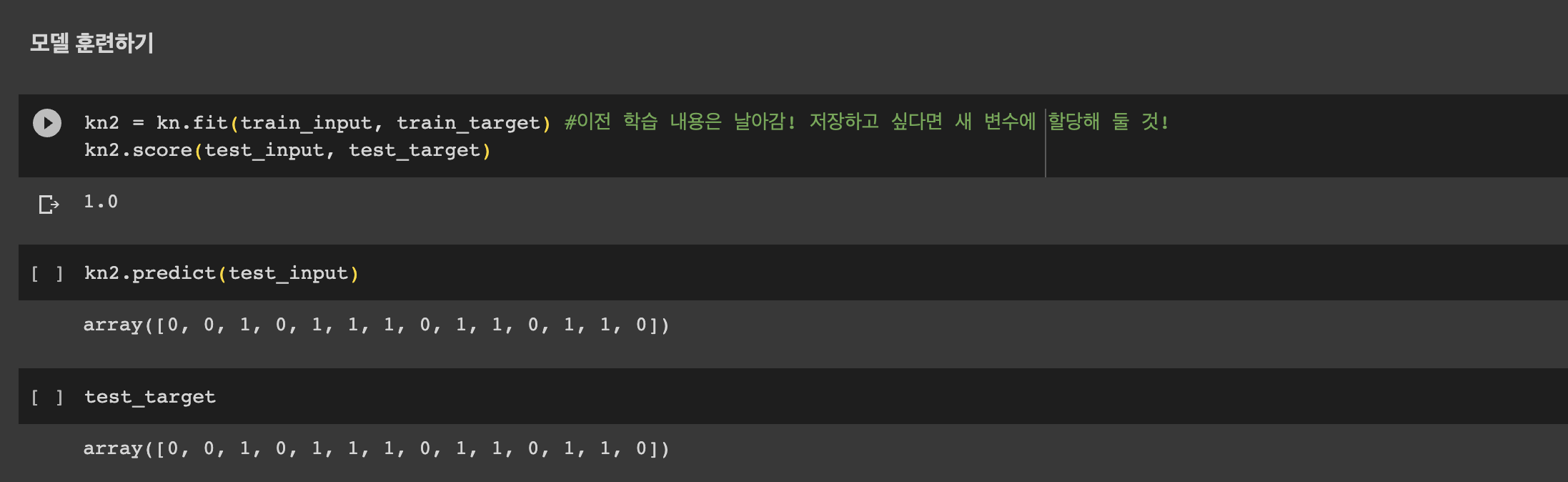
fish_data 전체와 정답지인 fish_target을 순서대로 fit() 메서드에 전달하면 모델이 해당 데이터를 학습한다.
# training
kn.fit(fish_data, fish_target)평가를 진행할 데이터, 예측한 정답 순으로 score() 메서드에 전달하면 해당 데이터에 대한 정확도를 0~1사이의 값으로 반환해준다.
# accuracy
kn.score(fish_data, fish_target)
정확도가 1이므로 100% 정답을 맞췄다고 볼 수 있다.
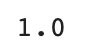
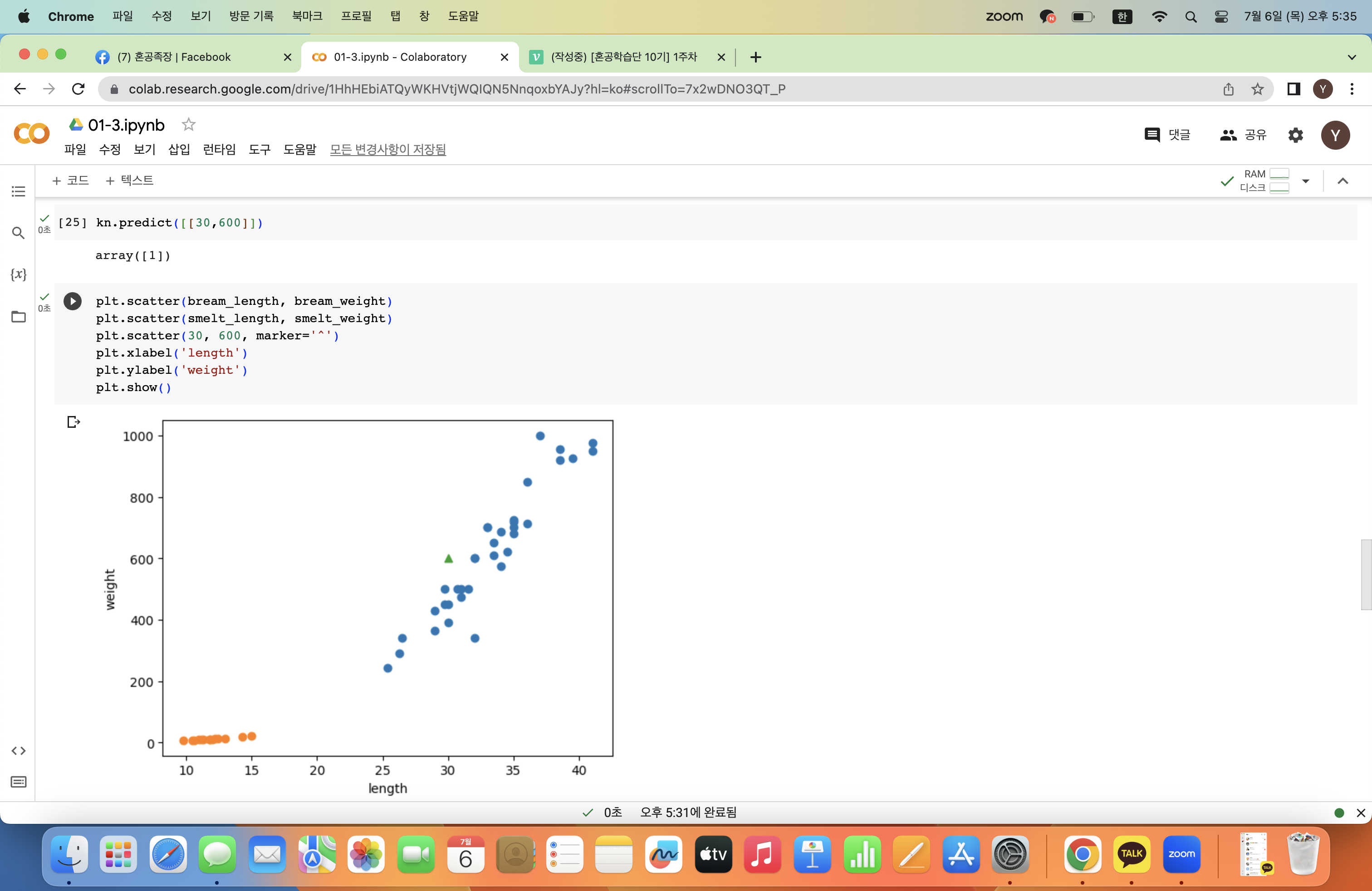
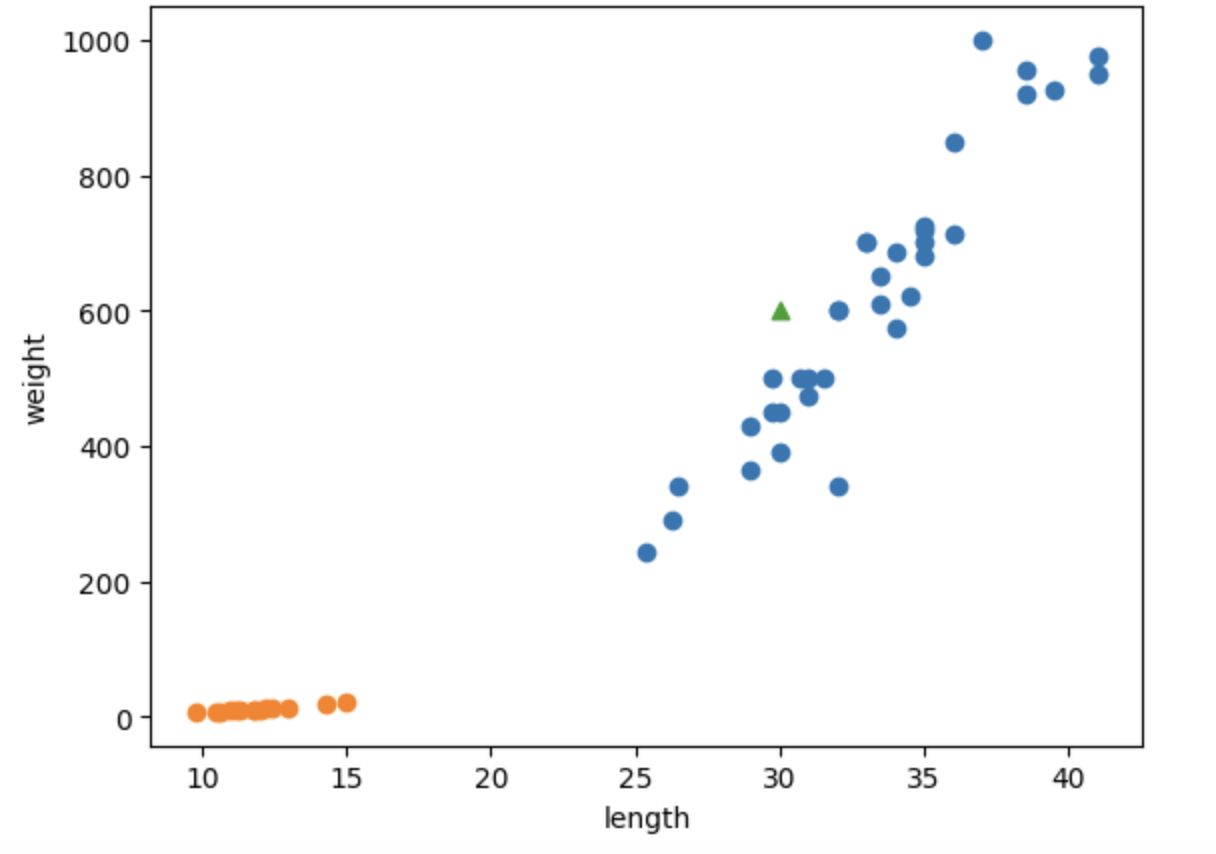
그렇다면 길이 30cm, 무게 600g인 생선은 도미일까 빙어일까?
kn.predict([[30,600]])데이터를 전달할 땐 2차원 리스트 형태여야 함을 잊지 말자!!
이전에 우리는 도미를 1로 설정했으므로 모델은 해당 생선이 도미라고 예측하고 있다.plt.scatter(bream_length, bream_weight) plt.scatter(smelt_length, smelt_weight) plt.scatter(30, 600, marker='^') plt.xlabel('length') plt.ylabel('weight') plt.show()
산점도로 찍어보면 주변 데이터가 파란색 도미 데이터이므로 길이 30cm, 무게 600g인 생선은 도미로 분류하는 것이 적절하다.
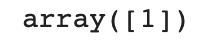
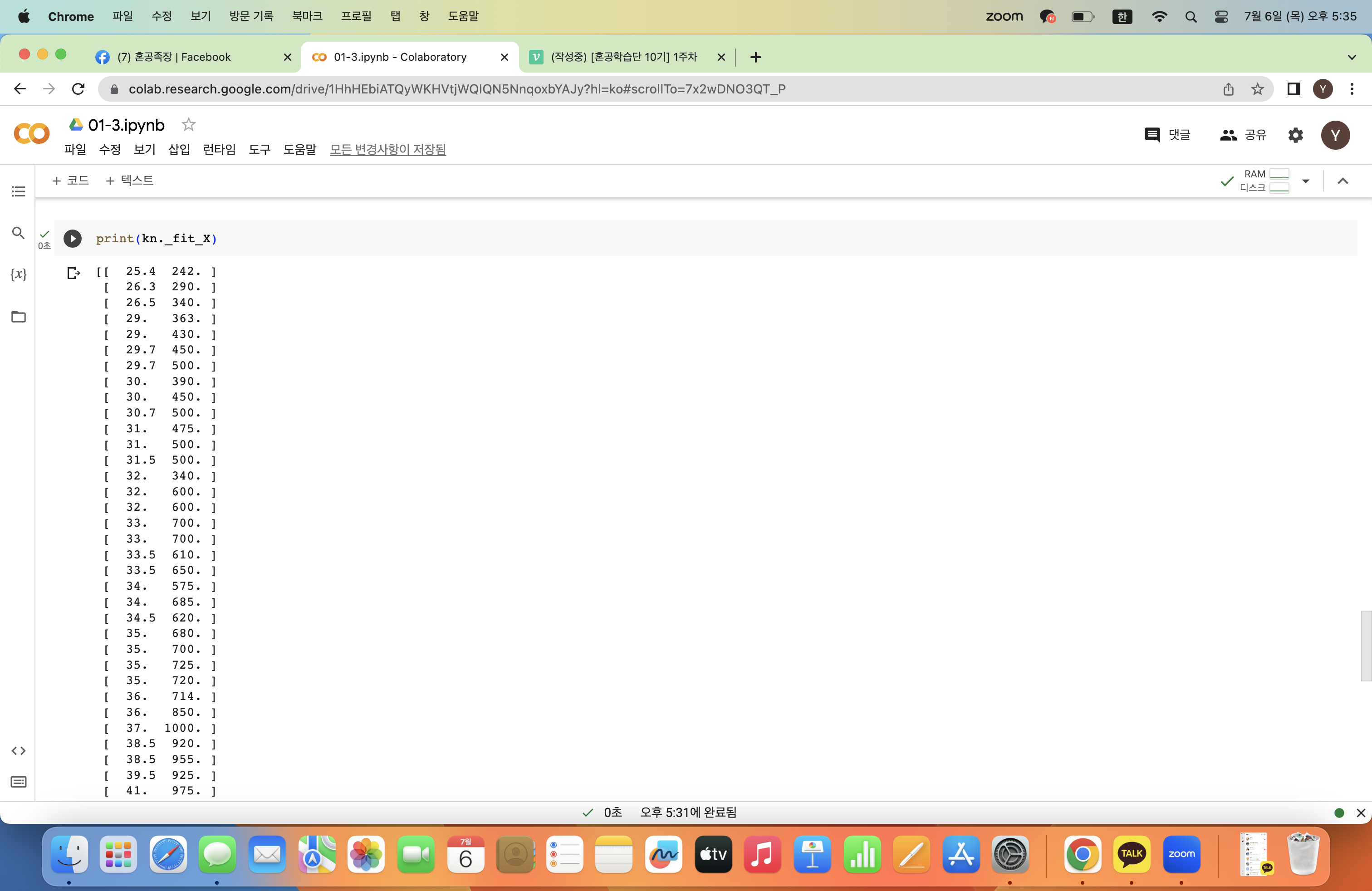
KNeighborsClassifier 클래스는 학습한 데이터에 넣어준 fish_data를 그대로 가지고 있다. 이 데이터를 그대로 가지고 있다가 예측할 데이터가 들어오면 거리를 계산하는 식!
print(kn._fit_X)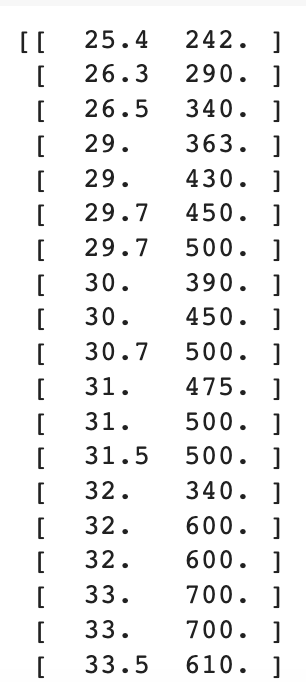
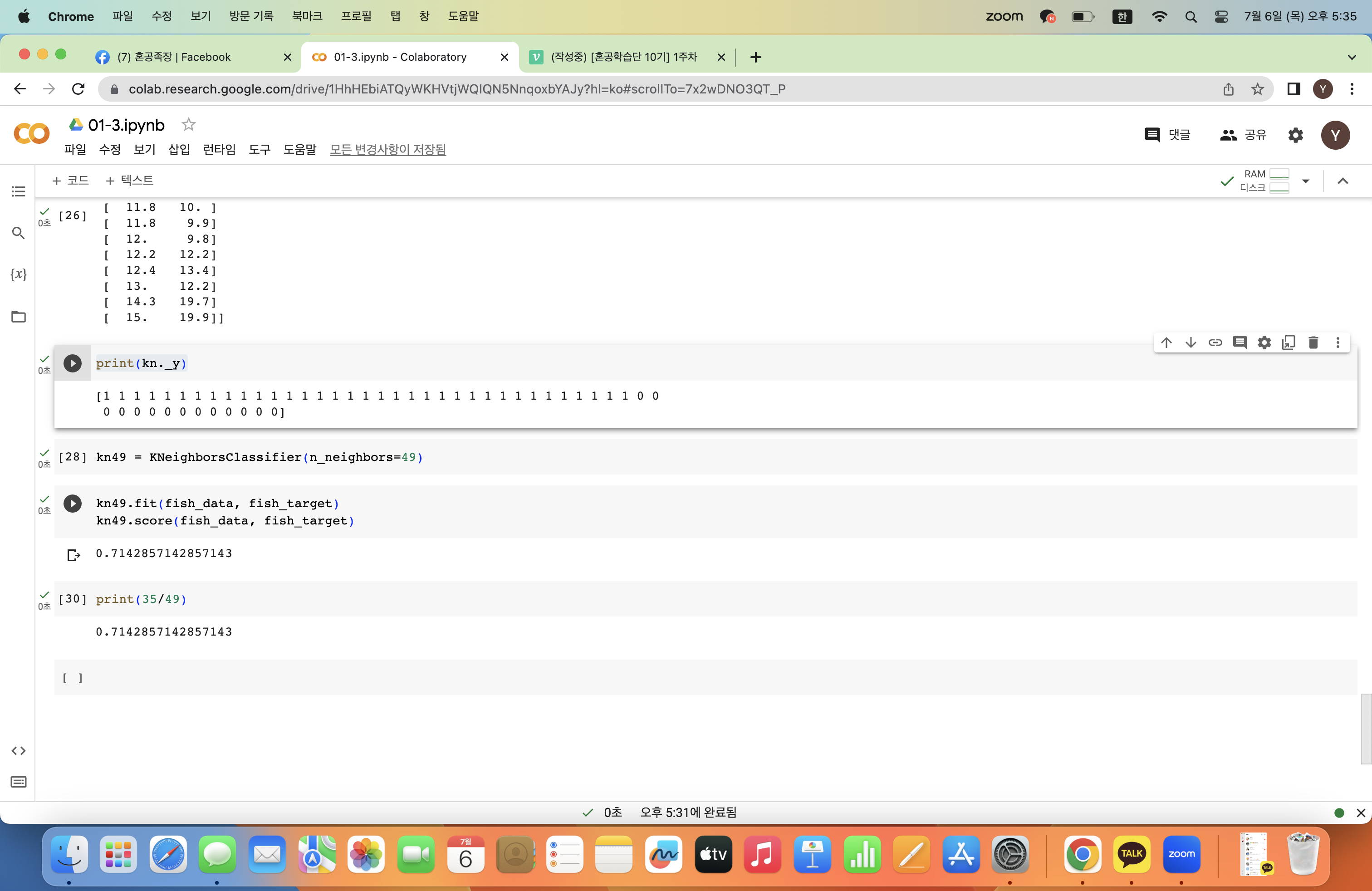
타겟값도 마찬가지다!
print(kn._y)
k를 바꿔본다면?
KNeighborsClassifier 클래스는 기본값으로 5개의 주변 데이터를 참고한다.
k값을 바꾸고 싶다면 n_neighbors 매개변수를 조정해주면 된다.
kn49 = KNeighborsClassifier(n_neighbors=49)위는 49개의 주변 데이터를 참고하는 모델이 된다.
이때 49는 가지고 있는 전체 데이터의 개수이므로 어떤 데이터를 입력하더라도 다수 데이터인 도미라고 예측할 것이다.
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)
결과값은 저렇게 되는데 저 숫자가 어디서 나온 숫자냐면print(35/49)
위 모델은 무조건 도미라고 예측하므로 정확도가 데이터의 도미 비율과 같게 된다.
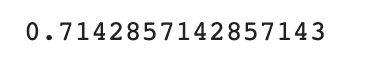
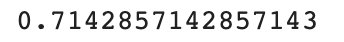
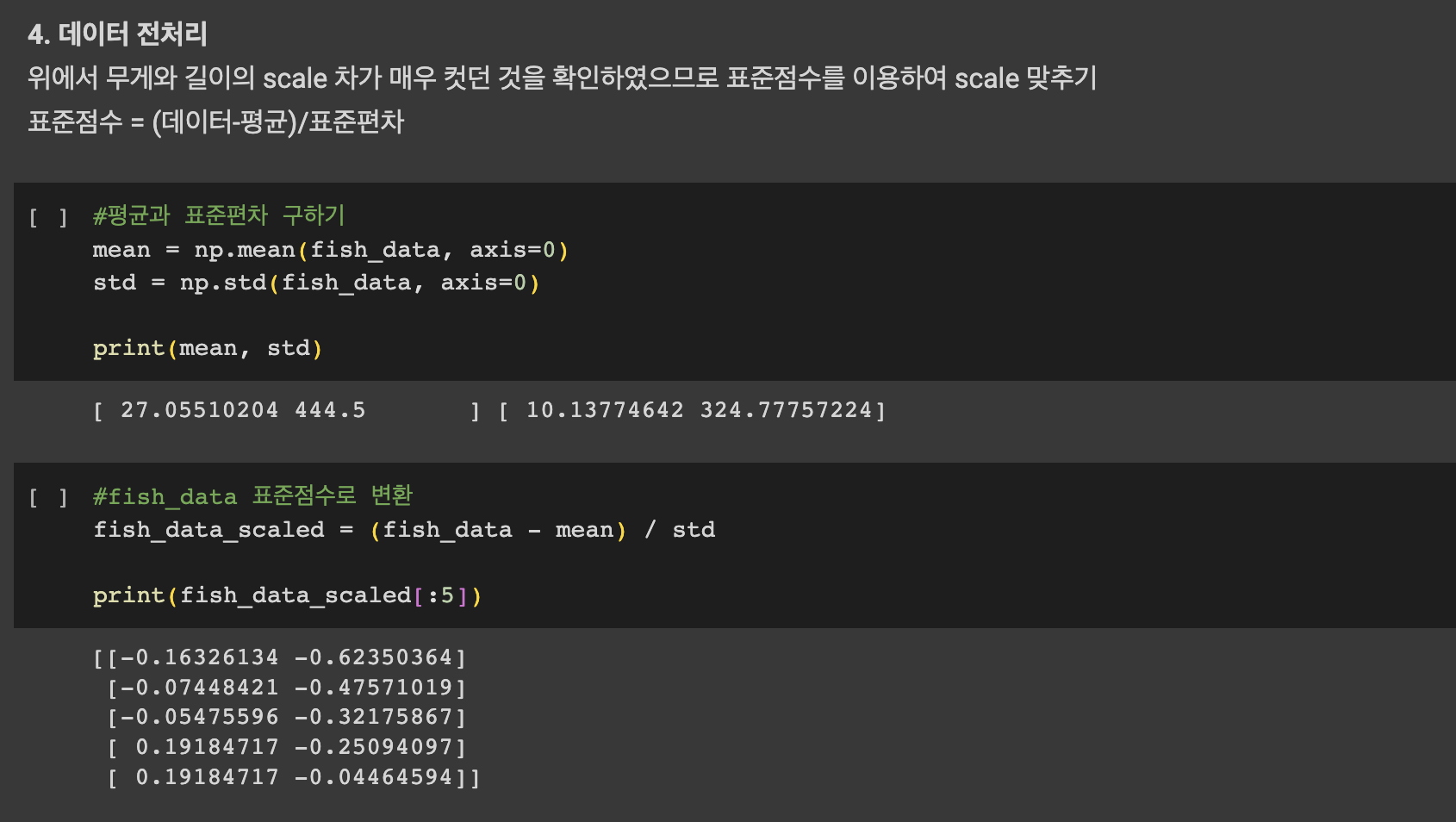
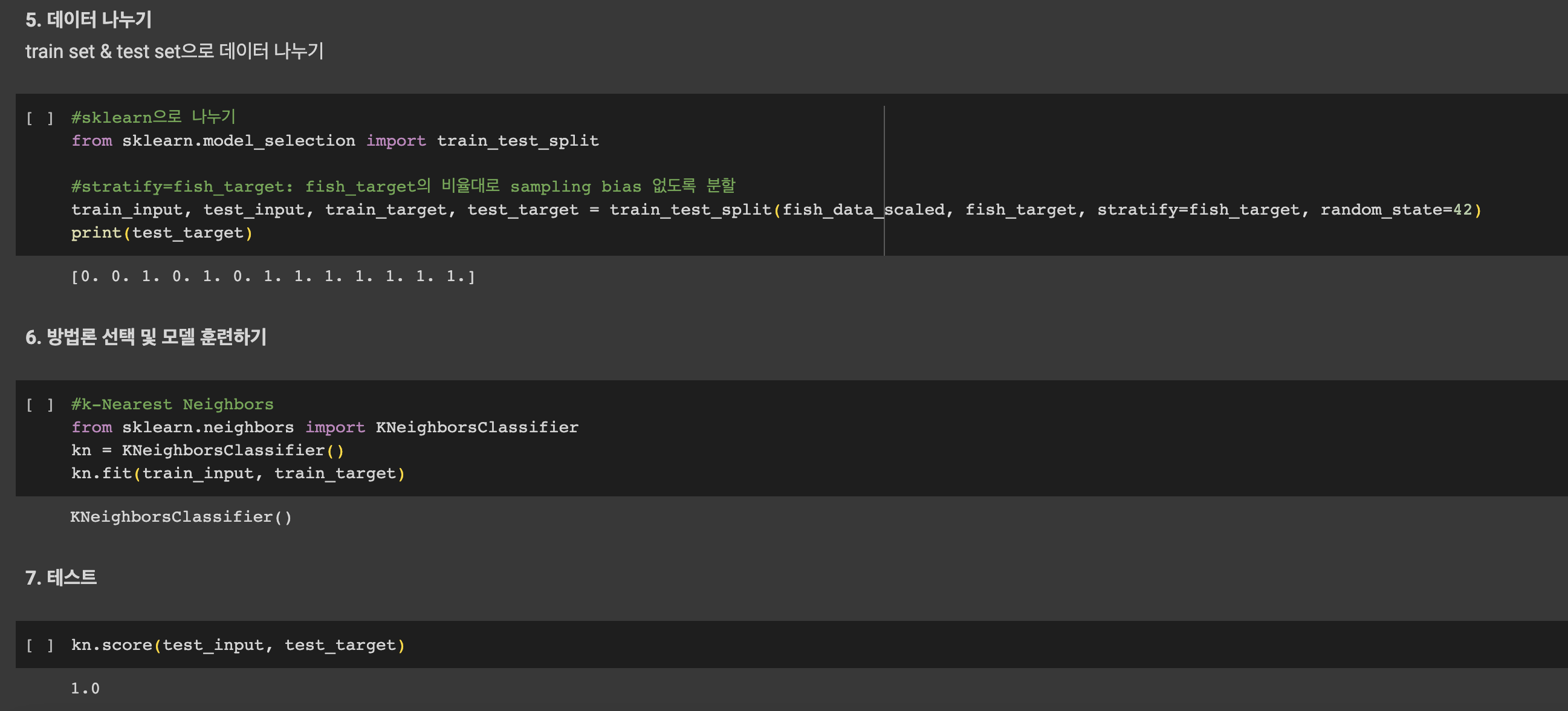
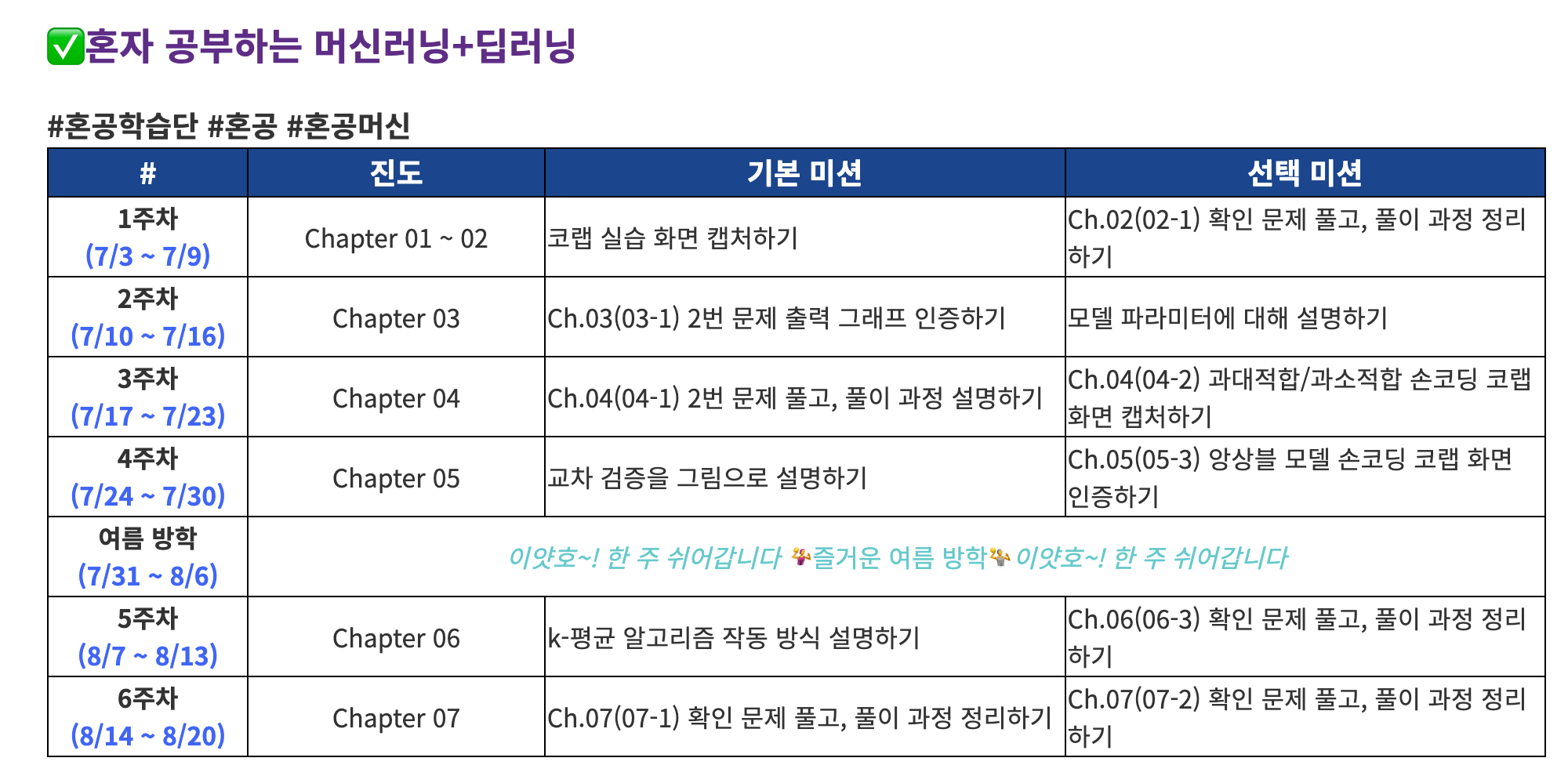
1️⃣ 1주차 미션