
데이터의 가치를 이끌어내기 위해서는 적절한 데이터와 데이터에 대한 방법론이 필요하다
데이터 분석 프로세스는 문제정의-데이터 수집-데이터 준비-데이터분석-해결책 유도-결과 공유이다
이번 포스팅에서는 데이터 준비단계까지 포스팅한다
❗ 문제 정의
문제를 어떻게 정의하느냐에 따라 어떤 데이터를 수집할 것인지 결정할 수 있다
🔴 가설 세우기
- 분석의 목표가 무엇인지
- 분석을 진행할 때 시간이나 비용 등의 제약조건은 무엇인지
🔵 분석에 대한 전반적인 내용 결정하기
- 어떤 데이터가 필요한지 데이터 정의하기
- 분석 도구 및 방법론 선택하기
🟢 결과와 평가기준 결정하기
- 분석 결과에 대한 평가 방법 결정하기
ex. RMSE로 모델 평가 - 결과물을 보는 사람이 누구인지 파악하기
🪣데이터 수집
🌟 수집 시 기억할 점
- 항상 스몰데이터로 시작하기
- 기존 데이터를 사용할지, 새로운 데이터를 수집할지 결정하기
⚠️ 잠깐, 데이터란 무엇인가?
1) 정형데이터
테이블로 표현 가능한 데이터
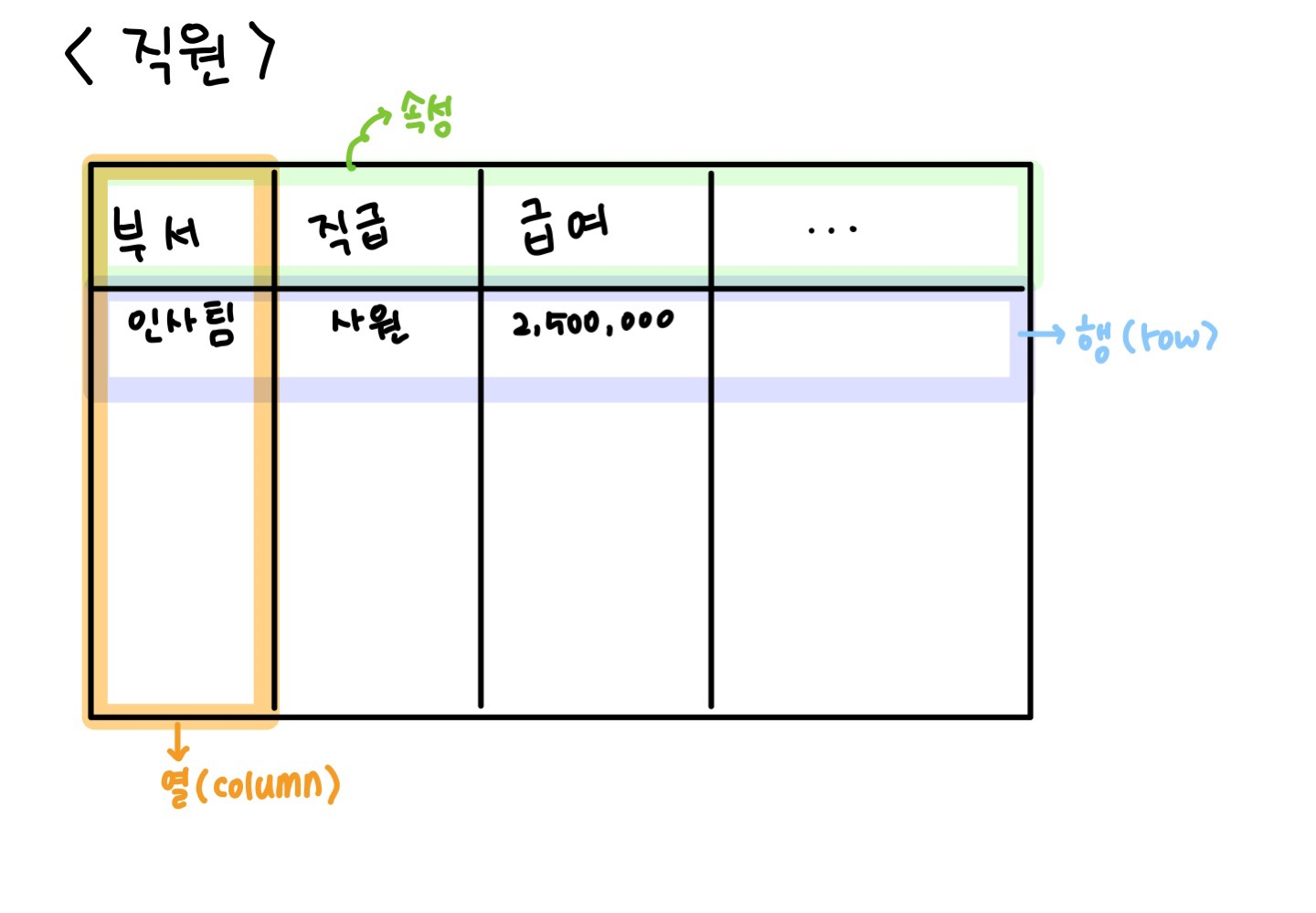
- 속성: 테이블이 나타내는 객체의 여러가지 특징
- 차원(dimension): 속성 중 데이터가 수집된 대상 및 상황
- 측정값(measurement): 속성 중 데이터 수집을 통해 관찰된 결과
- 행: 개별 항목
2) 비정형데이터
테이블로 표현할 수 없는(어려운) 데이터
텍스트 데이터나 사진이나 동영상 같은 멀티미디어 데이터 등
3) 메타데이터
데이터에 대한 데이터라고도 함
메타데이터가 잘못 되었을 경우 분석 단계에서 오류가 발생할 수도 있다
- 자료형이나 단위 등을 나타내는 데이터 포맷
- 누가, 언제 수집한 데이터인지에 대한 정보
🛒 데이터를 수집하자
1) 측정이 어렵거나 불가능한 경우는 어떡함?
데이터를 수집해야 하는데 현상이 복잡하거나 추상적인 경우 등이 있을 수 있다
예를 들어 행복도나 만족도를 측정해야하는 경우
이런 경우 현상 자체가 아니라 보완적인 지표 여러개로 대체할 수 있다
ex. 행복도 - 5점 척도로 계산하기
2) 표본의 대표성
모든 대상을 모두 조사하는 것은 불가능하므로 적절한 표본을 선택하여 데이터를 수집해야 한다
이때 대상 표본이 현상을 적절하게 반영해야 한다
bias가 생기지 않도록!
3) 데이터 수집 방법
① 관찰형 연구
현상에 대한 자연 상태의 데이터 그대로 수집
② 통제형 실험
관심을 갖는 변인(x) 외에 기타 변인을 통제하여 해당 x의 영향만을 관찰하는 방법
- 독립변인: x, 원인
독립변인을 기준으로 실험군/통제군으로 나눈다 - 종속변인: y, 결과
- 공변량: 독립변인 외에 종속변인에 영향을 끼칠 수 있는 변인
ⅰ) 무작위 디자인
대상을 실험군과 통제군에 무작위로 배치함
ex. A/B테스트: 비슷한 두 그룹에 A 또는 B 서비스를 제공하여 그룹별 반응 관찰
ⅱ) 블록 디자인
대상 그룹에 대해서 결과 비교
ex. 한 그룹에 A와B 서비스를 모두 제공
4) 데이터를 얼마나 수집할까?
표본 수(sample size) 결정 방법을 의미하고, 이는 분석 목표에 따라 달라진다
그러므로 목표와 기한을 명확하게 정하고 수집할 것!
① 목표가 현상에 대한 이해라면?
- 최소한의 데이터로 시작한다
- 가능한 모든 환경을 포함해야 한다
ex. 시간대, 부서 등
② 목표가 현상의 일반화라면?
- 통계적 추론의 목표 신뢰구간에 따라 결정한다
- 이후 정리 예정!
③ 목표가 현상의 예측이라면?
- 모델의 특성에 따라 결정한다
- 데이터 량을 늘려가면서 정확도를 평가해본다
5) 수집한 데이터가 좋은 데이터일까?
멋진 말로 데이터 품질 점검을 의미한다
① 완전성
- 데이터가 필요한 속성과 대상을 포함하는가?
- 누락된 데이터(결측치)가 있는가? → 있다면 결측치 처리(ex. drop/평균으로 채우기)
② 정확성
- 데이터가 현상을 정확히 반영하는가?
- 편향(bias)가 큰가?
- 분산(variance)가 큰가?
③ 일관성
- 데이터의 각 속성이 모순되지는 않는가?
ex. 합계 - 데이터의 값이 알맞게 들어갔는가?
ex. 수량 칼럼에 음수 혹은 문자열이 들어간 경우
🔨 데이터 준비하기
데이터를 분석하기 용이한 형태로 준비하기
1) 테이블 형태로 변환하기
분석과 시각화에 용이하도록 하기 위함!
DB 생성 규칙이랑 비슷한듯
- 각 칼럼은 한가지 속성을 나타낸다
ex. 과목별 성적 - 각 행(row)는 한가지 데이터이다
ex. 각 학생의 과목별 성적 - 하나의 테이블은 한가지 데이터이다
ex. 학생의 과목별 성적 테이블/학생 정보테이블 - 개별 테이블은 공통 속성을 통해 연결 가능하다
ex. 학생의 학번
2) 필요한 데이터 선택 및 추출
- 항목(row) 선택
- 항목(row) 추출: random sampling
- 속성(column) 선택: 분석에 관계 없는 속성 제거
3) 속성 변환& 추가
- 자료형 변환
ex. 텍스트 → 수치형 - 단위 변환
ex. 화씨 온도 → 섭씨 온도 - 속성 추가
ex. 칼럼 간 통계값
4) 집계(aggregate)
- 집계 기준은?
ex. 기간, 지역, 부서 등 - 집계 대상은?
ex. 매출액, 직원수 - 집계 방식은?
ex. 합계, 평균
