
📚 필요한 라이브러리 임포트
시리즈(Series)는 1차원 데이터를 다루는데 편리한 자료구조로 pandas 라이브러리에 있다.
매번 pandas를 다 작성하기 귀찮으므로 보통 pd로 줄여서 쓴다.
import pandas as pd🔁 리스트, 딕셔너리 자료형을 시리즈로 변환하기
data1 = ['a', 'b', 'c'] #리스트 자료형
data2 = {'a':1, 'b':2, 'c':3} #딕셔너리 자료형
print(data1)
print(data2)
일차원 형태로 출력됨
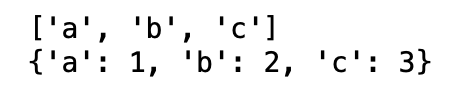
sr1 = pd.Series(data1)
sr2 = pd.Series(data2)
print(sr1)
print(sr2)
표 형태(엑셀 시트라고 생각하면 편함)로 출력됨

이 때 행 이름은 index, 열 이름은 name, 값은 values 라고 부르고 이 이름으로 접근할 수 있다.
sr3 = pd.Series(data1, index=[0,1,2], name='value')
print(sr3)
시리즈로 나타낼 데이터는 data1, 행 이름=[리스트], 열이름='문자열'

print(sr3.index) #sr3의 인덱스 출력하기
print(sr3.values) #sr3의 값 출력하기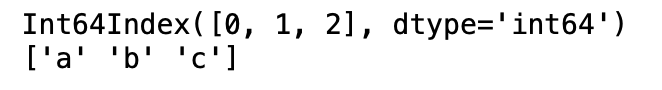
➿ 리스트, 딕셔너리 자료형을 데이터프레임으로 변환하기
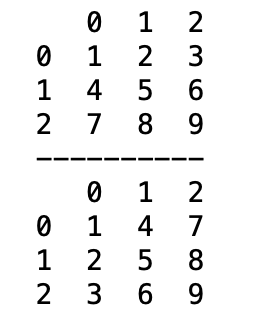
data3 = [[1,2,3], [4,5,6], [7,8,9]] #리스트 자료형
data4 = {0:[1,2,3], 1:[4,5,6], 2:[7,8,9]} #딕셔너리 자료형
print(data3)
print(data4)
마찬가지로 일차원 형태로 출력됨

df1 = pd.DataFrame(data3)
df2 = pd.DataFrame(data4)
print(df1)
print('----------')
print(df2)
- df1의 경우 행 단위로 데이터프레임이 만들어짐
- df2의 경우 key 값에 따라 하나의 열이 되어 데이터프레임이 만들어짐
- 데이터프레임은 시리즈와 마찬가지로 표 형태로 데이터를 취급하지만 개념적으로는 Series들을 하나의 열로 취급한 형태
✍️ 데이터프레임의 행이름(index), 열이름(columns) 바꾸기
df1.index = ['a', 'b', 'c'] #행이름 변경
df1.columns = ['A', 'B', 'C'] #열이름 변경
print(df1)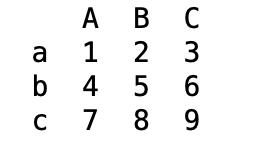
🔎 데이터프레임에서 특정 데이터 찾기(loc함수와 iloc함수)
인덱스, 칼럼명을 직접 쓸 땐 loc함수, 정수 인덱스(행, 열번호)를 쓸 땐 iloc함수를 쓰면 된다.
x = df1.loc['a','A'] #행, 열 순서
y = df1.iloc[0,0]
print(x,', ',y)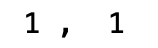
xx2 = df1.loc['a':'b', 'A']# a행부터 b행까지(b행 포함!!) A열 데이터 검색
x2
b행이 포함이라는 것에 주의해야 함

y2 = df1.iloc[0:2, 0] #0행부터 1행까지(2행 미포함!!) 0열 데이터 검색
y2
2행이 미포함이라는 것에 주의해야 함(loc함수와 차이점!)

x3 = df1.loc['a':'b', 'A':'C'] #a행부터 b행까지 A열부터 C열까지 데이터 검색
x3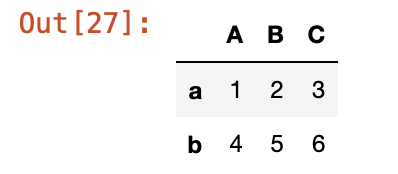
y3 = df1.iloc[0:2, 0:4] #0행부터 1행까지 0열부터 3열까지 데이터 검색
y3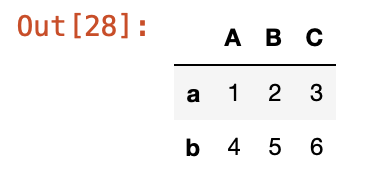
➿ 데이터프레임 간 연산
df1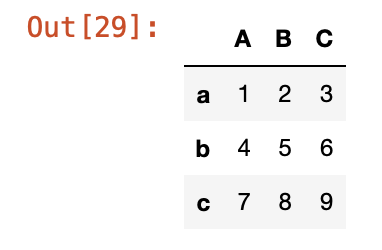
df2
df1 + df2
데이터프레임은 동일한 인덱스, 칼럼간 연산이 가능한데 동일한 인덱스가 없기 때문에 전체 NaN

동일한 인덱스 이름과 칼럼 이름을 갖도록 바꿔주면 된다.
df2.index = ['a', 'b', 'c']
df2.columns = ['A', 'B', 'C']
df2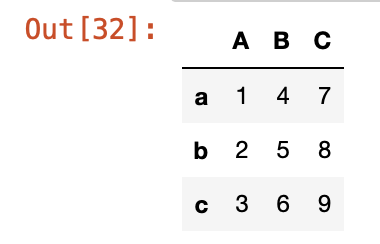
df1 + df2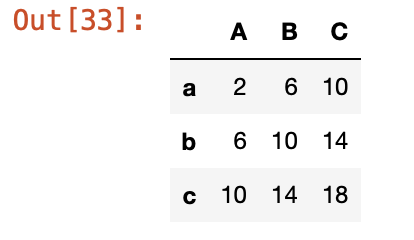
🧮 데이터프레임에 연산 적용하기
우선 데이터프레임에 일괄 적용할 함수를 define한다.
# x로 들어온 값을 제곱한 후 100을 더하여 리턴하는 함수
def add100(x):
return str(x**2 + 100)❗️ DataFrame에 적용할 수 있는 함수
1️⃣ map 함수
합성함수를 만드는 함수
x -> f(x) -> g(f(x))2️⃣ apply 함수
lambda 함수로 series별 적용됨
ex) x.apply(lambda v:v * 2)3️⃣ applymap 함수
apply함수를 각 원소에 적용함
ex) df.applymap(lambda x: x * 2): df의 모든 원소를 2배
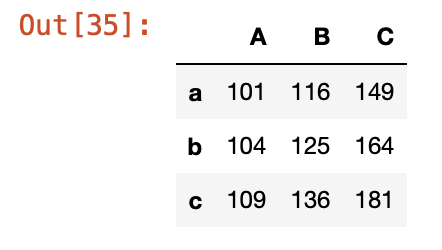
df3 = df2.applymap(add100) #함수명만 전달해도 됨
df3
df2의 각 원소에 add100함수를 적용한 데이터프레임 반환
➕ 데이터프레임 합치기(concat 함수)
두 데이터 프레임을 하나의 데이터프레임으로 연결하는 함수이다.
axis=0인 경우 row를 합치고(아래에 붙이기), axis=1인 경우 columns를 합친다(오른쪽에 붙이기).
join='outer'인 경우 합집합, 즉 모든 데이터를 합친다.
join='inner'인 경우 교집합, 양쪽에 모두 데이터가 존재하는 데이터만 join한다.
pd.concat([df1, df2], axis=0, join='outer')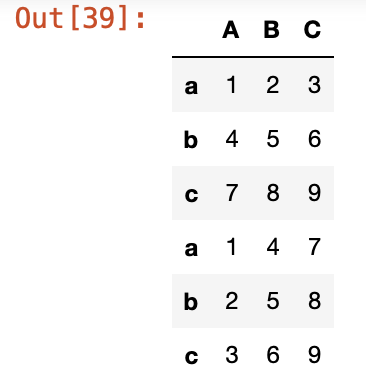
pd.concat([df1, df2], axis=1, join='outer')
🗑️ NaN 포함된 데이터 버리기(dropna 함수)
dopna함수를 사용하여 NaN이 포함된 행 또는 열을 drop할 수 있다.
매개변수로 axis=0을 전달하면 nan이 포함된 행을, axis=1을 전달하면 nan이 포함된 열을 drop한다.
thresh=n을 매개변수로 전달하면 nan이 n개 이상일 경우에만 해당 행 또는 열을 drop한다.
우선 nan를 만들어주기 위해 numpy 라이브러리를 임포트한다.
import numpy as np
a = [[1,2,np.nan], [4,5,np.nan], [np.nan, np.nan, 9]]
df4 = pd.DataFrame(a)
df4
nan이 포함된 데이터프레임 완성
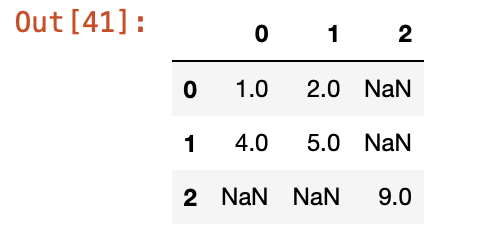
df5 = df4.dropna(axis = 0, thresh = 2)
# df4에서 한 행에 nan이 2개 이상인 경우 해당 행 drop
df5
df4에서 NaN이 2개인 2행만 drop
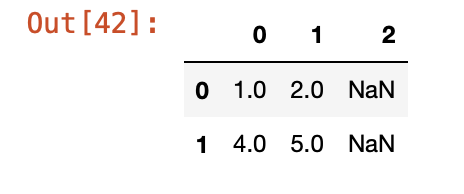
df6 = df4.dropna(axis=1, thresh=2)
#df4에서 한 열에 nan이 2개 이상인 경우 해당 열 drop
df6
df4에서 NaN이 2개인 2열만 drop
📇 reference
해당 내용은 신기술분야융합디자인전문인력양성 교육센터의 빅데이터 서비스 강좌를 수강한 내용을 바탕으로 작성되었습니다.
