
스쿼드 3번방에서 그래프를 배운 후 DFS와 BFS에 대해 알아보았다.
그래프(Graph)
코딩에서 그래프는 노드(Node)와 엣지(Edge)로 구성된 데이터 구조를 의미한다.
- 노드(Node)
그래프에서 각각의 개별 요소를 나타낸다. - 엣지(Edge)
노드와 노드를 연결하는 선을 의미한다. 두 노드 사이의 관계나 경로를 나타낸다.
그래프의 표현 방식
- 인접 행렬(Adjacency Matrix)
2차원 배열을 사용하여 노드 간의 연결 상태를 나타낸다. 노드의 개수가 많을 경우 공간 낭비가 발생할 수 있다. - 인접 리스트(Adjacency List)
각 노드에 연결된 노드들의 리스트를 저장하는 방식이다. 공간 효율성이 높다.
DFS(Depth First Search, 깊이 우선 탐색)
- DFS는 깊이 우선 탐색으로 그래프의 한 방향이 막힐 때까지 깊이 탐색하는 것이다.
시작 노드에서 출발하여 한 방향으로 갈 수 있는 곳까지 깊이 탐색한 후, 더 이상 갈 수 없으면 돌아와 다른 경로를 탐색한다. - 경로탐색, 사이클 검출, 그래프 연결성을 확인할 때 사용하면 좋다.
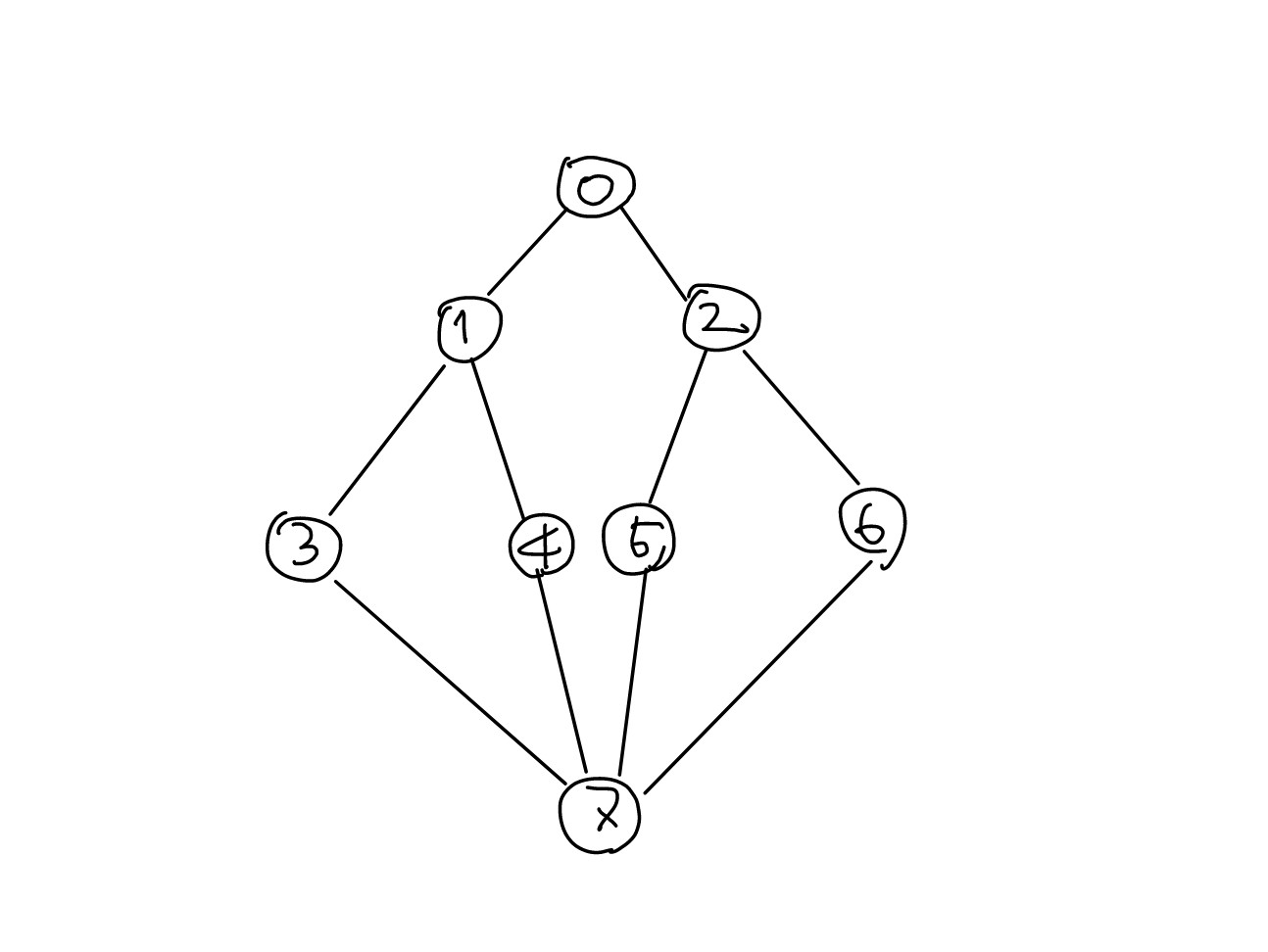
- 위와 같은 그래프가 있을 때
0 → 1 → 3 → 7 → 4 → 5 → 2 → 6순서로 순회하는 방식이다. - DFS를 코드로 구현할 때 후입선출을 하는
stack을 이용하여 구현할 수 있다.
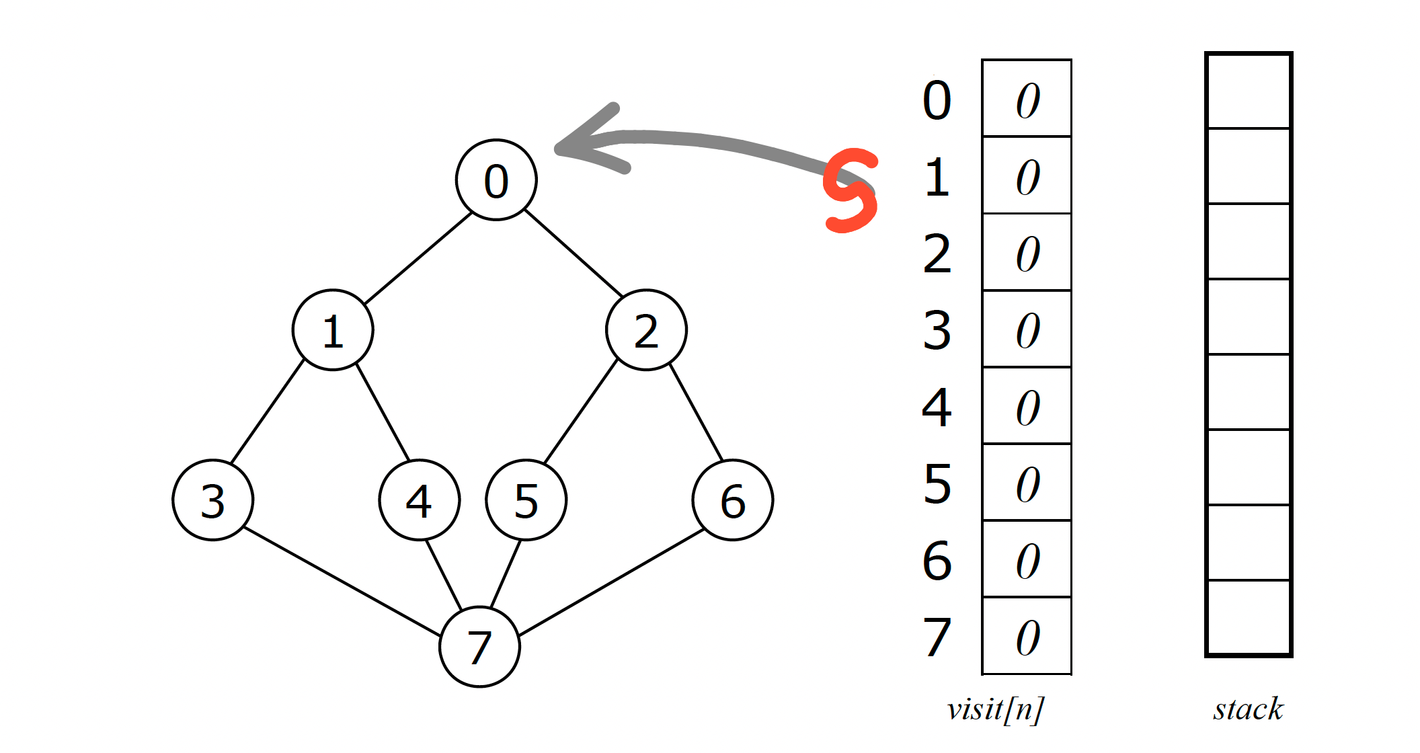
위와 같은 그래프를 순회하는 방법
튜터님이 DFS와 BFS를 제대로 이해하려면 직접 손으로 구현해볼 줄 알아야한다고 하셨다.
우선 숫자를 순회할 visit list가 있어야 한다.
visit = [0, 1, 3, 7, 4, 5, 2, 6] 순서로 숫자를 순회할 때 stack에 쌓이는 순서는 다음과 같다.
0을 스택에 추가: 스택 = [0]
1을 스택에 추가: 스택 = [0, 1]
3을 스택에 추가: 스택 = [0, 1, 3]
7을 스택에 추가: 스택 = [0, 1, 3, 7]
4를 스택에 추가:
0 → 1 → 3 → 7 → 4 → 4를 pop한 후 5 → 2 → 6
→ 6pop → 2pop → 5pop → 7pop → 3pop → 1pop → 0pop
-
처음 4를 pop 하는 이유는 4와 근접한 1과 7이 이미 순회가 되었으므로 4를 pop 한다. 그 후 7로 다시 돌아 가 5를 스택에 쌓는 방식이다.
-
이런 방식으로 계속 순회하다 모든 숫자가 pop 되어 stack이 empty가 되므로 DFS는 종료된다.
DFS로 순회하면 이러한 트리가 만들어지는데신장트리형태가 된다. -
신장 트리(Spanning Tree)는 그래프 이론에서 사용되는 개념으로, 주어진 연결 그래프(Connected Graph)의 모든 노드를 포함하면서 사이클이 없는 트리를 의미한다.
BFS(Breadth-First Search, 너비 우선 탐색)
- BFS는 너비를 우선적으로 탐색하여 옆으로 퍼지며 탐색하는 것이다.
시작 노드에서 출발하여 인정한 노드들을 먼저 탐색한 후 그 다음 단계로 넘어가 탐색하는 방식이다. - 최단경로 탐색, 연결 요소 탐색, 그래프 전체를 탐색 할 때 사용할 수 있다.
위와 같은 그래프가 있을 때 0 → 1→ 2 → 3 → 4 → 5 → 6 → 7 순서로 순회하는 방식이다.
DFS는 stack을 이용하여 구현한다면 BFS는 Queue를 이용하여 구현할 수 있다.
위와 같은 그래프를 순회하는 방법
DFS와 마찬가지로 숫자를 순회할 visit list가 있어야 한다. 너비 우선 탐색이기 때문에 visit = [0, 1, 2, 3, 4, 5, 6, 7] 순서로 숫자를 순회할 때 stack에 쌓이는 순서는 다음과 같다.
0 → 1 → 0 remove → 2 → 1 remove → 3 → 4 → 2 remove → 5 → 6 → 3 remove → 7 → 4 remove → 5 remove → 6 remove → 7 remove
-
remove 하는 이유를 처음 remove된 0을 예로 들면 1에서 2로 갈 때 이미 순회했던 0을 거쳐가야하기 때문에 0을 queue에서 제거하는 것이다.
-
이런 방식으로 계속 순회하다 모든 숫자가 remove 되어 queue가 empty가 되므로 BFS는 종료된다.
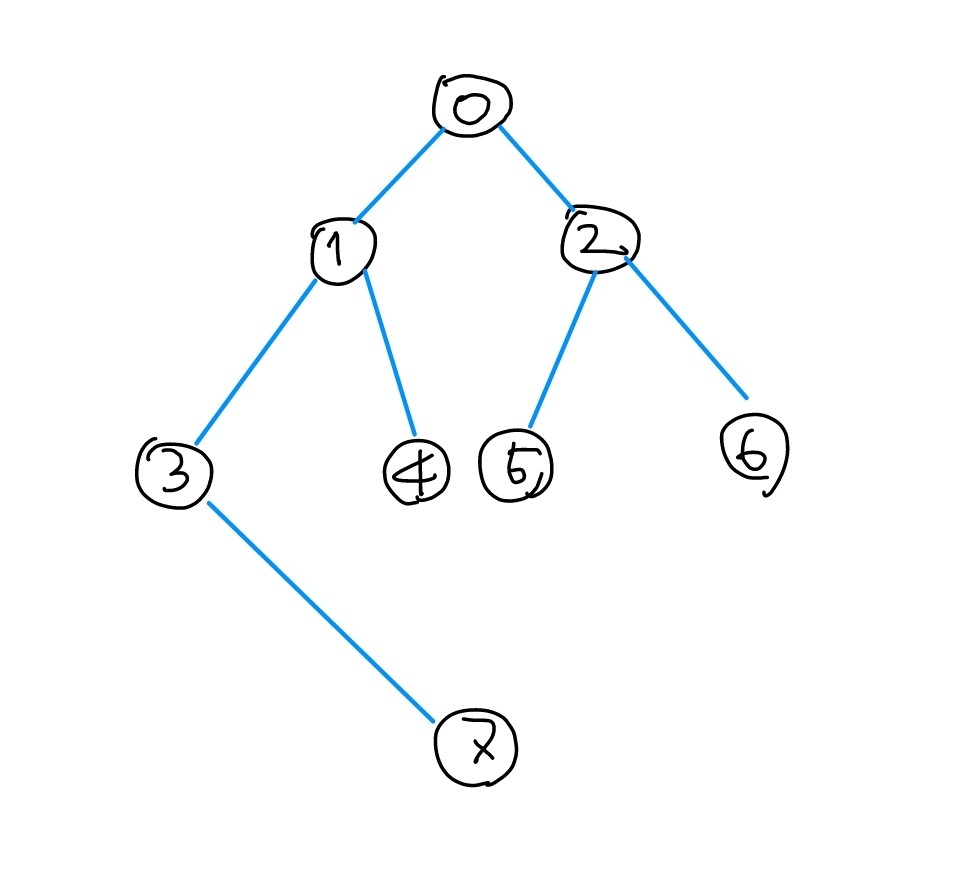
BFS는 이러한 루트로 순회하게 되는데 이 또한신장트리형태이다.
관련 예제
그러면 이제 코드로 구현해보자.
graph = {
"A": ["B", "C"],
"B": ["D", "E"],
"C": ["F"],
"D": [],
"E": ["F"],
"F": [],
}다음과 같은 그래프가 주어졌을 때 그래프모양은 다음과 같다.
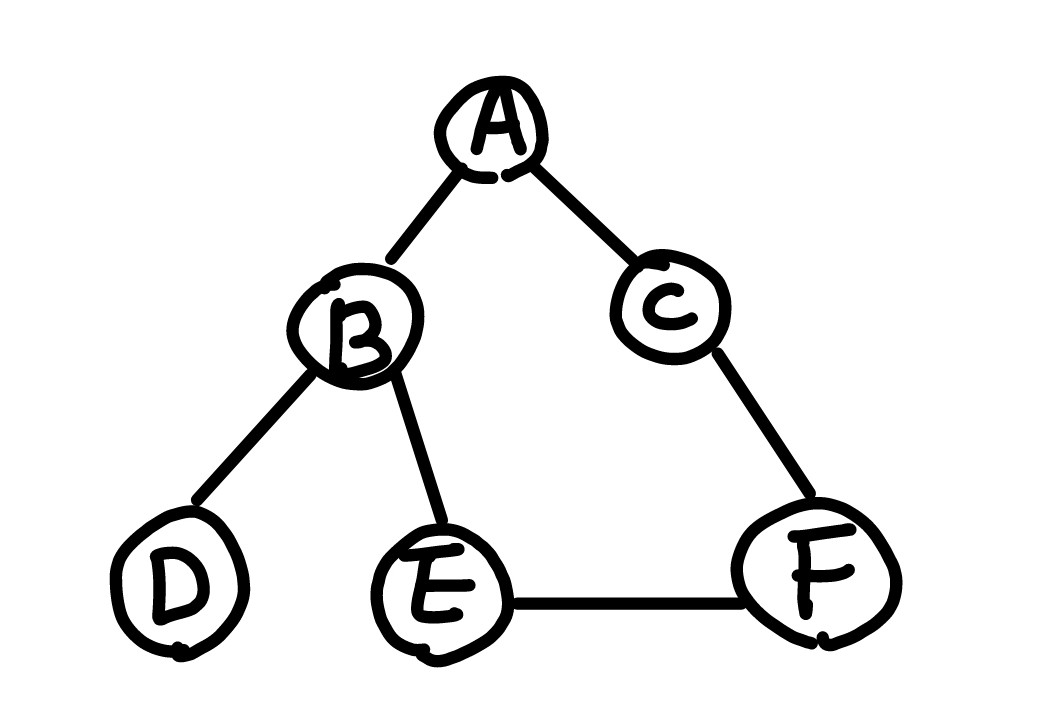
DFS로 코드를 구현하면 다음과 같다.
#정의부
def recursive_dfs(curr_v, visited):
if curr_v not in visited: #현재 내가 탐색하는게 visited에 없으면
visited.append(curr_v) # visited에 추가한다.
for next_v in graph[curr_v]: # graph를 하나씩 돌면서
recursive_dfs(next_v, visited) # 깊이 탐색 하기
#호출부
graph = {
"A": ["B", "C"],
"B": ["D", "E"],
"C": ["F"],
"D": [],
"E": ["F"],
"F": [],
}
visited = []
rlt = recursive_dfs("A", visited)
print(visited)
['A', 'B', 'D', 'E', 'F', 'C'] 출력BFS를 이용하여 탐색하는 방법은 다음과 같다.
from collections import deque
# 정의부
def bfs(curr_v, visited):
queue = deque([curr_v]) #큐 초기화
while queue:
node = queue.popleft() #큐의 왼쪽 요소 제거
if node not in visited: # 현재 노드가 방문한 적이 없으면
visited.append(node) #방문한 것으로 표시
queue.extend(graph[node]) #현재 노드의 인접 노드들을 큐에 추가
# 호출부
graph = {
"A": ["B", "C"],
"B": ["D", "E"],
"C": ["F"],
"D": [],
"E": ["F"],
"F": [],
}
visited = []
bfs("A", visited)
print(visited)
['A', 'B', 'C', 'D', 'E', 'F'] 출력
