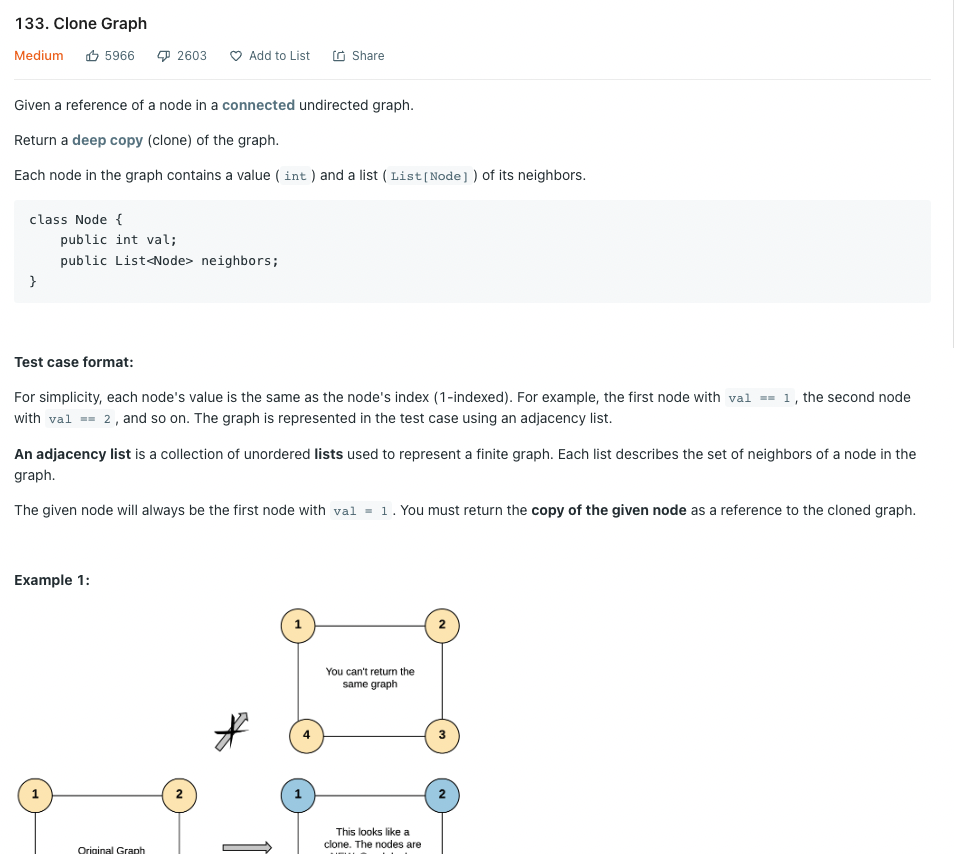
First Thoughts
솔직히 DFS나 BFS를 써야겠다..라는 생각말고는 떠오르는게 없었다. 그래프라는 개념을 처음 접해서 Tree를 처음 접했을때처럼 혼란의 시간을 겪은듯. 근데 생각해보면 사실상 Tree같은 구조는 맞다 (다만 children-parent 관계가 아니라 undirected direction 일뿐....)
Solution
class Solution {
private HashMap<Node, Node> visited = new HashMap<>();
public Node cloneGraph(Node node) {
if (node==null) return null;
if (visited.containsKey(node)) return visited.get(node);
Node clone = new Node(node.val, new ArrayList<Node>());
visited.add(node, clone);
for (Node neighbor : node.neighbors) clone.neighbors.add( cloneGraph(neighbor) );
return clone;
}
}Catch Point
아직 완벽하게 이해한지는 모르겠지만 감은 확실히 잡은 것 같다. 기본적으로 DFS를 이용하는 건 맞다. 시작점을 기준으로 하나하나씩 타고 복사본을 만들어간다. 이때 재귀함수의 무한루프에 걸리지 않으려면 visited HashMap을 사용해서 끊어줘야 한다. 만약 보는 node이면 그냥 clone을 돌려준다.
-
HashMap의 Key는 원본 graph의 node, Value는 그 node의 복사본 (clone Node) 이다. 이때 초면이 아닌 node면 단순히 그의 clone을 반환한다. -> 이걸 안해주면 계속 돌고 돌 수 밖에..undirected이기 때문에 타고타고 가면 언젠가는 똑같은 node를 마주하게 된다.
-
시작점만 있으면 타고타고 모든 node를 visit할 수 있다. 이때 저장되는 node는 복사본이여야함으로 똑같은 함수를 불러줘야한다 -> 재귀 개념.
-
새로운 복사본을 만들어주는 순간 해당 node를 봤다고 표식을 해줘야한다.
