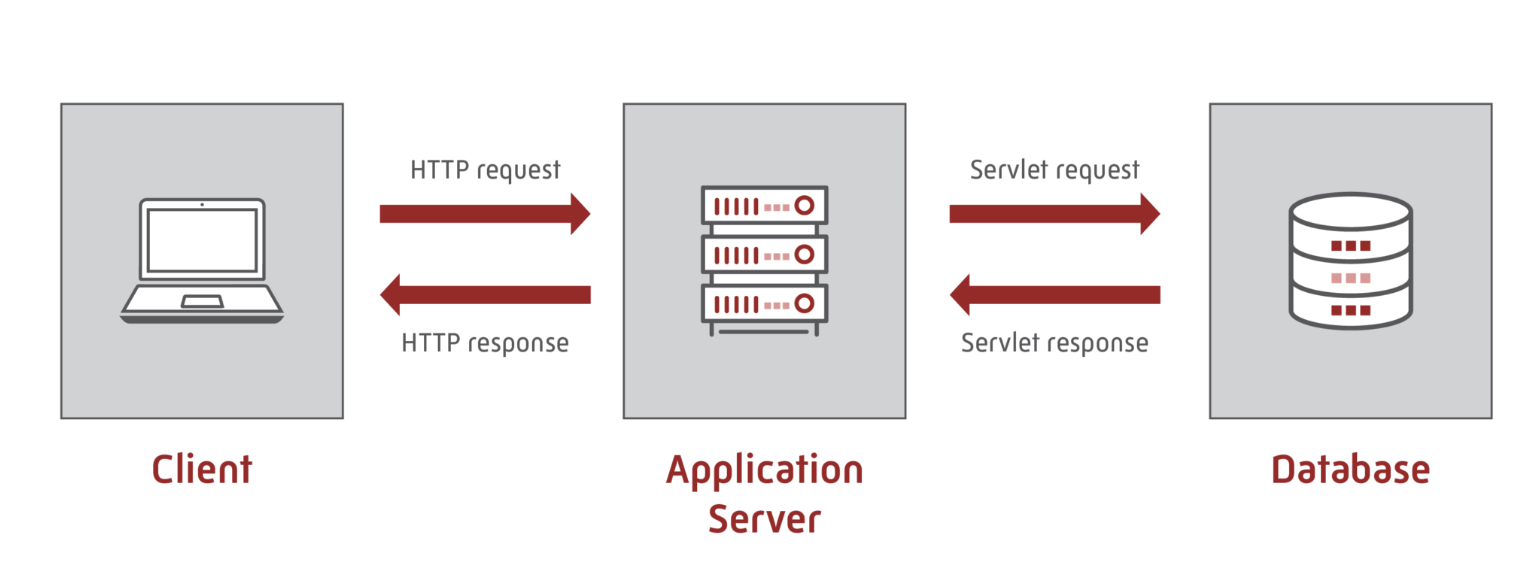
Client-Side and Server-Side Programming
Client-side programming - or front-end programming - works with code being run on the browser, shown to the client. Therefore, improving readability and presentation of the browser is a major concern. Pieces of HTML, CSS, and JS code are run inside the browser, thus often has no access to the underlying operating systems.
Server-side programming - or back-end programming - sets up the necessary APIs (similar to functions) in response to the requests received through the browser. These two sides (web browser and web server) communicates through HTTP requests and responses. Web servers listen to client requests made through the web browser, and sends back the desired results as responses.
HTTP Transfers
Computers communicate through a number of ways, depending on what data is transferred (files, mails, texts, etc.) Data in the form of texts are delivered through HTTP, or HyperText Transfer Protocol. Simply speaking, HTTP is a pathway, where text data is able to pass, in either direction. Through this protocol, requests and responses are sent and received by these separate computers. Because most browsers have more than one page and function, multiple HTTP transfer routes are needed, thus the need for multiple APIs to receive and send out the appropriate requests and response. (For more information of the definition and types of APIs, check out the separate post on API)
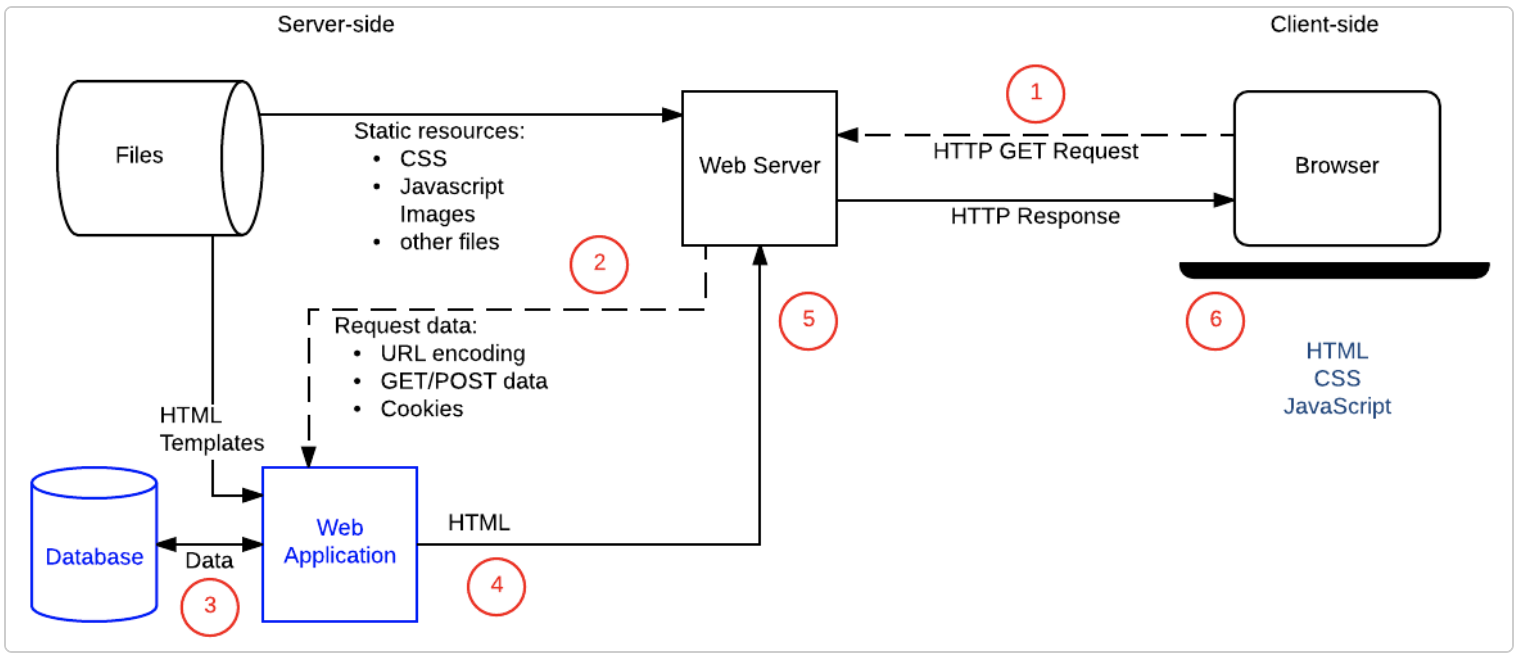
HTTP Request and Response
The frontend computer sends the text data (perhaps the values received from the user) to the backend computer through HTTP, requesting the data to be stored in the database.
Receiving this request, the backend computer sends out a response, indicating whether it is a success or failure. As such, it includes within the response an HTTP status code, ranging from 100 to 599. Some common ones include success(200), frontend error(400), backend error (500).
The frontend does not directly access the database due to reasons such as authorization and data filtering.
Static Sites
Static sites returns the same hard-coded content for every user. They lack efficiency, in that the pages are hard-coded, without a reusable template. Therefore, static site API consists of only GET requests, since no data is modified by the user, thus no need for data modification in database.
Dynamic Sites
Dynamic sites return customized content depending on the user-specified URL and input data, if any. This is relatively more efficient, in that HTML files are constructed from a reusable template, with relevant data inserted based on user input. This improves scalability and makes modification easier.
Functions of Server-Side Programming
Delivery of requested information: HTML template is "dynamically" constructed and returned, based on the user input information and relevant URL. Since information is stored in database, it can be easily shared with other server computers.
Customized browsers: since the pages are dynamically created, different pages are shown to different users and requests. Further analyses on user habits and history can tailor user notifications and display.
Security: servers also control certain access rights to content, showing different content based on user authorization level.
Storing sessions: this relates to the use of cookies, and storing user states (where the user left off can be stored in server)
Notification: server also sends notifications to users, such as confirmation emails and authorization codes to mobile devices.

Here the educational material is always quite provoking and beneficial as well. I hope the various people would able to explore and boost their knowledge about. Really like to share the proposal writing services material with others to learn the file transfer protocols. Thumbs up and please continue bringing wise help always.