
What is Version Control ?
Version control allows us to keep track of all the different versions of the specific file. This is useful when you want to recover an older version of the file to undo certain changes or recover lost files. In fact, our local files named 'essay-draft' 'essay-draft02' 'essay-final' 'essay-finalized-final' (진짜-마지막-최종-리포트.docx) all reflect the concept of version control. As we can see below, methods of version control have changed over time.
Local Version Control
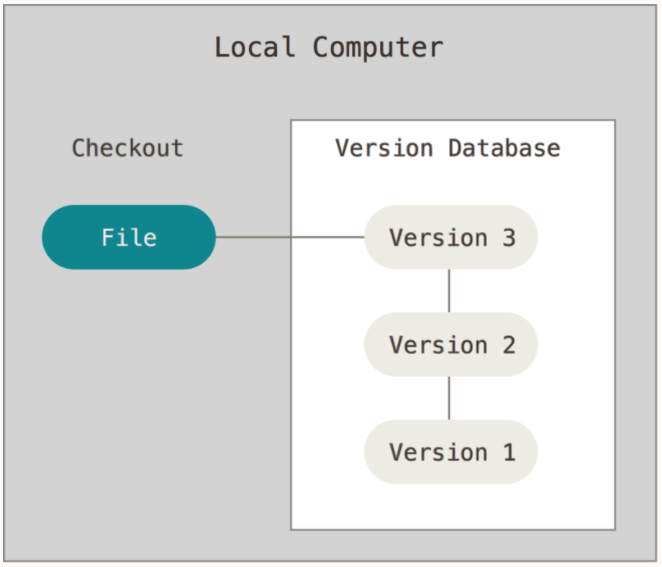
The most intuitive and simple method of keeping track of different versions was done by creating time-stamped copies of the files in local directories. However, as the file is updated multiple times, the number of files and directories must increase to keep track of these updates. Soon, this becomes very confusing, leading to potential loss or mutation of files. As a result, developers came up with a simple version control system to be used locally. This local VCS kept all the changes to the file in the version database. One such VCS is called RCS, which stores the differences between the multiple versions of the file in a special format on disk. This enables the system to recreate the file in any point in time, pulling together relevant patches of the file.
Centralized Version Control
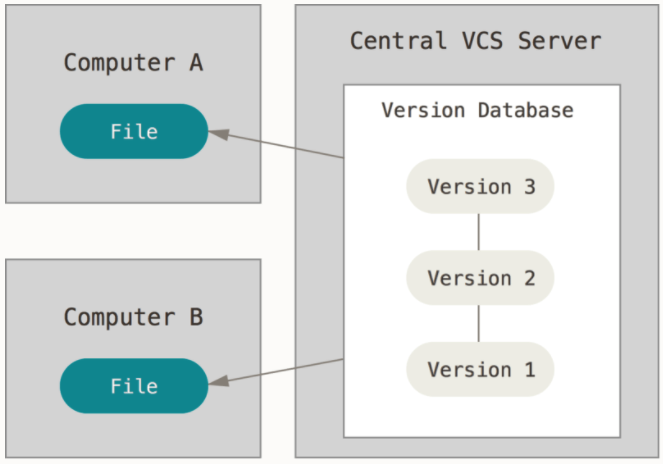
However, one major problem with localized version control was that it was hard to collaborate with other developers. To facilitate access of files between multiple users, a centralized version control system came into use. Through the new system, developers could now each check out the files they need from a shared, central system. Such centralized systems include CVS, Subversion, and Perforce.
The major problem with both local and centralized version control systems was the risk of single point of failure. If the centralized version database goes out and crashes, then now no one can have access to the most recent version, with each user now looking at differing versions of the file. Such critical downside introduced the need for a new version control system.
Distributed Version Control
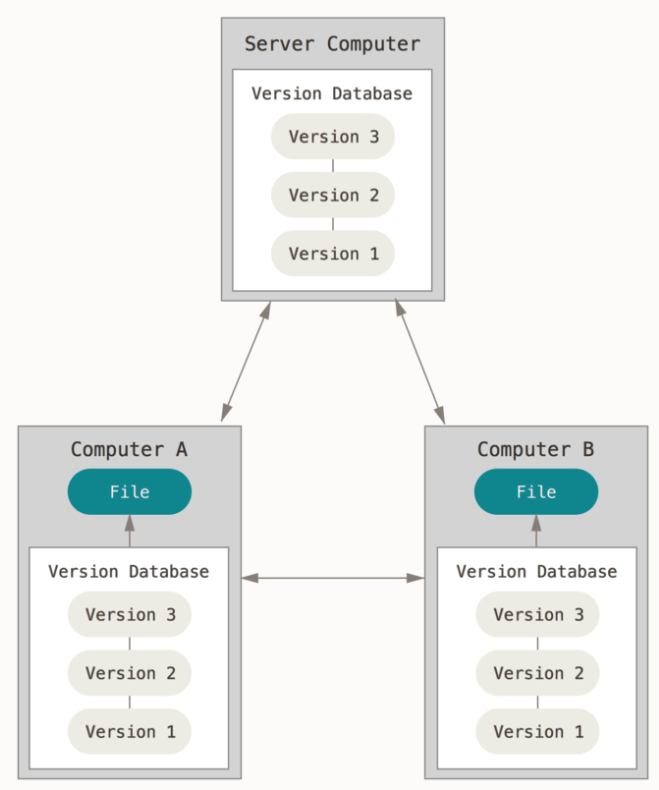
Rather than users checking out the most recent version of the file into their local computers, now when the users check out the file, they now check out its full history. This means that when the central system crashes for some reason, any one user can restore the full snapshot versions of the file back into the system. And one such distributed version control system is Git.
Okay So, What Is Git ?
Snapshots: Git
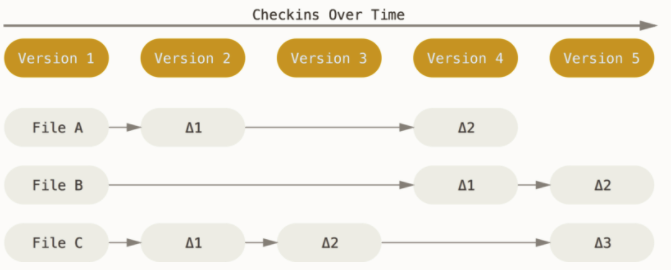
Other version control systems mostly works on a "delta-based" version control, meaning it stores data as a list of file changes. They store the files themselves, and then the updates made to the files over time.
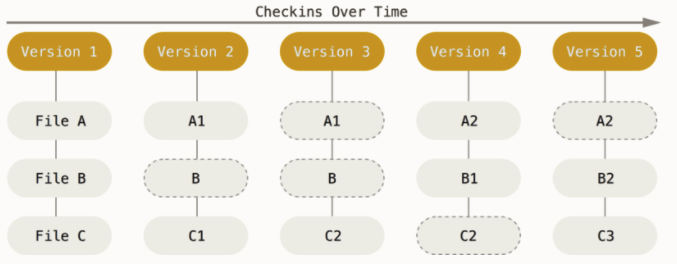
Unlike other version control systems, Git stores information more like a series of file snapshots. If the snapshots are the same, it does not store any additional information and instead refers to the previous version of the file. Simply, Git is a collection of references to file snapshots. As we will talk about later, in the context of git workflow and branching, this way of storing information becomes extremely useful.
The Three States
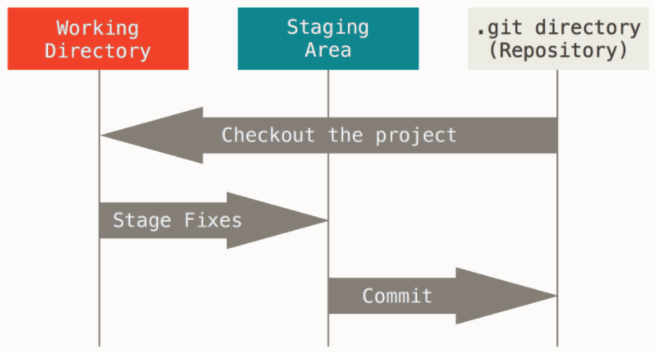
In the context of Git, files can reside in three states: modified, staged, committed. Modified files are altered versions of the file, but have not yet been committed to the database. Staged files are the altered files that have been marked to go into the next committed snapshot. Committed files are the snapshots of the files that are safely stored into the database.
In relation to the three states, there are three areas in a Git project: working directory (or working tree), staging area, and the Git directory. The working tree is simply the checked out version of the file, pulled from the Git database. The staging area is where the updates of the checked out file reside. It is these changes that will go into the next commit. The git repository is where all the snapshots of the project is stored, and is cloned to your local computer.
In sum, the general flow goes as follows: you make changes to the file (pulled from the remote git repository), stage the changes to be stored as your next snapshot version, commit the snapshot, which will be then safely stored permanently in the git repository.
Git Hooks and Husky
Git Hooks / Husky Module
When working in teams, it is especially important to follow common rules. Not doing so can result in inconsistency in coding structure, lack of test codes, lowering of coding coverage, master branch conflicts, etc. Git hooks are one solution to forcing these rules into action. Not allowing direct master pushes or displaying reminder messages to use MR are some examples of implementing git hooks.
More specifically, git hooks are tool kits that execute certain specified scripts triggered by certain git actions. Git hooks mainly consist of two components: client hooks and server hooks. Client hooks are run by the client, triggered by commit, merge, and before pushes to repository. On the other hand, server hooks are run by the server whenever there are new pushes to the git repository. If you have access to managing the git repository server, it may be useful to use server hooks, since all projects in the repository can be bound to a specific push protocol.
There are mainly three ways of sharing git hooks: sharing the scripts that configure git hook specifications, use of git templates, and use of husky. The latter may be a preferrable option in that the other two do not 'enforce' the implementation of the hook itself.
In simple terms, the husky tool adds a flavor of coercion to git hooks. The npm module enables managing commit and push script protocols.
For effective execution of such protocols, it may be useful to combine different tools with the husky npm module - such as gitlab CI/CD. But most of all, it is always important to remember that the effectiveness of protocols depend on whether all team members agree on the necessity of such rules.

Well to have understandable information here that would be useful for various people. The people who want to improve their knowledge about able to explore on https://thedigestonline.com/branded-content/how-to-write-a-cover-letter-for-a-job/ blog and learn. Keep sharing the further related material here that would be wise.