
[1] 필드 동기화 - 개발
앞선 포스트에서 로그 추적기를 만들며 다음 로그를 출력할 때 트랜잭션ID와 level을 동기화하는 문제가 있었다. 그리고 이 문제를 해결하기 위해 TraceId를 파라미터로 넘기도록 구현하였다.
결국 동기화는 성공했지만 로그를 출력하는 모든 메소드에 TraceId 파라미터를 추가해야 하는 문제가 또 발생했다.
이 문제를 해결하기 위해 새로운 로그 추적기를 만든다.
향후 다양한 구현체로 변경할 수 있도록 LogTrace 인터페이스를 먼저 만들고 구현한다.
✔️ LogTrace.java
public interface LogTrace {
// 기존에 했던걸 인터페이스로
TraceStatus begin(String message);
void end(TraceStatus status);
void exception(TraceStatus status, Exception e);
}LogTrace 인터페이스에는 로그 추적기를 위한 최소한의 기능인 begin(), end(), exception()을 정의했다.
⬇️ 이제 파라미터를 넘기지 않고도 TraceeId를 동기화 할 수 있는 FieldLogTrace 구현체를 만들면 된다.
✔️ FieldLogTrace.java
@Slf4j
public class FieldLogTrace implements LogTrace {
private static final String START_PREFIX = "-->";
private static final String COMPLETE_PREFIX = "<--";
private static final String EX_PREFIX = "<X-";
// (기존에는 파라미터로 넘겼다면 이제 여기에 보관해두고 쓰는)
private TraceId traceIdHolder; // traceId 동기화, !동시성 이슈 발생!
@Override
public TraceStatus begin(String message) {
syncTraceId();
TraceId traceId = this.traceIdHolder;
Long startTimeMs = System.currentTimeMillis();
// 로그 출력
log.info("[{}] {}{}", traceId.getId(), addSpace(START_PREFIX, traceId.getLevel()), message);
return new TraceStatus(traceId, startTimeMs, message);
}
private void syncTraceId() {
if(traceIdHolder == null) { // 맨 처음이라면 새로 생성
traceIdHolder = new TraceId();
} else {
traceIdHolder = traceIdHolder.createNextId();
}
}
@Override
public void end(TraceStatus status) {
complete(status, null);
}
@Override
public void exception(TraceStatus status, Exception e) {
complete(status, e);
}
private void complete(TraceStatus status, Exception e) {
Long stopTimeMs = System.currentTimeMillis();
long resultTimeMs = stopTimeMs - status.getStartTimeMs();
TraceId traceId = status.getTraceId();
if (e == null) {
log.info("[{}] {}{} time={}ms", traceId.getId(),
addSpace(COMPLETE_PREFIX, traceId.getLevel()), status.getMessage(),
resultTimeMs);
} else {
log.info("[{}] {}{} time={}ms ex={}", traceId.getId(),
addSpace(EX_PREFIX, traceId.getLevel()), status.getMessage(), resultTimeMs,
e.toString());
}
releaseTraceId();
}
private void releaseTraceId() {
if(traceIdHolder.isFirstLevel()) { // 들어갔다 나오는. 마지막 로그인 상태
traceIdHolder = null; // destroy 파괴
} else {
// 1 2 3 3 2 1 이니까
traceIdHolder = traceIdHolder.createPreviousId();
}
}
private static String addSpace(String prefix, int level) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < level; i++) {
sb.append( (i == level - 1) ? "|" + prefix : "| ");
}
return sb.toString();
}
}FieldLogTrace는 기존의 HelloTraceV2와 거의 같은 기능을 수행한다.
TraceId를 동기화 하는 부분만 파라미터를 사용하는 것에서 TraceId traceIdHolder 필드를 사용하도록 변경되었다.
이제 직전 로그의 TraceId는 파라미터로 전달되지 않고, FieldLogTrace의 필드인 traceIdHolder에 저장된다.
‼️ 중요한 부분은 로그를 시작할 때 호출하는 syncTraceId()와 로그를 종료할 때 호출하는 releaseTraceId()이다.
syncTraceId()
:TraceId를 새로 만들거나 앞선 로그의TraceId를 참고해 동기화하고,level도 증가한다.
그리고 최초 호출이라면TraceId를 새로 만든다.
직전 로그가 있다면 해당 로그의TraceId를 참고해 동기화하고, level도 하나 증가한다.
결과를traceIdHolder에 보관한다.
releaseTraceId()
: 메소드를 추가로 호출할 때는level이 하나 증가해야 하지만, 메소드 호출이 끝나면level이 하나 감소해야 한다.
releaseTraceId()는level을 하나 감소한다.
만약 최초 호출(level==0)이면 내부에서 관리하는traceId를 제거한다.
✔️ FieldLogTraceTest.java
class FieldLogTraceTest {
FieldLogTrace trace = new FieldLogTrace();
@Test
void begin_end_level2() {
TraceStatus status1 = trace.begin("hello1");
TraceStatus status2 = trace.begin("hello2");
trace.end(status2);
trace.end(status1);
}
@Test
void begin_exception_level2() {
TraceStatus status1 = trace.begin("hello1");
TraceStatus status2 = trace.begin("hello2");
trace.exception(status2, new IllegalStateException());
trace.exception(status1, new IllegalStateException());
}
}

실행 결과를 보면 트랜잭션ID도 동일하게 나오고 level을 통한 깊이도 잘 표현되고 있다.
FieldLogTrace.traceIdHolder 필드를 사용해 TraceId가 잘 동기화 되는 것을 확인할 수 있다.
이제 불필요하게 TraceId를 파라미터로 전달하지 않아도 되며, 애플리케이션의 메소드 파라미터도 변경하지 않아도 된다.
[2] 필드 동기화 - 적용
: FieldLogTrace 애플리케이션에 적용하기
LogTrace 스프링 빈 등록
FieldLogTrace를 수동으로 스프링 빈으로 등록한다.
수동으로 등록하면 향후 구현체를 편리하게 변경할 수 있다는 장점이 있다.
✔️ LogTraceConfig.java
@Configuration
public class LogTraceConfig {
@Bean
public LogTrace logTrace() { // 인스턴스가 딱 하나만 등록됨
return new FieldLogTrace();
}
}✔️ OrderControllerV3.java
@RestController // @Controller + @ResponseBody
@RequiredArgsConstructor
public class OrderControllerV3 {
private final OrderServiceV3 orderService;
private final LogTrace trace;
@GetMapping("/v3/request")
public String request(String itemId) {
TraceStatus status = null;
try { // 정상 실행시
status = trace.begin("OrderController.request()");
orderService.orderItem(itemId);
trace.end(status);
return "ok";
} catch (Exception e) { // 예외 발생시
trace.exception(status, e); // -> 예외를 먹음(?)
throw e; // (먹었으니 정상 흐름이 되어버림 그래서 )예외를 꼭 다시 던져주어야 한다.
}
}
}✔️ OrderServiceV3.java
@Service // @Service 안에 @Component가 있어 자동으로 컴포넌트 스캔의 대상이 됨(자동으로 스프링 빈 등록)
@RequiredArgsConstructor // 생성자 자동 생성
public class OrderServiceV3 {
private final OrderRepositoryV3 orderRepository;
private final LogTrace trace;
public void orderItem(String itemId) {
TraceStatus status = null;
try { // 정상 실행시
status = trace.begin("OrderService.orderItem()");
orderRepository.save(itemId);
trace.end(status);
} catch (Exception e) { // 예외 발생시
trace.exception(status, e); // -> 예외를 먹음(?)
throw e; // (먹었으니 정상 흐름이 되어버림 그래서 )예외를 꼭 다시 던져주어야 한다.
}
}
}✔️ OrderRepositoryV3.java
@Repository // 안에 @Component가 있어 자동으로 컴포넌트 스캔 대상이 됨(스프링 빈 등록)
@RequiredArgsConstructor
public class OrderRepositoryV3 {
private final LogTrace trace;
public void save(String itemId) {
TraceStatus status = null;
try {
status = trace.begin("OrderRepository.save()");
// 저장 로직
if(itemId.equals("ex")) { // (다양한 예제를 위해)"ex"라는 것이 넘어오면 예외 발생시킬
throw new IllegalStateException("예외 발생!");
}
sleep(1000); // 상품을 저장하는데 1초 정도 걸린다고 가정
trace.end(status);
} catch (Exception e) {
trace.exception(status, e);
throw e;
}
}
private void sleep(int millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}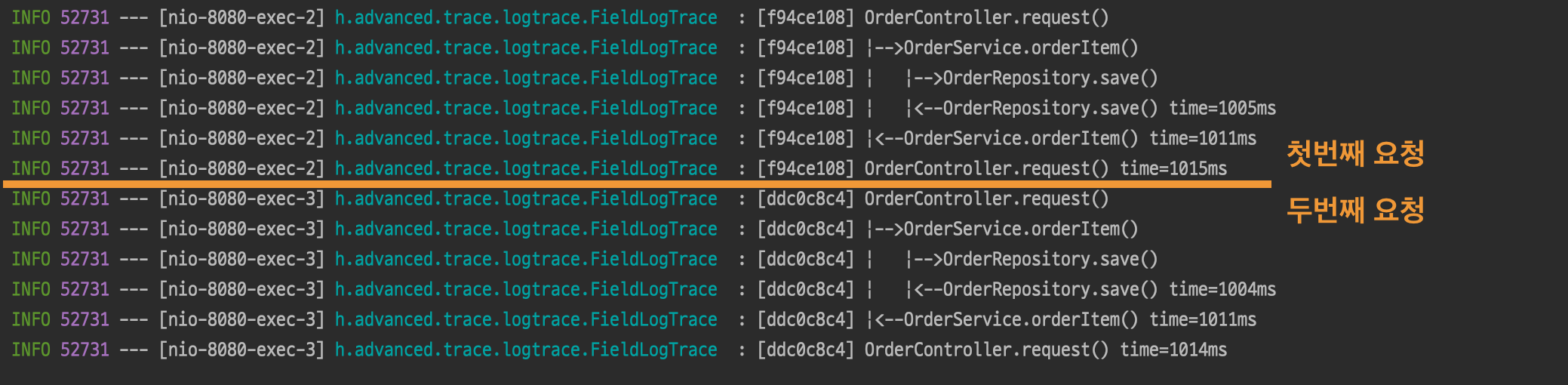
traceIdHolder 필드를 사용한 덕분에 파라미터 추가가 없는 깔끔한 로그 추적기를 만들었지만 실제 서비스에 가정한다면 동시성 문제 가 발생한다.
[3] 필드 동기화 - 동시성 문제
이렇게 만든 로그 추적기를 실제 서비스에 배포한다면 심각한 동시성 문제 로 고생하게 될 것이다.
동시성 문제를 확인해보기 위해 1초 안에 두 번 호출해보았다.
⬇️ 실제 결과
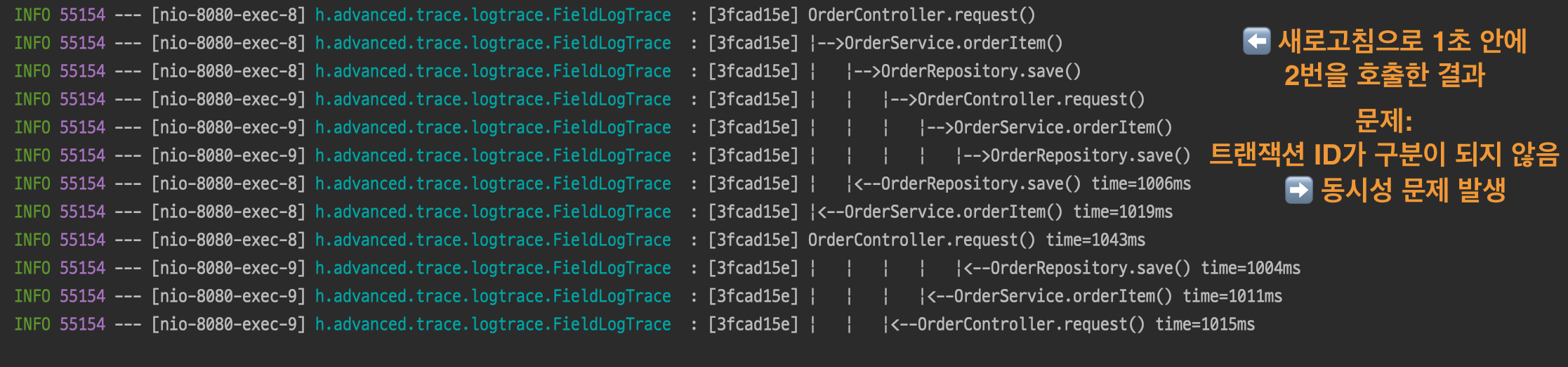
트랜잭션ID도 동일하고, level도 많이 꼬여있다.
⬇️ 기대했던 결과
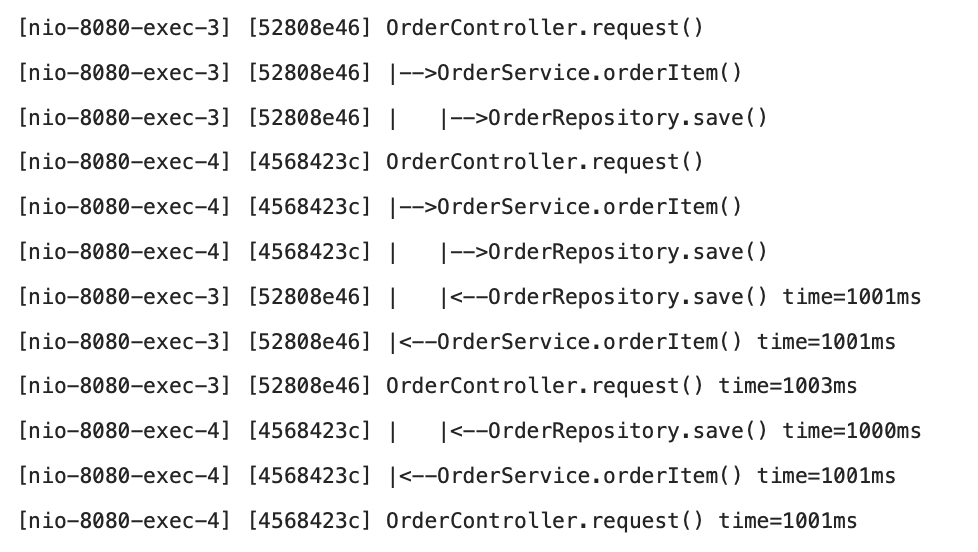
동시에 여러 사용자가 요청하면 여러 스레드가 동시에 애플리케이션 로직을 호출하여 로그가 이렇게 섞여 나오게 된다.
하지만 로그가 섞여 출력된다고 해도 특정 트랜잭ID로 구분해 직접 분류해보면 깔끔하게 분리된 것을 확인 할 수 있지만, 위 사진에서 보았듯 기대와는 전혀 다르게 트랜잭션ID가 구분되지 않고 있다.
이 문제의 원인은 동시성 문제이다.
FieldLogTrace는 싱글톤으로 등록된 스프링 빈이다.
그 말은 즉 이 객체의 인스턴스가 애플리케이션에 딱 1개 존재한다는 것이다.
이렇게 하나만 있는 인스턴스의 FieldLogTrace.traceIdHolder 필드를 여러 스레드가 동시에 접근하기 때문에 문제가 발생한다.
실무에서 발생하면 가장 괴로운 문제라고 하신다😞
[4] 동시성 문제 - 예제 코드
우선 테스트에서도 lombok을 사용하기 위해 build.gradle에 다음과 같은 코드 추가하기
dependencies {
...
// 테스트에서 lombok 사용을 위함
testCompileOnly 'org.projectlombok:lombok'
testAnnotationProcessor 'org.projectlombok:lombok'
}➡️ 이렇게 해줘야 테스트 코드에서 @Slfj4와 같은 어노테이션을 작동시킬 수 있다.
✔️ FieldService.java
위치는 src/test
@Slf4j
public class FieldService {
private String nameStore;
public String logic(String name) {
log.info("저장 name={} -> nameStore={}", name, nameStore);
nameStore = name;
sleep(1000); // 저장하는데 1초 정도 걸린다고 가정한 것
log.info("조회 nameStore={}", nameStore);
return nameStore;
}
private void sleep(int millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}매우 단순한 로직으로 파라미터로 넘어온 name을 필드인 nameStore에 저장한다.
그리고 1초 쉰 다음 필드에 저장된 nameStore을 반환한다.
✔️ FieldServiceTest.java
@Slf4j
public class FieldServiceTest {
private FieldService fieldService = new FieldService();
@Test
void field() {
log.info("main start");
// 스레드 실행 로직
Runnable userA = () -> {
fieldService.logic("userA");
};
Runnable userB = () -> {
fieldService.logic("userB");
};
Thread threadA = new Thread(userA);
threadA.setName("thread-A");
Thread threadB = new Thread(userB);
threadB.setName("thread-B");
threadA.start();
sleep(100); // 동시성 문제가 발생X
threadB.start();
sleep(2000); // 메인 스레드 종료 대기
log.info("main exit");
}
private void sleep(int millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}Runnable userA = new Runnable() { @Override public void run() { fieldService.logic("userA"); } };⬆️ (⚠️참고) 람다식을 풀어서 하면
sleep(2000)을 설정했기 때문에 thread-A의 실행이 끝나고 난 다음 thread-B가 실행된다.
(⚠️ FieldService.logic() 메소드는 내부에 sleep(1000)으로 1초의 지연이 설정되어 있다.)
그래서 차례대로 실행되기 위해서 넉넉히 2초의 지연을 설정했다.
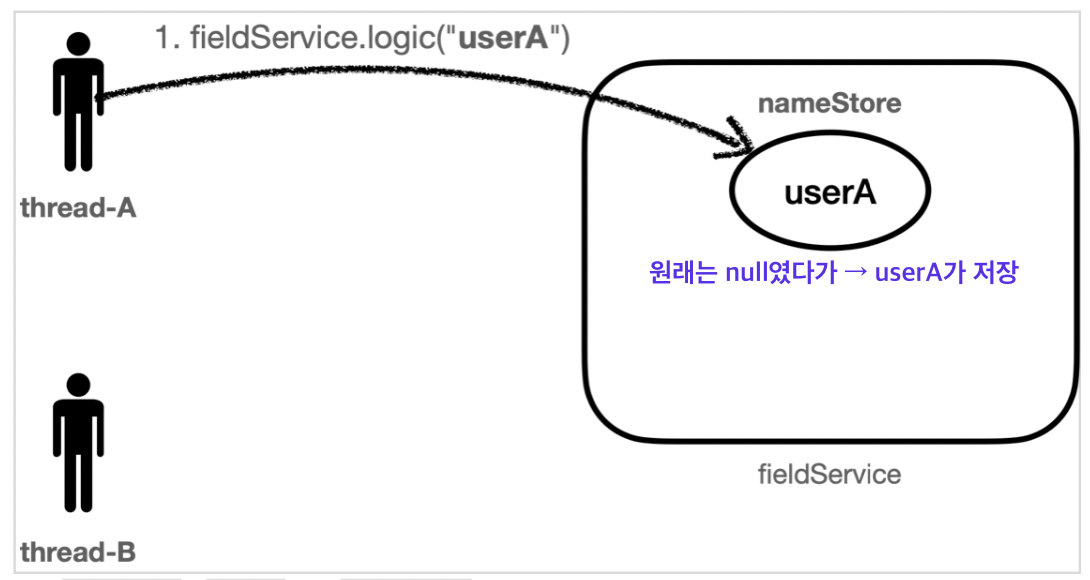
⬇️ 실행 결과

➡️ 처음에는 null이었지만, thread-A가 실행되고 nameStored에는 userA 값이 들어간다. 그래서 thread-A가 끝날 시점에 반환되는 값은 userA이다.
동작
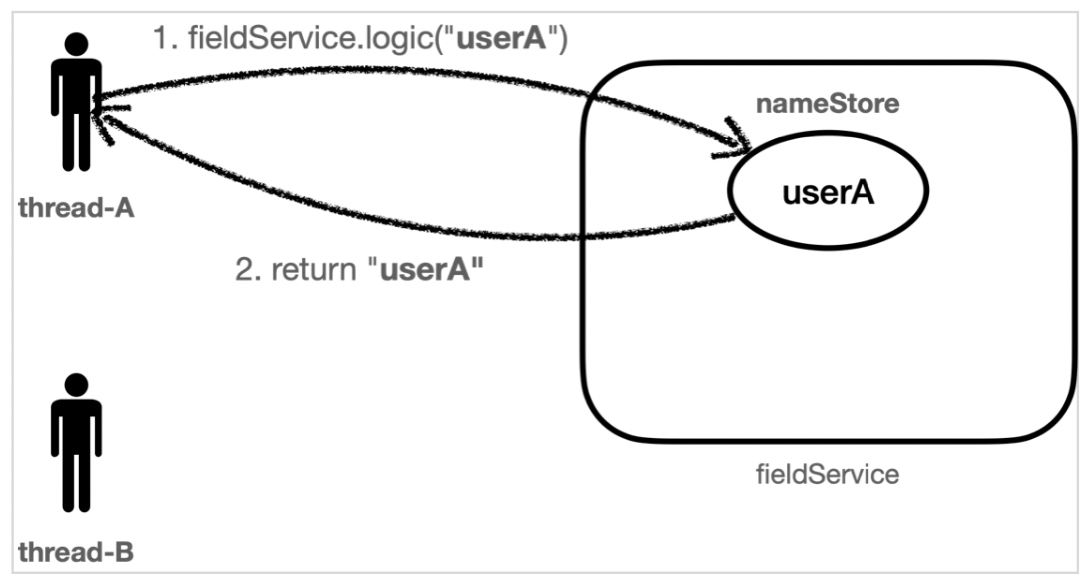
⬇️ 동시성 문제가 발생한 결과
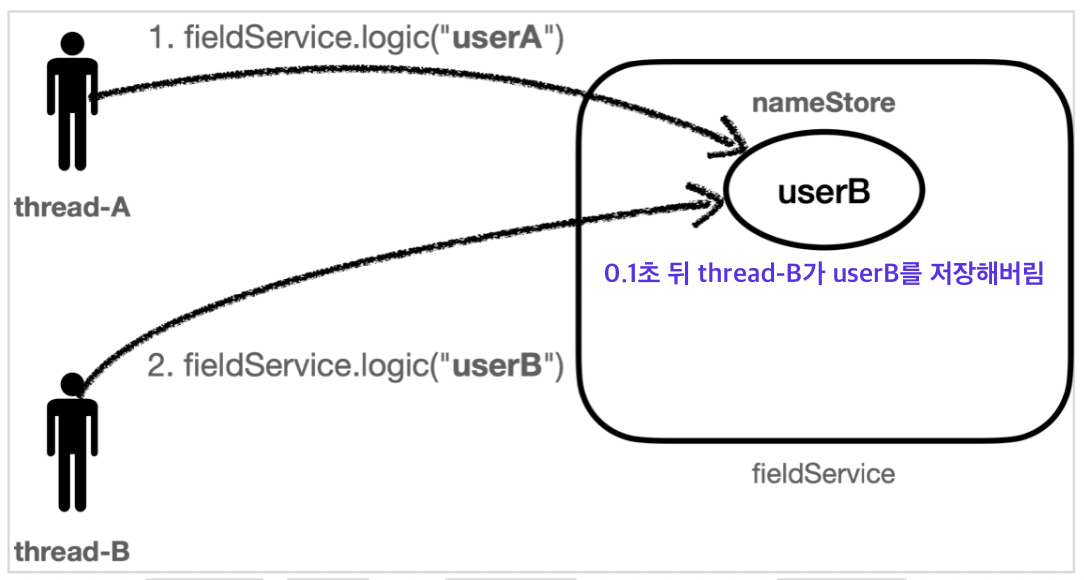
sleep(100)으로 코드를 수정하여 동시성 문제가 발생하도록 만들어보았다.
(1초 이상의 지연을 주어야 순서대로 실행 가능함)

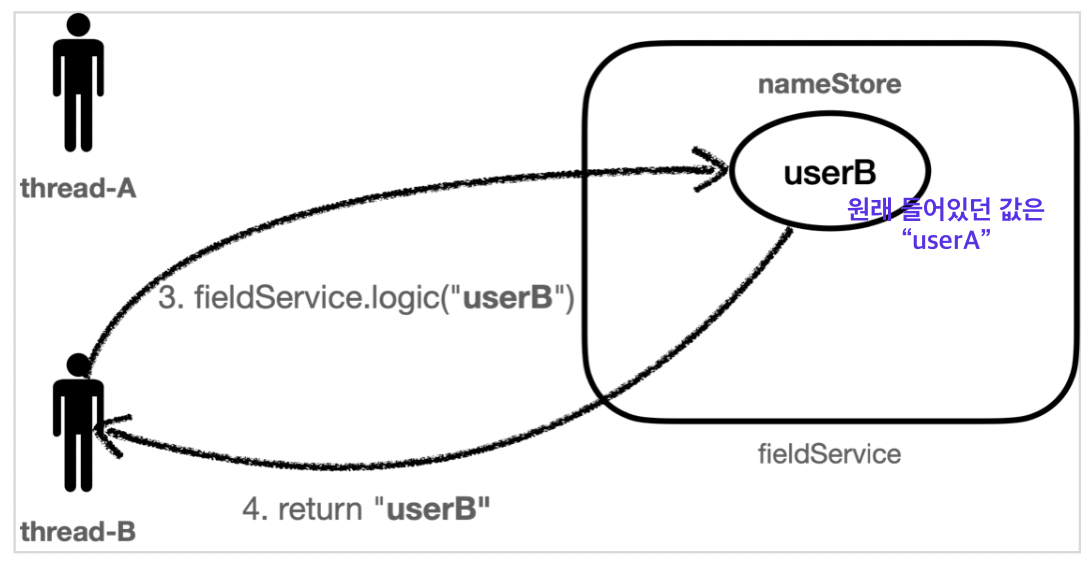
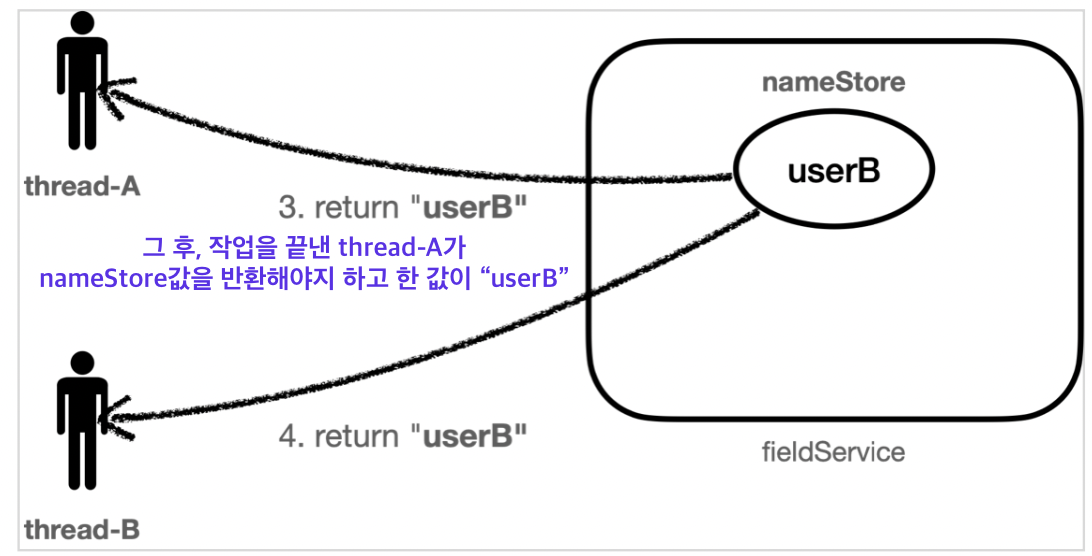
➡️ thread-A가 실행을 끝내고 userA를 반환해주어야 하는데 끝내기 전 thread-B가 새치기하여 userB 값을 nameStore에 넣어버렸기 때문에 thread-A의 반환값이 userB가 되어버렸다.
동작
동시성 문제
결과적으로 Thread-A의 입장에서는 저장한 데이터와 조회한 데이터가 다른 문제가 발생한다.
이처럼 여러 스레드가 동시에 같은 인스턴스의 필드 값을 변경하며 발생하는 문제를 동시성 문제라고 한다.
이런 동시성 문제는 여러 스레드가 같은 인스턴스의 필드에 접근해야 하기 때문에 트래픽이 적은 상황에서는 확률상 잘 나타나지 않지만, 트래픽이 점점 많아질 수록 자주 발생한다.
특히, 스프링빈처럼 싱글톤 객체의 필드를 변경하며 사용할 때 조심해야 한다.
📌
이런 동시성 문제는 지역 변수에서는 발생하지 않는다.
지역 변수는 스레드마다 각각 다른 메모리 영역이 할당된다.동시성 문제가 발생하는 곳은 같은 인스턴스 필드(멤버 변수)(주로 싱글톤에서 자주 발생), 또는 static 같은 공용 필드에 접근할 때 발생한다.
그리고 동시성 문제는 값을 읽기만 한다면 문제가 없다. 어디선가 값을 변경하기 때문에 발생한다.
그렇다면 싱글톤 객체의 필드를 사용하며 동시성 문제를 해결하기 위한 방법은 ? ThreadLocal
