왜..?
데이터 양이 많은 API같은 경우에 API 속도가 느려서 이 성능을 좀 개선해보고 싶어서 redis를 사용해보고자 한다
Redis란?
레디스(Redis)는 오픈 소스 인메모리 데이터 구조 저장소다. 인메모리 데이터 저장소가 뭐냐면, 쉽게 말하면 데이터를 메모리에 올리는거라고 생각하면 된다. cpu 입장에서 보면 메모리는 디스크의 캐시라고 생각하면 편하다. 그렇기 때문에 redis를 캐시 데이터베이스 라고 부르기도 한다.
주로 캐싱, 세션 관리, 메시지 브로커 등으로 사용되며, 디스크에 데이터를 저장하고 검색하는 것보다 훨씬 빠른 메모리 기반의 데이터베이스이다. 레디스는 키-값 쌍을 저장하며, 각 키는 문자열, 해시, 목록, 집합, 정렬된 집합 등과 같은 여러 가지 데이터 구조를 가진다.
백업 방식
redis는 인메모리 저장소니깐 메모리의 특성인 휘발성을 가지고 있다. 그렇기 때문에 데이터의 영속성을 보장하기 위해 특정 방식을 이용한다.
-
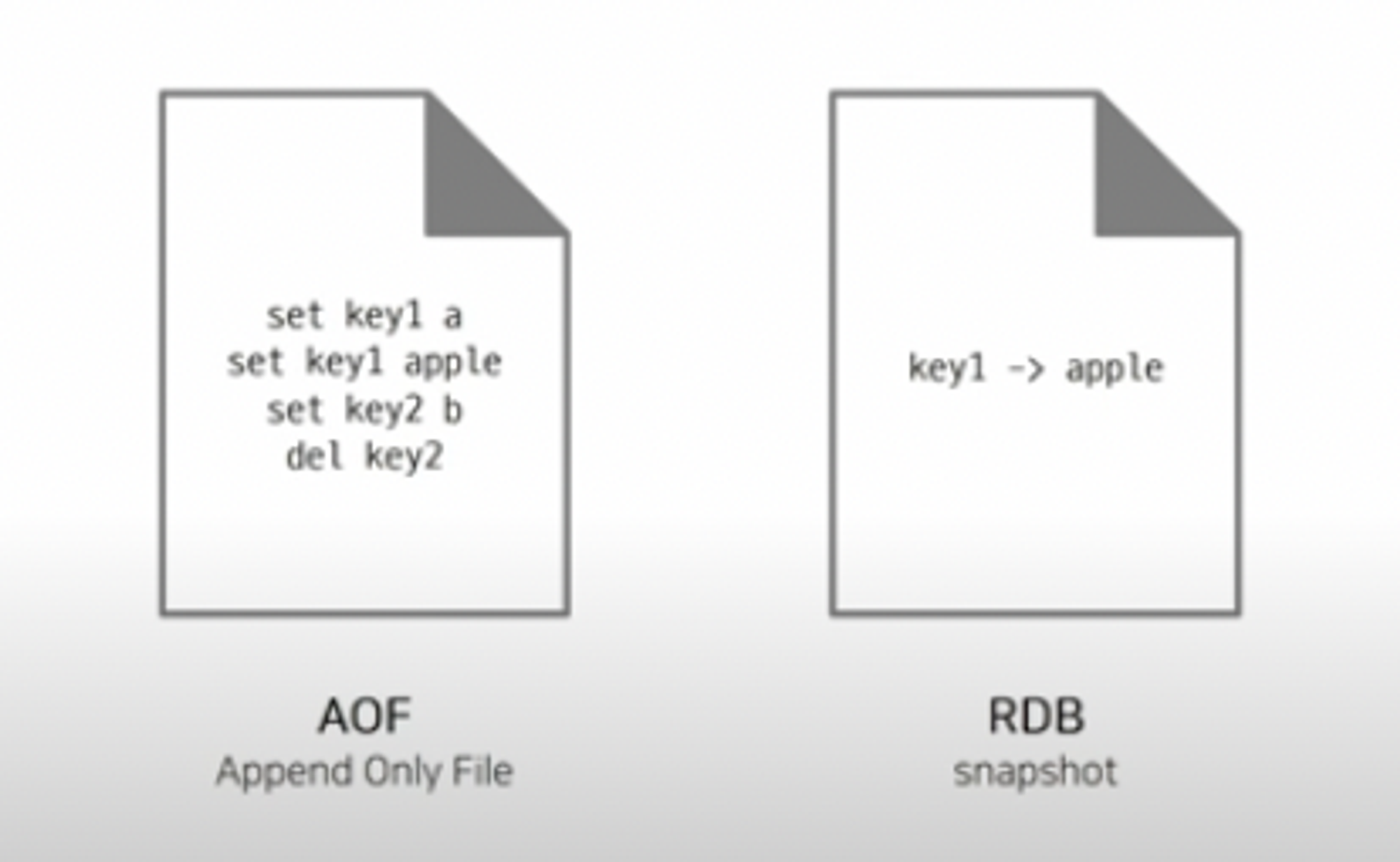
RDB (Redis Database) : 메모리에 있는 모든 데이터를 스냅샷으로 저장하고, 이를 디스크로 저장하는 방식
근데 이 방식은 스냅샷이 날아가거나 스냅샷 이후에 변경된 데이터를 복구할 수가 없다.(data loss)
-
AOF (Append Only File) : 데이터가 변경되는 이벤트가 발생하면 이를 모두 로그에 저장하는 방식
모든 데이터의 변경 기록들을 보관하고 있으므로 최신 데이터 정보를 백업 가능
RDB 방식보다 로딩 속도가 느리고 파일 크기가 큰 것이 단점
이러한 장,단점이 뚜렷하게 존재하기 때문에 프로젝트 컨셉에 맞게 백업방식을 설정해주는게 좋다. 뭐 예를 들자면
캐시로만 사용할 때(data loss가 사소한 경우) -> RDB
모든 데이터가 보장되어야 하는 경우 -> AOF
강력한 내구성을 요구하는 경우 -> RDB + AOF사실, 결국에는 redis는 AOF랑 RDB를 동시에 사용해서 데이터를 백업하긴 한다.
→ 스냅샷 전까지 데이터는 RDB, 스냅샷을 저장하기 전까지 변경된 데이터는 AOF
Thread
redis는 실행한 명령어들을 event loop 방식으로 처리한다. event loop 방식은 주로 node.js에서 비동기 처리를 할 때 자주 사용되는 방식이다. 쉽게 말해서 뭐냐면 실행한 명령어는 event queue라는 이벤트를 기록하는 목록에 넣어 놓고 스레드로 하나씩 처리한다. 결국에는 node.js랑 같게 redis로 single thread다. 하지만 메모리를 사용하기 때문에 빠르게 데이터를 처리할 수 있다.
뭐 single thread라고 해서 단점만 있는게 아니다. thread끼리 발생하는 context switch도 안생기기 때문에 리소스를 효율적으로 사용할 수도 있고 이 덕분에 Deadlock도 발생하지 않는다.
대신에 오버헤드가 큰 명령어를 처리하는 동안 다른 명령어를 처리 못하는 병목현상이 좀 뼈아프긴 하지만.. 이거는 뭐 메모리가 해결해주겠지..
용도
용도는 뚜렷하긴하다. 내가 사용한 것처럼 보통 데이터 캐시로 이용한다. 자주 사용되는 파일이나 API와 같은 것들을 캐싱해서 데이터베이스나 파일을 직접 열어보지 않고도 빠르게 꺼내올 수 있다.
이외에도 메시지큐를 통해서 실시간 애플리케이션을 만들때 사용되기도 하는데 이는 나중에 다뤄볼 예정이다.
자료구조
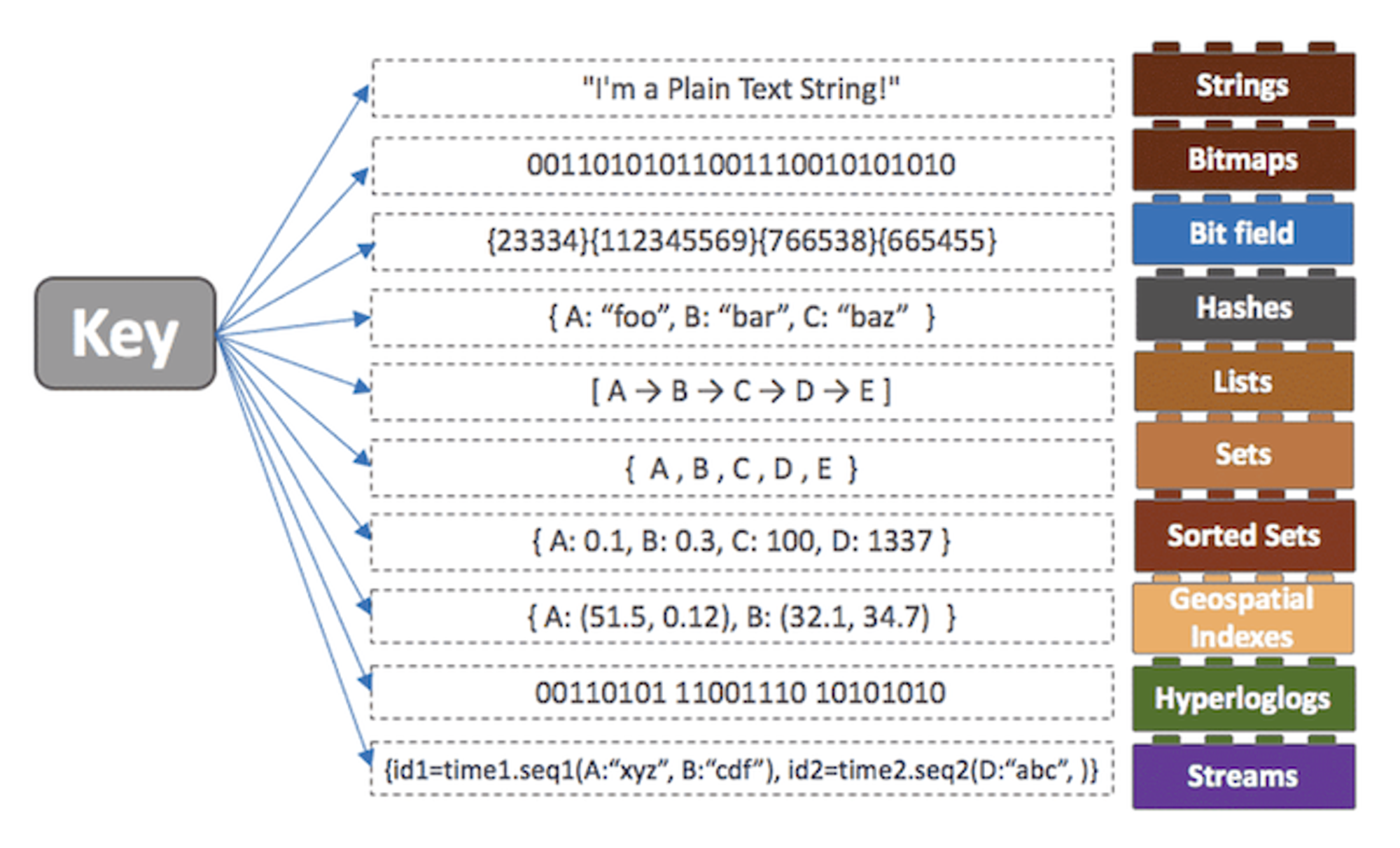
음 앞에서 말했듯이 기본적으로 key-value 형태의 구조를 띈다. 이 구조는 python에서는 dictionary java에서는 hashmap과 유사하다고 생각하면 된다.
# python
dicts = {i:"" for i in range(5)}
# java
Map<Integer, String> dicts = new HashMap<>();
for (int i = 0; i < 5; i++) {
dicts.put(i, "");
}
# redis
127.0.0.1:6379 > HMSET myhash 0 "" 1 "" 2 "" 3 "" 4 ""
OK- 문자열(Strings): 가장 기본적인 데이터 타입으로, 텍스트나 이진 데이터를 포함하는 문자열을 저장할 수 있다.
- 해시(Hashes): 필드와 값의 쌍을 저장하는 데이터 타입입니다. 주로 객체를 표현하거나 관련 있는 여러 속성을 그룹화하여 저장할 때 사용된다.
- 목록(Lists): 여러 개의 요소를 순서대로 저장하는 데이터 타입입니다. 주로 최근 작업 로그, 메시지 큐 등에 사용된다.
- 집합(Sets): 중복되지 않는 요소들을 저장하는 데이터 타입으로, 교집합, 합집합, 차집합 등의 집합 연산을 제공한다.
- 정렬된 집합(Sorted Sets): 집합과 유사하지만, 각 요소에 대한 순서가 지정된 데이터 타입입니다. 주로 랭킹 시스템이나 범위 쿼리에 사용된다.
- 비트맵(Bitmaps): 비트 단위로 값을 저장하는 데이터 타입입니다. 주로 여러 상태를 효율적으로 표현하거나 집계에 사용된다.
- 하이퍼로그로그(HyperLogLogs): 집합의 고유한 요소 수를 근사치로 추정하는 데이터 타입입니다. 주로 고유한 사용자 수나 중복 제거를 위해 사용된다.
- 지리적 위치(Geospatial Indexes): 지리적 좌표를 저장하고 검색하는 데이터 타입입니다. 주로 위치 기반 서비스에 사용된다.
그래서 해볼거
대충 redis가 어떤건지 알아봤는데 내가 이번에 할 task는 2가지다.
Todo
- 자주 사용하는 API 캐싱하기
- 모델 추론에 필요한 파일 redis에 저장해놓고 캐싱해서 사용하기
설치
쓸려면 설치를 해야되니깐 설치부터 알아보자. 나는 테스트하는 서버가 window고 실제 배포되는 서버가 ubuntu라 두가지 방법으로 설치를 해봤다.
linux(ubuntu)
일단 항상 하는거지만 업데이트를 먼저 진행해준다. 그리고 아래의 설치 명령어로 설치한다.
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install redis-server이렇게 설치하고 이 명령어를 입력하면
redis-server 이렇게 잘 나올거다.
이렇게 잘 나올거다.
window
일단 redis는 슬프게도 window에서는 지원하지 않는다. 그래도 쓸 수 있는 방법은 항상 존재한다. linux보다 쉽다 사실 그냥 https://github.com/microsoftarchive/redis/releases 여기에 가서 .msi파일 다운받으면 된다.
이렇게 해서

이렇게 나오면 잘 작동하는거다.
Django에 연결하기
설치는 다 완료 됐으니깐 이제 내가 사용하고 있는 django 프로젝트에 연결해야된다. 연결하는 방법도 간단하다. 프로젝트의 settings.py에 가서 이 코드만 추가해주면 된다.
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1", # 비밀번호가 없는 경우
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
}
}
-------------------------------------------------------------------
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://<password>@127.0.0.1:6379/1", # 비밀번호가 있는 경우
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
}
}1. 자주 사용하는 API 캐싱하기
연결도 다했으니 API 캐싱부터 해보자 일단 내 프로젝트에 데이터베이스에 있는 데이터를 모델 학습을 위해서 Airflow 서버로 넘겨줘야 하는데 이를 위한 API를 캐싱해 볼 생각이다.
@api_view(["GET"])
def answer_total(request):
queryset = AnswerList.objects.all()
serializer = AnswerSerializer(queryset,many=True)
return Response(serializer.data)간단한 전체 데이터를 get해주는 API 코드다. 이거를 cache를 사용해서 최적화 해보자
@api_view(["GET"])
def get_answer_total_cache(request):
cached_data = cache.get('cached_answer_total')
if cached_data is None:
queryset = AnswerList.objects.all()
serializer = AnswerSerializer(queryset,many=True)
data = serializer.data
cache.set('cached_answer_total',data,timeout=3600) # 3600초 동안 유지
return Response(data)
else:
return Response(cached_data)redis에서 queryset 그대로 저장하려고 해봤는데 redis에는 지원하지 않는 형식이라 serializer을 통해 직렬화를 진행해서 저장했다.
코드는 쉽게 말해서 caching된 데이터 없으면 원래 방식대로 코드 진행한 다음 redis에 저장해주고 있으면 그대로 불러와서 호출해주는거다.
성능은 확실하다. 2.5초 걸리던 API가 0.07초로 줄어들었다.

2. 모델 추론에 필요한 파일 redis에 저장해놓고 캐싱해서 사용하기
사실 이거를 위해서 redis를 사용하기로 마음먹었는데, 방법을 2가지 정도 생각해놓고 있었다.
1. python manage.py runserver 하기 전에 미리 올려놓는 코드 짠 다음에
script로 한번에 실행하기 -> 필요할때 그때그때 cache.get해서 가져오기
2. servicesconfig안에 파일을 올리는게 아니라 redis에 저장하는 코드를 만들어서
프로젝트안에 파일 저장안해도 빌드 되도록 하기이 2가지였다.
1번 방식
1번 방식은 API 캐싱이랑 방식이 비슷하다. 빌드하기 전에 실행할 python 파일을 만들어주고 캐싱을 위한 코드를 작성한다. 나는 올려놓을 파일이 종류도 다양하고 많아서 일반화해서 코드를 작성했다.
# toredis.py
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "recommendu.settings")
#django 안에 새로운 파일 실행할 때 필요한 세팅
def get_make_cache(name,make_file):
cache_data = cache.get(name)
if cache_data is None:
file = make_file()
cache.set(name,file)
return file
else:
return cache_data
def make_input_answer():
input_answer = pd.read_csv("<file path>")
return input_answer
def make_answer_emb_matrix():
answer_emb_matrix = np.load("<file path>.npy")
return answer_emb_matrix
def make_question_category_map_answer():
with open("<file path>.json", 'r') as f: #key: question_category, value(list): answer_id
qcate_dict = json.load(f)
return qcate_dict
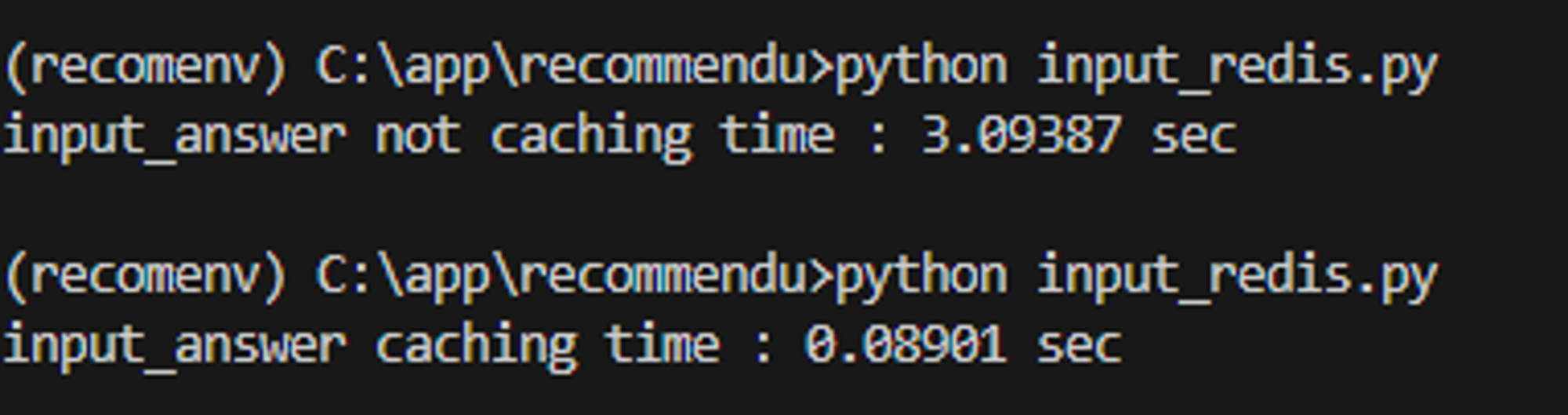
input_answer = get_make_cache('input_answer',make_file=make_input_answer)
answer_emb_matrix=time_test('answer_emb_matrix',make_answer_emb_matrix)
question_category_map_answer=time_test('question_category_map_answer',make_question_category_map_answer)어짜피 바이너리 형식으로 저장할 수 있기 때문에 이렇게 여러가지 파일 형식을 저장할 수 있다.
그리고 원래 이렇게 되어있는 코드를 아래의 형식으로 바꾸면 된다.
#views.py
from services.apps import ServicesConfig
@api_view(['POST', ])
def answer_recommend(request):
...
answers = ServicesConfig.input_answer.copy()
...
-----------------------------------------------------
#views.py
from django.core.cache import cache
@api_view(['POST', ])
def answer_recommend(request):
...
answers = cache.get('input_answer').copy()
...이런 방식으로 진행하면 빌드할 때 시간을 확실하게 단축시킬 수 있고 프로젝트 빌드시 메모리를 절약할 수 있다.
근데 문제는 만약에 캐싱되어있지 않은 상태라면 API의 성능이 급격하게 떨어지는 불상사가 발생한다.
2번 방식
일단 servicesconfig는 apps.py안에 클래스인데 여기 안에 코드를 짜면 프로젝트 빌드되기 전에 프로젝트에 필요한 것들을 저장하거나 실행할 수 있다.
#apps.py
class ServicesConfig(AppConfig):
default_auto_field = 'django.db.models.BigAutoField'
name = 'services'
input_answer = pd.read_csv("inference/data/input_answers_1_0_tmp.csv")
...
print("-----------------------------------ALL DATA LOADED-----------------------------------")뭐 이렇게 저장해놓고 views.py에는 이렇게 사용하면 된다.
#views.py
from services.apps import ServicesConfig
@api_view(['POST', ])
def answer_recommend(request):
...
answers = ServicesConfig.input_answer.copy()
...이야기가 다른 데로 샜는데 나는 아무튼 apps.py를 수정해볼거다. 1번 방식이랑 구현 방식은 동일하다.
#apps.py
def get_make_cache(name,make_file):
cache_data = cache.get(name)
if cache_data is None:
file = make_file()
cache.set(name,file)
return file
else:
return cache_data
def make_input_answer():
input_answer = pd.read_csv("<file path>")
return input_answer
class ServicesConfig(AppConfig):
default_auto_field = 'django.db.models.BigAutoField'
name = 'services'
input_answer = get_make_cache('input_answer',make_input_answer)
...
print("-----------------------------------ALL DATA LOADED-----------------------------------")이러면 처음 빌드할 때를 제외하고 파일도 필요하지 않을 뿐만 아니라
속도가 훨씬 빨라진 것을 확인할 수 있다.