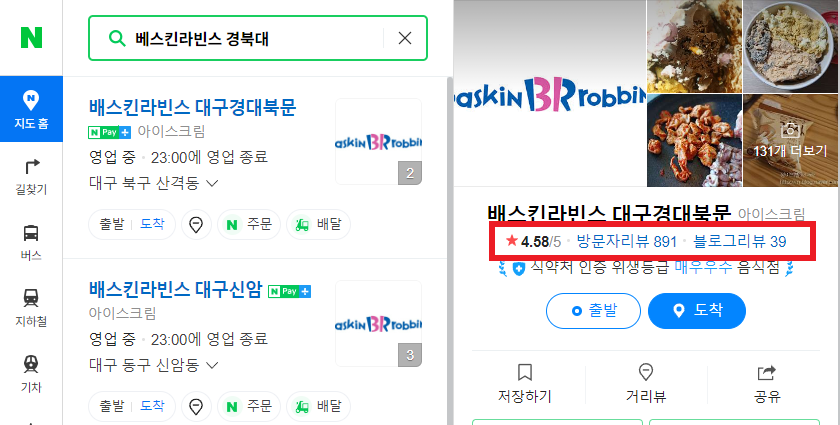
식당 별점,리뷰 들고오기
이전 포스팅에서 메뉴를 가져왔으니 이번에는 별점이랑 리뷰를 가져와보기로 했다. 애초에 어플리케이션에 리뷰와 별점순으로 식당을 보여줘야했기 때문에 어플 사용자들이 등록하는 리뷰 이외에도 이미 존재하는 리뷰를 가져와야했다.
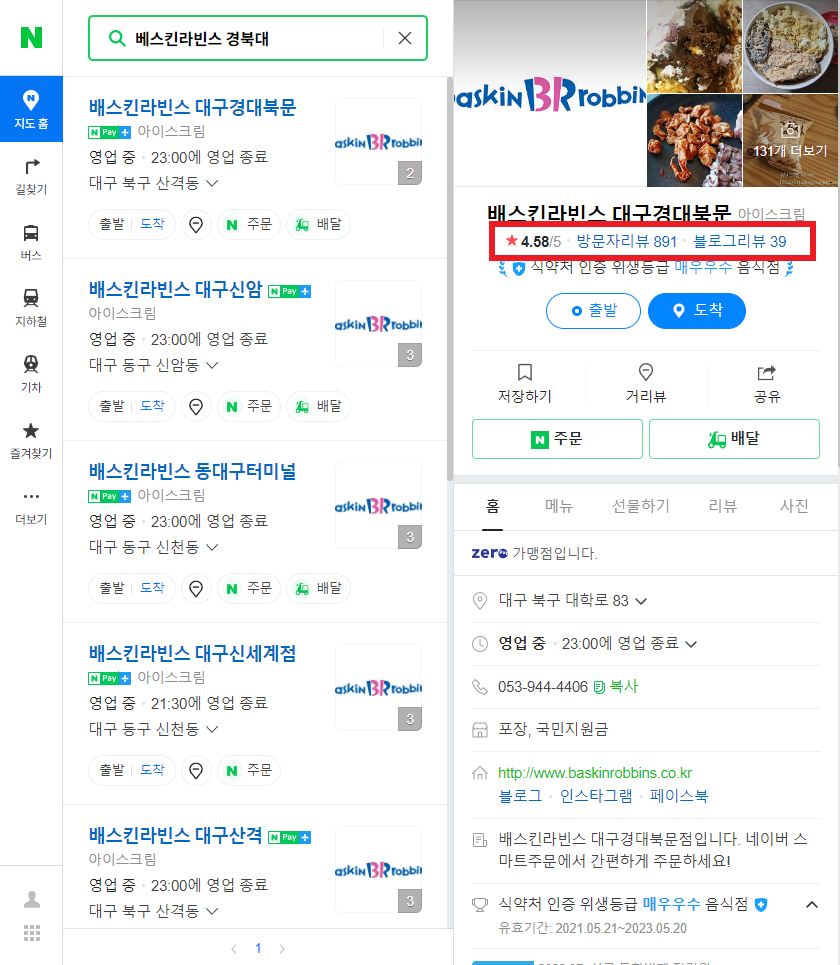
이 빨간색 박스 안에 있는 내용을 가져와야 했기 때문에 마찬가지고 selenium으로 tag를 찾아서 데이터를 가져오기로 했다.
iframe내에서 데이터 크롤링하기
역시 식당 상세정보를 담아놓은 창에 크롤링을 했어야했기 때문에 iframe을 바꿔주고 크롤링을 진행해야했다.
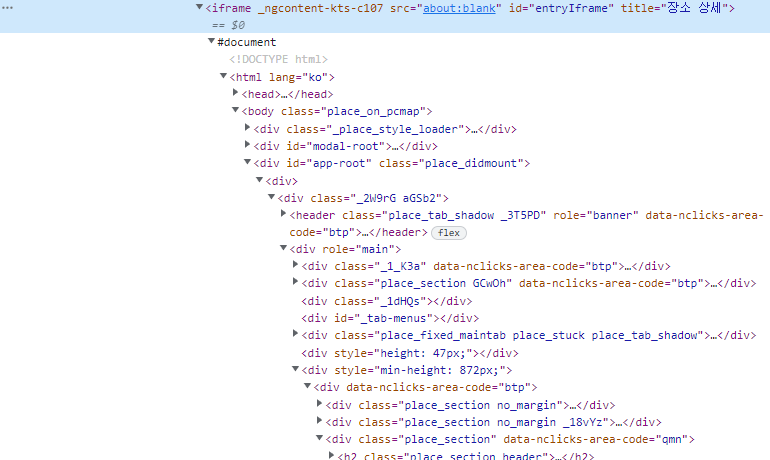
driver.switch_to.frame('entryIframe')frame을 바꿔줘야 크롤링을 할 수 있다.
Selector로 Tag 찾기
메뉴와는 다르게 class가 고정되어있어서 예외처리를 따로 해줄 필요없이 바로 selector로 tag를 찾을 수 있었다.
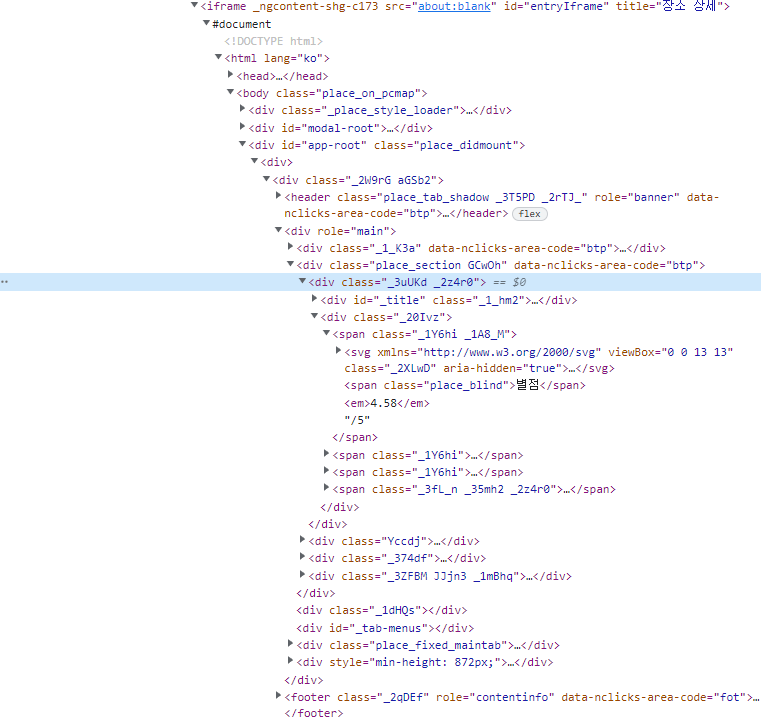
review = driver.find_element_by_css_selector('#app-root > div > div > div > div.place_section.GCwOh > div._3uUKd._2z4r0 > div._20Ivz')대신에 class안에 있는 text데이터들이 식당마다 다르게 되어있었기 때문에 그거를 parsing해주는 작업을 해야했다. 예를 들면, 별점이 있는 식당이 있는 반면에 리뷰만 있는 식당이 있는거 처럼 모든 식당이 위에 사진처럼 별점 - 방문자리뷰 - 블로그리뷰 모두 있는 것은 아니기 때문에 경우에 따라서 다르게 처리를 해줘야했다.
data parsing하기
일단 class안에 있는 span tag를 모두 가져온 다음 배열을 생성해서 tag안에 있는 text를 모두 담았다. 배열안에 담은 이유는 각 식당별로 규칙성을 찾아서 한번에 처리해주기 위함이다.
review_text = review.find_elements_by_tag_name('span')
for i in review_text:
out.append(i.text) # parsing하기 쉽게 배열에 넣어놓음그리고 별점이 있는 경우와 없는 경우, 그 안에 방문자리뷰 또는 블로그 리뷰만 있는 경우에 따라서 배열의 길이가 다를 것이기 때문에 배열의 길이를 기준으로 case를 처리해주었다.
rank_report = 0.0
review_report = 0
if len(out) == 0: # 리뷰가 아예 존재하지 않는 경우
pass
else:
if '별점' in out[0]: # 별점이 존재하는 경우
rank_report = float(out[0].split('\n')[1].split('/')[0]) # 별점을 실수형으로 바꿔서 담아둔다
if len(out) >3 and '리뷰' in out[3]: # 리뷰가 방문자리뷰, 사용자리뷰 2개가 있는데 방문자, 사용자리뷰가 둘다 있는 경우
out[2] = out[2].split(' ')[1].replace(',','') # [방문자리뷰,200] 이런 형태로 있는 데이터를 200만 가져오도록 parsing
out[3] = out[3].split(' ')[1].replace(',','') # [블로그리뷰,50] 형태의 데이터를 50만 가져오도록 parsing
review_report = int(out[2]) + int(out[3]) # 두 리뷰를 더해준다.
else:
out[2] = out[2].split(' ')[1].replace(',','') # 방문자리뷰만 있는 경우
review_report = int(out[2])
else: # 별점이 존재하지 않는 경우
if len(out) < 2: # 방문자리뷰만 있는 경우 또는 블로그리뷰만 있는 경우
out[0] = out[0].split(' ')[1].replace(',','')
review_report = int(out[0])
else: # 방문자리뷰, 블로그리뷰 둘다 있는 경우
out[0] = out[0].split(' ')[1].replace(',','')
out[1] = out[1].split(' ')[1].replace(',','')
review_report = int(out[0]) + int(out[1]) # 리뷰 더해준다
output = (rank_report,review_report) # 별점이랑 리뷰개수 담아서 return 해준다메뉴때는 계속 class가 바뀌어서 거기에 맞게 크롤링하는것이 힘들어서 고생을 했는데, 리뷰를 크롤링할 때는 class가 고정되어있어서 훨씬 크롤링하기 편했다.
전체코드
driver = webdriver.Chrome("C:/Program Files/chromedriver/chromedriver")
def rank(data):
out = []
driver.get("https://map.naver.com/v5/search/"+data) # 검색창에 가게이름 입력
time.sleep(3)
driver.implicitly_wait(3)
driver.switch_to.frame('searchIframe') # 검색하고나서 가게정보창이 바로 안뜨는 경우 고려해서 무조건 맨위에 가게 링크 클릭하게 설정
driver.implicitly_wait(3)
temp = driver.find_element_by_xpath('//*[@id="_pcmap_list_scroll_container"]/ul') # 메뉴표에 있는 텍스트 모두 들고옴(개발자 도구에서 그때그때 xpath 복사해서 들고오는게 좋다)
driver.implicitly_wait(20)
button = temp.find_elements_by_tag_name('a')
driver.implicitly_wait(20)
if '이미지수' in button[0].text or button[0].text == '': # 가게 정보에 사진이 있는 경우
button[1].send_keys(Keys.ENTER)
else: # 사진이 없는 경우
button[0].send_keys(Keys.ENTER)
driver.implicitly_wait(3)
time.sleep(3)
driver.switch_to.default_content()
driver.switch_to.frame('entryIframe')
driver.implicitly_wait(2)
review = driver.find_element_by_css_selector('#app-root > div > div > div > div.place_section.GCwOh > div._3uUKd._2z4r0 > div._20Ivz')
# xpath는 가게마다 다르게 설정되어 있었기 때문에 css selector를 이용해서 review text가 있는 tag에 접근
review_text = review.find_elements_by_tag_name('span') #span태그 안에서 별 규칙성을 찾지 못해서 span태그안에 별점, 리뷰 텍스트 정보가 들어가 있기 때문에 span에 있는거 모두 들고오기로 했음.
for i in review_text:
out.append(i.text) # parsing하기 쉽게 배열에 넣어놓음
rank_report = 0.0
review_report = 0
if len(out) == 0:
pass
else:
if '별점' in out[0]: # 별점이 존재하는 경우
rank_report = float(out[0].split('\n')[1].split('/')[0]) # 별점을 실수형으로 바꿔서 담아둔다
if len(out) >3 and '리뷰' in out[3]: # 리뷰가 방문자리뷰, 사용자리뷰 2개가 있는데 방문자, 블로그리뷰가 둘다 있는 경우
out[2] = out[2].split(' ')[1].replace(',','') # [방문자리뷰,200] 이런 형태로 있는 데이터를 200만 가져오도록 parsing
out[3] = out[3].split(' ')[1].replace(',','') # [블로그리뷰,50] 형태의 데이터를 50만 가져오도록 parsing
review_report = int(out[2]) + int(out[3]) # 두 리뷰를 더해준다.
else:
out[2] = out[2].split(' ')[1].replace(',','') # 방문자리뷰만 있는 경우
review_report = int(out[2])
else: # 별점이 존재하지 않는 경우
if len(out) < 2: # 방문자리뷰만 있는 경우 또는 블로그리뷰만 있는 경우
out[0] = out[0].split(' ')[1].replace(',','')
review_report = int(out[0])
else: # 방문자리뷰, 블로그리뷰 둘다 있는 경우
out[0] = out[0].split(' ')[1].replace(',','')
out[1] = out[1].split(' ')[1].replace(',','')
review_report = int(out[0]) + int(out[1]) # 리뷰 더해준다
output = (rank_report,review_report) # 별점이랑 리뷰개수 담아서 return 해준다
return output
감사합니다. 코드 잘 봤어요!!!