CPU 스케줄링 2
저번 시간 배웠던 것처럼 CPU스케줄링이란 프로세스들의 라이프사이클(상태)을 관리하는 것입니다. 이번 시간엔 저번 시간에 배웠던 내용을 바탕으로 CPU 스케줄링에 어떤 알고리즘이 존재하는지 살펴보겠습니다.
비선점형 알고리즘
비선점형이란 어떤 프로세스가 CPU를 사용하고 있는 경우, 다른 프로세스가 CPU를 빼앗아서 점유할 수 없는 것을 의미합니다.
이러한 비선점형 알고리즘에 어떤 스케줄링 방식이 있는지 살펴보겠습니다.
FCFS (Fisrt Come First Served)
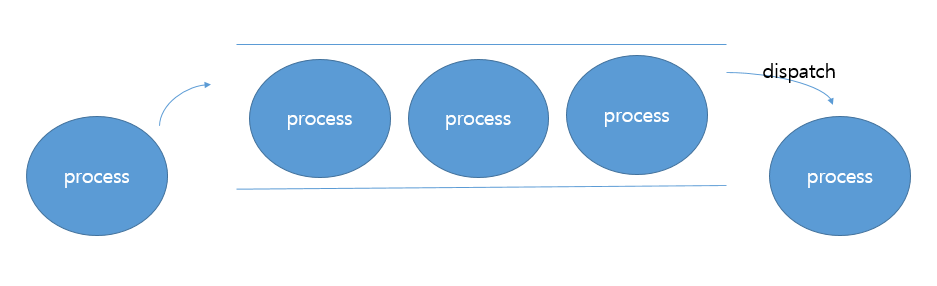 처음 살펴볼 스케줄링 알고리즘은 FCFS입니다. 말 그대로 프로세스가 도착하는 순서대로 큐에 넣고, 순서대로 CPU를 할당해주는 방식이죠. 그림에서 dispatch가 일어나면 해당 프로세스는 CPU를 할당받아 작업을 진행하게 됩니다.
처음 살펴볼 스케줄링 알고리즘은 FCFS입니다. 말 그대로 프로세스가 도착하는 순서대로 큐에 넣고, 순서대로 CPU를 할당해주는 방식이죠. 그림에서 dispatch가 일어나면 해당 프로세스는 CPU를 할당받아 작업을 진행하게 됩니다.
 그림으로 보면 저런 상태가 되겠습니다. 저번 시간에 살펴봤던 ready상태에 저렇게 큐가 존재하고 프로세스들이 대기하고 있는 상태라고 생각하시면 되겠습니다. 순서대로 dispatch되면 해당하는 프로세스가 CPU를 할당받고, running상태가 되겠죠.
그림으로 보면 저런 상태가 되겠습니다. 저번 시간에 살펴봤던 ready상태에 저렇게 큐가 존재하고 프로세스들이 대기하고 있는 상태라고 생각하시면 되겠습니다. 순서대로 dispatch되면 해당하는 프로세스가 CPU를 할당받고, running상태가 되겠죠.
이 방식은 단순하지만 convoy effect가 발생한다는 단점이 있습니다.
convoy effect란 실행 시간이 긴 프로세스가 짧은 프로세스보다 앞에 있으면 기다리는 시간이 길어져 효율성이 떨어지는 효과입니다.
또 비선점형 알고리즘 모두의 특징이지만, 한 번에 하나의 프로세스만 처리하기 때문에 시분할을 이용하여 한 번에 여러개의 프로세스가 동작하는 현대의 운영체제에는 맞지 않는 방법이겠죠.
SJF (Shortest Job Fisrt)
이 알고리즘도 간단합니다.
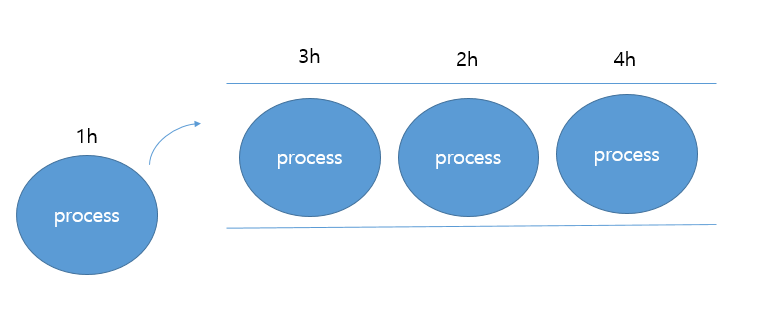 대기큐에 다음과 같이 프로세스들이 있다고 가정합시다. 이 때 프로세스가 걸리는 시간이 각각 3h, 2h, 4h였고 1h가 걸리는 프로세스가 대기큐에 들어온 상황입니다.
대기큐에 다음과 같이 프로세스들이 있다고 가정합시다. 이 때 프로세스가 걸리는 시간이 각각 3h, 2h, 4h였고 1h가 걸리는 프로세스가 대기큐에 들어온 상황입니다.
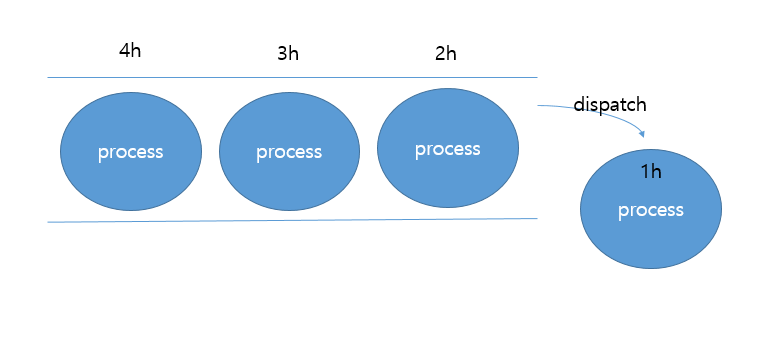 SJF는 대기큐에 프로세스가 추가될 때 마다 실행시간을 기준으로 짧은 아이가 앞에 오도록 정렬해주는 알고리즘입니다. 따라서 가장 빨리 실행이 끝나는 프로세스부터 CPU를 사용할 수 있어 효율성이 높아지고 convoy effect가 사라지는 장점을 갖고 있습니다.
SJF는 대기큐에 프로세스가 추가될 때 마다 실행시간을 기준으로 짧은 아이가 앞에 오도록 정렬해주는 알고리즘입니다. 따라서 가장 빨리 실행이 끝나는 프로세스부터 CPU를 사용할 수 있어 효율성이 높아지고 convoy effect가 사라지는 장점을 갖고 있습니다.
하지만 SJF는 너무 큰 단점을 가지고 있습니다. 먼저 starvation(기아현상)이 발생합니다.
위의 그림에서 보듯 2h, 3h, 4h짜리 프로세스가 먼저 대기하고 있었지만, 더 빨리 작업이 끝나는 프로세스가 들어오자 그 프로세스가 실행되고 여전히 대기하는 상황이 발생했죠.
이렇게 아무리 대기를 해도 짧은 프로세스가 계속해서 들어오게 되면, 실행 시간이 긴 프로세스는 절대 CPU를 할당받을 수 없어 작업을 진행할 수 없게 됩니다. 이런 현상이 바로 기아현상입니다. SJF의 가장 큰 단점이라고 할 수 있습니다.
두 번째 단점은 바로 프로세스의 실행 시간을 예측하는것이 현실적으로 어렵다는 것입니다. 우리가 사용하는 카카오톡, 캡처도구, 크롬 등의 프로세스는 사람마다 환경마다 실행되는 시간이 천차만별입니다. 즉, 프로세스의 실행 시간을 고려한다는 개념 자체가 현실성이 높지 않다는 것이죠.
세 번째 단점은 프로세스의 시간을 기준으로 계속해서 정렬을 해야 한다는 것입니다. 시간을 안다고 하더라도 이 시간을 기준으로 계속해서 정렬을 해야 하기 때문에 자원의 낭비가 발생합니다.
단점이 정말 많죠? 그래서 안쓴답니다..
HRN (Highest Response Ratio Next)
HRN은 CPU 사용 시간과 기다린 시간을 고려하여 스케줄링 우선순위를 정하는 방법입니다. 우선순위를 구하는 공식은 다음과 같습니다.
- 우선순위 = (대기시간 + CPU사용 시간) / CPU 사용 시간
위 수식에서 분자의 대기시간이 들어가 있는 것이 보이시나요? 대기시간이 분자에 있기 때문에 큐에서 대기한 시간이 긴 프로세스는 우선순위가 높아지게 됩니다. 따라서 SJF에서 CPU 사용 시간이 긴 프로세스들이 실행되지 못하는 starvation(기아현상)이 해결되는 것이죠.
이렇게 대기시간이 길수록 우선순위가 높아지게 만들어주는 기법을 에이징(ageing)이라고 합니다.
쉽게 말하면 HRN은 SJF에 에이징이 들어간 알고리즘입니다.
그러나 SJF와 마찬가지로 공정상이 위반되고 사용하기 어렵기에 잘 사용되지 않습니다.
선점형 알고리즘
지금까지 살펴본 알고리즘은 비선점형 알고리즘 입니다. 어떤 프로세스가 CPU를 점유하면 사용을 마칠때까지 CPU를 빼앗을 수 없는 알고리즘이죠.
그러나 이제부턴 다릅니다. 선점형 알고리즘은 프로세스가 CPU를 사용하는 도중에도 스케줄러가 CPU를 빼앗아 다른 프로세스에게 넘겨줄 수 있습니다. 이러한 방식은 시분할 방식을 이용하는 현대 운영체제에 알맞은 방법이라고 할 수 있습니다. 그럼 이제 선점형 알고리즘에는 어떠한 알고리즘들이 있는지 차근차근 살펴보겠습니다.
Round Robin
라운드 로빈은 간단합니다. 여러가지 프로세스를 순서대로 돌려가면서 CPU를 사용하게 만드는 방식이죠. 선점형 알고리즘에 익숙해질겸 그림을 통해 자세히 살펴보겠습니다.
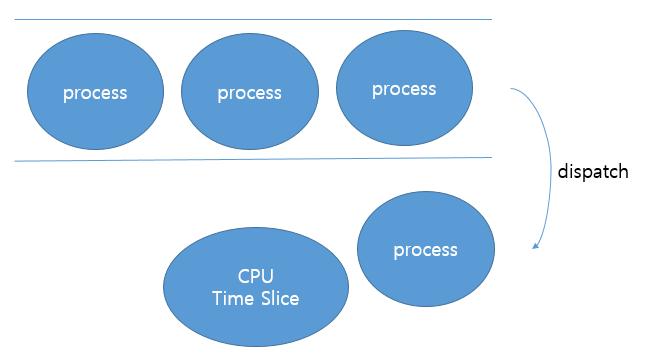 레디큐에서 맨 앞에 있는 프로세스가 먼저 dispatch되어 CPU 사용 권한을 얻습니다.
레디큐에서 맨 앞에 있는 프로세스가 먼저 dispatch되어 CPU 사용 권한을 얻습니다.
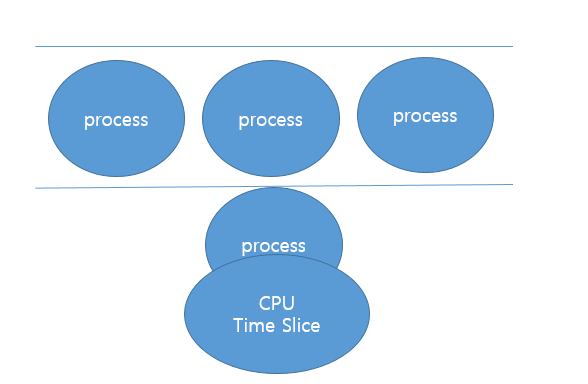 이 때 프로세스는 비선점형 알고리즘처럼 CPU를 계속 사용하는 것이 아니라, 일정 시간 동안만 CPU를 사용하게 됩니다.
이 때 프로세스는 비선점형 알고리즘처럼 CPU를 계속 사용하는 것이 아니라, 일정 시간 동안만 CPU를 사용하게 됩니다.
이렇게 짧은 시간동안 CPU를 사용하도록 하는 방식을 시분할 방식이라고 부릅니다. 그리고 CPU를 사용하는 짧은 시간을 Time Slice라고 부르죠.
즉, 프로세스는 Time Slice만큼의 짧은 시간동안 CPU를 사용하게 됩니다.
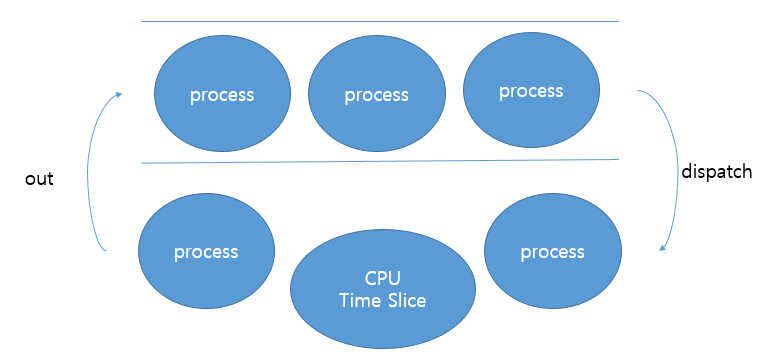 Time Slice만큼 사용하면 프로세스는 CPU를 잃고 레디큐로 돌아가게 됩니다. 그동안 스케줄러는 다른 프로세스를 dispatch하여 CPU를 넘겨줍니다.
Time Slice만큼 사용하면 프로세스는 CPU를 잃고 레디큐로 돌아가게 됩니다. 그동안 스케줄러는 다른 프로세스를 dispatch하여 CPU를 넘겨줍니다.
이런 식으로 프로세스를 계속 둥글게 돌리는 방식을 Round Robin방식이라고 합니다.
우리가 처음 배운 FCFS의 선점형 버전이라고 생각하셔도 좋습니다.
중요한것은 이 알고리즘부터 Time Slice라는 개념이 등장했다는 것입니다. 현대 운영체제는 이렇게 짧은 시간동안 프로세스를 동작시키는 과정을 통해 여러 프로세스를 동시에 동작하는 것 처럼 보이게 해줍니다. 따라서 우리는 컴퓨터로 한 번에 여러가지 작업을 동시에 진행할 수 있는 것이죠.
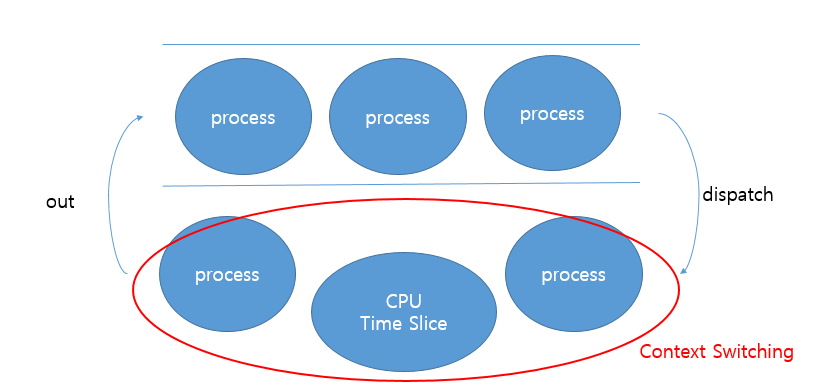 이런 방법에는 Context Switching이라고 하는 개념이 따라다닙니다. 쉽게 말하면 원래 CPU를 사용하는 프로세스에서 다른 프로세스로 CPU를 넘겨주는 과정을 의미하는데요. 이러한 과정에 CPU의 register값을 갱신해주는 등의 비용이 소모되기에 올바른 알고리즘을 잘 사용해야 합니다.
이런 방법에는 Context Switching이라고 하는 개념이 따라다닙니다. 쉽게 말하면 원래 CPU를 사용하는 프로세스에서 다른 프로세스로 CPU를 넘겨주는 과정을 의미하는데요. 이러한 과정에 CPU의 register값을 갱신해주는 등의 비용이 소모되기에 올바른 알고리즘을 잘 사용해야 합니다.
Round Robin방식은 FCFS에 Time Slice가 생긴 방식으로 자연스럽게 Convoy효과가 없어집니다. 하지만 Context Switching이 존재하기에 비슷한 성능의 비선점형 알고리즘보다 효율이 떨어지게 됩니다.(여기서 효율은 사람 기준이 아닌 컴퓨터 기준입니다)
Time Slice가 너무 큰 경우 Time Slice를 만든 의미가 없습니다. 만약 Time Slice를 무한대로 설정하면 비선점형 알고리즘과 다를바가 없죠. 그렇다고 TimeSlice를 너무 작게 설정하면 Context Switching이 너무 많이 일어나 이것만 하다가 시간을 다 보내게 됩니다.
즉, 선점형 알고리즘에선 Context Switching을 고려하며 최대한 작은 Time Slice를 설정하는 것이 중요합니다.
SRT(Shortest Remaining Time)
비선점형 SJF와 RR(Round Robin)스케줄링을 혼합한 선점형 스케줄링 방식입니다. 기본적인 RR베이스에 우선순위를 추가한 알고리즘이죠. 그러나 남은 시간을 주기적으로 계산해야하고 Context Switching도 발생하며 남은 시간을 계산하기 어렵고 아사현상도 발생할 수 있습니다. 즉, 사용하지 않습니다.
우선 순위 스케줄링
지금까지 나온 알고리즘들을 살펴보며 우선 순위라는 것에 중점을 맞출 필요가 있습니다. 우선 순위는 선점형, 비선점형에 모두 사용이 가능하고 기준을 어떻게 정하느냐에 따라 다양한 구현이 가능했습니다.
우선 순위 스케줄링 방식은 크게 2가지 형태를 가지고 있습니다.
- 고정 순위 알고리즘 - 우선 순위가 변하지 않는 방법입니다.
- 변동 순위 알고리즘 - 우선 순위가 변하는 알고리즘입니다.
이런 우선 순위 스케줄링을 잘못만들면 공평성을 위배하고, 아사 현상을 일으킬 수 있습니다. 또한 변동 순위 알고리즘의 경우 우선 순위를 변경하며 오버헤드가 발생할 수 있죠.
게다가 이런 알고리즘들은 때론 효율성보다 중요도를 기준으로 결정할 수 있어야 합니다. 가령 커널 프로세스는 어떤 일이 있어도 일반 프로세스보다 우선시 되어야 하죠. 지금부터 이런 우선 순위 스케줄링을 잘 고려한 멋진 알고리즘을 살펴보겠습니다.
다단계 큐 스케줄링
다단계 큐 스케줄링은 간단합니다. 프로세스가 CPU를 받기 전 ready상태에 머무르는 ready큐 기억나시나요?
 다단계 큐 스케줄링은 이러한 큐를 여러개 준비합니다. 즉, ready큐의 갯수가 여러 개가 되는 것이죠.
다단계 큐 스케줄링은 이러한 큐를 여러개 준비합니다. 즉, ready큐의 갯수가 여러 개가 되는 것이죠.
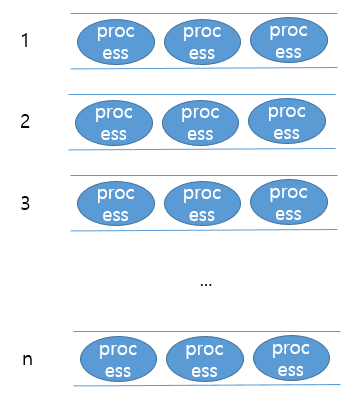 각각의 큐는 우선순위를 가지고 있습니다. 맨 위의 큐는 우선순위가 1로 제일 높고 아래로 내려갈수록 우선순위가 하나씩 낮아지는 것이죠.
각각의 큐는 우선순위를 가지고 있습니다. 맨 위의 큐는 우선순위가 1로 제일 높고 아래로 내려갈수록 우선순위가 하나씩 낮아지는 것이죠.
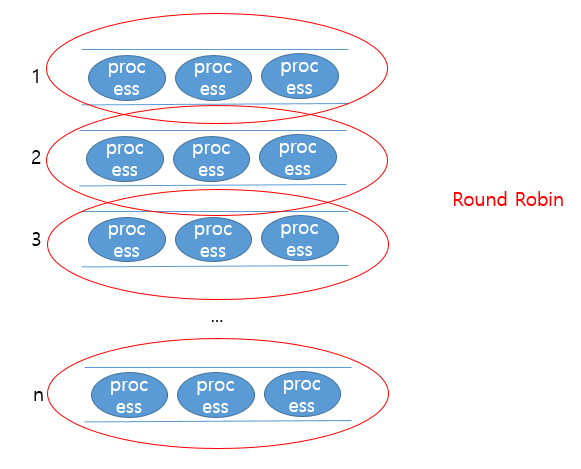 각각의 큐는 Round Robin방식으로 운영됩니다. 전체적으로는 1번 큐의 프로세스가 전부 완료되면 2번 큐의 프로세스가 CPU를 얻고, 2번 큐의 프로세스도 다 완료되면 3번 큐의 프로세스들이 동작하는 식으로 작동하게 됩니다.
각각의 큐는 Round Robin방식으로 운영됩니다. 전체적으로는 1번 큐의 프로세스가 전부 완료되면 2번 큐의 프로세스가 CPU를 얻고, 2번 큐의 프로세스도 다 완료되면 3번 큐의 프로세스들이 동작하는 식으로 작동하게 됩니다.
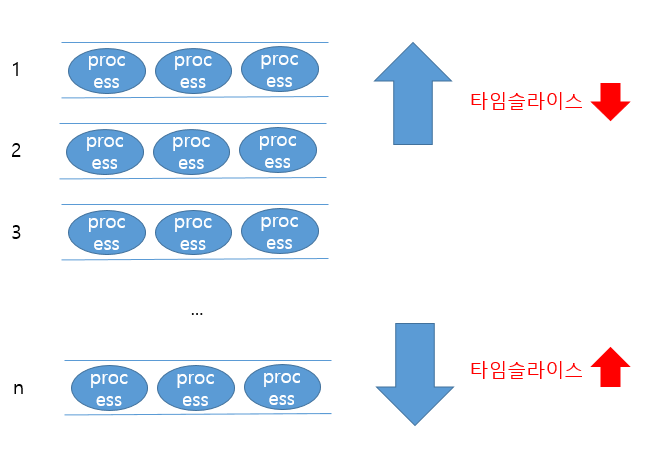 또한 각각의 큐는 Time Slice값이 각각 다릅니다. 우선 순위가 높은 큐는 Time Slice가 작고, 반면 우선 순위가 낮은 큐는 Time Slice가 높게 설정되죠.
또한 각각의 큐는 Time Slice값이 각각 다릅니다. 우선 순위가 높은 큐는 Time Slice가 작고, 반면 우선 순위가 낮은 큐는 Time Slice가 높게 설정되죠.
이러한 방식은 우선 순위가 높은 프로세스를 동시에 여러 개 처리할 수 있도록 도와줍니다.
또한 우선순위가 낮은 프로세스가 실행되는 경우는 우선순위가 높은 프로세스가 없는 경우 뿐이므로 낮은 프로세스는 CPU를 잡은김에 한번에 처리해버리기 위해 Time Slice를 높게 설정합니다. 이런식으로 각 큐의 설정을 다르게 하여 프로세스를 효과적으로 스케줄링 하는 방식이 다단계 큐 방식입니다.
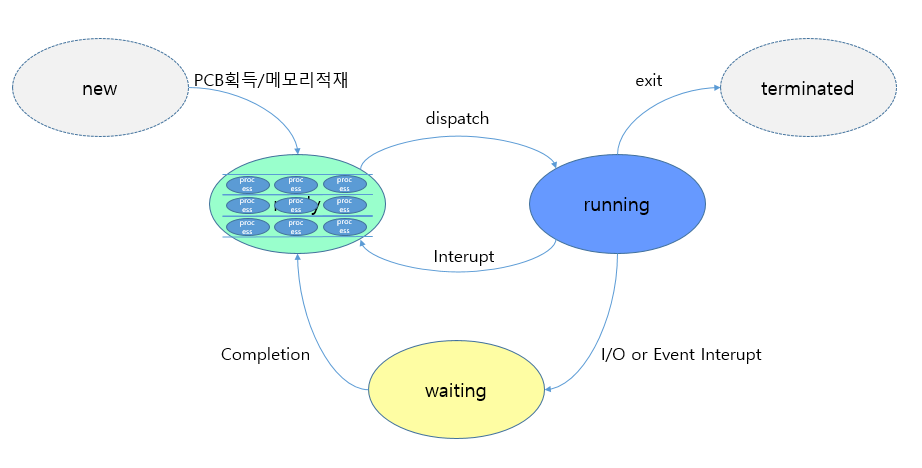 프로세스의 라이프 사이클에서 보면 이런 느낌입니다. ready큐가 여러 개 있는 것이죠.
프로세스의 라이프 사이클에서 보면 이런 느낌입니다. ready큐가 여러 개 있는 것이죠.
다단계 큐 스케줄링은 고정형 우선순위 방식입니다. 상단의 큐가 다 끝나야 다음 큐의 프로세스가 실행될 수 있죠. 또한 Time Slice로 효율성이 증가합니다. (맨 마지막 큐는 Time Slice가 무한으로 FCFS와 동일해집니다)
그러나 눈치가 빠른 분들은 다단계 큐의 단점을 눈치채실겁니다. 바로 다단계 큐는 아사현상이 발생할 수 있다는 것입니다.
우선순위가 높은 프로세스가 계속 들어오면 상대적으로 우선순위가 낮은 프로세스는 계속 실행되지 못한다는 것이죠.
이런 현상을 방지하기 위해 나온 알고리즘이 바로 다단계 피드백 큐 스케줄링 입니다.
다단계 피드백 큐 스케줄링
다단계 피드백 큐 스케줄링은 다단계 큐 스케줄링을 이해한다면 매우 간단히 이해할 수 있습니다. 우선 다단계 큐 상태를 생각해봅시다.
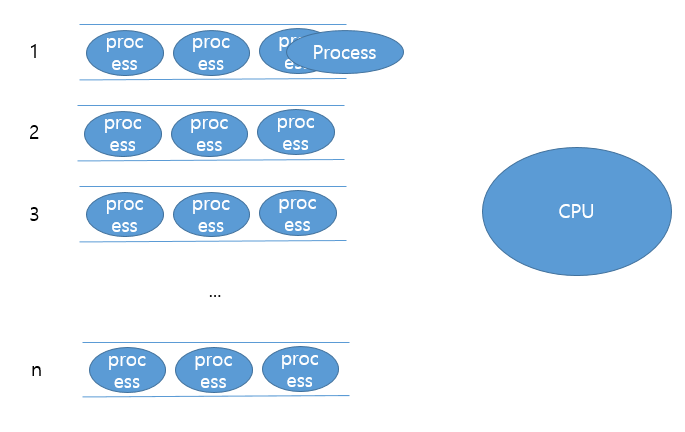 먼저 우선순위가 1인 큐의 프로세스가 dispatch됩니다.
먼저 우선순위가 1인 큐의 프로세스가 dispatch됩니다.
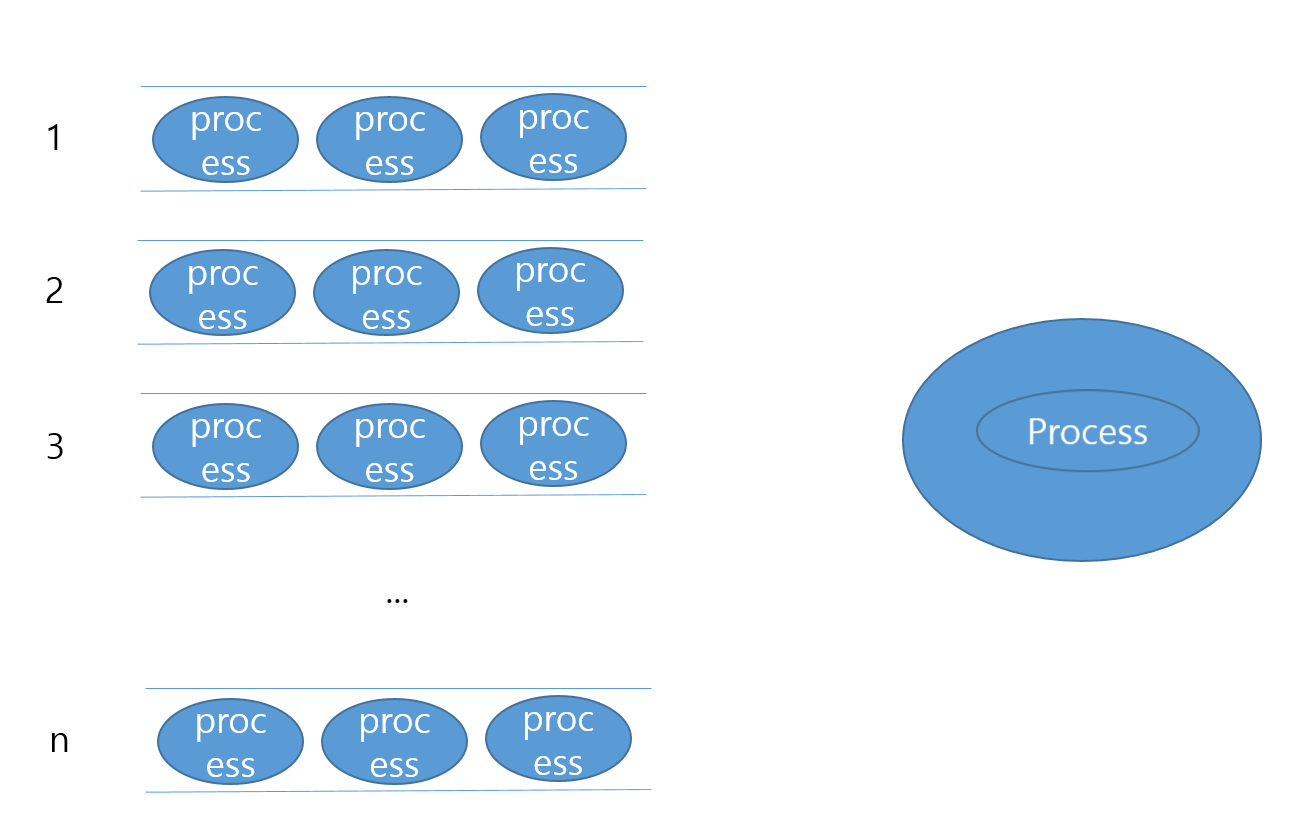 그럼 프로세스는 CPU를 할당 받아 Time Slice만큼 사용하게 될 겁니다.
그럼 프로세스는 CPU를 할당 받아 Time Slice만큼 사용하게 될 겁니다.
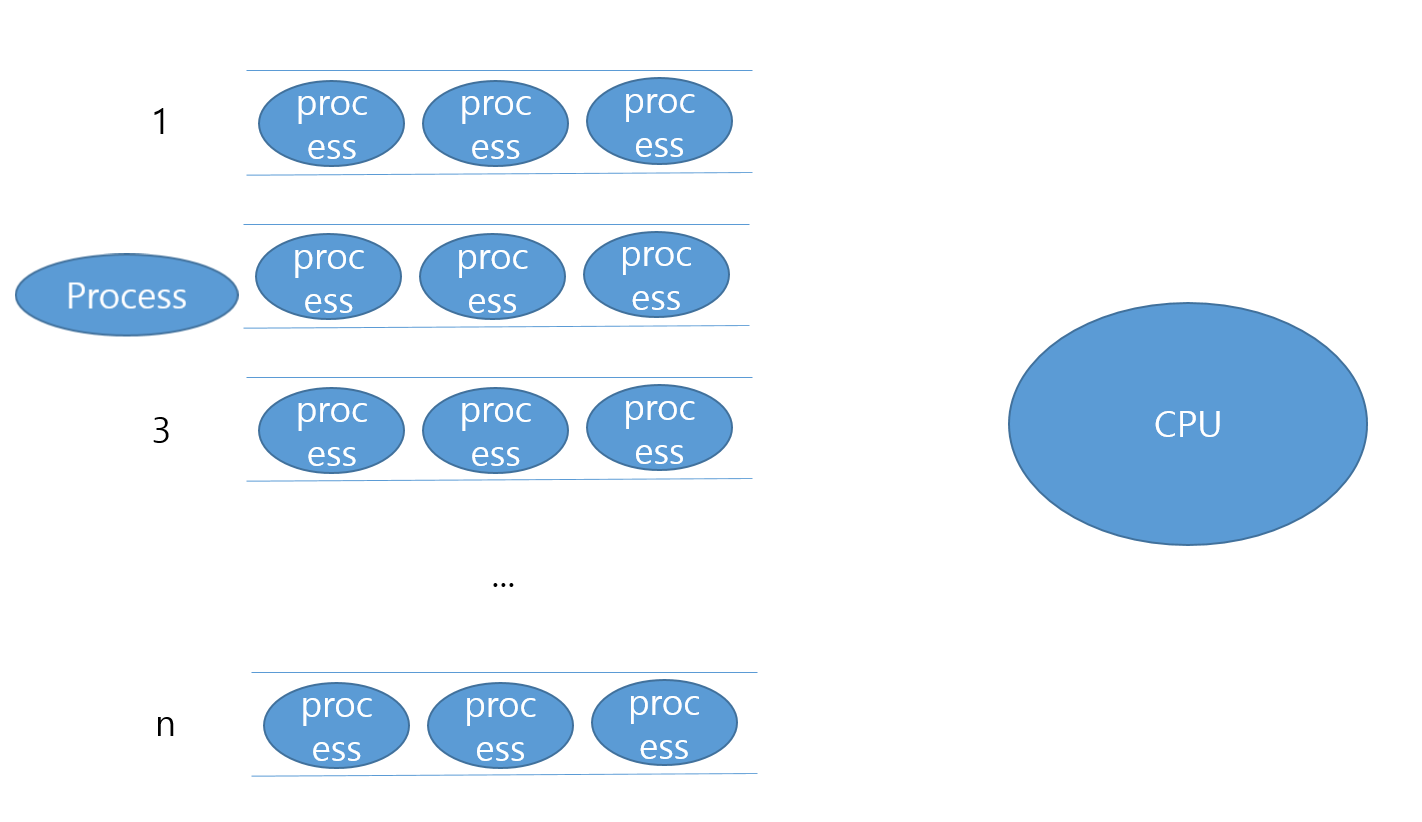 CPU의 사용을 마친 프로세스는 처음에 있던 1번큐가 아닌 한 단계 낮은 2번큐에 들어가게 됩니다.
CPU의 사용을 마친 프로세스는 처음에 있던 1번큐가 아닌 한 단계 낮은 2번큐에 들어가게 됩니다.
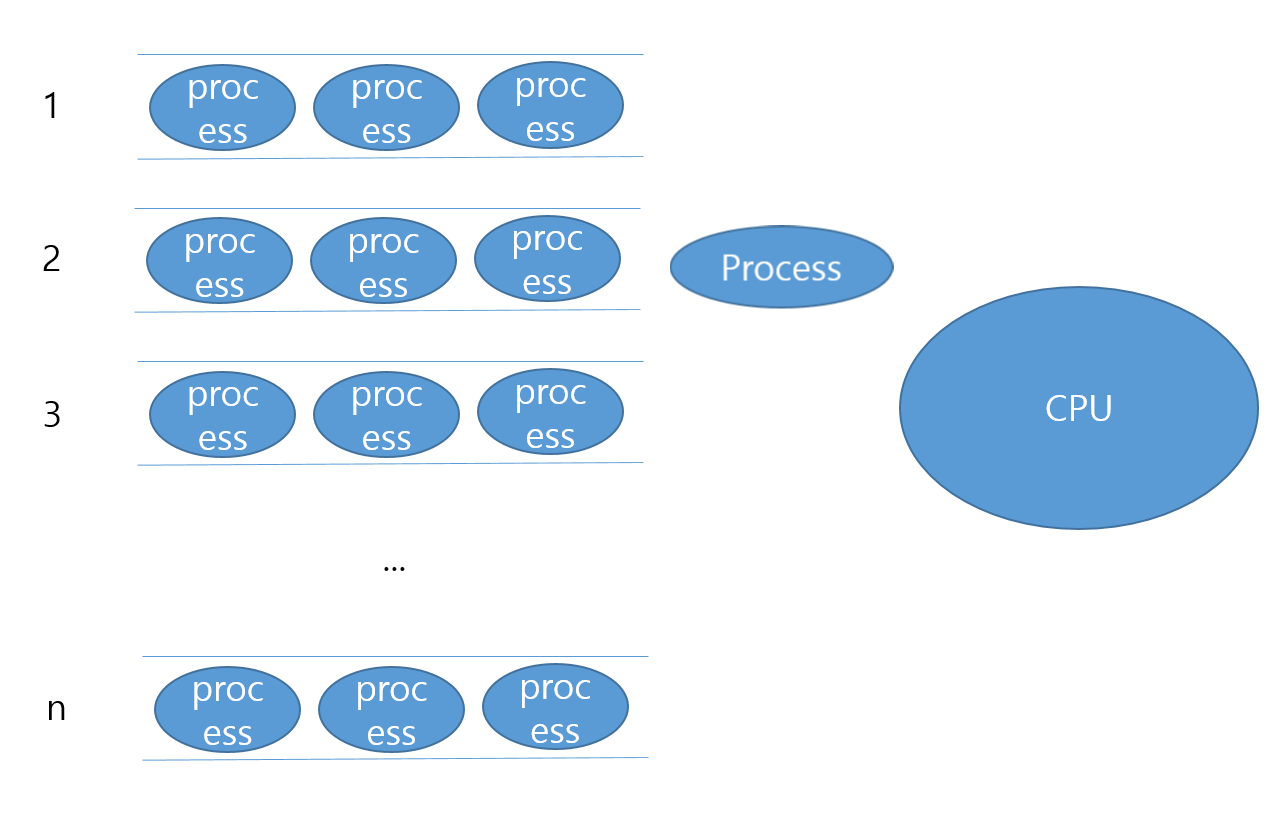 2번 큐의 프로세스도 마찬가지로 dispatch되면 CPU를 할당받아 Time Slice만큼 사용하겠죠.(1번 큐가 전부 끝났다고 가정합시다)
2번 큐의 프로세스도 마찬가지로 dispatch되면 CPU를 할당받아 Time Slice만큼 사용하겠죠.(1번 큐가 전부 끝났다고 가정합시다)
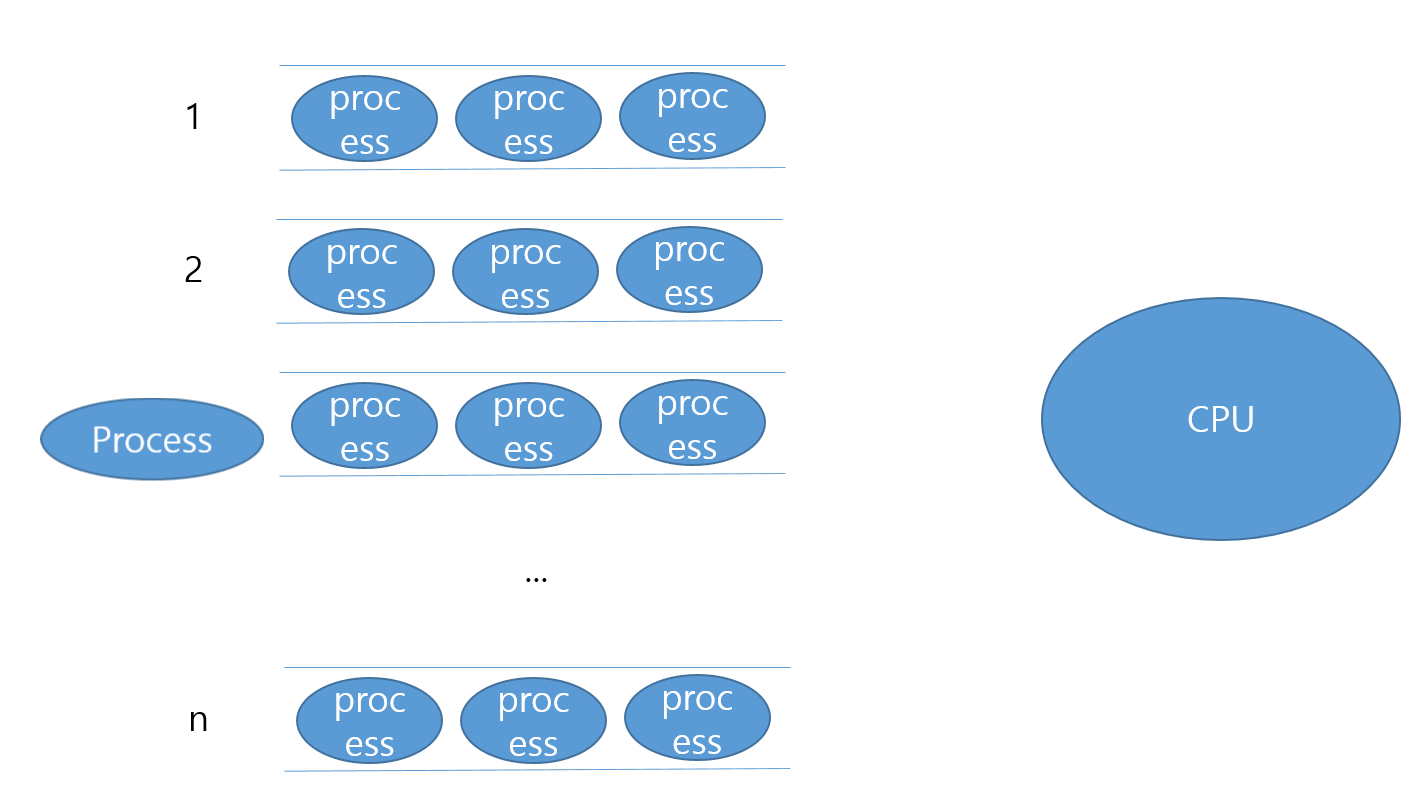 이번에도 CPU사용을 마친 뒤 프로세스는 한 단계 낮은 큐, 즉, 3번큐로 들어가게 됩니다.
이번에도 CPU사용을 마친 뒤 프로세스는 한 단계 낮은 큐, 즉, 3번큐로 들어가게 됩니다.
이런 식으로 프로세스들은 CPU를 사용할 때 마다 한 단계 낮은 큐로 들어가 대기하게 되는 것이죠.
이러한 방식은 1번 큐의 프로세스가 2번 큐의 프로세스를 계속 막지 못하게 하고, 2번 큐의 프로세스가 3번 큐의 프로세스를 계속 막지 못하게 합니다.
즉, CPU를 사용할 때 마다 인접한 큐 끼리 한 단계씩 우선순위가 낮아지므로 아사현상이 없어지는 것이죠.
정리해보겠습니다. 다단계 피드백 큐의 특징은 다음과 같습니다.
- 변동형 우선순위 방식입니다.
- 우선 순위가 낮은 프로세스에 불리한 다단계 큐 스케줄링을 보완하여 아사현상을 해결했습니다.
- 커널 프로세스와 일반 프로세스의 큐는 다릅니다. 아무리 우선순위가 낮아져도 커널 프로세스는 일반 프로세스보다 우선순위가 높기에 서로 섞이지 않습니다.
- 다단계 큐와 마찬가지로 우선 순위가 낮은 큐 마다 Time Slice값이 높아집니다. 어렵게 얻은 CPU를 오래 써서 한번에 해결하라는 것이죠.
이러한 다단계 피드백 큐 방식은 우선 순위 스케줄링을 잘 디자인한 대표적인 사례로 현대 운영체제에서 사용하는 스케줄링 방식의 근간이 되는 알고리즘입니다.
