1. Cache Memory
-
CPU와 메모리 속도 차이로 인한 병목 현상을 줄이기 위해 사용
- 병목 현상 ?
: 데이터의 집중적인 사용으로 인해, 전체 시스템에 영향을 미치는 부분의 사용 빈도가 늘어나 성능이 저하 되면서 전체 시스템이 마비되는 현상
- 병목 현상 ?
-
CPU가 메모리에 접근하는 횟수를 줄여 성능 향상
⇒ 자주 사용하는 데이터를 CPU와 가까운 cache memory에 저장 함으로써, 필요할 때 마다 꺼내 쓸 수 있음
-
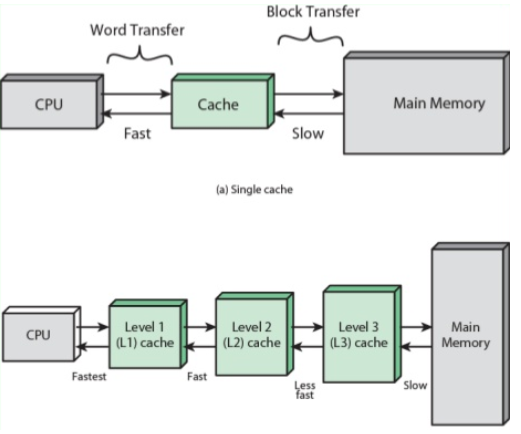
보통 CPU에 cache memory가 2~3개 사용 됨 (L1, L2, L3 캐시 메모리)
[ L1, L2, L3 cache memory ]
-
L1, L2, L3 순서대로 속도가 빠름
-
L1, L2, L3 순서대로 참조에 먼저 사용 됨
-
L1 : CPU 내부에 존재
-
L2 : CPU와 RAM 사이에 존재
-
L3 : 보통 메인보드에 존재
[ 듀얼 코어 프로세서의 cache memory ]
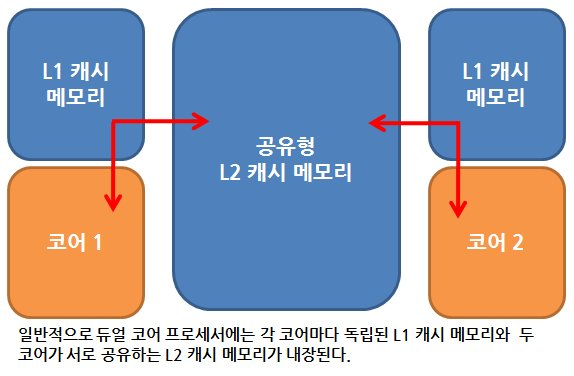
- 각 코어마다 독립된 L1 캐시 메모리를 가지고, 두 코어가 공유하는 L2 캐시 메모리가 내장 됨
- 만약 L1 캐시가 128kb면, 64/64로 나누어 64kb에 명령어를 처리하기 직전의 명령어를 임시 저장하고, 나머지는 64kb에는 실행 후 명령어를 임시 저장
2. Cache Hit, Miss
-
CPU가 기억장치의 데이터를 읽을 때, cache에 존재하는지 확인
1) cache에 데이터가 존재 (hit)
⇒ CPU는 cache에서 해당 데이터 읽음
2) cache에 존재 X (miss)
⇒ 주기억장치에서 데이터를 읽어서 사용 & cache에 적재시킴
[ Cache Hit, Cache Miss ]
-
Cache Hit
: cache에 필요한 데이터가 있는 경우
- Hit rate (적중률)
- 요청한 데이터를 cache 메모리에서 찾을 확률
- cache 메모리의 성능은 적중률에 의해 결정 됨
- Hit rate (적중률)
-
Cache Miss
: cache에 찾는 데이터가 없는 경우
- Miss rate (실패율)
3. Cache Memory 작동 원리 - Locality (지역성)
-
cache 메모리의 성공 여부는 참조의 지역성(Locality of reference)원리에 달려 있음
-
정보를 균일하게 액세스 하는 것이 아니라, 한 순간에 특정 부분을 집중적으로 참조하는 것
-
지역성의 종류
1) Temporal Locality (시간적 지역성)
: CPU가 한 번 참조한 데이터는 다시 참조 할 가능성이 높다
2) Spatial Locality (공간적 지역성)
: CPU가 참조한 데이터와 인접한 데이터는 참조 될 가능성이 높다
3) Sequential Locality (순차적 지역성)
: 분기가 발생하지 않는 한, 메모리에 저장된 순서대로 인출/실행된다
4. Cache의 구조
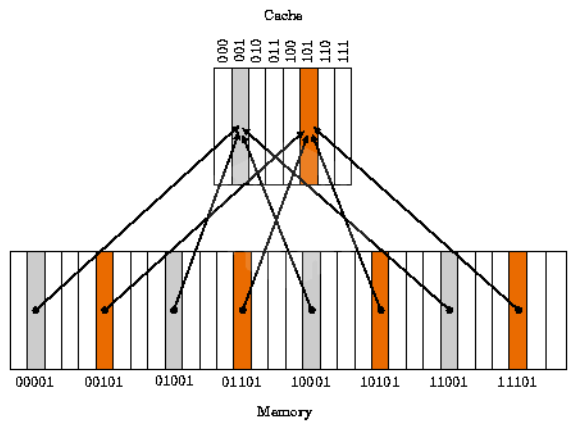
- DRAM의 여러 주소가 cache memory의 한 주소에 대응되는 다대일 방식
- 위의 그림은 메모리 공간이 32개 (00000~11111)이고, 캐시 메모리 공간은 8개 (000~111)
- EX
- 00000, 01000, 10000, 11000인 메모리 주소는 000 캐시 메모리 주소에 매핑
- 이때 뒤의 000이 인덱스 필드
- 인덱스를 제외한 앞의 나머지 (00, 01, 10, 11)가 태그 필드
- cache memory는 인덱스 필드 + 태그 필드 + 데이터 필드로 구성
- 위의 사진처럼 같은 색의 데이터를 동시에 사용 할 경우, Conflict Miss 발생
- Conflict Miss ?
- 캐시 메모리에 A와 B 데이터를 저장해야 하는데, A와 B가 같은 캐시 메모리 주소에 할당되어 있을 때 발생
- Conflict Miss ?
5. Cache Memory의 주소 저장 방식
1) Direct Mapping (직접 매핑)
-
메모리 주소, 캐시 순서를 일치 시킴
Ex) 메모리가 1~100까지 있고, 캐시가 1~10까지 있다면
1~10까지의 메모리는 캐시 1에 위치, 11~20까지의 메모리는 캐시 2의 위치
-
구현 간단
-
효율적 X
⇒ 캐시를 자주 교체 되는 상황 발생
-
적중률 낮음
2) Fully Associative Cache (연관 매핑)
- 비어있는 캐시 메모리가 있으면 마음대로 주소 저장 (순서 일치 X)
- 저장하는 방식은 간단
- 데이터 찾을때 복잡 ⇒ 시간 오래 걸림
- 규칙이 없어서 특정 캐시 Set안에 있는 모든 블럭을 찾아 원하는 데이터가 있는지 검사
- 적중률 높음 (필요한 캐시들 위주로 저장하므로)
3) Set Associative Cache (세트 연관 매핑)
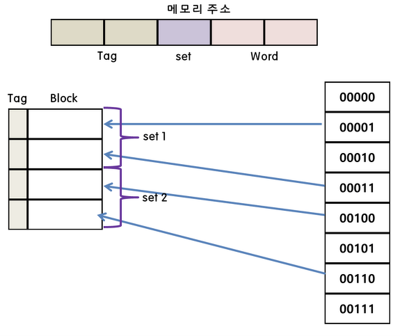
-
Direct + Fully 방식
⇒ 직접 매핑의 단순한 방법, 연관 매핑의 높은 적중률의 장점을 가짐
-
순서를 일치시키고 저장하되, 그룹(set)을 둬서 그 그룹내에 저장
Ex) 메모리가 1~100까지 있고, 캐시가 1~10까지 있다면
캐시 1~5에는 메모리 1~50의 데이터를 무작위로 저장
-
세트 번호를 통해 영역을 탐색하므로, 연관 매핑의 병렬 탐색을 줄일 수 있음
-
set안의 라인의 수에 따라 n-Way 연관 매핑이라고 함 (그림은 2-way 연관매핑)
