1. Index?
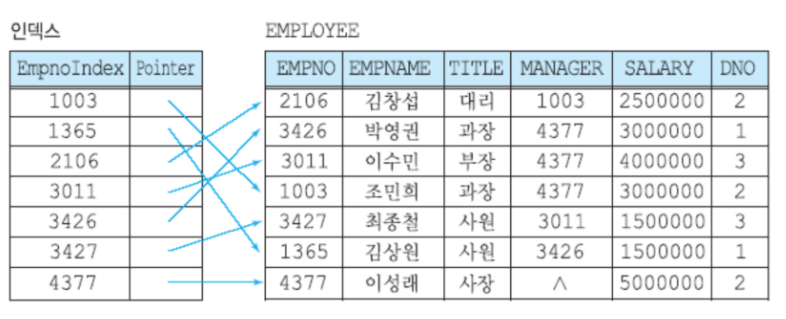
-
추가적인 쓰기 작업과 저장 공간을 활용 해 데이터 베이스 테이블의 검색 속도를 향상 시키기 위한 자료 구조
⇒ 책의 목차와 같다
-
key값으로 column 데이터의 위치를 식별하는데 사용
1) 목적
-
RDBMS에서 검색 속도를 높이기 위한 기술
- RDBMS (Relational Database Management System) ?
- 관계형 데이터 베이스를 생성, 수정, 관리 할 수 있는 소프트웨어
- 모든 데이터를 2차원 테이블 (row, column)로 표현
- 데이터 베이스 설계도를 ER (Entity Relationship) 모델이라고 함
- RDBMS (Relational Database Management System) ?
-
테이블의 column을 색인화 함 (따로 파일로 저장)
⇒ 해당 테이블의 record를 Full scan 하지 않고, Range scan (범위 스캔)
⇒ 색인화 된 (B+ Tree구조) index 파일 검색으로 검색 속도 향상
2) 과정
-
테이블을 생성하면 FRM ,MYD, MYI 3개의 파일 생성 됨
-
FRM : 테이블 구조가 저장 되어 있는 파일
-
MYD : 실제 데이터가 있는 파일
-
MYI : index 정보가 들어가 있는 파일
⇒ index를 사용하지 않는다면, MYI 파일은 비어져 있음
⇒ 이후에 사용자가 select 쿼리로 index를 사용 할 경우, MYI 파일 내용 검색
2. 장단점
1) 장점
- 테이블 조회 속도와 성능을 향상 시킬 수 있음
- 전반적인 시스템 부하를 줄일 수 있음
2) 단점
- index 생성시 .myi 파일 크기 증가
- 여러 사용자가 한 페이지를 동시에 수정 할 수 있는 병행성이 줄어 듬
- 인덱스 된 field에서 데이터를 업데이트 하거나, record를 추가, 삭제 할 경우 성능이 떨어짐
- 데이터 변경이 자주 일어나는 경우, index를 재작성 해야 하므로 성능에 영향 미침
- 인덱스가 데이터 베이스 공간을 차지 해, 추가적인 공간이 필요하다 (DB의 10% 내외 정도)
3. 상황 분석
1) 사용하면 좋은 경우
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 column
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 column
- 규모가 큰 테이블
- WHERE 절에서 자주 사용되는 column
2) 사용을 피해야 하는 경우
- 데이터 중복도가 높은 column
- DML이 자주 일어나는 column
- DML (Data Manipulation Language) ?
- 데이터 조작어
SELECT, INSERT, UPDATE, DELETE
- DML (Data Manipulation Language) ?
[ DML이 일어났을 때의 상황 ]
1) INSERT
1-1) 기존 block에 여유가 없을 때, 새로운 데이터가 입력 됨
-
index split 현상 발생
-
index split ?
: 인덱스의 block이 하나에서 두 개로 나눠지는 현상
-
1-2) 새로운 block을 할당 받은 후, key를 옮기는 작업 수행
⇒ 많은 양의 redo 발생
1-3) index split이 실행되는 동안, block에 대한 key값이 변경되면 안되므로 DML이 블로킹 됨
⇒ 대기 이벤트 발생
2) DELETE
-
테이블에서 데이터가 delete 되는 경우 : 데이터가 지워지고, 다른 데이터가 그 공간 사용 가능
-
index에서 데이터가 delete 되는 경우 : data가 지워지지 않고, 사용 안 됨 표시만 해 둠
⇒ table의 data 수와 index의 data 수가 다를 수 있음
⇒ 성능 저하 될 수 있음
3) UPDATE
-
table에서 update가 발생하면, index는 update 할 수 X
-
index에서 delete 한 후, 새로운 작업 insert
⇒ 2배의 작업이 소요되므로 힘들다
