ML
1.[ML] 지도 학습(1)- 회귀분석(1)

전체적 이해를 위해 통계적 개념과 머신러닝에서의 적용을 함께 다룸 📚 이론 회귀 입력된 데이터에 대해 연속된 값으로 예측 회귀분석의 다양한 유형 > 회귀는 독립변수의 개수에 따라 단순 선형 회귀, 다항 회귀로 먼저 나뉘어진다. 또한, 회귀 계수가 선형인지 아닌지에
2.[ML] 학습이란?

머신러닝을 공부하면 항상 '학습'이라는 개념을 마주칠 수 있는데, 이 학습의 개념과 종류에 대해 알아보고자 한다.머신러닝에서 '학습'이란, 데이터를 특정 알고리즘에 적용해 머신러닝 모델을 정의된 문제에 최적화하는 과정이다.머신러닝은 학습하려는 문제의 유형에 따라, 크게
3.[ML] 지도 학습 - 회귀분석(2)

📌 회귀분석의 다양한 유형 (2) 선형 회귀(Linear regression) 다중 회귀(Multivariate Regression) 다항 회귀(Polynomial regression) 로지스틱 회귀(Logistic regression) - 릿지회귀(Ridge reg
4.[ML] 지도학습- 의사결정나무
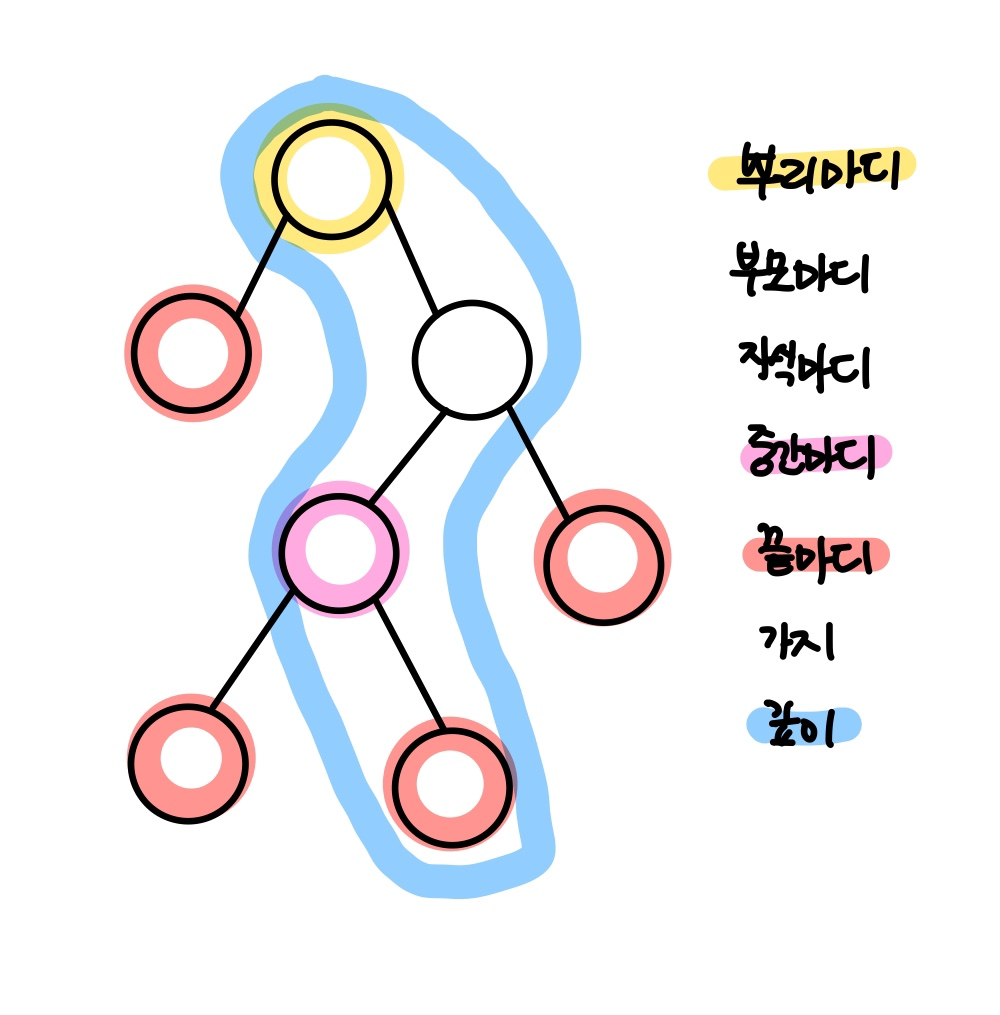
의사결정나무 (Decision Tree) > 의사결정나무는 주로 불연속 데이터를 다루며 노이즈가 발생해도 중단되거나 엉뚱한 결과를 보여주지 않는 매우 강건한 모델이다. 의사결정나무는 분류와 예측을 수행하는 분석 방법이다. 의사결정나무는 쉽게 말해 결정을 위해 스무고개
5.[ML] 앙상블 학습: 배깅, 부스팅, 랜덤포레스트
📍 앙상블 앙상블의 단어 뜻은 조화와 통일이다. 이 의미를 머신러닝에 대입한다면? 👉 하나의 모델 말고, 여러 개의 모델을 조화롭게 학습시켜 예측 결과들을 이용하면 더 정확한 예측 값을 구할 수 있을 것이란 아이디어다. 대표적인 앙상블 학습법은 배깅과 부스팅이
6.[ML] 지도학습 - 서포트 벡터 머신(SVM)

현재 이곳의 위치가 경남인가요? 경북인가요?라고 질문했을 때 남쪽이면 경남이라고 대답할 것이고, 북쪽이면 경북이라고 대답할 것이다. 이와 같이 내게 예측을 요구한 사람에게 이렇게 질문해서 위치를 예측하는 것! 여기서 경남인지, 경북인지 구분하는 것이 결정 경계선이라 하
7.[ML] 지도학습 - 나이브베이즈
📍 나이브베이즈 나이브베이즈 분류 알고리즘은 데이터를 단순(나이브)하게 독립적인 사건으로 가정하고, 이 독립 사건들을 베이즈 이론에 대입시켜 가장 높은 확률의 레이블로 분류를 실행하는 알고리즘이다. 나이브베이즈는 feature끼리 서로 독립이라는 조건이 필요하다. 예
8.[ML] 지도학습 - K-NN (K-최근접 이웃)
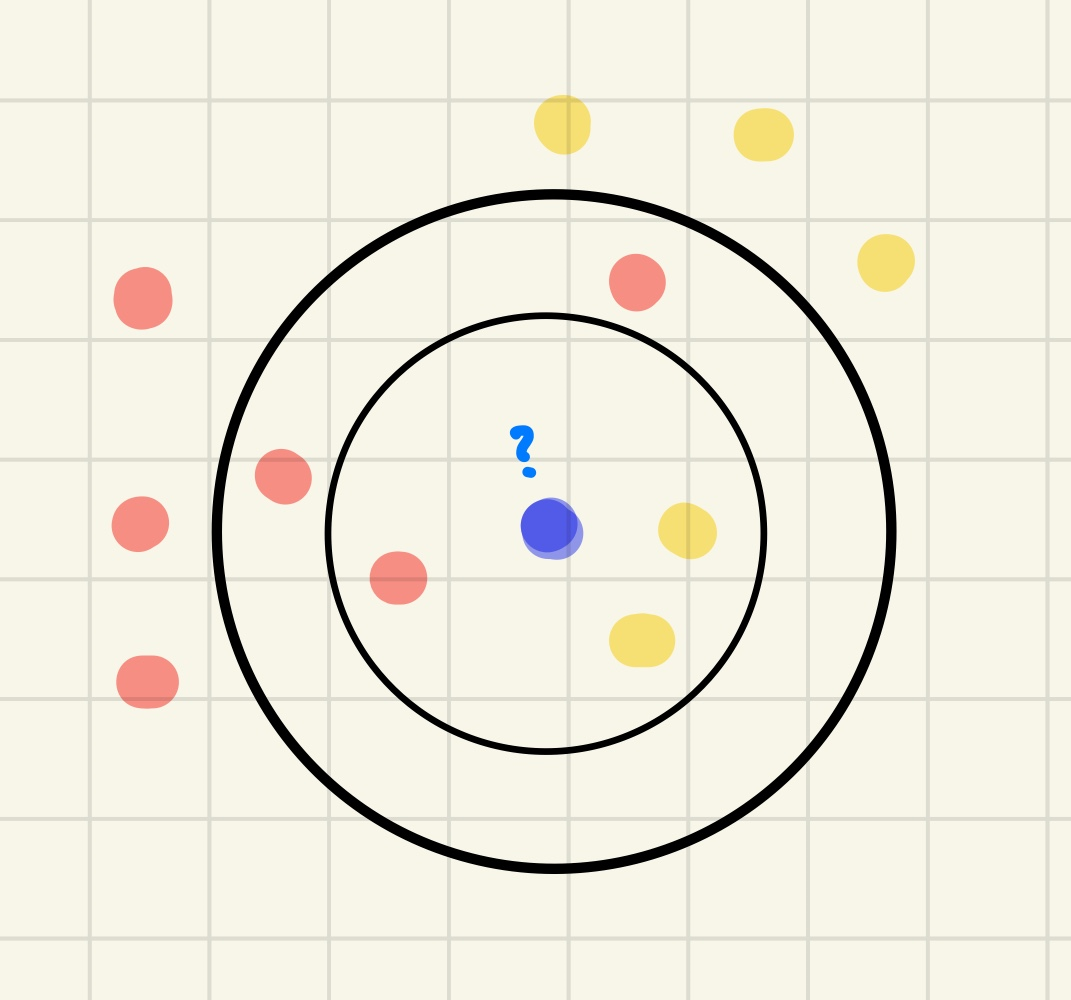
📍 K-NN (K-Nearest Neighbor) 거리기반의 분류 알고리즘으로, 주변의 가장 가까운 k개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘이다. ✔ 비지도 학습의 Clustering 역시 거리기반의 분류 알고리즘인데? k-nn은 clusterin
9.[ML] 비지도 학습 - 군집분석
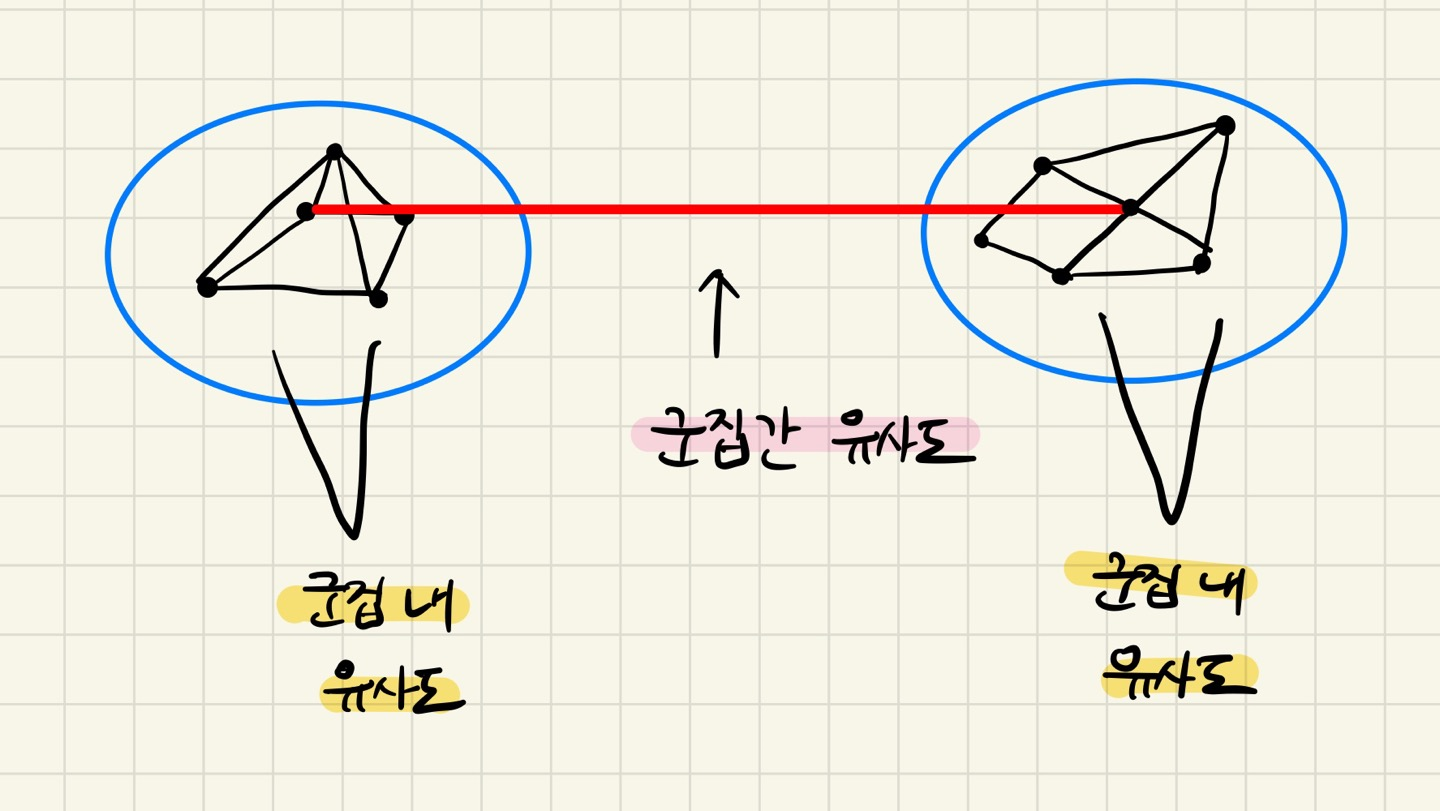
비지도 학습이란?레이블이 없는, 정답이 없는 데이터를 분류하는 것!비지도 학습의 종류?군집화, 차원 축소서로 유사한 정도에 따라 다수의 개체를 군집으로 나누는 것을 말한다. 한마디로, 유사도가 높은 데이터끼리 그룹화를 시키는것이라고 말할 수 있다.분할 기반 군집k-me
10.[ML] 비지도학습 - 연관 규칙 분석
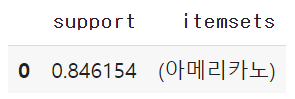
비지도 학습은 데이터에서 패턴을 찾고 분류하는 것을 목적으로 하며, 주어진 데이터에 대한 사전 지식 없이 스스로 학습을 수행한다. 📍 연관 규칙 분석이란? 연관규칙분석은 데이터의 아이템들 사이에서 발생하는 규칙을 찾아내는 것으로, 규칙이 발생하기 위해 어떤 아이템
11.[ML] 비지도학습 - 차원축소(2)
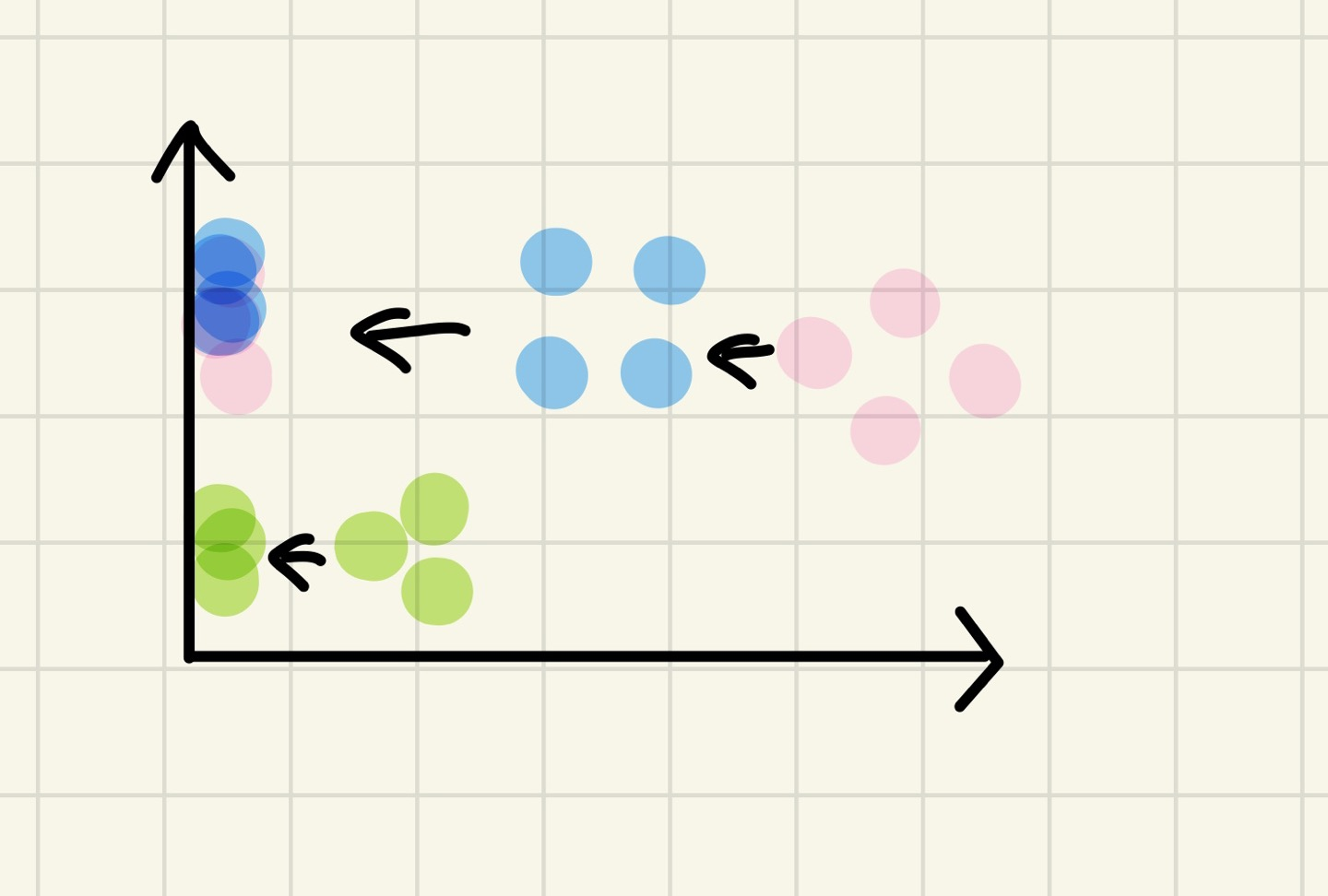
원래의 데이터 형태가 선형이 아닌 곡선과 같이 비선형을 나타내는 모형일 때 더 성능이 좋음EX) MNIST 데이터 셋에 대해 차원 축소를 고려하면, 8과 같은 숫자들은 곡선들로 이루어짐 = T-SNE와 같은 비선형 차원축소 알고리즘을 사용하면 더 성능이 좋음PCA의
12.[ML] 비지도학습 - 차원축소(1)
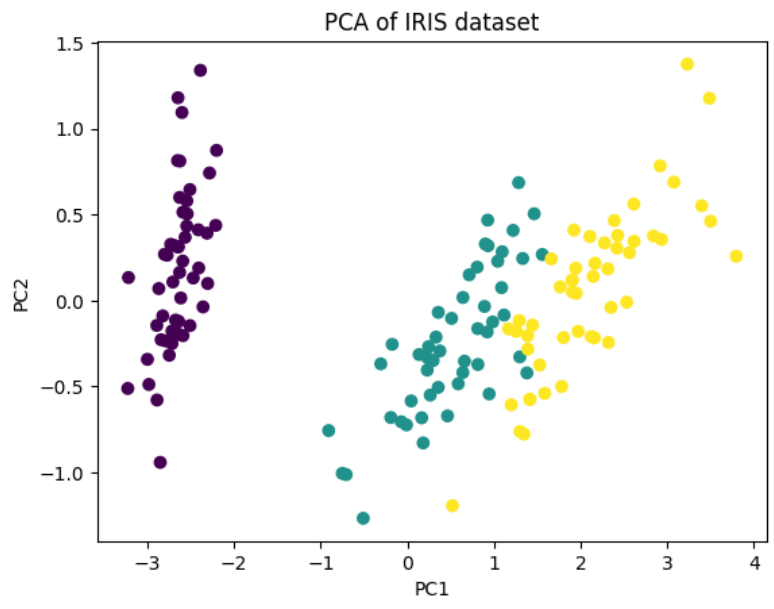
차원축소는 고차원데이터를 저차원 공간으로 변환(매핑)하는 과정으로, 불필요한 특성을 제거하거나 데이터의 중요한 특성만을 유지하면서 데이터를 단순화할 수 있다.차원 축소는 대표적으로 주성분 분석(PCA), 다차원 척도법(MDS),t-SNE 등의 방법이 있다.❓ 차원 축소