빅데이터 분석기사
채점 기준에 맞는 최소한의 코드 플로우 이며, 절대 좋은 코드가 아닐 수 있습니다.
문제 출처: 퇴근 후 딴 짓(캐글)
->빅분기 준비 하는 사람은 다 아실 것 같습니다.
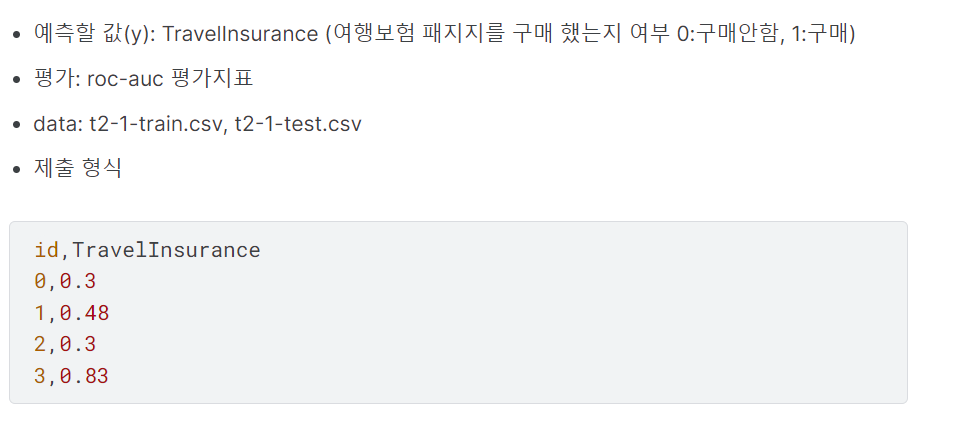
문제: [분류] 여행 보험 패키지 상품을 구매할 확률 값을 구하시오
✔️저는 기본적으로 앙상블 RandomForest 모델을 쓰려 합니당
기본적으로 시험에 train.csv test.csv 가 주어지는 것 같음
import pandas as pd
train= pd.read_csv('/content/t2-1-train (1).csv')
test = pd.read_csv('/content/t2-1-test (1).csv')
#기본 형태 확인
train.head(3)
test.head(3)
#결측치 확인
train.isnull().sum()
#결측치 있다면 저는 fillna(method='ffill' or method='bfill')을 사용하려 합니다.
#ffill=앞의 값 채우기, bfill=뒤의 값 채우기
train = train.fillna(method='ffill')
test = test.fillna(method='bfill')
#제출을 위해 id값 미리 할당
ID = test['id']
#id 할당해준 뒤, train/test는 drop
train= train.drop(['id'],axis=1)
test = test.drop(['id'],axis=1)
#object에 해당하는 값은 숫자 형태로 바꿔주기
from sklearn.preprocessing import LabelEncoder
le = LabelEncoer()
columns = list(train.select_dtypes(include='object').columns)
for col in columns:
train[col] = le.fit_transform(train[col])
test[col] = le.fit_transform(test[col])
#x,y 정의해주기
x = train.drop(['TravelInsurance'],axis=1)
y = train['TravelInsurance']
#정규화 => MinMaxScaler 사용
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
x = scaler.fit_transform(X)
#train,test 나눠주기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x,y,test_size=0.2, random_state=100)
#model 사용=> 회귀문제인지, 분류 문제인지 제대로 확인할 것! 회귀면 RandomForestRegressor 사용해야 됨
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()\
model.fit(X_train,y_train)
y_pred_train = model.predict(X_train)
y_pred_test = model.predict(X_test)
#정확도 보기 (시험에선 확인 못하는 듯)
from sklearm.metrics import accuracy_score
#accuracy_score(실제값, 예측값)
train_accuracy = accuracy_score(y_train, y_pred_train)
test_accuracy = accuracy_score(y_test, y_pred_test_
print(train_accuracy)
print(test_accuracy)
#제출 형태보고 predict와 predict_proba 중 select
predict = model.predict(test)
predict_prob = model.predict_proba(test)
#제출 형태 만들기
result=pd.DataFrame({
'ID' : ID,
#'TravelInsurace':predict
'TravelInsurace':predict_prob[:,1]
result.to_csv('파일명.csv',index=False)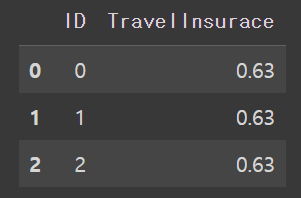

yunjin.log
글 잘 봤습니다~^^