페이징 처리란??
무한 스크롤과 NoOffset에 대해 알아보기 전에 페이징 처리에 대해 간단히 짚어가보자!!! 페이징처리란 흔히 우리가 게시판이나 검색엔진에서 볼 수 있는 페이지를 넘어가면서 보는 것을 구현한 것이다. 즉 수 많은 데이터를 한 페이지내에 보여줄 수 없기에 페이지별로 데이터를 나누고 보여주는 기법이다.
그러면 SpringBoot는 어떻게 페이징 처리를 구현하는가???
바로 Spring Boot JPA에 이미 Interface로 구축되어있으며, 우리는 이를 활용하여 손쉽게 구축할 수 있습니다!!

위처럼 Page는 심지어 객체로 인식되며,반환값으로 넘어갈 수 도 있으며 이 객체에 설정해둔 만큼의 데이터들이 담겨서 이동됩니다.
Pageable이라는 Interface를 객체로 선언하고,pageable을 통해 활용하며 offset, size, page 등 설정을 정할 수 있습니다. pageable은 늘 파라미터로 같이 넘어가며 만약 page=1이면 1페이지의 데이터들을 넘겨받게 됩니다.
무한 스크롤?!?!
필자의 마지막 프로젝트의 게시판을 무한 스크롤을 구현하고자 하였습니다. 무한 스크롤을 어떻게 구현할 것인지 생각했을 때, 무선 View에 보여주고자 하는 데이터보다 많이 가져온 다음에 스크롤 내릴 때 Client에서 빠르게 가져오며 딜레이 없이 보여주며, 추가적인 데이터는 특정한 기준의 이벤트를 잡고 DB에서 데이터를 받아오도록 설정할 예정이다.
하지만...고난의 시작!!
Page,Pageable의 interface를 활용하여 무한스크롤을 구현하려 했지만,Page객체는 Sort의 기준을 정하며 시작합니다. 그런데 필자의 다중,순차 조건의 동적 쿼리를 활용할 때는 Page내에서(이미 Sort조건이 끝난 Page객체로 한번 더 Sort하고 싶은 경우, 그에 반해 List는 쉽다.) Sort하는 것이 너무 어렵습니다.
아래는 Pageable의 Sort 및 size 설정하는 예제입니다.
URL : ?category=ALL&page=0&size=5&sort=default
- 참고로 controller단에서 sort를 따로 받는 코드였는데 아래와 같이 sort : default로 담긴다.
URL : ?category=ALL&page=0&size=5
- sort 파라미터가 없다면 UNSORTED로 담긴다.
- Page request [number: 0, size 5, sort: UNSORTED]
URL : ?category=ALL&page=0&size=5&sort=createdAt
- 만약 정렬기준이 없이 sort만 파라미터에 있다면 Default값은 ASC 오름차순이다.
- Page request [number: 0, size 5, sort: createdAt: ASC]
URL : ?category=ALL&page=0&size=5&sort=CREATED_AT,DESC
- 만약 정렬기준을 DESC로 설정하고 싶다면 ,DESC로 추가해준다.
Page request [number: 0, size 5, sort: CREATED_AT: DESC]
물론 Pageable도 다중조건을 설정해 줄 수 있습니다. @SortDefault라는 어노테이션을 활용하면 다중조건으로 Sort가 가능합니다. 하지만 동적 변수이기에 모든 가능한 Sort 기준을 짜놓아준다는 것은 정말 미친 짓이였기에 Page객체를 포기하고 Query Dsl의 Offset과 Limit을 활용하기로 했습니다.
Offset과 NoOffset?
아마 Pageable를 활용해 페이징 구현을 성공하거나, Test 하신 분들은 알것이다. Query 로그를 보면 아래와 같다는 것을!!!
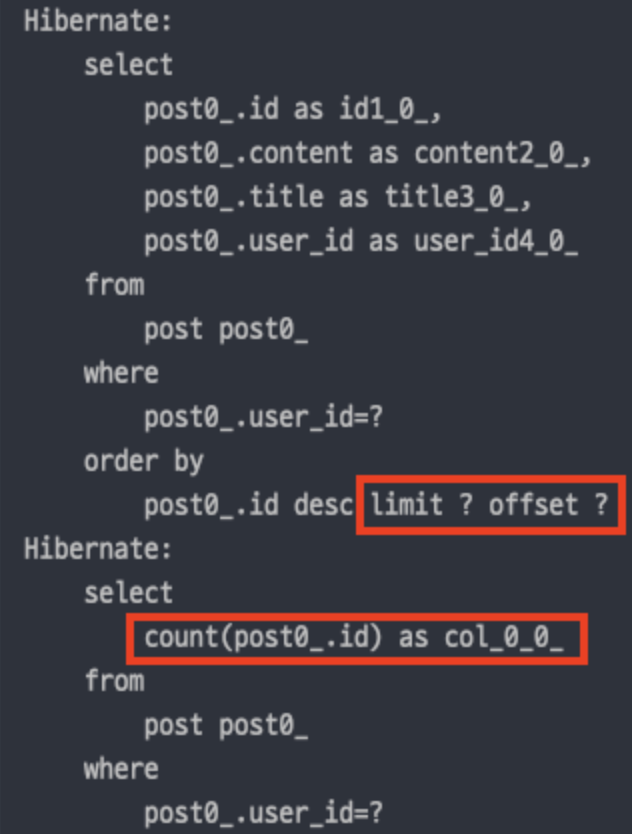
MySQL,Mariadb는 결국 Page는 Limit과 Offset으로 구현되고 있음을 알 수 있다. 추가적으로 Count는 해당 페이지에 지금 몇개가 있는지 세고 있는 쿼리이다.
Query dsl은 offset과 limit을 동적변수를 활용해 설정할 수 있으므로, 굳이 pageable을 활용하지 않고도 페이징을 구현할 수 있다!!
그 전에 Offset과 limit의 역할이 정확히 먼지 알아보자.
- Offset : 시작점을 지정하는 것이라 생각하면 된다. 만약 Offset(100)이면 100이후 부터 데이터를 불러오겠다는 것이다.
- Limit: 데이터의 개수라고 생각하며 된다. 만약 Limit(100)이면 100개의 데이터만 가져오겠다는 것이다.
하지만 Offset은 한가지 치명적인 단점을 가지게 됩니다. 바로 이전까지 데이터까지 다 읽어온다는 것입니다. 예를 들어 offset(1000) limit(100)이라하면 총 1100개의 데이터를 읽어야한다는 것입니다.
이 조회는 나중에 규모가 커지고 데이터가 많아지면 말도안되는 조회속도를 초래하게 됩니다!!!
그러면 어떻게 시작 지점을 조회할 것이냐????라는 문제점이 생기게 됩니다. Query Dsl에서는 BooleanExpression을 통해 새로운 조건을 추가하면 해결할 수 있습니다. 아래의 필자의 코드를 보면서 확인해봅시다.
- Offset을 활용할 때
List<Problem> content = queryFactory.selectFrom(problem).where(containLevel(condition),containType(condition)).orderBy(getProblemSortedByLikes(condition),getProblemSortedByViews(condition),getProblemSortedByLocalTime(condition)).offset(pageable.getOffset()).limit(pageable.getPageSize()).fetch();2.NoOffset일 때
List<Problem> content = queryFactory.selectFrom(problem).where(ProblemId(problemId),containLevel(level),containType(types)).orderBy(getProblemSortedByLikes(order),getProblemSortedByViews(order),getProblemSortedByLocalTime(order)).limit(100).fetch(); private BooleanExpression ProblemId(Long problemId){ if (problemId == null){ return null; } return problem.problemId.gt(problemId); }위 둘의 코드를 비교해보면 차이점음 Offset 부분이 사라지고, Where절에 아래의 BooleanExpression 메소드가 하나 더 생겼다.이 메소드를 살펴보면 problemId가 null이면 조건이 걸리지 안하고, 그 외에는 problemId보다 큰것들에 대해서만 조회를 시작하겠다라는 조건을 겁니다!!!
problemId를 통해 시작 지점을 걸겠다는 것입니다.
그러면 이것은 효율적인가???
대답은 완전 당근입니다. 왜냐하면 NoOffset은 이미 인덱스 처리된 행을 빠르게 찾아내서 그 부분을 기점으로 시작하겠다는 것이기 때문입니다. 모든 데이터를 읽을 필요도 없고, 인덱스 처리된 데이터는 매우 빠를 수 있기 때문에 효율적입니다. 아래의 다른 블로그에서 테스트한 결과를 첨부하며 글을 마무리하고자 합니다.
성능 비교
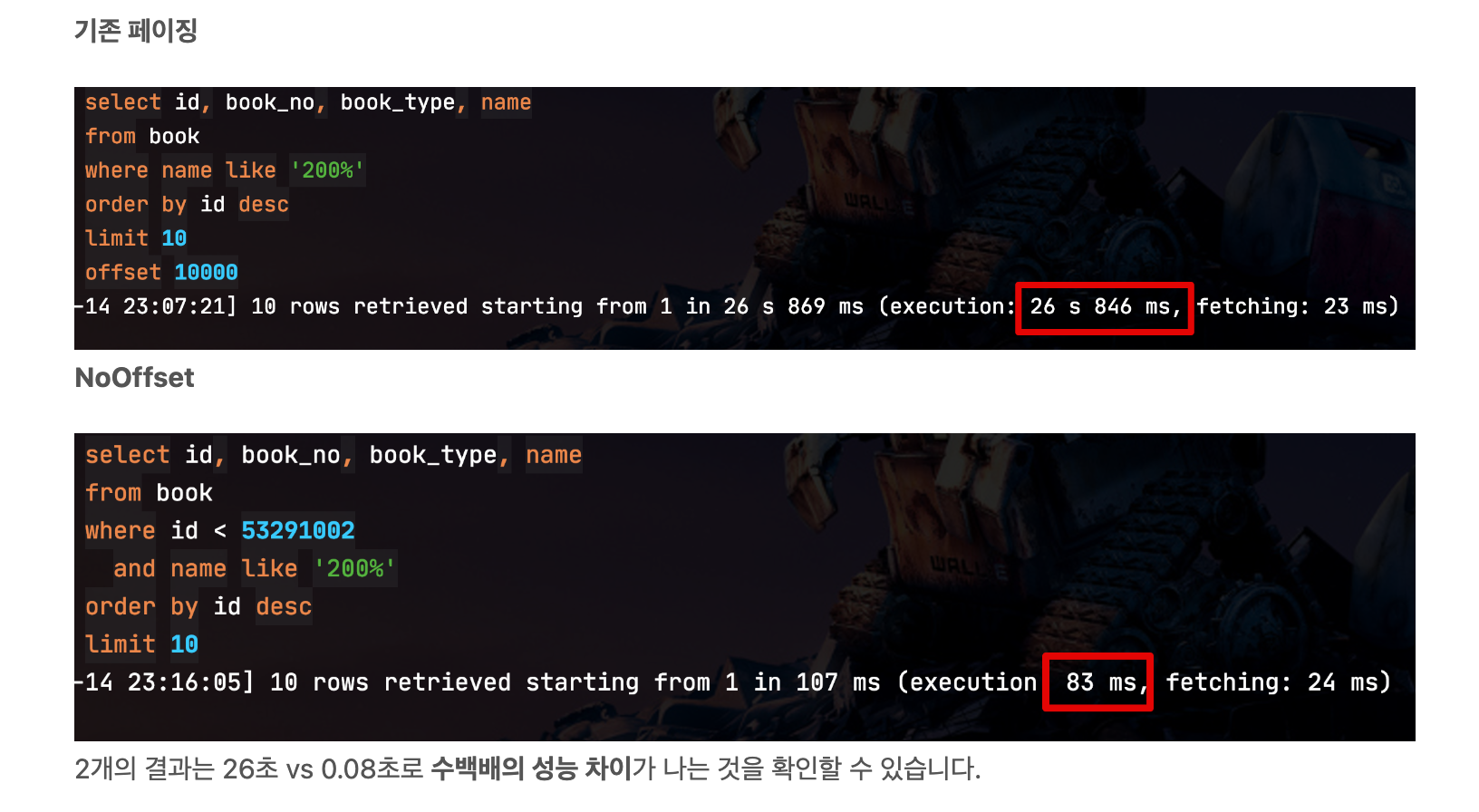
자 그럼 이렇게 변경된 방식은 얼마나 큰 성능 차이를 낼까요?
아래와 같은 환경에서 비교를 해봅니다.
- 테스트 DB
- AWS RDS Aurora MySQL r5.large
- 테스트 테이블
- 1억 row
- 5개 컬럼
글을 마무리하며
필자는 받아온 데이터를 캐시를 통해 더 빠르게 Sort해서 클라이언트에 넘길려고 구상해서 Page,Pageable를 쓰지 않았지만!! 결국 클라이언트 Indexed DB에 넘기면서 다시 써도 되겠다고 글을 쓰면서 생각이 들었지만...결국 NoOffset을 필요가 없어졌네요?? 만약 이 글을 읽는 사람이 있다면, 다시 Page처리에 대해 생각할 수 있는 기회였으면 좋겠습니다.
