
2.3 정수 연산 (Integer Arithmetic)
많은 초보 프로그래머들은 양수 두 개를 더했는데 음수가 나오거나, x < y와 x - y < 0의 결과가 다른 것을 보고 놀라곤 합니다. 이는 컴퓨터 연산이 유한한 비트 내에서 이루어지기 때문에 발생하는 현상입니다. 컴퓨터 연산의 미묘한 특징을 이해하면 더 신뢰성 있는 코드를 작성하는 데 도움이 됩니다.
2.3.1. 부호 없는 덧셈 (Unsigned Addition)
w비트로 표현 가능한 두 부호 없는 정수 x,y가 있을 때 (0≤x,y<2w), 두 수의 합은 의 범위를 가집니다. 이 합을 온전히 표현하려면 w+1개의 비트가 필요할 수 있습니다. 하지만 대부분의 프로그래밍 언어는 고정된 크기의 연산을 지원하므로, 실제 정수 덧셈과는 다른 결과가 나옵니다.
부호 없는 덧셈의 원칙
w비트 부호 없는 덧셈()은 두 수의 실제 합을 w비트로 잘라낸(truncate) 결과와 같습니다. 이는 에 대한 모듈러(modulo) 연산과 동일합니다.
- 예시 (w=4):
x = 9([1001]),y = 12([1100])
- 실제 합: 9+12=21
- 5비트 이진수:[10101]
- 4비트로 잘라내기: 상위 비트1을 버리면[0101], 즉 10진수 5가 됩니다.
- 모듈러 연산: 21(mod16)=5. 결과가 동일합니다.
이처럼 실제 합이 w비트로 표현 가능한 범위를 넘어설 때, 이를 오버플로우(Overflow)라고 합니다.
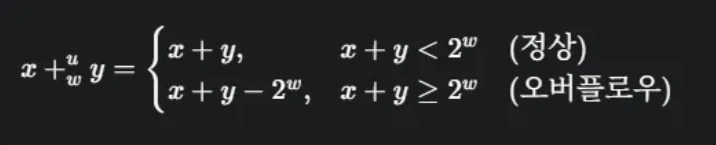
부호 없는 덧셈의 오버플로우 탐지
C언어는 오버플로우가 발생해도 에러를 내지 않습니다. 하지만 오버플로우 발생 여부를 확인할 수 있습니다.
원칙: 합의 결과 s가 원래의 두 수(x 또는 y)보다 작으면 오버플로우가 발생한 것이다.
일 때, (또는 )이면 오버플로우가 발생했다.
- 예시:
9 + 12의 결과는5입니다.5 < 9이므로 오버플로우가 발생했음을 알 수 있습니다.
부호 없는 수의 음수(덧셈의 역원)
모듈러 덧셈에서 모든 수 x는 x+(−x)=0을 만족하는 덧셈의 역원(-x)을 가집니다.
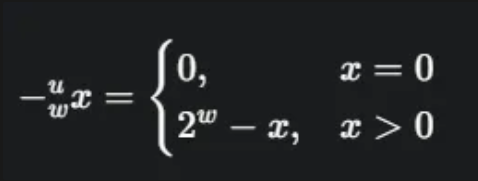
이 원리에 따라, 와 를 더하면 가 되고, 는 0이 되므로 덧셈의 역원 관계가 성립합니다.
2.3.2 2의 보수 덧셈 (Two’s-Complement Addition)
2의 보수 덧셈에서는 결과값이 표현 가능한 범위를 넘어 너무 커지거나(양수 오버플로우) 너무 작아질 때(음수 오버플로우)를 고려해야 합니다.
부호 없는 덧셈과 마찬가지로, 실제 정수 합을 계산한 뒤 w비트로 잘라내는(truncate) 방식을 사용합니다. 2의 보수 덧셈()은 부호 없는 덧셈과 비트 수준에서는 완전히 동일하게 동작합니다. 실제로 대부분의 컴퓨터는 부호 있는 덧셈과 부호 없는 덧셈에 동일한 기계어 명령어를 사용합니다.
2의 보수 덧셈의 원칙
w비트 2의 보수 덧셈은 실제 두 수의 합 x+y의 결과에 따라 세 가지 경우로 나뉩니다.
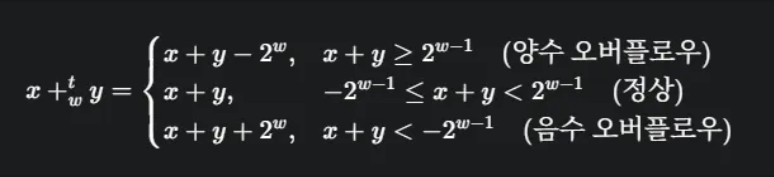
- 양수 오버플로우 (Positive Overflow): 두 양수를 더한 결과가 표현 가능한 최댓값(TMax)보다 커져서 음수가 되는 경우입니다. 결과값은 실제 합에서 를 뺀 것과 같습니다.
- 음수 오버플로우 (Negative Overflow): 두 음수를 더한 결과가 표현 가능한 최솟값(TMin)보다 작아져서 양수가 되는 경우입니다. 결과값은 실제 합에서 를 더한 것과 같습니다.
2의 보수 덧셈의 오버플로우 탐지
2의 보수 덧셈의 오버플로우는 두 피연산자와 결과값의 부호를 비교하여 간단하게 탐지할 수 있습니다.
원칙:
- 양수 오버플로우: 두 양수(x>0,y>0)를 더했는데 결과(s)가 음수 또는 0(s≤0)이 된 경우.
- 음수 오버플로우: 두 음수(x<0,y<0)를 더했는데 결과(s)가 양수 또는 0(s≥0)이 된 경우.
- 예시 (w=4, 범위: -8 ~ 7):
- 양수 오버플로우:
5 + 5- 실제 합: 10
- 4비트 결과: -6 (
1010) - 탐지: 양수 + 양수 → 음수. 오버플로우 발생.
- 음수 오버플로우:
-5 + (-5)- 실제 합: -10
- 4비트 결과: 6 (
0110) - 탐지: 음수 + 음수 → 양수. 오버플로우 발생.
- 정상:
2 + 5- 실제 합: 3
- 4비트 결과: 3 (
0011) - 탐지: 부호가 다른 두 수의 합은 절대 오버플로우가 발생하지 않습니다.
- 양수 오버플로우:
2.3.3 2의 보수 음수 변환 (부호 바꾸기)
2의 보수 체계에서 모든 숫자 x는 x+(−x)=0을 만족하는 덧셈의 역원(음수)을 가집니다.
원칙: 2의 보수 음수 변환
2의 보수 값 x의 부호를 바꾼(negation) 결과 는 다음과 같습니다.
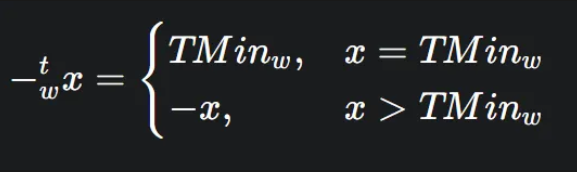
이 원칙은 두 가지 경우로 나뉩니다.
- 일반적인 경우 ():
대부분의 숫자는 우리가 아는 것처럼 단순히 부호를 바꾼 값(x)이 덧셈의 역원이 됩니다. 예를 들어, 5의 역원은 -5입니다. - 특별한 경우 ():
표현 가능한 가장 작은 음수(TMin)는 예외입니다. 의 부호를 바꾼 값은 표현 가능한 범위를 벗어나기 때문에, 의 덧셈 역원은 자기 자신이 됩니다.
- 예시 (w=4, 범위: -8 ~ 7):
-TMin₄ = -8.(-8) = 8이지만,8은 이 범위 안에 표현할 수 없습니다.
- 실제로8 + (-8)을 계산하면16이 되고, 이는 4비트 2의 보수 덧셈에서 음수 오버플로우를 일으킵니다.
-16 + 2^4 = -16 + 16 = 0.
- 따라서 2의 보수 체계에서TMin의 덧셈 역원은TMin자신입니다.
이처럼 값은 2의 보수 체계의 비대칭성을 보여주는 특별한 예외 사례입니다.
2.3.4 부호 없는 곱셈 (Unsigned Multiplication)
비트로 표현 가능한 두 부호 없는 정수 를 곱하면, 그 결과값 는 최대 비트가 필요할 수 있습니다. 예를 들어, 가장 큰 비트 수인 를 제곱하면 그 결과는 약 가 됩니다.
하지만 C언어와 같은 프로그래밍 언어는 연산 결과에 맞춰 데이터 크기를 계속 늘리지 않고 고정된 크기를 사용합니다.
부호 없는 곱셈의 원칙
C언어에서 부호 없는(unsigned) 곱셈은 두 수를 곱한 실제 결과값(2w비트)에서 하위 w비트만 남기고 나머지는 버리는(truncate) 방식으로 정의됩니다.
이는 수학적으로 에 대한 모듈러(modulo) 연산과 같습니다.
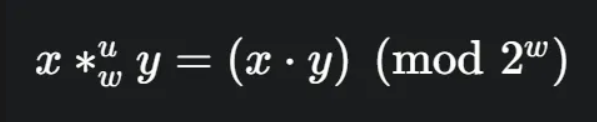
- 예시 (w=4):
x = 9(이진수:1001)y = 12(이진수:1100)
- 실제 곱셈 결과:
9×12=108 - 결과의 8비트(2w) 표현:
108→0110 1100 - 하위 4비트(w)만 남기기 (Truncation):
0110 **1100**→1100 - 최종 결과:
1100(이진수) → 12 (10진수)
- 모듈러 연산으로 검증:
108(mod24)=108(mod16)=12
(108을 16으로 나누면 몫이 6이고 나머지가 12)
두 결과가 정확히 일치하는 것을 볼 수 있습니다.
2.3.5 2의 보수 곱셈 (Two's-Complement Multiplication)
w비트 2의 보수 정수 x,y를 곱하면, 그 결과값은 최대 2w 비트가 필요할 수 있습니다. C언어의 부호 있는(signed) 곱셈은 이 2w비트짜리 실제 결과값에서 하위 w비트만 남기는(truncate) 방식으로 동작합니다.
2의 보수 곱셈의 원칙
w비트 2의 보수 곱셈()은 다음과 같이 정의됩니다.
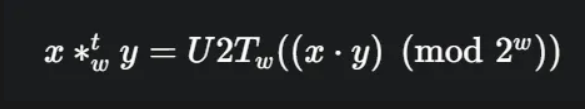
이 수식의 의미는 다음과 같습니다.
- 먼저 두 수의 실제 곱셈을 수행합니다.
- 그 결과에 로 나눈 나머지(modulo)를 구합니다. (이는 하위 w비트를 취하는 것과 같습니다.)
- 이 나머지 값의 비트 패턴을 w비트 2의 보수로 해석합니다.
부호 없는 곱셈과의 비트 수준 동일성 (⭐ 중요)
2의 보수 곱셈에서 가장 중요하고 놀라운 특징은, 최종적으로 얻어지는 w비트 결과의 비트 패턴이 부호 없는 곱셈의 결과와 완전히 동일하다는 점입니다.
원칙:
두 w비트 벡터를 각각 2의 보수로 해석하여 곱셈하고 w비트로 잘라낸 결과나, 부호 없는 수로 해석하여 곱셈하고 w비트로 잘라낸 결과의 비트 패턴은 서로 같다.
- 예시 (w=3):
2 * -3- 2의 보수:
[110]*[101]- 실제 값:
(-2) * (-3) = 6 - 3비트 결과:
6 mod 8 = 6. 2의 보수[110]은-2이므로, 오버플로우 발생하여-2가 됨. 최종 비트 패턴은110.
- 실제 값:
- 부호 없음:
[110]*[101]- 실제 값:
6 * 5 = 30 - 3비트 결과:
30 mod 8 = 6. 부호 없음[110]은6임. 최종 비트 패턴은110.
- 실제 값:
- 2의 보수:
보시는 것처럼, 중간 과정의 숫자 값은 완전히 다르지만 최종 3비트 결과의 비트 패턴은 [110]으로 동일합니다.
이러한 특징 덕분에, CPU는 부호 있는 정수와 부호 없는 정수의 곱셈을 할 때 동일한 곱셈 하드웨어(기계어 명령어)를 사용할 수 있어 칩 설계가 단순해지는 큰 장점이 있습니다.
2.3.6 상수에 의한 곱셈 (Multiplying by Constants)
역사적으로 곱셈 연산은 덧셈이나 시프트 같은 다른 정수 연산(1 클럭 사이클)에 비해 10 클럭 사이클 이상이 걸리는 매우 느린 작업이었습니다. 최신 CPU에서도 정수 곱셈은 3 클럭 사이클이 필요할 정도로 여전히 상대적으로 비싼 연산입니다.
이 때문에 컴파일러는 프로그램의 성능을 높이기 위해 상수와의 곱셈을 더 빠른 시프트(shift)와 덧셈/뺄셈의 조합으로 바꾸는 중요한 최적화를 수행합니다.
1. 기본 원리: 2의 거듭제곱 곱셈 = 왼쪽 시프트
어떤 숫자든 2k를 곱하는 것은 그 숫자의 비트들을 왼쪽으로 k칸 시프트(shift)하는 것과 같습니다.
x* ↔ x << k
- 비유 (10진수): 10진수에서 어떤 수에 10을 곱하는 것은 그 수 뒤에 0을 하나 붙이는 것과 같습니다. (예:
123 * 10 = 1230) 100을 곱하는 것은 0을 두 개 붙이는 것과 같죠. - 비유 (2진수): 2진수에서는 2를 곱하는 것이 뒤에 0을 하나 붙이는 것과 같습니다. (예:
5(101) * 2 = 10(1010))
이 원리는 부호 있는(signed) 수와 부호 없는(unsigned) 수 모두에게, 심지어 오버플로우가 발생하는 경우에도 동일하게 적용됩니다.
2. 일반적인 상수로의 확장
컴파일러는 이 기본 원리를 확장하여 어떤 상수 K와의 곱셈도 시프트와 덧셈/뺄셈의 조합으로 바꿀 수 있습니다.
- 예시:
x * 14
방법 A: 덧셈으로 분해
- 분해:
14 = 8 + 4 + 2 = 2³ + 2² + 2¹ - 변환:
x * 14→x * (2³ + 2² + 2¹)→(x * 2³) + (x * 2²) + (x * 2¹) - 최종 코드:
(x << 3) + (x << 2) + (x << 1)
느린 곱셈 연산 한 번을 빠른 시프트 연산 세 번과 덧셈 연산 두 번으로 바꿨습니다.
방법 B: 뺄셈으로 분해 (더 효율적)
- 분해:
14 = 16 - 2 = 2⁴ - 2¹ - 변환:
x * 14→x * (2⁴ - 2¹)→(x * 2⁴) - (x * 2¹) - 최종 코드:
(x << 4) - (x << 1)
이 방식은 시프트 연산 두 번과 뺄셈 연산 한 번만 필요하므로 방법 A보다 더 효율적입니다.
결론적으로, 컴파일러는 이처럼 상수를 2의 거듭제곱의 합 또는 차로 분해하여, 느린 곱셈 명령어를 사용하지 않고도 동일한 결과를 내는 빠른 코드를 생성하는 최적화를 수행합니다.
2.3.7 2의 거듭제곱으로 나누기
대부분의 컴퓨터에서 정수 나눗셈은 곱셈보다 훨씬 느려서 30 클럭 사이클 이상이 필요합니다. 2의 거듭제곱으로 나누는 작업 역시 시프트 연산으로 대체할 수 있는데, 이번에는 오른쪽 시프트를 사용합니다. 부호 없는 수는 논리 시프트로, 2의 보수(부호 있는 수)는 산술 시프트로 나눗셈을 구현할 수 있습니다.
정수 나눗셈의 반올림 규칙
C언어와 같은 대부분의 프로그래밍 언어에서 정수 나눗셈은 항상 0을 향해 반올림(round toward zero)합니다.
- 양수 나눗셈: 소수점 이하를 버립니다. (예:
7 / 2→3) - 음수 나눗셈: 소수점 이하를 올립니다. (예:
7 / 2→3)
1. 부호 없는 수의 나눗셈
부호 없는 수의 오른쪽 시프트는 논리 시프트로 동작하도록 보장되어 있어 나눗셈 구현이 간단합니다.
원칙: 부호 없는 수의 2의 거듭제곱 나눗셈
부호 없는 정수 x와 k에 대해, C 표현식 x >> k는 x / $2^k$를 소수점 이하 버림한 값과 같습니다.
x를 오른쪽으로 k칸 시프트하면 하위 k개의 비트가 버려지는데, 이는 로 나눈 몫을 구하는 것과 수학적으로 동일합니다.
2. 2의 보수(부호 있는 수)의 나눗셈
부호 있는 수의 나눗셈은 조금 더 복잡합니다.
단순 산술 시프트의 문제점
원칙: 2의 보수 숫자를 산술 오른쪽 시프트하면, 결과는 음의 무한대를 향해 반올림(round down)된다.
- 양수: 문제가 없습니다.
x >> k는x / $2^k$를 0을 향해 반올림한 것과 결과가 같습니다. - 음수: 문제가 발생합니다. 산술 시프트는 음수를 더 작은 값(음의 무한대 방향)으로 내림해 버립니다.
- 예시:
7 / 2- C언어 나눗셈:
-3(0을 향해 올림) - 산술 시프트:
-7 >> 1→-4(음의 무한대를 향해 내림)
- C언어 나눗셈:
- 예시:
해결책: 바이어스(Bias) 추가 후 시프트
음수를 0을 향해 올바르게 반올림하기 위해, 시프트를 하기 전에 특정 '바이어스(bias)' 값을 더해주는 기법을 사용합니다.
원칙: 2의 보수 나눗셈 (0을 향한 반올림)
2의 보수 정수 x를 로 나누는 올바른 C 표현식은 다음과 같습니다.
(x + (1 << k) - 1) >> k
- 동작 원리: 음수
x에$2^k$ - 1이라는 바이어스 값을 더함으로써, 나눗셈 결과가 소수점을 가질 경우 몫이 1만큼 증가하는 효과를 줍니다. 이는 음수를 내림하는 대신 올림하는 것과 같은 결과를 만들어 냅니다. - 최종 C 코드:
// x를 2^k로 나누는 가장 안전한 코드
(x < 0 ? x + (1 << k) - 1 : x) >> k;결론적으로, 오른쪽 시프트는 2의 거듭제곱 나눗셈을 위해 존재하며, 논리 시프트는 부호 없는 수에, 산술 시프트는 부호 있는 수에 사용됩니다. 하지만 산술 시프트는 음수를 처리할 때 반올림 방식이 다르므로, 올바른 결과를 얻기 위해서는 바이어스를 더하는 추가적인 처리가 필요합니다.
2.3.8 정수 연산에 대한 최종 정리
컴퓨터가 수행하는 '정수' 연산은 실제로는 모듈러 연산(modular arithmetic)의 한 형태입니다. 숫자를 표현하는 유한한 워드 크기는 표현 가능한 값의 범위를 제한하며, 이로 인해 연산 결과가 오버플로우(overflow)될 수 있습니다.
2의 보수 표현법의 장점
2의 보수 표현법은 음수와 양수를 모두 표현하는 매우 영리한 방법을 제공합니다. 특히 덧셈, 뺄셈, 곱셈, 나눗셈과 같은 연산들이 부호 없는(unsigned) 산술 연산과 동일하거나 매우 유사한 비트 수준의 동작을 갖도록 해줍니다. 이 덕분에 CPU는 부호 있는 연산과 없는 연산에 동일한 하드웨어 회로를 사용할 수 있습니다.
C언어 사용 시 주의점
C언어의 몇몇 규칙들은 예상치 못한 결과를 낳을 수 있으며, 이는 찾아내기 어려운 버그의 원인이 될 수 있습니다.
특히 부호 없는(unsigned) 자료형은 개념은 단순하지만, 부호 있는(signed) 값과 섞어 쓸 때 암묵적 형 변환으로 인해 숙련된 프로그래머조차 예상하지 못하는 동작을 유발할 수 있습니다. 이러한 unsigned 타입은 숫자 상수를 작성하거나 라이브러리 함수를 호출하는 등 예상치 못한 곳에서 등장할 수 있어 주의가 필요합니다.
