
3.7 프로시저 (Procedures)
- 프로시저(Procedure)는 소프트웨어의 핵심적인 추상화 개념입니다. 특정 기능을 수행하는 코드를 지정된 인자(argument)와 선택적인 반환 값(return value)과 함께 묶어주는 방법을 제공하며, 프로그램의 여러 다른 지점에서 호출될 수 있습니다. (C언어의 함수(function)가 대표적인 예입니다.)
잘 설계된 소프트웨어는 프로시저를 통해 특정 동작의 세부 구현은 숨기고, 어떤 값을 계산하고 어떤 효과를 내는지에 대한 명확하고 간결한 인터페이스만 제공합니다.
프로시저 구현을 위한 기계 수준의 메커니즘
기계어 수준에서 프로시저(함수)를 지원하려면 다음과 같은 여러 속성들을 처리해야 합니다. 프로시저 P가 프로시저 Q를 호출하고, Q가 실행된 뒤 P로 돌아오는 상황을 가정해 봅시다.
- 제어 전달 (Passing Control)
- 호출: 프로그램 카운터(PC)를 Q의 시작 주소로 설정해야 합니다.
- 반환: Q가 끝나면, PC를 P에서 Q를 호출했던 명령어의 다음 주소로 설정해야 합니다.
- 데이터 전달 (Passing Data)
- P는 Q에게 하나 이상의 매개변수(parameter)를 전달할 수 있어야 합니다.
- Q는 P에게 반환 값(return value)을 돌려줄 수 있어야 합니다.
- 메모리 할당 및 해제 (Allocating and Deallocating Memory)
- Q는 시작할 때 지역 변수(local variables)를 위한 공간을 할당하고, 반환하기 전에 그 공간을 해제할 필요가 있을 수 있습니다.
x86-64는 이러한 메커니즘을 구현하기 위해 특별한 명령어들과, 레지스터나 메모리 같은 자원을 어떻게 사용할지에 대한 규약(conventions)의 조합을 사용합니다. 프로시저 호출에 드는 비용(오버헤드)을 최소화하기 위해, 각 프로시저에 필요한 만큼의 메커니즘만 구현하는 최소주의 전략을 따릅니다.
3.7.1 런타임 스택 (The Run-Time Stack)
C언어를 포함한 대부분의 언어에서 프로시저(함수) 호출은 스택(Stack)이라는 데이터 구조가 제공하는 '후입선출(Last-In, First-Out)' 메모리 관리 방식을 사용합니다.
프로시저 P가 Q를 호출하면, Q가 실행되는 동안 P는 잠시 일시 중단됩니다. Q가 실행 중일 때는 Q 자신만이 지역 변수를 위한 새로운 저장 공간을 필요로 합니다. 그리고 Q가 반환(return)되면, Q가 할당했던 모든 지역 저장 공간은 해제될 수 있습니다. 이처럼 함수 호출과 반환에 따라 메모리가 생성되고 해제되는 패턴은 스택 구조에 완벽하게 들어맞습니다.
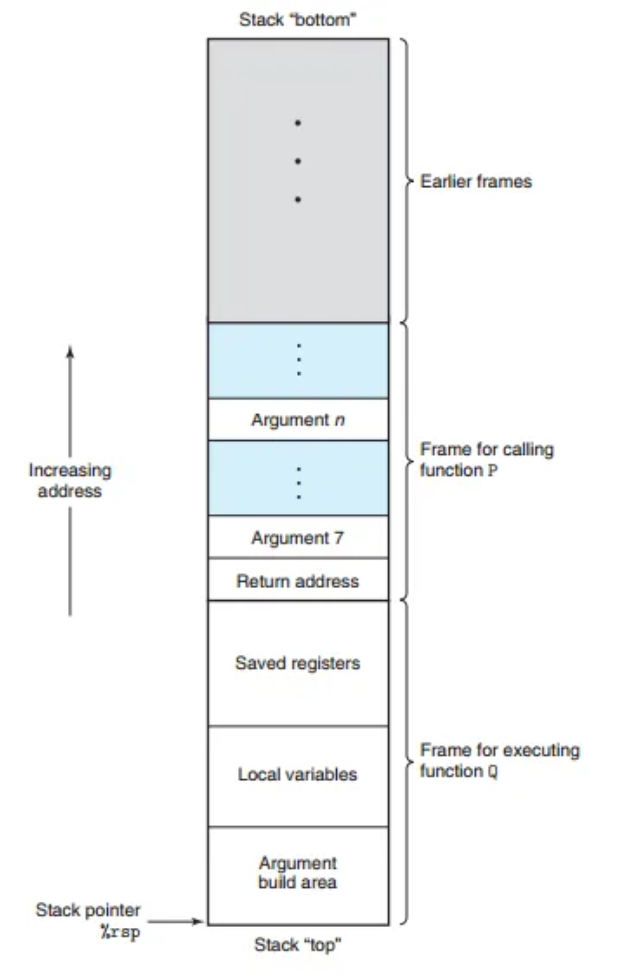
스택 프레임 (Stack Frame)
x86-64에서 프로시저가 레지스터에 다 담을 수 없는 추가적인 저장 공간을 필요로 할 때, 스택에 공간을 할당합니다. 이 영역을 해당 프로시저의 '스택 프레임(Stack Frame)'이라고 합니다.
- 구조: 현재 실행 중인 프로시저의 스택 프레임은 항상 스택의 가장 꼭대기(top)에 위치합니다.
- 동작:
- 프로시저 P가 Q를 호출할 때, P는 Q가 끝난 뒤 돌아올 위치(return address)를 스택에 PUSH합니다. (이 반환 주소는 P의 스택 프레임 일부로 간주됩니다.)
- Q는 자신의 스택 프레임을 위해 스택 포인터(
%rsp)를 아래로(낮은 주소로) 이동시켜 공간을 확보합니다. - Q는 이 공간을 레지스터 값 저장, 지역 변수 할당, 다른 함수에 전달할 인자 설정 등의 용도로 사용합니다.
효율적인 스택 사용
x86-64 프로시저는 시간과 공간의 효율성을 위해 자신에게 필요한 만큼의 스택 프레임만 할당합니다.
- 인자 전달: 최대 6개의 정수/포인터 인자는 레지스터를 통해 전달됩니다. 7개 이상의 인자가 필요할 때만 호출하는 쪽(P)의 스택 프레임에 인자를 저장합니다.
- 스택 프레임이 필요 없는 경우: 모든 지역 변수를 레지스터에 저장할 수 있고, 다른 함수를 전혀 호출하지 않는 '리프 프로시저(leaf procedure)'는 스택 프레임을 아예 사용하지 않을 수도 있습니다.
1. 인자 전달: 레지스터 우선 사용 퀵서비스
과거에는 함수에 인자를 전달할 때 모든 인자를 느린 메모리(스택)에 쌓아두고, 호출된 함수가 다시 메모리에서 읽어오는 비효율적인 방식을 사용했습니다.
이를 개선하기 위해, x86-64 시스템에서는 "자주 쓰는 처음 6개까지의 인자는 매우 빠른 레지스터를 통해 직접 전달하자"는 약속(Calling Convention)을 만들었습니다.
- 6개 이하의 인자:
sum(a, b, c);→a,b,c의 값을 각각 약속된 레지스터(%rdi,%rsi,%rdx등)에 넣어 함수를 호출합니다. 마치 퀵서비스로 물건을 바로 전달하는 것처럼 빠릅니다. - 7개 이상의 인자:
레지스터가 부족하므로, 7번째 인자부터는 어쩔 수 없이 예전 방식대로 호출하는 쪽(P)의 스택 프레임에 쌓아두고 전달합니다.
2. 리프 프로시저: 스택 프레임 생략
리프 프로시저(Leaf Procedure)란, 함수 호출 관계를 나무 모양으로 그렸을 때 가장 끝에 달린 '나뭇잎(leaf)'처럼, 자기 자신 안에서 다른 함수를 전혀 호출하지 않는 함수를 의미합니다.
이런 함수는 스택 프레임을 아예 만들지 않아도 되는 경우가 많습니다. 스택 프레임의 주된 용도는 다음과 같은데, 리프 프로시저에서는 이 작업들이 필요 없거나 레지스터만으로 충분하기 때문입니다.
- 추가 함수 호출을 위한 반환 주소 저장: 다른 함수를 호출하지 않으므로 필요 없습니다.
- 레지스터 값 보존: 다른 함수가 내 레지스터 값을 덮어쓸 걱정이 없으므로, 값을 스택에 백업할 필요가 없습니다.
- 지역 변수 저장: 함수가 사용하는 지역 변수의 개수가 적어 사용 가능한 레지스터에 모두 저장할 수 있다면, 굳이 느린 스택에 공간을 만들 필요가 없습니다.
3.7.2 제어 전달 (Control Transfer)
함수 P에서 Q로 제어를 전달하는 것은 프로그램 카운터(PC)를 Q의 시작 주소로 설정하는 것입니다. 하지만 Q가 끝나고 P로 돌아올 때를 대비해, CPU는 P의 어느 위치로 돌아와야 하는지에 대한 기록을 남겨둬야 합니다.
1. call과 ret 명령어
x86-64는 이 제어 전달을 위해 call과 ret이라는 두 가지 핵심 명령어를 사용합니다.
call Label:- 반환 주소(Return Address)를 스택에 PUSH합니다. 이 주소는
call명령어 바로 다음 명령어의 주소입니다. - 프로그램 카운터(PC)를
Label이 가리키는 함수의 시작 주소로 설정하여 점프합니다.
- 반환 주소(Return Address)를 스택에 PUSH합니다. 이 주소는
ret:- 스택의 가장 위에서 주소를 POP합니다.
- 꺼낸 주소로 프로그램 카운터(PC)를 설정하여 그 위치로 점프합니다.
이처럼 call이 스택에 돌아올 주소를 저장하고 ret이 그 주소를 꺼내 돌아오는 간단한 메커니즘 덕분에, 함수가 여러 번 중첩되어 호출되더라도(예: main → top → leaf) 항상 올바른 위치로 정확하게 복귀할 수 있습니다. 이는 스택의 '후입선출(Last-In, First-Out)' 특성과 완벽하게 들어맞습니다.
call과 ret의 정확한 동작
1. call 명령어 실행
main 함수가 sum 함수를 호출하는 순간입니다.
- CPU는
call명령어 바로 다음 줄의 주소(복귀 주소)를 스택의 가장 위에 PUSH합니다. sum함수의 시작 주소로 점프합니다.
- 이때 스택의 맨 위:
main으로 돌아올 복귀 주소
2. ret 명령어 실행
sum 함수가 모든 계산을 마치고 ret을 실행하는 순간입니다.
ret명령어는 스택의 가장 위에 있는 값, 즉main으로 돌아갈 복귀 주소를 POP합니다.- 스택 포인터는 한 칸 위로 올라가, 이제
main함수의 스택 프레임 꼭대기를 가리키게 됩니다. - CPU는 방금 POP한 복귀 주소를 프로그램 카운터(PC)에 넣고, 그곳으로 점프합니다.
3.7.3 데이터 전달 (Data Transfer)
x86-64에서 함수 호출 시 데이터를 전달하는 규칙은 대부분 레지스터를 통해 이루어집니다. 이는 느린 메모리(스택) 접근을 최소화하여 성능을 높이기 위함입니다.
1. 레지스터를 통한 인자 전달 (최대 6개)
함수를 호출할 때, 최대 6개까지의 정수 또는 포인터 인자(argument)는 정해진 순서의 레지스터에 담아 전달됩니다.
인자 전달 순서 및 레지스터:
| 인자 순서 | 64비트 (long, 포인터) | 32비트 (int) | 16비트 (short) | 8비트 (char) |
|---|---|---|---|---|
| 1번째 | %rdi | %edi | %di | %dil |
| 2번째 | %rsi | %esi | %si | %sil |
| 3번째 | %rdx | %edx | %dx | %dl |
| 4번째 | %rcx | %ecx | %cx | %cl |
| 5번째 | %r8 | %r8d | %r8w | %r8b |
| 6번째 | %r9 | %r9d | %r9w | %r9b |
- 예시:
my_func(long a, int b);
- 첫 번째 인자a는%rdi레지스터에 저장됩니다.
- 두 번째 인자b는%esi레지스터에 저장됩니다.
2. 스택을 통한 인자 전달 (7번째부터)
함수에 전달할 인자가 6개를 초과할 경우, 7번째 인자부터는 스택을 통해 전달됩니다.
- 호출하는 함수(Caller)는
call명령어를 실행하기 전에, 7번째, 8번째, ... 인자들을 자신의 스택 프레임(Argument build area)에 순서대로 PUSH합니다. - 호출된 함수(Callee)는 스택에 저장된 이 인자들을 직접 참조하여 사용합니다.

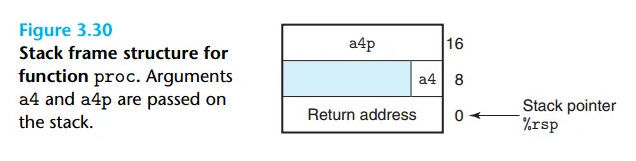
3. 반환 값 전달
함수가 실행을 마치고 값을 반환할 때는, 약속된 %rax 레지스터를 사용합니다.
- 반환 값의 크기가 64비트보다 작으면,
%rax의 하위 부분(예: 32비트는%eax, 8비트는%al)이 사용됩니다.
3.7.4 스택 위의 지역 저장 공간
지금까지 본 대부분의 함수는 레지스터만으로 모든 지역 데이터를 처리할 수 있었습니다. 하지만 때로는 지역 데이터를 반드시 메모리에 저장해야 하는 경우가 발생합니다.
지역 변수를 스택에 저장해야 하는 경우:
- 모든 지역 데이터를 담기에 레지스터가 부족할 때.
- 지역 변수에 주소 연산자
&가 사용되어, 해당 변수의 메모리 주소를 생성해야 할 때. - 지역 변수가 배열이나 구조체라서, 주소 계산을 통해 접근해야 할 때.
일반적으로 함수는 스택 포인터(%rsp)를 감소시켜 자신의 스택 프레임 내에 지역 변수를 위한 공간을 할당합니다.

예시 1: swap_add 함수 호출
caller 함수는 지역 변수인 arg1과 arg2의 주소를 swap_add 함수에 전달해야 합니다. (&arg1, &arg2)
- 문제: 변수의 주소를 얻으려면, 그 변수는 반드시 메모리상에 존재해야 합니다.
- 해결:
caller함수는 시작하자마자 스택 포인터를 16만큼 감소시켜(subq $16, %rsp),arg1과arg2(각각 8바이트)를 저장할 공간을 자신의 스택 프레임에 마련합니다. - 동작:
arg1과arg2의 값을 스택에 저장합니다. (movq $534, (%rsp))leaq명령어를 사용하여 스택에 저장된 변수들의 주소를 계산하고, 이 주소들을 레지스터(%rdi,%rsi)에 넣어swap_add함수를 호출합니다.- 함수가 반환된 후, 스택 포인터를 다시 16만큼 증가시켜(
addq $16, %rsp) 할당했던 공간을 해제합니다.
3.7.5 레지스터 내의 지역 저장 공간
프로그램의 레지스터들은 모든 함수가 공유하는 단일 자원입니다. 따라서 어떤 함수(호출자, Caller)가 다른 함수(피호출자, Callee)를 호출할 때, 피호출자가 호출자가 나중에 사용하려고 했던 레지스터 값을 덮어쓰지 않도록 보장하는 규칙이 필요합니다.
x86-64는 이를 위해 모든 함수가 반드시 지켜야 하는 레지스터 사용 규약을 정의합니다.
1. 피호출자 저장 레지스터 (Callee-Saved Registers)
- 대상:
%rbx,%rbp,%r12–%r15 - 규칙: 함수 P가 함수 Q를 호출할 때, 피호출자인 Q는 이 레지스터들의 원래 값을 반드시 보존해야 할 의무가 있습니다. 즉, Q는 P로 반환될 때 이 레지스터들의 값을 호출 전의 상태와 동일하게 유지해야 합니다.
- 보존 방법: Q는 이 레지스터를 사용하기 전에, 원래 값을 스택에 PUSH하여 백업해두고, 함수가 끝나기 전에 POP하여 원래 값으로 복원해야 합니다.
- 호출자의 이점: 이 규칙 덕분에, 호출자 P는 이 레지스터에 중요한 값을 안전하게 저장해두고, 함수 Q를 호출한 뒤에도 그 값이 변하지 않았을 것이라고 믿을 수 있습니다.
2. 호출자 저장 레지스터 (Caller-Saved Registers)
- 대상:
%rsp와 피호출자 저장 레지스터를 제외한 모든 레지스터 (예:%rax,%rdi,%rsi,%rdx,%rcx,%r8–%r11) - 규칙: 이 레지스터들은 어떤 함수든 마음대로 수정할 수 있습니다.
- 호출자의 의무: 따라서 호출자 P가 이 레지스터에 중요한 값을 가지고 있는데, 다른 함수 Q를 호출해야 한다면, Q가 그 값을 망가뜨릴 수 있습니다. 이 값을 잃지 않으려면 호출자인 P가 직접
call을 하기 전에 그 값을 스택에 저장하는 등의 방법으로 백업해야 할 책임이 있습니다.
예시 코드 분석
long P(long x, long y) {
long u = Q(y);
long v = Q(x);
return u + v;
}위 C 코드에서, 첫 번째 Q(y) 호출 중에는 x의 값을 보존해야 하고, 두 번째 Q(x) 호출 중에는 첫 번째 호출의 결과인 u의 값을 보존해야 합니다.

어셈블리어 코드:
컴파일러는 이 보존이 필요한 값들을 피호출자 저장 레지스터인 %rbp와 %rbx에 저장하는 코드를 생성합니다.
- 2-3번 라인:
pushq %rbp,pushq %rbx
함수 P는 시작하자마자, 자신이 사용할 피호출자 저장 레지스터들의 원래 값을 스택에 백업합니다. - 5번 라인:
movq %rdi, %rbp
첫 번째 인자x를 피호출자 저장 레지스터인%rbp에 안전하게 보관합니다. - 8번 라인:
movq %rax, %rbx
첫 번째Q호출의 결과(u)를 또 다른 피호출자 저장 레지스터인%rbx에 안전하게 보관합니다. - 13-14번 라인:
popq %rbx,popq %rbp
함수가 끝나기 전, 백업해두었던 레지스터들의 원래 값을 스택에서 복원합니다. (PUSH의 역순)
3.7.6 재귀 프로시저 (Recursive Procedures)
지금까지 설명한 레지스터와 스택 사용 규약은 함수가 자기 자신을 재귀적으로 호출하는 것을 완벽하게 지원합니다.
재귀 호출이 가능한 이유
- 독립적인 저장 공간: 함수가 호출될 때마다 스택에는 그 함수만을 위한 독립적인 스택 프-레임이 새로 생성됩니다. 덕분에 여러 번의 재귀 호출이 중첩되어도, 각 호출의 지역 변수들은 서로 간섭하지 않고 안전하게 유지됩니다.
- 스택 규율: 함수가 호출될 때 저장 공간이 할당되고, 반환될 때 해제되는 스택의 '후입선출' 방식은 재귀 함수의 호출-반환 순서와 자연스럽게 일치합니다.
예시: 재귀 팩토리얼 함수
- (a) C 코드:
long rfact(long n) {
if (n <= 1)
return 1;
else
return n * rfact(n-1);
}- (b) 생성된 어셈블리어 코드:
// n in %rdi
1 rfact:
2 pushq %rbx // (백업) %rbx의 원래 값 저장
3 movq %rdi, %rbx // n의 값을 %rbx에 저장
4 movl $1, %eax // 반환값(result)을 1로 초기화
5 cmpq $1, %rdi // n과 1을 비교
6 jle .L35 // 만약 n <= 1 이면 .L35(done)로 점프
7 leaq -1(%rdi), %rdi // n-1 계산
8 call rfact // rfact(n-1) 재귀 호출
9 imulq %rbx, %rax // 반환된 결과(%rax)에 n(%rbx)을 곱함
10 .L35: // done:
11 popq %rbx // (복원) 백업해둔 %rbx 원래 값 복원
12 ret코드 분석
- 2, 3, 11번 라인:
rfact함수는n의 값을 재귀 호출 이후에도 사용해야 합니다. 하지만call명령어 이후에는%rdi레지스터의 값이 바뀔 수 있으므로(호출자 저장 레지스터),n의 값을 안전한 피호출자 저장 레지스터인%rbx에 백업해 둡니다. 함수가 시작될 때%rbx의 원래 값을 스택에 저장하고(pushq), 끝나기 전에 복원(popq)하여 레지스터 사용 규약을 지킵니다. - 8번 라인
call rfact:rfact(n-1)을 재귀적으로 호출합니다. - 9번 라인
imulq %rbx, %rax: 재귀 호출이 끝나고 돌아오면,%rax에는rfact(n-1)의 결과가,%rbx에는 이전에 저장해 둔n의 값이 안전하게 보존되어 있습니다. 이 두 값을 곱하여 최종 결과를 계산합니다.
이처럼 재귀 호출은 일반적인 함수 호출과 전혀 다를 바 없이, 스택과 레지스터 규약을 통해 각 호출이 독립적인 상태 정보를 가지고 순서에 맞게 실행되고 복귀하는 방식으로 완벽하게 구현됩니다.
3.8 배열 할당 및 접근
C언어에서 배열은 기본 데이터 타입들을 묶어 더 큰 데이터 타입을 만드는 방법 중 하나입니다. C는 배열을 매우 단순한 방식으로 구현하기 때문에, 기계어 코드로의 번역 역시 비교적 간단합니다.
C언어의 독특한 특징 중 하나는 배열 내부 요소에 대한 포인터를 생성하고, 이 포인터로 산술 연산을 할 수 있다는 점입니다. 이러한 포인터 연산은 기계어 코드에서 주소 계산으로 직접 번역됩니다.
최적화 컴파일러는 배열 인덱싱에 사용되는 이러한 주소 계산을 단순화하는 데 특히 능숙합니다. 이 때문에 때로는 C 코드와 컴파일러가 생성한 기계어 코드 사이의 연관성을 파악하기가 다소 어려울 수 있습니다.
3.8.1 기본 원칙
C언어에서 T A[N];과 같이 배열을 선언하면 두 가지 일이 일어납니다.
- 메모리 할당: 데이터 타입 T의 크기를 L이라고 할 때, L × N 바이트 크기의 연속된 메모리 공간이 할당됩니다.
- 식별자 생성:
A라는 이름의 식별자가 생성됩니다. 이A는 배열의 시작 주소를 가리키는 포인터로 사용될 수 있습니다.
배열 요소 접근
배열의 i번째 요소(A[i])의 주소는 다음 공식으로 계산됩니다.
주소(A[ i ]) = (배열 시작 주소 x A) + (요소 크기 L) × i
x86-64의 배열 접근 최적화
x86-64의 메모리 주소 지정 방식은 이러한 배열 접근을 매우 쉽게 할 수 있도록 설계되었습니다.
예를 들어, int 타입 배열 E가 있고, E의 시작 주소는 %rdx 레지스터에, 인덱스 i는 %rcx 레지스터에 저장되어 있다고 가정해 봅시다.
E[i]의 값을 가져오는 C 코드는 단 하나의 어셈블리어 명령어로 번역될 수 있습니다.
movl (%rdx, %rcx, 4), %eax
(%rdx, %rcx, 4): "베이스 주소%rdx에 인덱스%rcx와 스케일4를 곱한 값을 더하라" (%rdx + %rcx * 4)는 뜻입니다. 이는 정확히xE + 4*i계산과 일치합니다.movl ..., %eax: 위에서 계산된 최종 주소로 찾아가 4바이트(int) 값을 읽어와서%eax레지스터에 저장합니다.
이처럼 leaq처럼 주소 계산에 스케일 인수(1, 2, 4, 8)를 사용할 수 있어, 대부분의 기본 데이터 타입 배열에 대한 접근을 매우 효율적으로 처리할 수 있습니다.

3.8.2 포인터 연산 (Pointer Arithmetic)
C언어는 포인터에 대한 산술 연산을 허용하며, 이 연산의 결과는 포인터가 가리키는 데이터 타입의 크기에 따라 자동으로 스케일이 조정됩니다.
포인터 덧셈/뺄셈 규칙
T 타입 포인터 p의 주소 값이 일 때, p + i의 결과 주소는 입니다.
(여기서 L은 데이터 타입 T의 크기)
포인터 관련 연산자
&(주소):&Expr는Expr이라는 객체의 메모리 주소를 가리키는 포인터를 생성합니다.*(역참조):*AExpr는AExpr이라는 주소에 저장된 실제 값을 가져옵니다.- 배열과 포인터: C언어에서 배열 참조
A[i]는 포인터 연산*(A+i)와 완전히 동일하게 동작합니다.
포인터 연산과 어셈블리어 코드
정수 배열 E의 시작 주소가 %rdx에, 인덱스 i가 %rcx에 저장되어 있다고 가정했을 때, 다양한 C언어 표현식이 어떻게 어셈블리어로 번역되는지 보여주는 예시입니다.
| C 표현식 | 타입 | 값 (계산식) | 어셈블리어 코드 | 설명 |
|---|---|---|---|---|
E | int * | xE | movq %rdx, %rax | E의 시작 주소를 rax로 복사 |
E[0] | int | M[xE] | movl (%rdx), %eax | E의 첫 번째 요소 값을 eax로 복사 |
E[i] | int | M[xE+4i] | movl (%rdx,%rcx,4), %eax | E의 i번째 요소 값을 eax로 복사 |
&E[2] | int * | xE+8 | leaq 8(%rdx), %rax | E의 2번째 요소의 주소를 계산하여 rax에 저장 |
E+i-1 | int * | xE+4i−4 | leaq -4(%rdx,%rcx,4), %rax | E[i-1]의 주소를 계산하여 rax에 저장 |
*(E+i-3) | int | M[xE+4i−12] | movl -12(%rdx,%rcx,4), %eax | E[i-3]의 값을 eax로 복사 |
- 값 vs. 주소:
int값을 반환하는 표현식은movl을 사용하고,int *(포인터)를 반환하는 표현식은 주소 계산만 하는leaq를 사용하는 것을 볼 수 있습니다. - 포인터 간의 뺄셈: 같은 배열 내의 두 포인터를 빼면(
&E[i] - E), 그 결과는 두 주소의 차이를 요소의 크기로 나눈 값, 즉 두 요소 사이의 인덱스 차이(i)가 됩니다.
3.8.3 중첩 배열 (Nested Arrays)
C언어의 2차원 배열은 실제 메모리에는 '행 우선 순서(Row-major order)'로 펴쳐진 1차원 배열처럼 저장됩니다.
1. 행 우선 순서 (Row-Major Order)
int A[5][3]; 선언은 "3개의 int로 이루어진 배열"을 하나의 단위로 보고, 이러한 단위를 5개 가진 배열로 해석됩니다. 따라서 메모리에는 다음과 같은 순서로 저장됩니다.
- 첫 번째 행의 모든 요소 (
A[0][0],A[0][1],A[0][2])가 먼저 나란히 저장됩니다. - 그 바로 뒤에 두 번째 행의 모든 요소 (
A[1][0],A[1][1],A[1][2])가 이어서 저장됩니다. - 이 과정이 마지막 행까지 반복됩니다.
2. 주소 계산 공식
T D[R][C]; 와 같이 선언된 2차원 배열에서, D[i][j] 요소의 메모리 주소는 다음 공식으로 계산됩니다. (L은 타입 T의 크기)
&D[i][j] = (시작 주소 xD) + L × (C × i + j)
C × i:i번째 행에 도달하기 위해 건너뛰어야 할 전체 요소의 수입니다.j:i번째 행의 시작 부분에서j만큼 더 이동해야 할 요소의 수입니다.

3. 어셈블리어 코드 분석
컴파일러는 위 주소 계산 공식을 매우 효율적인 어셈블리어 코드로 번역합니다.
- C 코드:
A[i][j](int A[5][3]배열의 요소) - 어셈블리어: (A의 시작 주소는
%rdi, i는%rsi, j는%rdx에 저장)
1 leaq (%rsi,%rsi,2), %rax // %rax = i + i*2 = 3*i
2 leaq (%rdi,%rax,4), %rax // %rax = xA + (3*i)*4 = xA + 12*i
3 movl (%rax,%rdx,4), %eax // %eax = M[ %rax + j*4 ] = M[ xA + 12*i + 4*j ]코드 분석:
- 1번 라인:
leaq를 이용해i + i*2를 계산하여3*i를 만듭니다. (배열의 한 행당 요소 개수가 3개이므로) - 2번 라인: 다시
leaq를 이용해xA + (3*i)*4를 계산하여i번째 행의 시작 주소를 구합니다. (int크기가 4바이트이므로 4를 곱함) - 3번 라인:
i번째 행의 시작 주소에j*4를 더하여A[i][j]의 최종 주소를 계산하고,movl명령어로 그 주소에 있는 실제 값을 읽어옵니다.
이처럼 컴파일러는 leaq 명령어의 강력한 주소 계산 능력을 여러 번 조합하여, 2차원 배열의 복잡한 주소 계산을 매우 효율적으로 수행합니다.
3.8.4 고정 크기 배열
컴파일러는 크기가 고정된 다차원 배열을 다루는 코드에 대해 매우 효과적인 최적화를 수행할 수 있습니다.
1. 최적화 이전 (원본 C 코드)
아래 코드는 두 행렬 A와 B의 곱셈 결과 중 i행 k열의 원소 하나를 계산하는 함수입니다. 이는 A의 i번째 행과 B의 k번째 열의 내적(inner product)을 구하는 것과 같습니다.
// (a) Original C code
int fix_prod_ele(fix_matrix A, fix_matrix B, long i, long k) {
long j;
int result = 0;
for (j = 0; j < N; j++)
result += A[i][j] * B[j][k];
return result;
}이 코드의 문제점은, for 반복문이 돌 때마다 A[i][j]와 B[j][k]의 메모리 주소를 매번 새로 계산해야 한다는 것입니다. 이 주소 계산에는 곱셈과 덧셈이 포함되어 있어 비용이 비쌉니다.
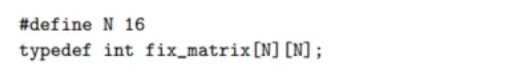

2. 컴파일러의 최적화 기법들
GCC 컴파일러는 -O1 같은 최적화 옵션을 사용하면, 위 코드를 훨씬 효율적인 방식으로 변환합니다. 핵심은 반복 변수 j를 없애고, 모든 배열 접근을 포인터 연산으로 바꾸는 것입니다.
1. 인덱스 j 제거 및 포인터 변환
j를 1씩 증가시키는 대신, A의 행과 B의 열을 따라가는 포인터 Aptr과 Bptr을 사용합니다.
2. 행 접근 최적화 (Aptr++)
A의 i번째 행을 순서대로 접근하는 것은 간단합니다.
Aptr을&A[i][0](i행의 시작 주소)로 초기화합니다.- 루프가 한 번 돌 때마다
Aptr++연산으로 포인터를 다음 요소(&A[i][1],&A[i][2], ...)로 한 칸씩 이동시킵니다. - 이는 복잡한 주소 계산(
A[i][j])을 매우 빠른 포인터 증가 연산으로 대체한 것입니다.
3. 열 접근 최적화 (Bptr += N)
B의 k번째 열을 따라 내려가는 것은 메모리상에서 N칸씩(한 행의 길이만큼) 건너뛰는 것과 같습니다.
Bptr을&B[0][k](k열의 첫 요소 주소)로 초기화합니다.- 루프가 한 번 돌 때마다
Bptr += N연산으로 포인터를 다음 행의 같은 열(&B[1][k],&B[2][k], ...)로 이동시킵니다.
4. 루프 종료 조건 최적화
매번 j < N을 비교하는 대신, 컴파일러는 루프가 끝나야 할 최종 주소(&B[N][k])를 미리 계산해서 Bend라는 포인터에 저장해 둡니다. 그리고 루프 조건으로 Bptr != Bend라는 훨씬 빠른 포인터 비교를 사용합니다.
3. 어셈블리어 코드 분석
위 최적화 기법들이 적용된 실제 어셈블리어 코드는 다음과 같습니다.


%eax:result%rdi:Aptr%rcx:Bptr%rsi:Bend- 2-6번 라인 (초기화): 루프 시작 전에
Aptr,Bptr,Bend포인터의 초기값을 계산하고result를 0으로 설정합니다. - 7-10번 라인 (루프 본체):
Aptr(%rdi)과Bptr(%rcx)이 가리키는 값을 곱하고 결과에 더합니다. - 11-14번 라인 (루프 업데이트 및 검사):
Aptr은 4바이트(int크기),Bptr은 64바이트(16*4, 즉 한 행의 크기)만큼 증가시킨 뒤,Bptr이Bend에 도달했는지 비교하여 루프를 계속할지 결정합니다.
3.8.5 가변 크기 배열 (Variable-Size Arrays)
과거 C언어는 컴파일 시점에 크기가 결정되는 배열만 지원했습니다. 하지만 ISO C99 표준부터는 배열의 크기를 실행 시점에 동적으로 결정할 수 있는 가변 크기 배열 기능이 도입되었습니다.
예를 들어, n x n 크기 배열의 [i][j] 요소에 접근하는 함수를 다음과 같이 작성할 수 있습니다.
int var_ele(long n, int A[n][n], long i, long j) {
return A[i][j];
}여기서 n은 함수가 호출될 때 결정되며, 컴파일러는 이 n 값을 이용해 A[i][j]의 주소를 계산하는 기계어 코드를 생성합니다.
1. 가변 크기 배열의 주소 계산
고정 크기 배열과 주소 계산 방식은 유사하지만, 한 가지 중요한 차이점이 있습니다.
- 고정 크기 배열:
A[i][j](예:A[5][3])의 주소는xA + 12*i + 4*j였습니다. 여기서12(4*3)는 컴파일 시점에 아는 상수이므로,leaq와 시프트 연산으로 빠르게 계산 가능했습니다. - 가변 크기 배열:
A[i][j](예:A[n][n])의 주소는xA + 4*n*i + 4*j입니다. 여기서n은 실행 시점에 결정되는 변수이므로, 컴파일러는 더 이상 시프트 연산으로 최적화할 수 없고 느린 곱셈 명령어(imulq)를 사용해야 합니다.
2. 반복문에서의 최적화
가변 크기 배열을 반복문 안에서 참조할 때, 컴파일러는 접근 패턴의 규칙성을 활용하여 주소 계산을 최적화합니다.
아래는 두 가변 크기 행렬의 곱셈 결과 중 한 요소를 계산하는 C 코드와, 컴파일러가 최적화한 코드, 그리고 실제 어셈블리어 코드입니다.

-
(a) 원본 C 코드:
for루프 안에서 매번A[i][j]와B[j][k]의 주소를 계산합니다. -
(b) 최적화된 C 코드: 컴파일러는 이 코드를 포인터 연산을 사용하는 방식으로 변환합니다.
A의i번째 행을 따라가는 포인터Arow를 사용합니다. (j가 증가함에 따라Arow도 하나씩 증가)B의k번째 열을 따라가는 포인터Bptr을 사용합니다. (j가 증가함에 따라Bptr은n칸씩 건너뜀)
이 방식은 반복문 내에서 비싼 곱셈 연산을 피하고, 더 빠른 포인터 연산만으로 동일한 작업을 수행합니다.
-
어셈블리어 코드: 최적화된 C 코드의 동작을 보여줍니다.
- 루프가 돌 때마다,
Arow포인터(%rsi)는 4바이트씩(addq $4, %rsi),Bptr포인터(%rcx)는4*n바이트씩(addq %r9, %rcx) 증가하는 것을 볼 수 있습니다.
- 루프가 돌 때마다,
결론적으로, 가변 크기 배열은 주소 계산 시 곱셈이 필요하여 고정 크기 배열보다 약간의 성능 저하가 있을 수 있지만, 반복문 내에서는 컴파일러가 포인터 연산으로 주소 계산을 최적화하여 성능을 크게 향상시킬 수 있습니다.
