
3.10 기계 수준 프로그램에서의 제어와 데이터의 결합
지금까지 프로그램의 제어 측면과 데이터 구조 구현을 각각 따로 살펴보았습니다. 이 섹션에서는 데이터와 제어가 서로 어떻게 상호작용하는지 알아보겠습니다.
이 섹션에서 다룰 내용:
- 포인터 심층 분석: C언어의 가장 중요한 개념 중 하나이지만 많은 프로그래머들이 얕게만 이해하고 있는 포인터에 대해 깊이 있게 살펴봅니다.
- GDB 디버거 사용: 기계 수준 프로그램의 상세한 동작을 검사하기 위해 GDB 디버거를 사용하는 방법을 복습합니다.
- 버퍼 오버플로우: 기계 수준 프로그램을 이해함으로써, 실제 시스템의 중요한 보안 취약점인 버퍼 오버플로우를 연구합니다.
- 가변 크기 스택 프레임: 함수가 실행될 때마다 필요한 스택 저장 공간의 크기가 달라지는 경우, 기계 수준 프로그램이 이를 어떻게 구현하는지 살펴봅니다.
3.10.1 포인터 이해하기
포인터는 C언어의 핵심 기능으로, 다양한 데이터 구조 내의 요소에 대한 참조를 생성하는 통일된 방법을 제공합니다. 포인터의 기본 원칙과 기계어 코드로의 변환은 다음과 같습니다.
-
모든 포인터는 타입을 가진다: 포인터가 어떤 종류의 객체를 가리키는지 나타냅니다. 포인터 타입은 주소 지정 오류를 피하도록 돕는 C언어의 추상화이며, 기계어 코드에는 존재하지 않습니다.
int *ip;→int타입의 객체를 가리키는 포인터.
1. 모든 포인터는 타입을 가진다
포인터의 타입은 컴파일러에게 두 가지 매우 중요한 정보를 알려줍니다.
- 크기: 포인터를 역참조()할 때, 메모리에서 몇 바이트를 읽어야 하는가?
int *: "이 주소부터 4바이트를 읽어라."char *: "이 주소부터 1바이트만 읽어라."
- 포인터 연산: 포인터에 1을 더할 때, 실제 주소를 몇 바이트나 이동해야 하는가?
int *p; p+1;→ 주소 값을 4만큼 증가시켜라. (다음int로 이동)char *p; p+1;→ 주소 값을 1만큼 증가시켜라. (다음char로 이동)
2.
void *: 타입이 없는 '범용' 포인터void *는 "설명서가 없는" 범용 포인터입니다. 순수한 메모리 주소 값만 가지고 있을 뿐, 그곳에 어떤 데이터가 있는지에 대한 정보가 전혀 없습니다.malloc함수가 대표적인 예입니다.malloc은 단순히 요청받은 크기의 메모리 공간만 할당해주고 그 시작 주소를 알려줄 뿐, 프로그래머가 그 공간을int로 쓸지struct로 쓸지 알 수 없으므로void *를 반환합니다.- 제약: 타입 정보가 없기 때문에,
void *포인터는 직접 역참조(*)하거나 포인터 연산(+1)을 할 수 없습니다.
3. 형 변환 (Casting): 설명서 붙여주기
프로그래머는 형 변환을 통해
void *같은 범용 포인터에 "이 주소에는 이런 타입의 데이터가 들어있다"고 컴파일러에게 알려줄 수 있습니다.// malloc은 타입 정보가 없는 주소(void *)를 반환 void *generic_ptr = malloc(sizeof(int)); // 프로그래머가 '이 주소는 int를 저장하는 곳이다'라고 알려줌 (형 변환) int *int_ptr = (int *)generic_ptr; // 이제부터는 int 포인터로 안전하게 사용 가능 *int_ptr = 10;이것은 기본 열쇠(
void *)에 "내용물: 4칸 서랍장"이라는 꼬리표를 붙여주는 행위와 같습니다. -
모든 포인터는 값을 가진다: 이 값은 특정 타입의 객체가 저장된 메모리 주소입니다. 특별한 값인
NULL(0)은 포인터가 아무 곳도 가리키지 않음을 의미합니다. -
&연산자로 생성된다:&연산자는 변수나 배열 요소처럼 할당문의 왼쪽에 올 수 있는 표현식(lvalue)에 적용되어, 해당 객체의 주소를 반환합니다. 기계어에서는 주로leaq명령어를 사용하여 이 주소 계산을 수행합니다. -
연산자로 역참조된다: 포인터가 가리키는 주소로 찾아가서 그곳에 저장된 실제 값을 가져옵니다. 이는 메모리에서 값을 읽거나 쓰는 메모리 참조 동작으로 구현됩니다.
-
배열과 밀접하게 관련된다: 배열의 이름은 그 배열의 시작 주소를 가리키는 포인터처럼 사용될 수 있습니다.
a[3]와*(a+3)은 완전히 동일한 표현식입니다. -
포인터 간의 형 변환(Casting): 한 타입의 포인터를 다른 타입으로 형 변환하면, 포인터가 담고 있는 주소 값 자체는 변하지 않지만 타입만 바뀝니다. 타입이 바뀌면 포인터 연산 시 적용되는 스케일(크기)이 달라집니다.
- 예:
char *p가 있을 때,(int *)p + 7→ 주소p에sizeof(int) * 7(즉, 28)을 더합니다.(int *)(p + 7)→ 주소p에sizeof(char) * 7(즉, 7)을 더한 뒤, 그 결과를int*로 해석합니다.
- 예:
-
함수를 가리킬 수도 있다: 포인터는 함수를 가리킬 수도 있습니다. 함수 포인터의 값은 해당 함수의 기계어 코드가 시작되는 첫 번째 명령어의 주소입니다. 이를 통해 코드에 대한 참조를 저장하고 전달하여, 프로그램의 다른 부분에서 그 코드를 호출하는 강력한 기능을 구현할 수 있습니다.
int fun(int x, int *p);int (*fp)(int, int *); fp = fun;int y = 1; int result = fp(3, &y);
3.10.2 실전 프로그래밍: GDB 디버거 사용하기
- GDB (GNU Debugger)는 기계 수준 프로그램의 런타임 동작을 평가하고 분석하는 데 유용한 여러 기능을 제공하는 도구입니다.
코드를 눈으로만 분석하는 대신, GDB를 사용하면 프로그램의 실행을 원하는 대로 제어하면서 실제로 어떻게 동작하는지 직접 관찰할 수 있습니다.
GDB의 기본 사용법
- 실행:
gdb <프로그램_이름>명령어로 디버거를 시작합니다. - 중단점(Breakpoint) 설정: 함수 시작 지점이나 특정 코드 주소처럼, 프로그램 실행을 잠시 멈추고 싶은 지점에 중단점을 설정합니다.
- 실행 및 관찰: 프로그램을 실행하다가 중단점에 도달하면, 프로그램은 멈추고 사용자에게 제어권이 돌아옵니다. 이 상태에서 다음과 같은 작업을 할 수 있습니다.
- 레지스터 및 메모리 검사: 특정 레지스터의 값이나 메모리의 내용을 다양한 형식으로 확인할 수 있습니다.
- 단계별 실행 (Single-stepping): 한 번에 한 명령어씩 프로그램을 실행하며 변화를 관찰합니다.
- 계속 실행: 다음 중단점까지 프로그램을 계속 실행합니다.
유용한 팁
objdump활용: GDB를 실행하기 전에objdump를 이용해 프로그램의 디스어셈블된 버전을 미리 확보하면, 코드의 전체적인 구조를 파악하는 데 매우 도움이 됩니다.- 도움말: GDB의 명령어는 복잡할 수 있지만, GDB 내에서
help명령어를 사용하면 온라인 도움말을 볼 수 있습니다. - GUI: 많은 프로그래머들은 GDB의 커맨드 라인 인터페이스 대신, DDD와 같은 그래픽 사용자 인터페이스(GUI)를 제공하는 확장 프로그램을 선호합니다.
3.10.3 범위를 벗어난 메모리 참조와 버퍼 오버플로우
C언어는 배열의 경계를 검사하지 않으며, 지역 변수는 반환 주소 같은 상태 정보와 함께 스택에 저장됩니다. 이 두 특징이 결합되면, 배열의 경계를 벗어난 쓰기 작업이 스택에 저장된 다른 상태 정보를 손상시키는 심각한 프로그램 오류를 유발할 수 있습니다.
1. 버퍼 오버플로우 (Buffer Overflow)
버퍼 오버플로우는 스택에 할당된 문자 배열(버퍼)에, 할당된 공간보다 더 긴 문자열을 저장할 때 발생하는 상태 손상의 한 형태입니다. gets와 같이 입력값의 길이를 검사하지 않는 함수를 사용할 때 주로 발생합니다.
- 기본 문제:
char buf[8];와 같이 8바이트 버퍼에 20글자를 입력하면,buf의 경계를 넘어 스택의 다른 데이터를 덮어쓰게 됩니다. - 1차적 결과:
ret명령어가 손상된 반환 주소를 읽고 프로그램이 예상치 못한 곳으로 점프하여 비정상적으로 종료되거나 오작동합니다.
오버플로우 발생 과정 (단계별)
1단계: 함수 호출 및 스택 프레임 생성
echo 함수가 호출되면, 메모리의 스택 공간에 echo 함수만을 위한 영역(스택 프레임)이 만들어집니다. 이 공간 안에는 8칸짜리 선반(buf)과, 그 바로 위(높은 주소)에 '비상 대피도'(복귀 주소)가 순서대로 위치합니다.
정상적인 스택 상태
높은 주소
[ ... ]
[ 복귀 주소 (예: 0x400560) ]⬅️ 매우 중요한 정보!
[ char buf[8] (8바이트 공간) ]
낮은 주소
2단계: 경계를 넘는 입력 (벽이 무너지는 순간)
사용자가 8글자가 넘는 문자열, 예를 들어 "AAAAAAAAAAAAAAAA" (16글자)를 입력하고, gets(buf)가 실행됩니다.
- 멍청한 로봇(
gets)은 16개의 'A'를 8칸짜리 선반(buf)에 꾸역꾸역 밀어 넣기 시작합니다. - 선반의 8칸이 모두 채워집니다.
- 하지만 로봇은 멈추지 않고, 남은 8개의 'A'를 계속 밀어 넣습니다.
- 넘쳐흐른 'A'들이 선반 옆 벽을 뚫고, '비상 대피도'(복귀 주소)가 붙어있던 자리를 덮어버립니다.
손상된 스택 상태
[ 'A','A','A','A','A','A','A','A' ]⬅️ 복귀 주소가 'A'의 아스키 코드 값(0x41)으로 덮어쓰여짐!
[ 'A','A','A','A','A','A','A','A' ]⬅️buf공간
3단계: 함수 종료 (ret 명령어 실행)
echo 함수가 끝나고 ret 명령어를 실행할 차례가 됩니다. ret 명령어의 역할은 단 하나입니다.
"스택에서 '복귀 주소'를 꺼내서, 그 주소로 점프하라!"
CPU는 '비상 대피도'가 있던 자리로 가서 주소를 읽으려고 합니다. 하지만 그 자리에는 이제 'AAAA...'라는 쓰레기 값(정확히는 0x41414141...)이 있습니다.
CPU는 이 쓰레기 값을 주소로 착각하고 그곳으로 점프하려고 시도합니다. 하지만 0x41414141은 대부분의 경우 프로그램이 접근할 수 없는 엉뚱한 주소이므로, 운영체제는 이를 '잘못된 메모리 접근'으로 감지하고 프로그램을 강제로 종료시킵니다. 이것이 바로 '세그멘테이션 오류(Segmentation Fault)'입니다.
2. 악용: 보안 공격으로의 발전
버퍼 오버플로우의 더 악의적인 사용법은, 프로그램을 원래 의도되지 않은 기능을 수행하도록 만드는 것입니다. 이는 네트워크를 통해 시스템 보안을 공격하는 가장 흔한 방법 중 하나입니다.
공격 방식:
- 악성 코드 준비: 해커는 시스템 제어권을 탈취하는 등의 악의적인 기계어 코드(익스플로잇 코드, exploit code)를 만듭니다.
- 공격 문자열 제작: 해커는 이 익스플로잇 코드와, 반환 주소를 익스플로잇 코드의 시작 주소로 덮어쓸 가짜 주소를 포함한 매우 긴 문자열을 제작합니다.
- 공격 실행: 이 공격 문자열을
gets와 같은 취약한 함수에 입력합니다. 버퍼 오버플로우가 발생하면서, 스택의 원래 반환 주소는 해커가 만든 가짜 주소로 변경됩니다. - 제어권 탈취: 함수가
ret명령어를 실행하면, CPU는 변경된 가짜 주소, 즉 스택에 주입된 익스플로잇 코드로 점프하여 이를 실행하기 시작합니다.
익스플로잇 코드의 목표:
- 셸 실행: 시스템 콜을 이용해 셸(명령어 해석기)을 실행시켜, 공격자가 원격으로 운영체제의 모든 기능을 사용할 수 있게 합니다.
- 은밀한 공격: 허가되지 않은 특정 작업을 수행한 뒤, 손상된 스택을 원래대로 복구하고 다시
ret을 실행하여 마치 아무 일 없었던 것처럼 정상적으로 호출자에게 복귀합니다.
실제 사례: 1988년의 유명한 '인터넷 웜'은 finger라는 서비스의 버퍼 오버플로우 취약점을 이용하여 수많은 컴퓨터에 침투했습니다. 웜은 시스템에 침투한 뒤 스스로를 복제하여 컴퓨터의 자원을 모두 소모시켰고, 수백 대의 기계가 마비되었습니다.
3. 교훈 및 해결책
gets, strcpy처럼 목적지 버퍼의 크기를 확인하지 않는 함수를 사용하는 것은 매우 위험합니다. 외부 환경과의 모든 인터페이스는 외부 요인의 어떤 행동으로도 시스템이 오작동하지 않도록 '완벽하게 방어(bulletproof)'되어야 합니다.
3.10.4 버퍼 오버플로우 공격 막기
버퍼 오버플로우 공격은 매우 널리 퍼져 컴퓨터 시스템에 수많은 문제를 일으켰기 때문에, 현대의 컴파일러와 운영체제는 이러한 공격을 더 어렵게 만들고 공격자가 시스템 제어권을 탈취하는 방법을 제한하기 위한 여러 메커니즘을 구현해 왔습니다.
이 섹션에서는 최신 GCC 컴파일러가 리눅스 환경에서 제공하는 방어 메커니즘들을 소개합니다.
스택 랜덤화 (Stack Randomization)
버퍼 오버플로우 공격을 성공시키려면, 해커는 악성 코드뿐만 아니라 그 코드의 메모리 주소까지 알아내어 반환 주소를 변조해야 합니다.
- 과거의 문제점: 과거에는 프로그램의 스택 주소가 매우 예측 가능했습니다. 같은 프로그램과 OS를 사용하는 모든 시스템은 거의 동일한 스택 주소를 사용했죠. 이 때문에 해커는 하나의 공격 코드로 수많은 시스템을 감염시킬 수 있었습니다. (보안 단일경작, security monoculture)
- 해결책 (스택 랜덤화): 이 문제를 해결하기 위해, 프로그램을 실행할 때마다 스택의 위치를 임의로 변경하는 기술이 도입되었습니다.
- 동작 방식: 프로그램이 시작될 때, 스택의 시작 부분에 무작위 크기의 빈 공간을 할당합니다. 이 공간은 사용되지는 않지만, 이 공간 때문에 프로그램 내의 모든 스택 주소가 매번 실행할 때마다 달라지게 됩니다.
ASLR (주소 공간 배치 난수화)
스택 랜덤화는 더 큰 개념인 ASLR(Address-Space Layout Randomization)의 일부입니다. ASLR은 스택뿐만 아니라 프로그램 코드, 라이브러리, 힙, 전역 변수 등 메모리의 여러 영역을 프로그램 실행 시마다 각기 다른 주소에 로드합니다. 이로 인해 공격자가 목표 주소를 예측하기가 훨씬 더 어려워집니다.
스택 랜덤화의 한계와 공격 기법
하지만 끈질긴 공격자는 무차별 대입 공격(brute-force)을 통해 랜덤화된 주소를 알아낼 수 있습니다.
- Nop 슬라이드 (Nop Sled): 이 공격을 돕는 일반적인 기법으로, 실제 악성 코드 앞에 아무 동작도 하지 않는
nop명령어를 아주 길게(수백 바이트) 나열하는 것입니다.- 원리: 해커는 이제 악성 코드의 정확한 시작 주소를 맞출 필요 없이, 이 긴
nop미끄럼틀 위의 아무 곳이나 착지하기만 하면 됩니다. 프로그램 카운터(PC)는nop을 따라 미끄러지듯 실행되다가, 결국 미끄럼틀 끝에 있는 실제 악성 코드를 실행하게 됩니다.
- 원리: 해커는 이제 악성 코드의 정확한 시작 주소를 맞출 필요 없이, 이 긴
결론적으로, 스택 랜덤화와 ASLR은 공격을 성공시키는 데 필요한 노력을 크게 증가시켜 바이러스나 웜의 확산 속도를 늦출 수는 있지만, 완벽한 보안을 보장하지는 못합니다.
스택 프로텍터와 카나리(Canary) 값
최신 GCC 컴파일러는 버퍼 오버런을 탐지하기 위해 스택 프로텍터(Stack Protector)라는 메커니즘을 사용합니다.
- 핵심 아이디어: 지역 변수인 버퍼(buffer)와 스택의 나머지 상태 정보(복귀 주소 등) 사이에 '카나리(canary)'라고 불리는 특별한 값을 저장해 둡니다.

비유: 탄광 속 카나리아
과거 광부들이 유독가스를 탐지하기 위해 카나리아 새를 데리고 탄광에 들어간 것에서 유래했습니다. 만약 카나리아가 죽으면(값이 변경되면), 광부(프로그램)는 위험을 감지하고 즉시 대피(프로그램 중단)합니다.
- 동작 방식:
- 카나리 값 저장: 함수가 시작될 때, 프로그램이 실행될 때마다 무작위로 생성된 카나리 값을 스택의 특정 위치(버퍼와 복귀 주소 사이)에 저장합니다. 이 값은 공격자가 쉽게 예측할 수 없습니다.
- 버퍼 오-버플로우 발생: 만약 버퍼 오버플로우가 발생하면, 공격자는 복귀 주소를 덮어쓰기 전에 반드시 카나리 값을 먼저 덮어쓰게 됩니다.
- 카나리 값 검사: 함수가 종료되기 직전, 스택에 저장해 둔 카나리 값이 원래의 값과 일치하는지 검사합니다.
- 결과:
- 일치: 카나리 값이 변경되지 않았으므로, 함수는 정상적으로 종료됩니다.
- 불일치: 카나리 값이 변경된 것을 보고 스택이 손상되었다고 판단하여, 프로그램을 오류와 함께 즉시 중단시킵니다.
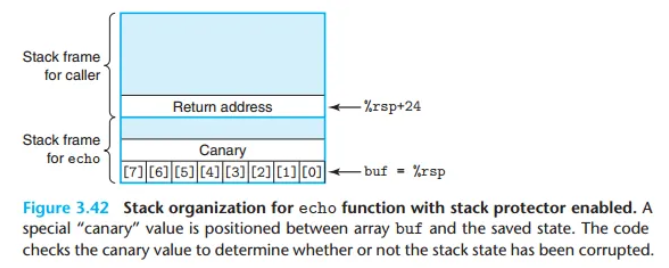
이러한 스택 보호 기능은 버퍼 오버플로우 공격이 프로그램의 실행 흐름을 장악하는 것을 효과적으로 막아주며, GCC는 함수 내에 char 타입 버퍼가 있을 때 자동으로 이 기능을 삽입합니다.
실행 가능 코드 영역 제한하기
버퍼 오버플로우 공격을 막는 마지막 방어선은, 공격자가 시스템에 실행 가능한 코드를 주입하는 능력 자체를 없애는 것입니다.
1. 핵심 아이디어: 권한 분리
일반적인 프로그램에서 기계어 코드가 실행될 필요가 있는 곳은 컴파일러가 생성한 코드 영역(.text segment)뿐입니다. 스택이나 힙 같은 다른 메모리 영역은 데이터를 읽고 쓰는 역할만 하면 됩니다.
따라서 메모리 각 페이지마다 읽기(Read), 쓰기(Write), 실행(Execute) 권한을 분리하여 제어하는 방법이 사용됩니다.
2. 과거의 문제점
과거 x86 아키텍처에서는 '읽기' 권한과 '실행' 권한이 하나로 묶여 있었습니다. 따라서 데이터를 읽고 써야 하는 스택 영역은 항상 실행 가능한 상태였고, 이는 공격자가 스택에 악성 코드를 주입하여 실행시키기 매우 좋은 환경이었습니다.
3. 현대의 해결책: NX 비트 (No-Execute Bit)
이 문제를 해결하기 위해, AMD와 인텔은 최신 64비트 프로세서에 NX(No-Execute) 비트라는 메모리 보호 기능을 도입했습니다. (윈도우에서는 DEP(데이터 실행 방지)라고 부릅니다.)
- 동작: 이 기능을 사용하면 운영체제는 스택이나 힙 같은 데이터 영역을 읽고 쓰기는 가능하지만, 실행은 불가능하도록 표시할 수 있습니다.
- 장점: 이 검사는 하드웨어 수준에서 이루어지므로, 성능 저하 없이 매우 효율적으로 공격을 막을 수 있습니다. 만약 프로그램이 스택에 주입된 코드를 실행하려고 시도하면, CPU는 이를 감지하고 프로그램을 즉시 강제 종료시킵니다.
결론: 3가지 자동 방어 기법
지금까지 설명된 스택 랜덤화(ASLR), 스택 보호(스택 카나리), 그리고 실행 가능 영역 제한(NX 비트)은 버퍼 오버플로우 공격에 대한 취약점을 최소화하는 가장 일반적인 세 가지 메커니즘입니다.
이 기법들은 프로그래머의 특별한 노력 없이 컴파일러와 운영체제가 자동으로 적용하며, 성능 저하도 거의 없습니다. 각각의 기법이 독립적으로 방어 수준을 높여주며, 함께 사용될 때 더욱 강력한 효과를 냅니다.
3.10.5 가변 크기 스택 프레임 지원
지금까지 본 대부분의 함수는 컴파일 시점에 필요한 스택 프레임의 크기를 미리 결정할 수 있었습니다. 하지만 alloca 함수를 사용하거나 가변 크기 배열을 선언하는 경우처럼, 함수가 실행될 때마다 필요한 지역 저장 공간의 크기가 달라질 수 있습니다.
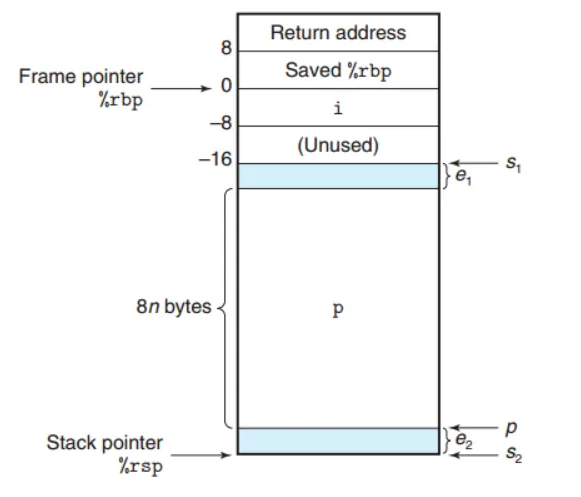
프레임 포인터 (%rbp)의 사용
이러한 가변 크기 스택 프레임을 관리하기 위해, x86-64 코드는 %rbp 레지스터를 프레임 포인터(Frame Pointer) 또는 베이스 포인터(Base Pointer)로 사용합니다.
- 동작 원리:
- 프레임 포인터 설정: 함수가 시작되면, 이전 함수의
%rbp값을 스택에 저장하고, 현재의 스택 위치를 새로운%rbp값으로 설정합니다. 이%rbp값은 함수가 실행되는 내내 고정된 기준점 역할을 합니다. - 가변 공간 할당: 가변 크기 배열(
p)과 같은 동적 공간은%rbp아래쪽, 즉 스택의 더 깊은 곳에 할당됩니다. 이 공간의 크기는 변할 수 있으므로, 스택 포인터(%rsp)는 계속 움직입니다. - 지역 변수 접근:
i와 같이 크기가 고정된 지역 변수는 변하지 않는 기준점인%rbp를 기준으로 한 고정된 오프셋(예:-8(%rbp))을 통해 안정적으로 접근할 수 있습니다.
- 프레임 포인터 설정: 함수가 시작되면, 이전 함수의
코드 예시: vframe 함수
vframe 함수는 n의 크기에 따라 가변적인 배열 p를 스택에 할당해야 합니다.
- 2-3번 라인:
pushq %rbp,movq %rsp, %rbp
함수 프롤로그입니다. 이전%rbp를 스택에 저장하고, 현재%rsp위치를 새로운 프레임 포인터로 설정합니다. - 4-11번 라인: 고정 크기 변수
i를 위한 공간(16바이트)과 가변 크기 배열p를 위한 공간(8n 바이트)을 스택에 할당합니다. - 17번 라인:
movq -8(%rbp), %rax
지역 변수i의 값을 읽을 때, 계속 변하는%rsp가 아닌 고정된%rbp를 기준으로-8오프셋을 사용하여 접근하는 것을 볼 수 있습니다.
leave 명령어: 스택 프레임 정리
함수가 종료될 때, leave 명령어는 가변 크기 프레임을 정리하는 역할을 합니다.
- 동작:
leave명령어는 아래 두 명령어와 동일하게 동작합니다.movq %rbp, %rsp: 스택 포인터를 프레임 포인터 위치로 되돌려, 할당했던 모든 지역 공간(가변 배열 포함)을 한 번에 해제합니다.popq %rbp: 스택에 저장해두었던 이전 함수의%rbp값을 복원합니다.
결론적으로, %rbp를 프레임 포인터로 사용하는 것은 스택의 크기가 동적으로 변하는 상황에서도 고정된 지역 변수에 안정적으로 접근할 수 있는 메커-니즘을 제공합니다. (참고: 현대 컴파일러는 최적화를 위해 스택 프레임의 크기가 고정된 함수에서는 프레임 포인터를 생략하기도 합니다.)
3.11 부동소수점 코드
프로세서의 부동소수점 아키텍처는 부동소수점 데이터를 다루는 프로그램이 기계에 어떻게 매핑되는지에 영향을 주는 여러 측면을 포함합니다.
- 부동소수점 값이 저장되고 접근되는 방식 (주로 레지스터 사용)
- 부동소수점 데이터에 대한 연산 명령어
- 함수 인자 전달 및 값 반환에 대한 규약
- 함수 호출 시 레지스터 보존에 대한 규약 (호출자/피호출자 저장)
역사적 배경: MMX, SSE, AVX
1997년 Pentium/MMX 이후, 인텔과 AMD는 그래픽 및 이미지 처리를 지원하기 위해 미디어 명령어를 지속적으로 발전시켜 왔습니다. 이 명령어들은 여러 데이터를 병렬로 처리하는 SIMD(Single Instruction, Multiple Data) 방식에 초점을 맞추었습니다.
이러한 확장 기능들은 MMX → SSE → AVX 순서로 발전해 왔으며, 데이터를 저장하는 레지스터도 MM(64비트) → XMM(128비트) → YMM(256비트)로 점점 커졌습니다.
x86-64 부동소수점의 기반: SSE/AVX
2000년 Pentium 4와 함께 도입된 SSE2부터, 이 미디어 명령어들은 단일 부동소수점 값을 처리하는 스칼라(scalar) 연산을 포함하게 되었습니다.
x86-64를 실행할 수 있는 모든 프로세서는 SSE2 이상을 지원하므로, 오늘날 x86-64의 부동소수점 연산은 전통적인 x87 방식이 아닌 SSE 또는 AVX를 기반으로 합니다.
이 책에서는 2013년 Core i7 Haswell과 함께 도입된 AVX2를 기준으로 설명합니다.
AVX 부동소수점 아키텍처
AVX 아키텍처는 16개의 256비트(32바이트) YMM 레지스터(%ymm0–%ymm15)를 제공합니다.
- 스칼라 연산: 단일 부동소수점 값을 다룰 때는 이 거대한 레지스터의 하위 32비트(
float) 또는 64비트(double)만 사용합니다. - 레지스터 이름: 어셈블리어 코드에서는 YMM 레지스터의 하위 128비트에 해당하는 SSE 시절의 이름, 즉 XMM 레지스터(
%xmm0–%xmm15)를 사용하여 이 레지스터들을 참조합니다.
3.11.1 부동소수점 이동 및 변환 연산
1. 데이터 이동 (vmovss, vmovsd, vmovaps, vmovapd)
부동소수점 데이터는 메모리와 XMM 레지스터 사이, 또는 XMM 레지스터끼리 이동합니다.
- 스칼라 이동 (
vmovss,vmovsd): 단일 값(32비트 또는 64비트)을 메모리와 레지스터 사이에서 옮깁니다.ss는 scalar single precision,sd는 scalar double precision을 의미합니다. - 벡터 이동 (
vmovaps,vmovapd): XMM 레지스터 간에 데이터를 복사할 때는, 레지스터 전체(128비트)를 한 번에 복사하는 벡터 명령어를 사용합니다. 이는 스칼라 값을 옮길 때도 마찬가지이며, 성능상의 차이는 거의 없습니다.
예시:
vmovss (%rdi), %xmm0 // 메모리(src)에서 float 값을 %xmm0으로 읽어온다. (v2 = *src)
vmovaps %xmm0, %xmm1 // %xmm0의 값을 %xmm1로 복사한다.
vmovss %xmm1, (%rsi) // %xmm1의 값을 메모리(dst)에 쓴다. (*dst = v1)2. 데이터 변환 (정수 ↔ 부동소수점)
부동소수점 → 정수 변환 (vcvttss2si, vcvttsd2si)
XMM 레지스터나 메모리에 있는 부동소수점 값을 읽어 정수로 변환한 뒤, 그 결과를 범용 레지스터(%rax 등)에 저장합니다. C언어의 규칙에 따라 소수점 이하는 0을 향해 버리는(truncate) 방식으로 변환됩니다.
vcvttsd2siq: double → quadint(64비트 정수)로 변환.
정수 → 부동소수점 변환 (vcvtsi2ss, vcvtsi2sd)
메모리나 범용 레지스터에 있는 정수 값을 읽어 부동소수점으로 변환한 뒤, 그 결과를 XMM 레지스터에 저장합니다.
vcvtsi2sdq: quadint(64비트 정수) → double로 변환.
3. 부동소수점 형식 간의 변환 (float ↔ double)
GCC 컴파일러는 float을 double로, 또는 그 반대로 변환할 때 단일 변환 명령어를 사용하는 대신, 두 개의 벡터 명령어 조합을 사용하는 독특한 방식을 사용합니다.
예를 들어, %xmm0의 하위 4바이트에 있는 float 값을 double로 변환할 때,
vunpcklps: 먼저 이 4바이트 값을 복제하여 8바이트로 만듭니다.vcvtps2pd: 그 후 8바이트 전체를double형식으로 변환합니다.
이러한 방식은 결과적으로 XMM 레지스터 안에 동일한 값이 두 개 복제되는 형태로 나타나는데, 왜 컴파일러가 더 간단한 단일 명령어를 쓰지 않고 이런 방식을 사용하는지에 대한 명확한 이유는 없습니다.
3.11.2 프로시저에서의 부동소수점 코드
x86-64에서는 XMM 레지스터가 부동소수점 인자를 함수에 전달하고, 부동소수점 값을 반환하는 데 사용됩니다.
1. 부동소수점 인자 전달 규칙
- 최대 8개의 부동소수점 인자는 XMM 레지스터(
%xmm0–%xmm7)를 통해 전달됩니다. 인자 목록에 나타난 순서대로 레지스터가 사용됩니다. - 9번째 부동소수점 인자부터는 스택을 통해 전달됩니다.
2. 부동소수점 반환 값 규칙
- 함수가
float이나double값을 반환할 때는, 약속된%xmm0레지스터를 사용합니다.
3. 레지스터 저장 규약
- 모든 XMM 레지스터는 호출자 저장(caller-saved) 레지스터입니다. 즉, 피호출자(callee)는 이 레지스터들을 백업 없이 마음대로 덮어쓸 수 있습니다.
혼합된 인자 전달 예시
함수에 정수, 포인터, 부동소수점 인자가 섞여 있을 때, 인자들은 각자의 타입에 맞는 레지스터에 순서대로 할당됩니다.
- 예시 1:
double f1(int x, double y, long z);x(정수, 1번째 정수/포인터 인자) →%ediy(부동소수점, 1번째 부동소수점 인자) →%xmm0z(정수, 2번째 정수/포인터 인자) →%rsi
- 예시 2:
double f2(double y, int x, long z);y(부동소수점, 1번째) →%xmm0x(정수, 1번째) →%ediz(정수, 2번째) →%rsi
(인자의 순서가 바뀌어도, 각 타입별로 순서를 따져 레지스터가 할당되므로 결과는 위와 동일합니다.)
3.11.4 부동소수점 상수 정의 및 사용
정수 연산(addq $5, %rax)과 달리, AVX 부동소수점 연산 명령어는 피연산자로 즉시 값(immediate value, 상수)을 직접 사용할 수 없습니다.
따라서 컴파일러는 코드에 사용된 부동소수점 상수(예: 1.8, 32.0)를 위해 메모리에 미리 공간을 할당하고 값을 저장해 둔 뒤, 연산 시 그 메모리에서 값을 읽어오는 방식으로 코드를 생성합니다.
예시: 섭씨를 화씨로 변환하는 함수
- C 코드:
double cel2fahr(double temp) {
return 1.8 * temp + 32.0;
}- 어셈블리어 코드:
// temp in %xmm0
1 cel2fahr:
2 vmulsd .LC2(%rip), %xmm0, %xmm0 // temp를 .LC2 위치의 값(1.8)과 곱한다.
3 vaddsd .LC3(%rip), %xmm0, %xmm0 // 결과에 .LC3 위치의 값(32.0)을 더한다.
4 ret
// --- 읽기 전용 데이터 섹션 ---
5 .LC2:
6 .long 3435973837 // 1.8의 하위 4바이트
7 .long 1073532108 // 1.8의 상위 4바이트
8 .LC3:
9 .long 0 // 32.0의 하위 4바이트
10 .long 1077936128 // 32.0의 상위 4바이트코드 분석
- 2, 3번 라인:
vmulsd와vaddsd명령어는$1.8과 같은 상수 값을 직접 사용하지 못하고, 대신.LC2와.LC3라는 레이블이 붙은 메모리 주소에서 값을 읽어와 연산을 수행합니다. - 5-10번 라인: 컴파일러는
.LC2와.LC3라는 이름으로 읽기 전용 데이터 섹션(.rodata)에 8바이트double상수1.8과32.0의 비트 패턴을 미리 저장해 두었습니다. (.long은 4바이트 데이터를 의미하며, 두 개가 모여 8바이트를 이룹니다.)
결론적으로, 부동소수점 코드에서 상수를 사용하는 것은, 컴파일러가 상수를 메모리에 '변수'처럼 저장해두고, 실제 연산 시에는 이 메모리 변수를 읽어오는 방식으로 구현됩니다.
3.11.5 부동소수점 코드에서의 비트 단위 연산 사용
때때로 GCC 컴파일러는 유용한 부동소수점 결과를 얻기 위해, XMM 레지스터에 비트 단위(bitwise) 연산을 수행하는 코드를 생성하기도 합니다.
이러한 비트 연산 명령어들(vxorps, vandps 등)은 패킹된 데이터(packed data)에 대해 동작합니다. 이는 두 소스 XMM 레지스터의 모든 비트에 대해 병렬적으로 비트 연산을 수행하여, 목적지 XMM 레지스터 전체를 업데이트한다는 의미입니다.
비록 이 명령어들이 벡터 연산을 위한 것이지만, 스칼라(단일) 부동소수점 값을 다룰 때도 레지스터의 하위 4바이트 또는 8바이트에 미치는 영향을 이용하여, 특정 부동소수점 연산을 간단하고 편리하게 구현하는 영리한 방법으로 사용될 수 있습니다.
3.11.6 부동소수점 비교 연산
AVX2는 부동소수점 값을 비교하기 위해 두 가지 주요 명령어를 제공합니다.
ucomiss S₁, S₂: 단정밀도(float) 비교ucomisd S₁, S₂: 배정밀도(double) 비교
이 명령어들은 정수 cmp 명령어처럼 두 피연산자를 비교하여 조건 코드(condition codes)를 설정합니다. 단, 피연산자 S₂는 반드시 XMM 레지스터에 있어야 합니다.
1. 조건 코드 설정
정수 비교와 달리, 부동소수점 비교는 ZF(Zero Flag), CF(Carry Flag)와 함께 PF(Parity Flag)라는 특별한 플래그를 설정합니다.
S₂와 S₁의 관계 | CF | ZF | PF | 설명 |
|---|---|---|---|---|
| 순서 없음 (Unordered) | 1 | 1 | 1 | S₁ 또는 S₂가 NaN일 경우 |
S₂ < S₁ | 1 | 0 | 0 | |
S₂ = S₁ | 0 | 1 | 0 | |
S₂ > S₁ | 0 | 0 | 0 |
- Parity Flag (PF): 부동소수점 비교에서는 특별히 피연산자 중 하나라도 NaN(Not a Number)일 때 1로 설정됩니다.
jp(jump on parity) 같은 명령어를 통해 이 경우를 감지할 수 있습니다.
NaN이 아닌 경우, CF와 ZF는 부호 없는(unsigned) 정수 비교와 동일하게 동작합니다.
2. 예시: find_range 함수
아래 코드는 float 값 x가 0보다 작은지, 같은지, 큰지, 아니면 NaN인지를 판별하는 함수와 그에 해당하는 어셈블리어 코드입니다.
- (a) C 코드:
typedef enum { NEG, ZERO, POS, OTHER } range_t;
range_t find_range(float x) {
if (x < 0) return NEG;
else if (x == 0) return ZERO;
else if (x > 0) return POS;
else return OTHER;
}- (b) 생성된 어셈블리어 코드:
GCC가 생성한 코드는 비효율적이지만, 조건 코드와 분기(jump)를 어떻게 사용하는지 잘 보여줍니다.
-vxorps %xmm1, %xmm1, %xmm1: XOR 연산을 이용해 0.0을 만들어%xmm1에 저장합니다.
-vucomiss %xmm0, %xmm1:x와0.0을 비교합니다.
-ja .L5:x > 0.0이면.L5(neg)로 점프합니다. (어셈블리어에서는ja가ja보다 크다는 뜻이지만, 피연산자 순서가 반대이므로 실제로는x < 0.0일 때 점프합니다. 이는 책의 설명 오류로 보입니다.)
-jp .L8:x가 NaN이면.L8(posornan)로 점프합니다.
-je .L3:x == 0.0이면.L3(done)로 점프합니다.
- 각 분기(jump)는 조건에 맞는enum값(0, 1, 2, 3)을%eax에 설정한 뒤 반환하는 코드로 이어집니다.
결론적으로, 부동소수점 비교는 ucomiss/ucomisd 명령어로 조건 코드(CF, ZF, PF)를 설정하고, ja, jp, je와 같은 조건부 점프 명령어로 이 플래그들을 조합하여 프로그램의 실행 흐름을 제어하는 방식으로 구현됩니다.
3.11.7 부동소수점 코드에 대한 관찰
AVX2를 사용하여 부동소수점 데이터를 처리하기 위해 생성된 기계어 코드의 일반적인 스타일은, 정수 데이터를 처리하기 위한 코드와 유사합니다. 두 방식 모두 레지스터를 사용하여 값을 저장하고 연산하며, 함수 인자를 전달하는 데에도 레지스터를 사용합니다.
물론, 서로 다른 데이터 타입과 혼합된 표현식을 처리하는 규칙에는 많은 복잡성이 따르며, AVX2 코드는 정수 연산만 수행하는 함수보다 훨씬 더 많은 종류의 명령어와 형식을 포함합니다.
또한, AVX2는 패킹된 데이터(packed data)에 대한 병렬 연산을 수행하여 계산 속도를 높일 수 있는 잠재력을 가지고 있습니다. 컴파일러 개발자들이 스칼라 코드를 병렬 코드로 자동 변환하는 작업을 하고 있지만, 현재로서는 병렬성을 통해 더 높은 성능을 얻는 가장 신뢰할 수 있는 방법은 GCC가 지원하는 C언어 확장 기능을 사용하여 데이터 벡터를 직접 다루는 것입니다.
3.12 요약 (Summary)
이번 챕터에서는 C언어라는 추상화 계층의 이면을 들여다보고, 기계 수준 프로그래밍의 세계를 살펴보았습니다. 컴파일러가 생성한 어셈블리어 코드를 통해 우리는 컴파일러와 그 최적화 능력, 그리고 컴퓨터 자체의 데이터 타입 및 명령어 집합에 대한 통찰력을 얻었습니다.
C언어와 기계어 코드의 차이점
기계 수준 프로그램은 C 프로그램과 여러 면에서 다릅니다.
- 자료형: 데이터 타입 간의 구분이 거의 없습니다.
- 명령어: 프로그램은 각각 단일 작업을 수행하는 명령어들의 연속으로 표현됩니다.
- 프로그램 상태: 레지스터나 런타임 스택과 같은 프로그램 상태가 프로그래머에게 직접적으로 드러납니다.
- 저수준 연산: 데이터 조작과 프로그램 제어를 위해 저수준 연산만 제공되므로, 컴파일러는 C언어의 조건문, 반복문, 프로시저 같은 구조를 구현하기 위해 여러 개의 명령어를 사용해야 합니다.
보안 및 메모리
C언어의 경계 검사 부재는 많은 프로그램을 버퍼 오버플로우에 취약하게 만듭니다. 이 때문에 많은 시스템이 악의적인 공격에 노출되었지만, 최근에는 런타임 시스템과 컴파일러가 제공하는 안전장치(ASLR, 스택 카나리 등) 덕분에 프로그램의 보안성이 향상되었습니다.
또한, 프로그램이 데이터를 런타임 스택, 동적 할당된 힙, 전역 데이터 영역 중 어디에 저장하는지 이해하는 것이 중요하며, 기계 수준의 지식은 이러한 저장 방식 간의 차이를 더 쉽게 이해하도록 돕습니다.
다른 언어와의 관계
- C++: C와 매우 유사하게 컴파일됩니다. 객체는 구조체로, 메서드는 함수 포인터로 표현됩니다.
- Java: 완전히 다른 방식으로 구현됩니다. Java 코드는 자바 바이트코드라는 특별한 이진 표현으로 컴파일됩니다. 이 바이트코드는 하드웨어가 아닌 자바 가상 머신(JVM)이라는 소프트웨어 인터프리터에 의해 실행됩니다. 또는 JIT(Just-In-Time) 컴파일을 통해 동적으로 기계어 명령어로 번역되기도 합니다. 바이트코드의 장점은 다양한 컴퓨터에서 동일한 코드를 실행할 수 있다는 점입니다.
