
6.6 종합: 캐시가 프로그램 성능에 미치는 영향 (Putting It Together: The Impact of Caches on Program Performance)
이 섹션에서는 실제 머신에서 실행되는 프로그램의 성능에 캐시가 미치는 영향을 연구함으로써 메모리 계층 구조에 대한 논의를 마무리합니다.
6.6.1 메모리 마운틴 (The Memory Mountain)
프로그램이 메모리 시스템에서 데이터를 읽는 속도를 읽기 처리량(read throughput) 또는 읽기 대역폭(read bandwidth)이라고 합니다. 만약 프로그램이 s초 동안 n바이트를 읽는다면, 해당 기간 동안의 읽기 처리량은 n/s이며, 일반적으로 초당 메가바이트(MB/s) 단위로 표현됩니다.
만약 우리가 타이트한 프로그램 루프(tight program loop)에서 연속적인 읽기 요청을 발행하는 프로그램을 작성한다면, 측정된 읽기 처리량은 해당 특정 읽기 시퀀스에 대한 메모리 시스템의 성능에 대한 통찰력을 제공할 것입니다.
측정 코드 분석 (mountain.c)
본문 그림 6.40의 코드는 특정 읽기 시퀀스에 대한 읽기 처리량을 측정하는 함수 쌍을 보여줍니다.

test함수:stride만큼의 간격으로 배열의 첫elems개 요소를 스캔하여 읽기 시퀀스를 생성합니다. 내부 루프에서 사용 가능한 병렬성을 높이기 위해 4x4 루프 언롤링(loop unrolling)을 사용합니다.run함수:test함수를 호출하고 측정된 읽기 처리량을 반환하는 래퍼(wrapper) 함수입니다.- 37행의
test함수 호출은 실제 측정을 시작하기 전에 캐시를 예열(warm up)하는 역할을 합니다 (콜드 미스 영향을 배제하기 위함). - 38행의
fcyc2함수는test함수를 실제로 호출하고 실행 시간을 CPU 사이클 단위로 추정합니다. - 39행은 측정된 사이클을 MB/s 단위로 변환합니다.
- 37행의
run 함수에 전달되는 size와 stride 인자는 결과적인 읽기 시퀀스의 시간적 지역성과 공간적 지역성의 정도를 제어할 수 있게 해줍니다.
size값이 작을수록 작업 집합(working set) 크기가 작아져 더 나은 시간적 지역성을 갖습니다.stride값이 작을수록 더 나은 공간적 지역성을 갖습니다.
만약 우리가 size와 stride 값을 바꿔가며 run 함수를 반복적으로 호출한다면, 시간적 지역성과 공간적 지역성에 대한 읽기 처리량의 관계를 나타내는 매혹적인 2차원 함수를 얻을 수 있습니다. 이 함수를 메모리 마운틴(Memory Mountain)이라고 부릅니다.
메모리 마운틴 분석 (Intel Core i7 Haswell 예시)
모든 컴퓨터는 해당 메모리 시스템의 능력을 특징짓는 고유한 메모리 마운틴을 가집니다. 그림 6.41은 Intel Core i7 Haswell 시스템의 메모리 마운틴을 보여줍니다.
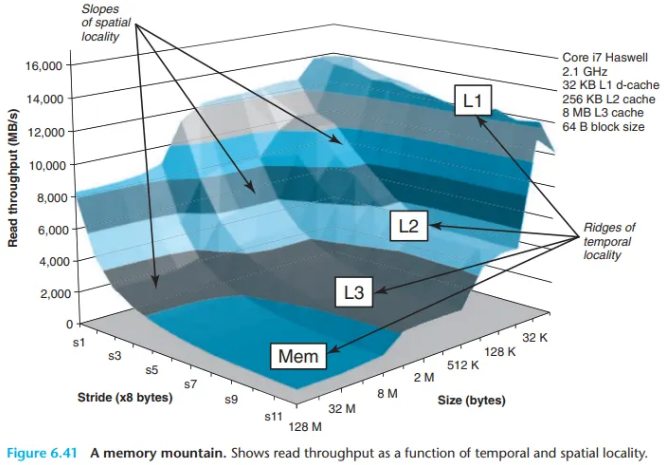
- 능선 (Ridges) - 시간적 지역성의 영향:
size축에 수직으로 뻗어 있는 4개의 능선(ridge)이 보입니다. 이는 작업 집합이 각각 L1 캐시, L2 캐시, L3 캐시, 그리고 메인 메모리에 완전히 들어가는 시간적 지역성 영역에 해당합니다. L1 능선의 가장 높은 봉우리(14 GB/s 이상)와 메인 메모리 능선의 가장 낮은 지점(900 MB/s) 사이에는 10배 이상의 성능 차이가 있음을 주목하십시오. - 경사 (Slopes) - 공간적 지역성의 영향: L2, L3, 메인 메모리 능선 각각에는
stride가 증가하고 공간적 지역성이 감소함에 따라 내리막길을 형성하는 경사(slope)가 존재합니다. 작업 집합이 너무 커서 어떤 캐시에도 들어가지 못하는 경우에도, 메인 메모리 능선의 가장 높은 지점은 가장 낮은 지점보다 8배나 더 높습니다. 이는 프로그램의 시간적 지역성이 나쁘더라도, 공간적 지역성만으로도 여전히 상당한 성능 차이를 만들 수 있음을 의미합니다. - 특별한 현상 - 하드웨어 프리페칭 (Hardware Prefetching):
stride가 1일 때, 작업 집합이 L1과 L2 용량을 초과함에도 불구하고 읽기 처리량이 12 GB/s로 비교적 평탄하게 유지되는 특히 흥미로운 능선이 있습니다. 이는 Core i7 메모리 시스템의 하드웨어 프리페칭 메커니즘 때문인 것으로 보입니다. 이 메커니즘은 순차적인 스트라이드-1 참조 패턴을 자동으로 식별하여, 해당 블록들이 실제로 접근되기 전에 미리 캐시로 가져오려고 시도합니다. 이 알고리즘이 작은 스트라이드에서 가장 잘 작동한다는 사실은, 코드에서 순차적인 스트라이드-1 접근을 선호해야 하는 또 다른 이유가 됩니다.
메모리 마운틴 단면 분석 (Slicing the Mountain)
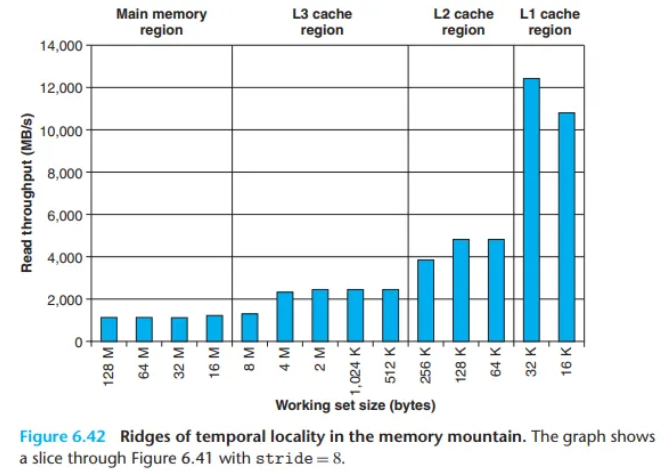
- 시간적 지역성의 영향 (그림 6.42):
stride를 상수로 고정하고size를 변화시키면, 작업 집합 크기가 각 캐시 용량을 초과할 때마다 처리량이 급격히 떨어지는 계단식 그래프를 볼 수 있습니다. 32KB까지는 L1, 256KB까지는 L2, 8MB까지는 L3에서 처리되며, 그 이상은 메인 메모리에서 처리됩니다.
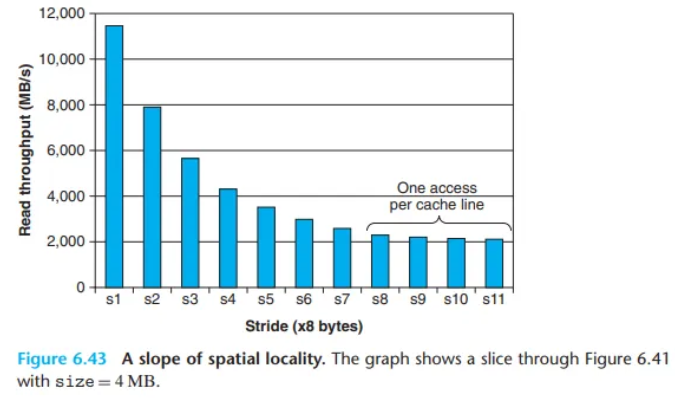
- 공간적 지역성의 영향 (그림 6.43): 작업 집합 크기를 4MB로 고정하고
stride를 변화시키면,stride가 1에서 8로 증가함에 따라 읽기 처리량이 꾸준히 감소하는 것을 볼 수 있습니다.stride가 증가할수록 L2 미스 대 L2 히트의 비율이 증가하기 때문입니다.stride가 8개의 워드(64바이트, 즉 블록 크기)에 도달하면, 모든 읽기 요청이 L2에서 미스가 되어 L3로부터 블록을 가져와야 하므로, 처리량은 L3에서 L2로 블록을 전송하는 속도에 의해 결정되는 일정한 값으로 수렴합니다.
결론: 프로그래머를 위한 시사점
메모리 시스템의 성능은 단 하나의 숫자로 특징지어질 수 없습니다. 대신, 그것은 성능의 고저차가 10배 이상 날 수 있는 시간적 및 공간적 지역성의 산(mountain)입니다.
현명한 프로그래머는 자신의 프로그램이 골짜기가 아닌 봉우리에서 실행되도록 구조화하려고 노력합니다. 목표는 시간적 지역성을 활용하여 자주 사용하는 워드가 L1 캐시에서 처리되도록 하고, 공간적 지역성을 활용하여 가능한 한 많은 워드가 단일 L1 캐시 라인에서 접근되도록 하는 것입니다.
6.6.2 공간적 지역성 향상을 위한 루프 재배치 (Rearranging Loops to Increase Spatial Locality)
이번에는 n x n 행렬 쌍의 곱셈 C = AB 문제를 고려해 봅시다. 행렬 곱셈 함수는 보통 i, j, k 인덱스를 사용하는 3중 중첩 루프로 구현됩니다. 이 루프들의 순서를 바꾸고 약간의 코드 변경을 가하면, 기능적으로 동일한 6가지 버전의 행렬 곱셈 함수를 만들 수 있습니다. 각 버전은 루프의 순서에 따라 고유하게 식별됩니다.
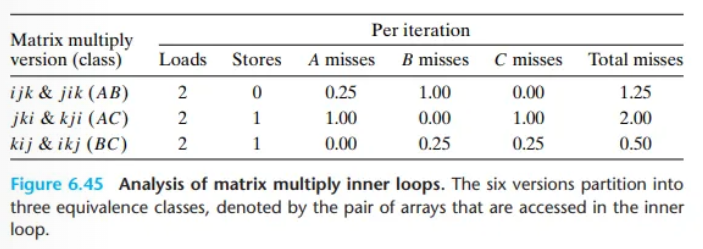
겉보기에는 6가지 버전이 모두 매우 유사합니다. 각 버전은 의 연산을 수행하며, 동일한 횟수의 덧셈과 곱셈을 합니다. 하지만 가장 안쪽 루프(inner loop)의 동작을 분석해 보면, 메모리 접근 횟수와 지역성 측면에서 큰 차이가 있음을 발견할 수 있습니다.
분석을 위한 가정
- 각 배열은
double형의n x n행렬이며,sizeof(double) = 8바이트입니다. - 캐시는 단 하나이며 블록 크기는 32바이트입니다 (
B=32). (즉, 한 블록에 4개의 double 값을 담을 수 있음) - 배열 크기
n은 매우 커서, 행렬의 한 행 전체가 L1 캐시에 들어가지 않습니다. - 컴파일러는 지역 변수를 레지스터에 저장하므로, 루프 내 지역 변수 참조는 메모리 로드/스토어 명령을 유발하지 않습니다.
클래스 AB: 중간 성능 (반은 좋고, 반은 나쁨)
(a) Version ijk / (b) Version jik

두 버전 모두 가장 안쪽 루프는 k에 대한 루프입니다. 내부 루프의 핵심 코드는 다음과 같습니다.
sum += A[i][k] * B[k][j];
A[i][k]접근 분석:k가0, 1, 2, ...로 변하는 동안i는 고정됩니다.- 접근 순서:
A[i][0], A[i][1], A[i][2], ... - 결론: 이것은 메모리 상에서 연속된 데이터를 순서대로 읽는 행 우선 접근(Stride-1)입니다. 공간적 지역성이 매우 좋습니다.
- 미스율: 4번 접근할 때마다 1번의 미스가 발생합니다. (미스율: 0.25)
B[k][j]접근 분석:k가0, 1, 2, ...로 변하는 동안j는 고정됩니다.- 접근 순서:
B[0][j], B[1][j], B[2][j], ... - 결론: 이것은 메모리 상에서 멀리 떨어진 데이터를 건너뛰며 읽는 열 우선 접근(Stride-n)입니다. 공간적 지역성이 매우 나쁩니다.
- 미스율: 배열
n이 크기 때문에, 매번 접근이 새로운 메모리 블록을 요구하여 100% 미스가 발생합니다. (미스율: 1.0)
성능 요약: 반복당 총 미스율은 0.25 + 1.0 = 1.25입니다. A에 대한 접근은 효율적이지만, B에 대한 접근이 매우 비효율적이라 전체 성능을 저하시킵니다.
클래스 AC: 최악의 성능 (둘 다 나쁨)
(c) Version jki / (d) Version kji

두 버전 모두 가장 안쪽 루프는 i에 대한 루프입니다. 내부 루프의 핵심 코드는 다음과 같습니다.
C[i][j] += A[i][k] * r; (여기서 r은 B[k][j])
A[i][k]접근 분석:i가0, 1, 2, ...로 변하는 동안k는 고정됩니다.- 접근 순서:
A[0][k], A[1][k], A[2][k], ... - 결론: 열 우선 접근(Stride-n)입니다. 공간적 지역성이 매우 나쁩니다.
- 미스율: 1.0
C[i][j]접근 분석:i가0, 1, 2, ...로 변하는 동안j는 고정됩니다.- 접근 순서:
C[0][j], C[1][j], C[2][j], ... - 결론: 열 우선 접근(Stride-n)입니다. 공간적 지역성이 매우 나쁩니다.
- 미스율: 1.0
성능 요약: 반복당 총 미스율은 1.0 + 1.0 = 2.0입니다. 내부 루프에서 접근하는 두 배열 모두 최악의 접근 패턴을 보이므로 성능이 가장 느립니다.
클래스 BC: 최고의 성능 (둘 다 좋음)
(e) Version kij / (f) Version ikj

두 버전 모두 가장 안쪽 루프는 j에 대한 루프입니다. 내부 루프의 핵심 코드는 다음과 같습니다.
C[i][j] += r * B[k][j]; (여기서 r은 A[i][k])
B[k][j]접근 분석:j가0, 1, 2, ...로 변하는 동안k는 고정됩니다.- 접근 순서:
B[k][0], B[k][1], B[k][2], ... - 결론: 행 우선 접근(Stride-1)입니다. 공간적 지역성이 매우 좋습니다.
- 미스율: 0.25
C[i][j]접근 분석:j가0, 1, 2, ...로 변하는 동안i는 고정됩니다.- 접근 순서:
C[i][0], C[i][1], C[i][2], ... - 결론: 행 우선 접근(Stride-1)입니다. 공간적 지역성이 매우 좋습니다.
- 미스율: 0.25
A[i][k]는?:r = A[i][k]는 가장 안쪽 루프의 바깥에 있습니다. 즉,j루프가 한 번 도는 동안A[i][k]의 값은 변하지 않고 레지스터에 저장된r값을 계속 재사용합니다. 따라서 내부 루프의 캐시 성능에 영향을 주지 않습니다.
성능 요약: 반복당 총 미스율은 0.25 + 0.25 = 0.50입니다. 내부 루프에서 반복적으로 접근하는 두 배열 모두 이상적인 스트라이드-1 패턴을 가지므로 캐시 효율이 극대화되어 가장 빠른 성능을 보입니다.
최종 결론
이처럼 겉보기에는 사소한 루프 순서의 변경이 내부 루프의 메모리 접근 패턴을 완전히 바꾸어 버리고, 이는 캐시의 공간적 지역성 활용도에 직접적인 영향을 미쳐 수십 배의 성능 차이를 만들어냅니다. kij와 ikj가 가장 빠른 이유는, 가장 빈번하게 실행되는 내부 루프가 메모리에 연속적으로 저장된 데이터를 순서대로 접근하기 때문입니다.
실제 성능 측정 결과 (Core i7)
본문 그림 6.46의 그래프는 실제 Core i7 시스템에서 측정한 결과이며, 몇 가지 흥미로운 점을 보여줍니다.
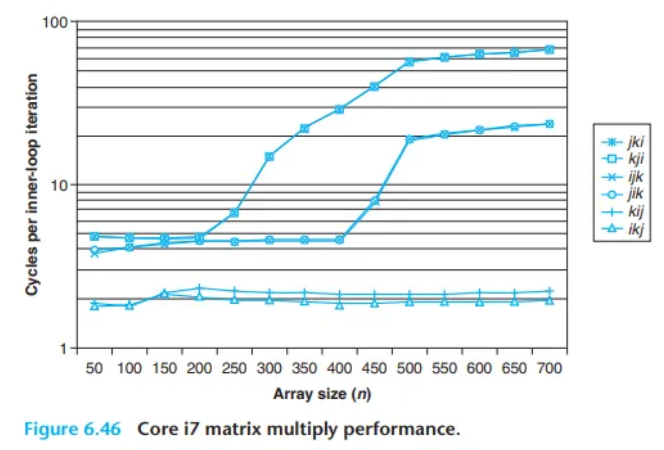
- 압도적인 성능 차이: 큰
n값에 대해, 가장 빠른 버전(kij,ikj)은 가장 느린 버전(jki,kji)보다 거의 40배 더 빠르게 실행됩니다. 두 버전이 동일한 수의 부동소수점 연산을 수행함에도 불구하고 말입니다. - 이론과 실제의 일치: 이론적으로 동일한 메모리 참조 및 미스율을 가진 버전 쌍들은 거의 동일한 실제 성능을 보입니다.
- 메모리 접근 패턴의 중요성: 반복당 접근 횟수와 미스율 측면에서 최악의 메모리 동작을 보인 두 버전(클래스 AC)은 다른 네 버전보다 훨씬 느리게 실행됩니다.
- 성능 예측 지표: 이 경우, 미스율이 총 메모리 접근 횟수보다 더 나은 성능 예측 지표입니다. 예를 들어, 반복당 0.5의 미스율을 가진 클래스 BC는, 반복당 더 적은 메모리 참조(2 로드)를 하지만 1.25의 미스율을 가진 클래스 AB보다 훨씬 뛰어난 성능을 보입니다.
- 하드웨어 프리페칭의 위력: 큰
n값에 대해, 가장 빠른 버전(kij,ikj)의 성능은 일정하게 유지됩니다. 배열이 어떤 SRAM 캐시보다 훨씬 큼에도 불구하고, 하드웨어 프리페칭(prefetching) 메커니즘이 스트라이드-1 접근 패턴을 인지하고, 타이트한 내부 루프의 메모리 접근 속도를 따라잡을 만큼 충분히 빠르게 데이터를 미리 가져오기 때문입니다. 이는 프로그래머가 좋은 공간적 지역성을 가진 프로그램을 개발해야 하는 강력한 동기가 됩니다.
6.6.3 프로그램에서 지역성 활용하기 (Exploiting Locality in Your Programs)
지금까지 살펴본 바와 같이, 메모리 시스템은 저장 장치들의 계층 구조로 구성되어 있으며, 상위 계층으로 갈수록 더 작고 빠른 장치가, 하위 계층으로 갈수록 더 크고 느린 장치가 위치합니다.
이러한 계층 구조 때문에, 프로그램이 메모리 위치에 접근할 수 있는 유효 속도는 단 하나의 숫자로 특징지어질 수 없습니다. 오히려, 그 속도는 프로그램의 지역성(locality)에 따라 수십 배까지 차이가 날 수 있는, 매우 변동이 심한 함수(우리가 '메모리 마운틴'이라 불렀던 것)입니다. 좋은 지역성을 가진 프로그램은 데이터의 대부분을 빠른 캐시 메모리에서 접근하고, 나쁜 지역성을 가진 프로그램은 데이터의 대부분을 상대적으로 느린 DRAM 메인 메모리에서 접근합니다.
메모리 계층 구조의 본질을 이해하는 프로그래머는 이러한 이해를 활용하여, 특정 메모리 시스템의 구조와 상관없이 더 효율적인 프로그램을 작성할 수 있습니다. 특히, 다음과 같은 기법들을 권장합니다.
- 계산과 메모리 접근의 대부분이 발생하는 내부 루프(inner loops)에 집중하십시오. 프로그램의 성능은 대부분 이 작은 코드 영역에서 결정됩니다.
- 데이터가 메모리에 저장된 순서대로, 스트라이드-1(stride 1)을 유지하며 순차적으로 데이터 객체를 읽음으로써 프로그램의 공간적 지역성(spatial locality)을 극대화하도록 노력하십시오.
- 일단 메모리에서 데이터를 읽어온 후에는, 해당 데이터 객체를 가능한 한 자주 재사용함으로써 프로그램의 시간적 지역성(temporal locality)을 극대화하도록 노력하십시오.
6.7 요약 (Summary)
1. 기본 저장 기술 (Basic Storage Technologies)
- RAM (Random Access Memory): 기본적인 저장 기술은 RAM, 비휘발성 메모리(ROM), 그리고 디스크입니다. RAM은 두 가지 기본 형태가 있습니다.
- SRAM (정적 RAM): 더 빠르고 비싸며, 캐시 메모리로 사용됩니다.
- DRAM (동적 RAM): 더 느리고 저렴하며, 메인 메모리와 그래픽 프레임 버퍼로 사용됩니다.
- ROM (비휘발성 메모리): 전원이 꺼져도 정보를 유지합니다. 펌웨어(firmware)를 저장하는 데 사용됩니다.
- 디스크 (Disks):
- 회전식 디스크 (HDD): 기계적인 비휘발성 저장 장치로, 비트당 비용이 저렴하여 막대한 양의 데이터를 저장할 수 있지만 DRAM보다 접근 시간이 훨씬 깁니다.
- SSD (Solid State Disk): 비휘발성 플래시 메모리 기반의 저장 장치로, 특정 응용 분야에서 회전식 디스크의 매력적인 대안으로 점점 더 부상하고 있습니다.
2. 메모리 계층 구조의 필요성 및 원리
일반적으로, 더 빠른 저장 기술은 비트당 비용이 더 비싸고 용량이 더 작습니다. 이러한 기술들의 가격과 성능 특성은 극적으로 다른 속도로 변화하고 있습니다. 특히, DRAM과 디스크의 접근 시간은 CPU 사이클 시간보다 훨씬 깁니다.
시스템은 이러한 성능 격차를 해소하기 위해, 상위 계층에는 더 작고 빠른 장치를, 하위 계층에는 더 크고 느린 장치를 두는 메모리 계층 구조(hierarchy of storage devices)로 메모리를 구성합니다. 잘 작성된 프로그램은 좋은 지역성(locality)을 가지기 때문에, 대부분의 데이터는 상위 계층에서 처리됩니다. 그 결과, 전체 메모리 시스템은 하위 계층의 비용과 용량을 가지면서도, 상위 계층의 속도로 실행되는 효과를 얻게 됩니다.
3. 프로그래머의 역할
프로그래머는 좋은 공간적 및 시간적 지역성을 가진 프로그램을 작성함으로써 프로그램의 실행 시간을 획기적으로 향상시킬 수 있습니다. 특히 SRAM 기반의 캐시 메모리를 활용하는 것이 중요합니다. 데이터를 주로 캐시 메모리에서 가져오는 프로그램은, 데이터를 주로 메인 메모리에서 가져오는 프로그램보다 훨씬 더 빠르게 실행될 수 있습니다.
2.1 운영체제 소개: 가상화의 개념 정리
해당 내용은 운영체제의 핵심적인 역할과 기본 원리, 특히 '가상화'에 대해 설명하고 있습니다. 주요 내용을 아래와 같이 자세히 정리했습니다.
1. 프로그램 실행의 기본 원리
컴퓨터 프로그램이 실행될 때의 가장 기본적인 동작은 CPU(프로세서)가 명령어를 처리하는 것입니다. 이 과정은 다음과 같은 주기로 반복됩니다.
- 반입 (Fetch): 메모리에서 다음 실행할 명령어를 가져옵니다.
- 해석 (Decode): 가져온 명령어가 무엇을 하는 것인지 파악합니다.
- 실행 (Execute): 해석된 명령어에 따라 실제 연산(두 수의 덧셈, 메모리 접근, 조건 검사 등)을 수행합니다.
이 과정이 초당 수십억 번 반복되며 프로그램이 종료될 때까지 계속됩니다. 이는 폰 노이만 컴퓨팅 모델(Von Neumann computing model)의 기초입니다.
2. 운영체제(OS)의 역할
단순한 명령어 실행만으로는 복잡한 현대 컴퓨터 시스템을 사용하기 어렵습니다. 이때 운영체제(Operating System, OS)가 시스템을 사용하기 쉽고, 편리하며, 올바르게 동작하도록 만드는 역할을 합니다.
운영체제의 주요 역할은 다음과 같습니다.
- 사용의 용이성 제공:
- 여러 프로그램을 동시에 실행할 수 있게 합니다.
- 프로그램 간 메모리 공유를 가능하게 합니다.
- 하드웨어 장치(디스크, 키보드 등)와의 상호작용을 쉽게 만듭니다.
- 자원 관리자 (Resource Manager):
- CPU, 메모리, 디스크와 같은 시스템의 물리적 자원을 관리합니다.
- 여러 프로그램이 이 자원들을 효율적이고 공정하게 나눠 쓸 수 있도록 제어합니다.
3. 핵심 기법: 가상화(Virtualization)
운영체제는 위와 같은 역할을 수행하기 위해 가상화(Virtualization)라는 핵심 기법을 사용합니다.
- 정의: CPU, 메모리, 디스크와 같은 물리적 자원(physical resource)을 이용해, 더 사용하기 편리하고 강력한 가상 자원(virtual resource)을 생성하는 기술입니다.
- OS = 가상 머신(Virtual Machine): 가상화를 통해 물리적 하드웨어를 추상화하여 사용자 프로그램에게 제공하므로, 운영체제를 일종의 '가상 머신'이라고 부르기도 합니다.
- API 제공: 프로그램이 OS가 제공하는 가상 자원과 기능들을 사용할 수 있도록 시스템 콜(System Call)이라는 형태의 API를 수백 개 제공합니다. 이 때문에 OS가 표준 라이브러리(Standard Library)를 제공한다고도 말합니다.
4. CPU 가상화 예시
본문은 운영체제의 핵심 질문인 "어떻게 자원을 가상화하는가?"에 대한 답을 찾기 위해 CPU 가상화를 첫 번째 예시로 듭니다.
- 상황: CPU가 하나뿐인 시스템에서 4개의 동일한 프로그램(
cpu.c)을 동시에 실행시킵니다. (./cpu A & ; ./cpu B & ; ./cpu C & ; ./cpu D &) - 결과: 각 프로그램의 출력(A, B, C, D)이 번갈아 가며 나타납니다.
- 분석: 실제 물리적인 CPU는 하나지만, 사용자에게는 마치 4개의 프로그램이 동시에 실행되는 것처럼 보이는 환상(illusion)을 만들어 냅니다.
이것이 바로 CPU 가상화(Virtualizing the CPU)입니다. 운영체제는 하드웨어의 도움을 받아 하나의 물리적 CPU를 마치 여러 개의 가상 CPU가 있는 것처럼 보이게 만들어, 다수의 프로그램을 동시에 실행시킬 수 있게 합니다.
5. 정책(Policy)과 메커니즘(Mechanism)
CPU 가상화는 새로운 문제를 야기합니다. 예를 들어, 동시에 여러 프로그램이 실행되길 원할 때, "어떤 프로그램을 먼저 실행시킬 것인가?" 라는 결정의 문제가 생깁니다.
- 정책 (Policy): "무엇을 할 것인가"에 대한 결정. 즉, 여러 선택지 중 어떤 것을 고를지에 대한 규칙입니다. (예: 어떤 프로세스에 CPU를 할당할지 결정하는 스케줄링 알고리즘)
- 메커니즘 (Mechanism): "어떻게 할 것인가"에 대한 구현. 즉, 정책에 따라 결정된 사항을 실제로 수행하는 방법 및 기술입니다. (예: 한 프로세스에서 다른 프로세스로 CPU 제어권을 넘기는 문맥 교환 기술)
운영체제는 이러한 정책과 메커니즘을 통해 자원을 효과적으로 관리합니다.
2. 2 운영체제 소개: 메모리 가상화 정리
이어서 제공된 내용은 CPU 가상화에 이어 운영체제의 또 다른 핵심 기능인 메모리 가상화에 대해 설명하고 있습니다. 주요 내용을 아래와 같이 자세히 정리했습니다.
1. 물리 메모리의 기본 모델
- 구조: 컴퓨터의 물리 메모리(physical memory)는 기본적으로 거대한 바이트의 배열(array of bytes)과 같습니다.
- 접근 방식: 특정 데이터를 읽거나 쓰기 위해서는 해당 데이터가 저장된 고유한 주소(address)를 명시해야 합니다.
- 중요성: 프로그램은 실행되는 동안 명령어(code)와 데이터(자료 구조)를 모두 메모리에 저장하고 끊임없이 접근하기 때문에 메모리 관리는 매우 중요합니다.
2. 예제 프로그램(mem.c)과 핵심 질문
본문은 메모리 할당(malloc) 후 해당 주소의 값을 1초마다 1씩 증가시키는 간단한 C 프로그램(mem.c)을 예시로 듭니다.
- 단일 실행: 프로그램을 한 번 실행하면, 특정 메모리 주소(예:
0x200000)를 할당받아 그곳의 값을 계속 증가시킵니다. 이 과정은 예상대로 동작합니다. - 동시 실행 및 의문점:
- 현상: 같은 프로그램을 동시에 두 번 실행하면 놀라운 결과가 나타납니다. 두 프로그램 모두 완전히 동일한 메모리 주소(
0x200000)를 할당받았다고 출력합니다. - 독립적 동작: 만약 두 프로그램이 정말로 같은 물리 메모리 주소를 공유한다면, 한쪽이 값을 1로 바꾸면 다른 쪽은 그 값을 2로 바꿔야 합니다. 하지만 실행 결과는 다릅니다. 각 프로그램은 서로에게 전혀 영향을 주지 않고, 각자의 공간에서 값을 1, 2, 3... 으로 독립적으로 증가시킵니다.
- 핵심 질문: 어떻게 두 개의 다른 프로세스가 동일한 메모리 주소를 사용하면서도 서로 충돌하지 않고 독립적으로 데이터를 변경할 수 있는가?
- 현상: 같은 프로그램을 동시에 두 번 실행하면 놀라운 결과가 나타납니다. 두 프로그램 모두 완전히 동일한 메모리 주소(
3. 해답: 메모리 가상화 (Virtualizing Memory)
이러한 현상이 가능한 이유는 운영체제가 메모리 가상화를 제공하기 때문입니다.
- 가상 주소 공간 (Virtual Address Space): 운영체제는 실행되는 각 프로세스에게 독립적인 자신만의 가상 주소 공간을 제공합니다. 프로그램 내에서 보이는 주소
0x200000는 실제 물리 메모리 주소가 아닌, 이 가상 주소 공간 상의 주소입니다. - 매핑 (Mapping): 운영체제는 각 프로세스의 가상 주소 공간을 컴퓨터의 물리 메모리의 서로 다른 위치로 연결(mapping)합니다.
- 예를 들어, 프로세스 A의 가상 주소
0x200000는 물리 메모리의1000번지에 매핑될 수 있습니다. - 동시에 실행된 프로세스 B의 가상 주소
0x200000는 물리 메모리의5000번지에 매핑될 수 있습니다.
- 예를 들어, 프로세스 A의 가상 주소
- 결과 (환상 제공): 이 매핑 과정 덕분에 각 프로세스는 자기 자신만의 거대한 물리 메모리를 단독으로 사용하는 것 같은 환상(illusion)을 갖게 됩니다. 실제로는 여러 프로세스가 하나의 물리 메모리를 공유하고 있지만, 운영체제의 가상화 덕분에 서로의 메모리 공간을 침범하지 않고 안전하게 프로그램을 실행할 수 있습니다.
2.3 운영체제 소개: 병행성(Concurrency) 문제 정리
이번 내용은 운영체제의 세 번째 주요 주제인 병행성(Concurrency)에 대해 설명하고 있습니다. 앞서 다룬 가상화가 '하나의 자원을 여러 개처럼' 보이게 하는 기술이라면, 병행성은 '여러 작업을 동시에 처리할 때' 발생하는 문제와 그 해결법에 관한 것입니다.
1. 병행성(Concurrency)의 정의와 발생
- 정의: 여러 작업(프로세스, 쓰레드 등)이 동시에 실행될 때 발생하는 상호작용과 그로 인한 문제들을 다루는 분야입니다.
- 발생 지점:
- 운영체제 자체: OS는 여러 프로세스를 번갈아 실행시키며 CPU 가상화를 구현합니다. 이 과정 자체가 병행성을 관리하는 것입니다.
- 멀티쓰레드 프로그램: 사용자가 작성한 프로그램 내에서 여러 개의 쓰레드가 하나의 메모리 공간을 공유하며 동시에 실행될 때 병행성 문제가 명확하게 드러납니다.
2. 예제 프로그램(threads.c) 심층 분석
본문은 공유 변수 counter를 두 개의 쓰레드가 동시에 증가시키는 간단한 프로그램을 통해 병행성 문제의 심각성을 보여줍니다.
가. 프로그램의 목적 및 구조
- 전역 변수
counter를 0으로 초기화합니다. - 두 개의 쓰레드(
p1,p2)를 생성합니다. - 각 쓰레드는
worker함수를 실행하여,loops번 만큼counter의 값을 1씩 증가시킵니다. - 두 쓰레드가 모두 종료되면 최종
counter값을 출력합니다.
나. 예상 결과와 실제 결과의 차이
- 예상: 두 쓰레드가 각각
loops번씩counter를 증가시키므로, 최종 값은 2 *loops가 되어야 합니다. - 실제 (loops 값이 작을 때):
loops = 1000일 때, 예상대로2000이 출력됩니다. - 실제 (loops 값이 클 때):
loops = 100000일 때, 예상 값인200000이 아닌143012,137298등 예측할 수 없는 잘못된 값이 출력됩니다. 심지어 실행할 때마다 결과가 달라집니다.
3. 문제의 근본 원인: 원자성(Atomicity)의 부재
이처럼 예상치 못한 결과가 나오는 이유는, 우리가 한 줄의 코드로 생각하는 counter++ 연산이 CPU 수준에서는 원자적(Atomic)으로 실행되지 않기 때문입니다. 즉, counter++는 한번에 실행되는 단일 명령어가 아니라, 다음과 같은 여러 개의 기계어 명령어로 나뉘어 실행됩니다.
- LOAD: 메모리에 있는
counter변수의 값을 CPU 내의 임시 저장 공간인 레지스터(Register)로 읽어온다. - INCREMENT: 레지스터에 있는 값을 1 증가시킨다.
- STORE: 레지스터에 있는 새로운 값을 다시 메모리의
counter변수에 덮어쓴다.
이 세 단계가 실행되는 도중에 다른 쓰레드로 제어권이 넘어갈 수 있기 때문에 문제가 발생합니다. 아래는 두 쓰레드가 충돌하는 최악의 시나리오입니다.
| 시간 | 쓰레드 1 (in CPU) | 쓰레드 2 (Waiting) | 메모리 counter 값 | 설명 |
|---|---|---|---|---|
| T1 | 1. LOAD (counter=50) -> Reg1=50 | 대기 중 | 50 | 쓰레드 1이 메모리에서 50을 읽음 |
| T2 | (Context Switch 발생!) 일시 정지 | 1. LOAD (counter=50) -> Reg2=50 | 50 | OS가 쓰레드 2로 실행 전환. 쓰레드 2도 메모리에서 아직 50을 읽음 |
| T3 | 일시 정지 | 2. INCREMENT -> Reg2=51 | 50 | 쓰레드 2가 자신의 레지스터 값을 51로 증가시킴 |
| T4 | 일시 정지 | 3. STORE -> (counter=51) | 51 | 쓰레드 2가 51을 메모리에 저장함 |
| T5 | (Context Switch 발생!) 다시 실행 | 일시 정지 | 51 | OS가 다시 쓰레드 1로 실행 전환 |
| T6 | 2. INCREMENT -> Reg1=51 | 일시 정지 | 51 | 쓰레드 1은 T1에서 읽었던 50을 기준으로 자신의 레지스터 값을 51로 증가시킴 |
| T7 | 3. STORE -> (counter=51) | 일시 정지 | 51 | 쓰레드 1이 51을 메모리에 덮어씀 |
결과: 두 개의 쓰레드가 각각 counter++를 실행했지만, 최종 counter 값은 52가 아닌 51이 되었습니다. 한 번의 증가 연산이 누락(lost update)된 것입니다. 이런 현상이 수만 번 반복되면서 최종 결과값이 200,000보다 훨씬 작아지는 것입니다.
4. 핵심 질문 및 해결 방향
이러한 문제를 해결하기 위해 책은 다음과 같은 핵심 질문을 던집니다.
"올바르게 동작하는 병행 프로그램을 어떻게 작성해야 하는가?"
이를 해결하기 위해서는 다음과 같은 요소들이 필요하며, 이것이 앞으로 배울 내용의 핵심입니다.
- 운영체제의 지원: 락(Lock), 세마포어(Semaphore) 등 여러 쓰레드가 공유 자원에 안전하게 접근하도록 제어하는 동기화(Synchronization) 기법들을 제공해야 합니다.
- 하드웨어의 지원: 특정 메모리 연산을 누구의 방해도 받지 않고 원자적으로 처리할 수 있는 특별한 하드웨어 명령어가 필요할 수 있습니다.
- 프로그래머의 역할: 제공된 기법들을 올바르게 사용하여 공유 자원에 접근하는 코드 영역, 즉 임계 구역(Critical Section)을 보호해야 합니다. 위 예제에서는
counter++가 임계 구역에 해당합니다.
2.4 운영체제 소개: 영속성(Persistence) 정리
이번 내용은 운영체제의 세 번째 주요 주제인 영속성(Persistence)에 대해 설명합니다. 이는 데이터가 전원이 꺼지거나 시스템이 고장 나도 사라지지 않고 영구적으로 저장되도록 하는 기술에 관한 것입니다.
1. 영속성(Persistence)의 필요성
- 문제점: 컴퓨터의 주 기억장치인 메모리(DRAM)는 휘발성(volatile)입니다. 즉, 전원 공급이 중단되면 저장된 모든 데이터가 사라집니다.
- 필요성: 따라서 작업한 내용이나 중요한 데이터를 영구적으로 보존하기 위한 방법이 반드시 필요합니다.
2. 해결책: 하드웨어와 소프트웨어
- 하드웨어: 데이터를 영속적으로 저장하기 위해 하드 드라이브(HDD)나 SSD(Solid-State Drive)와 같은 비휘발성 저장 장치를 사용합니다. 이들은 입출력(I/O) 장치의 한 종류입니다.
- 소프트웨어: 운영체제 내에서 이러한 저장 장치를 관리하고, 파일(file)을 생성, 수정, 삭제하는 등의 작업을 체계적으로 처리하는 소프트웨어 부분을 파일 시스템(File System)이라고 부릅니다.
3. 파일 시스템의 특징: 공유 (Sharing)
파일 시스템은 CPU나 메모리 가상화와는 다른 중요한 특징을 가집니다.
- 가상화와의 차이점: CPU나 메모리 가상화는 각 프로세스에게 독립적인 '가상' 자원을 할당하여 서로를 격리하는 것이 목적이었습니다.
- 파일 시스템의 목적: 반면, 파일 시스템은 격리가 아니라 공유(Sharing)를 기본 전제로 설계되었습니다. 여러 다른 프로세스가 동일한 파일에 접근하고 사용하는 상황이 매우 흔하기 때문입니다.
- 예시 (컴파일 과정):
emacs(텍스트 에디터 프로세스)가main.c라는 소스 코드 파일을 생성합니다.gcc(컴파일러 프로세스)가main.c파일을 읽어서main이라는 실행 파일을 생성합니다.- 사용자는 셸(Shell)을 통해
./main명령으로main실행 파일을 실행하여 새로운 프로세스를 만듭니다.
- 이처럼 에디터, 컴파일러, 셸 등 여러 프로세스가 파일이라는 매개체를 통해 순차적으로 상호작용합니다.
4. 파일 I/O의 이면: 복잡성
사용자가 open(), write(), close()와 같은 간단한 시스템 콜을 호출하여 파일을 다루지만, 그 이면에서 파일 시스템은 매우 복잡한 작업을 수행합니다.
- 데이터 위치 결정: 새로 작성된 데이터를 디스크의 물리적인 공간 어디에 저장할지 결정합니다.
- 메타데이터 관리: 파일의 이름, 크기, 위치, 권한 등의 정보를 담고 있는 파일 시스템 내부의 자료 구조(메타데이터)를 읽고 갱신합니다.
- 하드웨어 제어: 저수준의 장치 드라이버(Device Driver)를 통해 실제 저장 장치와 통신하여 데이터를 읽고 쓰는 작업을 수행합니다. 운영체제는 이 복잡한 과정을 표준화된 시스템 콜로 추상화하여 제공합니다.
5. 핵심 과제: 성능과 안정성의 균형
파일 시스템이 직면한 가장 큰 과제 중 하나는 I/O 성능과 데이터 안정성 사이의 균형을 맞추는 것입니다.
- 성능 향상 기법 (Write Buffering): 파일에 데이터를 쓸 때(
write()) 즉시 디스크에 기록하지 않습니다. 디스크 I/O는 매우 느린 작업이므로, 여러 쓰기 요청을 메모리의 버퍼(buffer)에 모았다가 한꺼번에 처리하는 것이 훨씬 효율적입니다. - 치명적인 위험: 이 방식은 지연 시간을 만듭니다. 만약
write()요청이 버퍼에만 기록되고 아직 실제 디스크에 쓰이기 전에 시스템이 갑자기 꺼지거나 고장 나면, 해당 데이터는 영구적으로 손실됩니다 (Lost Update). - 더 심각한 문제: 데이터의 일부만 기록되거나, 쓰기 순서가 뒤바뀌어 파일 시스템의 전체 구조가 깨지는 불일치(inconsistency) 상태가 발생할 수도 있습니다.
- 안정성 확보 기술: 이러한 시스템 고장에 대비하여 많은 현대 파일 시스템은 다음과 같은 고급 기법들을 사용합니다.
- 저널링 (Journaling): 변경 사항을 실제 데이터에 반영하기 전에 '저널'이라는 특별한 로그 영역에 먼저 기록합니다. 고장이 발생하면 이 로그를 보고 시스템을 일관된 상태로 신속하게 복구할 수 있습니다.
- 쓰기-시-복사 (Copy-on-Write, CoW): 데이터를 수정할 때 원본을 덮어쓰는 대신, 수정된 내용의 복사본을 새로운 위치에 씁니다. 모든 쓰기가 완료된 후에야 메타데이터가 새 위치를 가리키도록 변경하여, 쓰기 도중 고장이 나도 원본 데이터는 안전하게 보존됩니다.
2.5 운영체제(OS)의 설계 목표 정리
이 내용은 앞서 설명한 가상화, 병행성, 영속성 등의 기능을 구현할 때 운영체제 설계자들이 반드시 고려해야 할 핵심적인 목표들을 설명합니다. 적절한 목표 설정은 시스템의 방향을 정하고, 여러 목표가 충돌할 때 합리적인 절충안(trade-off)을 찾는 데 필수적입니다.
1. 추상화 (Abstraction)
- 목표: 복잡한 하드웨어나 저수준의 동작을 숨기고, 개발자와 사용자가 시스템을 편리하고 쉽게 사용할 수 있도록 만드는 것입니다.
- 설명: 추상화는 컴퓨터 과학의 근간을 이루는 개념입니다. 우리가 C언어로 프로그래밍할 때 어셈블리어를 몰라도 되는 것처럼, 운영체제는 프로세스, 가상 주소 공간, 파일과 같은 추상적인 개념을 제공하여 복잡한 물리 자원을 직접 다루지 않아도 되게 해줍니다. 이를 통해 거대한 시스템을 이해하기 쉬운 작은 부분들로 나누어 개발하고 사용할 수 있습니다.
2. 성능 (Performance)
- 목표: 운영체제가 제공하는 추상화와 각종 기능들이 시스템에 주는 부담, 즉 오버헤드(Overhead)를 최소화하는 것입니다.
- 설명: 가상화나 편리한 API는 매우 유용하지만, 이 기능들을 구현하느라 시스템의 전반적인 속도가 크게 느려진다면 의미가 없습니다. 오버헤드는 추가적인 CPU 연산 시간이나 더 많은 메모리/디스크 공간 사용의 형태로 나타납니다. 운영체제 설계의 핵심 과제는 유용한 기능을 제공하면서도 이러한 오버헤드를 최소화하는 효율적인 해결책을 찾고, 때로는 기능과 성능 사이에서 적절한 절충안을 선택하는 것입니다.
3. 보호 (Protection)
- 목표: 여러 프로그램이 동시에 실행될 때, 하나의 프로그램이 다른 프로그램이나 운영체제 자신에게 악의적이거나 의도치 않은 피해를 주지 못하도록 막는 것입니다.
- 설명: 이는 고립(Isolation) 원칙의 핵심입니다. 운영체제는 각 프로세스가 자신만의 독립된 메모리 공간과 자원을 가진 것처럼 동작하게 하여, 특정 프로세스의 오류가 다른 프로세스나 시스템 전체의 안정성을 해치지 않도록 보장해야 합니다.
4. 신뢰성 (Reliability)
- 목표: 운영체제가 멈추지 않고 계속해서 안정적으로 실행되도록 보장하는 것입니다.
- 설명: 운영체제는 모든 응용 프로그램의 기반이 되기 때문에, 만약 운영체제가 실패(crash)하면 그 위에서 실행 중인 모든 프로그램도 함께 실패하게 됩니다. 수백만 줄의 코드로 이루어진 복잡한 소프트웨어인 운영체제를 높은 수준의 신뢰성을 갖도록 만드는 것은 매우 어렵고 중요한 목표입니다.
5. 기타 중요한 목표들
시스템의 사용 목적에 따라 다음과 같은 추가적인 목표들이 중요해질 수 있습니다.
- 에너지 효율성 (Energy-efficiency): 특히 모바일 장치나 데이터 센터에서 전력 소비를 최소화하는 것이 중요합니다.
- 보안 (Security): 보호의 확장된 개념으로, 네트워크 환경에서 악의적인 공격으로부터 시스템과 데이터를 지키는 것을 목표로 합니다.
- 이동성 (Mobility): 스마트폰이나 태블릿과 같은 소형 장치에서 운영체제가 효율적으로 동작하도록 하는 것입니다.
2.6 운영체제(OS)의 역사적 배경 정리
이 내용은 운영체제가 초기의 단순한 프로그램 보조 도구에서 오늘날의 복잡하고 강력한 시스템 소프트웨어로 발전해 온 역사를 시대별로 요약하고 있습니다.
1. 초창기 운영체제: 단순 라이브러리
- 형태: 자주 사용되는 기능(특히 저수준 입출력)을 모아놓은 라이브러리에 불과했습니다. 프로그래머가 모든 것을 직접 만드는 수고를 덜어주는 역할이었습니다.
- 운영 방식: 사람이 직접 컴퓨터 관리자 역할을 했습니다. 실행할 프로그램의 순서를 정하고, 하나씩 기계에 넣어 실행하는 일괄 처리(Batch Processing) 방식이었습니다.
- 시대적 배경: 컴퓨터가 매우 고가였기 때문에, 사람이 컴퓨터 앞에서 대화하며 사용하는 것은 상상할 수 없었습니다. 기계를 쉬게 두는 것은 엄청난 비용 낭비였으므로, 기계의 효율을 최우선으로 고려했습니다.
2. 라이브러리를 넘어서: 보호(Protection)의 등장
- 문제 제기: OS가 단순 라이브러리라면, 모든 응용 프로그램이 디스크 같은 하드웨어에 직접 접근할 수 있습니다. 이는 다른 사용자의 파일을 마음대로 읽는 등 심각한 개인정보 및 데이터 보호 문제를 야기합니다.
- 혁신적 발명: 시스템 콜(System Call)
- OS 코드와 일반 사용자 코드를 명확히 구분하는 개념이 도입되었습니다.
- 사용자 모드(User Mode): 일반 응용 프로그램이 실행되는 상태. 하드웨어적으로 기능이 제한됩니다 (예: 디스크 직접 접근 불가).
- 커널 모드(Kernel Mode): 운영체제 코드가 실행되는 상태. 시스템의 모든 하드웨어에 대한 완전한 제어 권한을 가집니다.
- 모드 전환: 프로그램이 OS의 기능(예: 파일 쓰기)을 사용하려면, 트랩(trap)이라는 특별한 하드웨어 명령어를 호출합니다. 이 명령어는 CPU의 모드를 '사용자 모드'에서 '커널 모드'로 격상시키고, 제어권을 OS에게 넘깁니다. OS가 작업을 완료하면 return-from-trap 명령어로 다시 '사용자 모드'로 복귀하여 프로그램 실행을 이어갑니다.
3. 멀티프로그래밍(Multiprogramming) 시대
- 시대적 배경: 미니컴퓨터(minicomputer)의 등장으로 컴퓨터 가격이 하락하며 더 많은 개발자들이 시스템을 활용하게 되었습니다.
- 핵심 기술: 멀티프로그래밍
- CPU의 효율을 극대화하기 위해, 여러 개의 프로그램(작업)을 동시에 메모리에 올려놓고 빠르게 번갈아 가며 실행하는 기법입니다.
- 특히 한 프로그램이 느린 입출력(I/O) 작업을 기다리는 동안, CPU가 다른 프로그램을 실행함으로써 CPU가 노는 시간을 없애는 것이 핵심이었습니다.
- 새로운 과제:
- 메모리 보호: 한 프로그램이 다른 프로그램의 메모리 영역을 침범하지 못하도록 막는 기술이 중요해졌습니다.
- 병행성(Concurrency): 여러 작업이 뒤섞여 실행될 때 발생하는 복잡한 문제들을 해결해야 했습니다.
- 중요한 등장: Unix 운영체제
- Ken Thompson과 Dennis Ritchie가 개발한 Unix는 기존 OS들의 좋은 아이디어를 단순하고 강력하게 통합했습니다.
- 소스 코드가 널리 공유되면서 전 세계 개발자들이 기능 개선에 참여하는 오픈소스 문화의 시초가 되었습니다.
4. 현대: 개인용 컴퓨터(PC) 시대와 그 이후
- 초기 PC 시대의 퇴보: Apple II, IBM PC의 등장으로 개인용 컴퓨터 시대가 열렸지만, 초기 PC 운영체제(MS-DOS, 초기 Mac OS 등)는 미니컴퓨터 시대에 쌓아온 중요한 기술들을 무시했습니다.
- MS-DOS: 메모리 보호 기능이 없어, 잘못된 프로그램 하나가 시스템 전체를 다운시킬 수 있었습니다.
- 초기 Mac OS: 협업 스케줄링 방식을 사용해, 프로그램이 자발적으로 CPU를 양보해야만 다른 작업이 가능했습니다. 무한 루프에 빠진 프로그램 하나가 시스템 전체를 멈추게 했습니다.
- 암흑기 이후의 발전: 다행히 시간이 지나면서 미니컴퓨터 시대의 견고한 OS 기술들이 PC 운영체제에 다시 도입되었습니다.
- Mac OS X (현 macOS): Unix를 기반으로 재탄생했습니다.
- Windows: Windows NT를 기점으로 메모리 보호, 선점형 스케줄링 등 현대적인 OS 기술을 대거 채택했습니다.
- 현재: 오늘날의 스마트폰에 탑재된 OS(Linux 기반의 Android, Unix 기반의 iOS)조차 1980년대의 초기 PC용 OS보다 1970년대의 미니컴퓨터용 OS에 기술적으로 더 가깝습니다. 이는 잘 설계된 운영체제의 핵심 아이디어들이 시대를 초월하여 여전히 유효함을 보여줍니다.
