
Implicit 메모리 할당기 구현하기
Implicit 메모리 할당기에 대해 알아봅시다!
명시적으로 자료구조를 선언하지 않기 때문에 Implicit(묵시적) 할당기라고 부릅니다.
alloc + free 블록을 사이즈를 포함하는 헤더 정보를 이용하여 뛰어다니는 매커니즘으로 동작합니다.
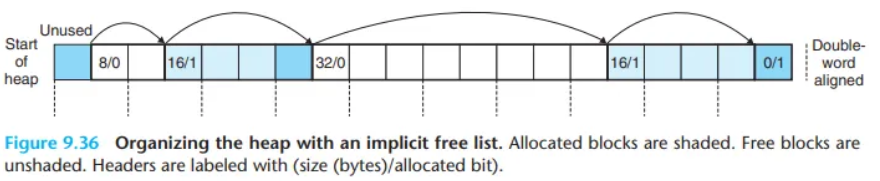
이런식으로 말이죠!
CSAPP에서 예시 코드를 제공하고 있는데 이를 설명해볼까 합니다.
그 전에 알아야 할 것들을 정리해봅시다.
위에서는 헤더 정보에 대한 이야기만 했지만 이번 예시에서는 푸터(footer)가 존재하는 블록을 기준으로 이야기합니다.
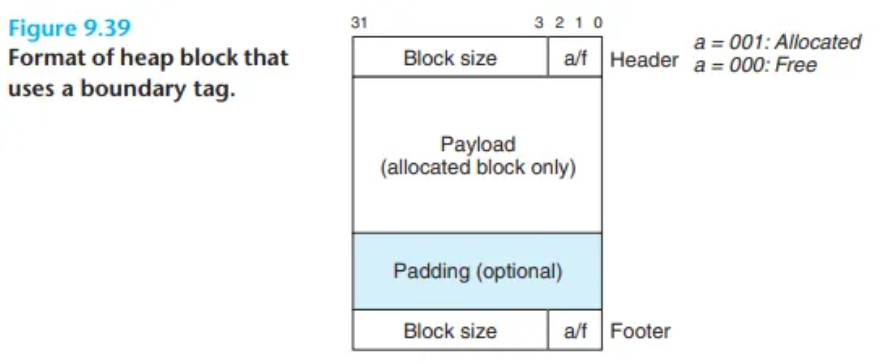
32비트 체계이며 워드 사이즈가 4임을 잊으면 안됩니다!
double형과 같은 8바이트 자료형 때문에 패딩을 고려하여야 합니다. 즉, 주소는 8의 배수여야 합니다.
헤더와 푸터는 각 1 워드 = 4바이트 입니다.
최소 블럭의 크기는 헤더 + 푸터 + 페이로드 (4 + 4+ 8 = 16) 입니다.
할당한 공간의 데이터를 payload라고 부릅니다.
→ 1바이트만 필요하더라도 주소는 8의 배수여야 하기 때문에 8바이트를 할당 받습니다.
블럭 사이즈 또한 8의 배수임을 예측할 수 있을 것입니다! 그런데 여기서 아주 똑똑한 아이디어가 나옵니다. 사이즈가 무조건 8의 배수라면 하위 3비트는 무조건 000입니다. 따라서 이를 이용하여 현재 블럭이 할당됐는지!(001) 할당되지 않았는지!(000) 구분할 수 있도록 합니다.
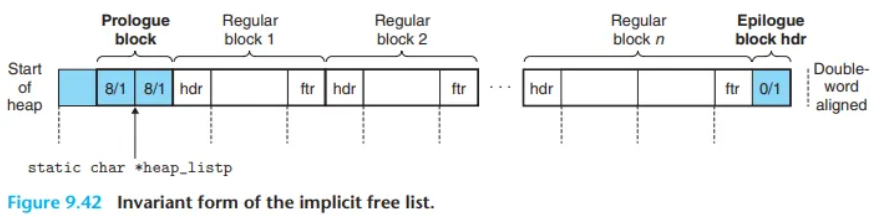
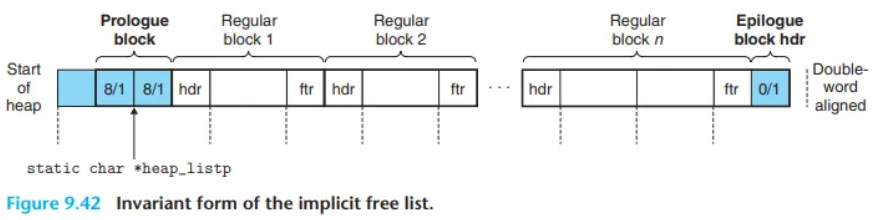
시작을 알리는 프롤로그 블록이 존재합니다. 이는 페이로드가 필요없기 때문에 헤더, 푸터만 존재하며 최종적으로 2워드(=8 바이트)만 할당해주면 됩니다. 절대 해제(free)되지 않는 할당된 메모리 영역입니다! 따라서 블럭의 사이즈는 8, alloc 비트는 1입니다.
끝을 알리는 에필로그 블럭이 존재합니다. 이는 헤더만 있으면 되고(1 워드만 있으면 됨) 사이즈는 0, alloc 비트는 1이 할당됩니다.
초기화를 이렇게 하면 어떤 문제가 생길까요~?
맞습니다! 우리는 주소가 8의 배수여야 한다고 했죠? 하지만 12바이트이므로 8의 배수가 아니게 됩니다. 따라서 맨 앞에 1 워드 크기의 패딩도 넣어줍시다!
마지막으로 heap_listp와 같이 모든 블럭을 가리키는 포인터들은 페이로드의 시작점을 가르키고 있습니다.
Implicit 가정 정리
- 32비트 체계 → 워드 사이즈 = 4 바이트
- 블럭 = 헤더 + 페이로드 + 푸터 → 최소 크기 (16 바이트)
- 헤더 및 푸터에 할당 비트 존재
- 초기화 시 패딩 + 프롤로그(헤더 + 푸터 : 8바이트/alloc bit = 1) + 에필로그(헤더 : 4바이트/alloc bit = 1)
CSAPP에서 정의된 기본 상수 및 매크로 정의
/* Basic constants and macros */
#define WSIZE 4 /* Word and header/footer size (bytes) */
#define DSIZE 8 /* Double word size (bytes) */
#define CHUNKSIZE (1<<12) /* Extend heap by this amount (bytes) */
#define MAX(x, y) ((x) > (y)? (x) : (y))
/* Pack a size and allocated bit into a word */
#define PACK(size, alloc) ((size) | (alloc))
/* Read and write a word at address p */
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
/* Read the size and allocated fields from address p */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
/* Given block ptr bp, compute address of its header and footer */
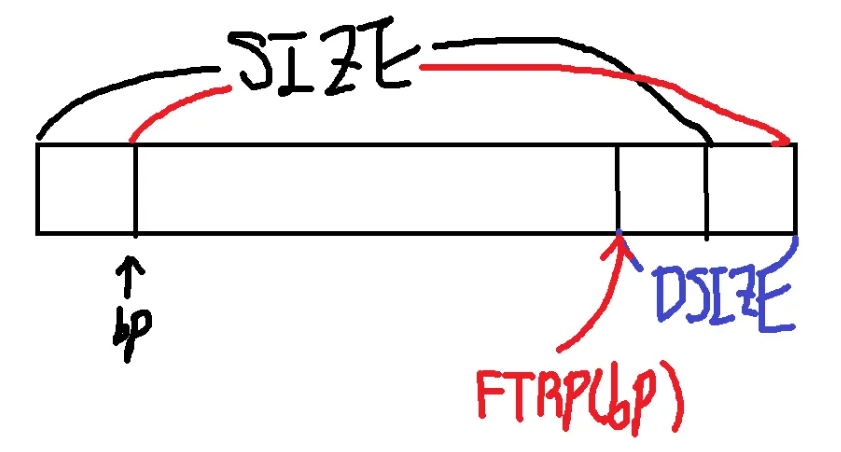
#define HDRP(bp) ((char *)(bp) - WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/* Given block ptr bp, compute address of next and previous blocks */
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))#define WSIZE 4→ 워드 사이즈 4바이트#define DSIZE 8→ 8의 배수 주소를 고려한 더블 워드 사이즈#define PACK(size, alloc) ((size) | (alloc))→ 헤더와 푸터에 적용, 사이즈와 alloc bit#define GET_SIZE(p) (GET(p) & ~0x7)→ 헤더 포인터를 넣었을 때 현재 블럭의 사이즈를 반환#define GET_ALLOC(p) (GET(p) & 0x1)→ 헤더 포인터를 넣었을 때 할당 됐는지 판단#define HDRP(bp) ((char *)(bp) - WSIZE)→ 페이로드 시작점에서 헤더 크기인 WSIZE를 빼주면 현재 블럭의 헤더 포인터를 알 수 있습니다.#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)→ 페이로드 시작점에다가 현재 블럭의 사이즈를 더해주면 현재 블럭의 페이로드가 끝난시점 이후 푸터와 다음 블럭의 헤더만큼 더 나아가 있으므로 (푸터 + 헤더)의 크기인 DSIZE를 빼주면 현재 블럭의 푸터의 포인터 위치를 알 수 있습니다. 아래 그림을 참고 하세요!
mm_init()
int mm_init(void) {
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *) -1)
return -1;
PUT(heap_listp, 0); /* Alignment padding */
PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1)); /* Prologue header */
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1)); /* Prologue footer */
PUT(heap_listp + (3*WSIZE), PACK(0, 1)); /* Epilogue header */
heap_listp += (2 * WSIZE);
/* Extend the empty heap with a free block of CHUNKSIZE bytes */
if (extend_heap(CHUNKSIZE / WSIZE) == NULL)
return -1;
return 0;
}초기화 할 때 (패딩 + 에필로그 + 프롤로그) 총 4워드(=16 바이트)가 필요합니다. 따라서 mem_sbrk(4 * WSIZE) 실행!
PUT(heap_listp, 0)→ 패딩을 위해 heap_listp가 가리키고 있는 부분에 0 삽입!PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1))→ 패딩 1 워드 뒤, 프롤로그 헤더에 사이즈는 DSIZE, alloc bit는 1로 하겠다!- DSIZE인 이유는 헤더와 푸터가 하나의 프롤로그 블럭이며 총 8바이트이기 때문입니다.
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1))→ 패딩 2 워드 뒤, 프롤로그 푸터에 사이즈는 DSIZE, alloc bit는 1로 하겠다!- 마찬가지로 헤더와 푸터가 하나의 블럭이기 때문입니다.
PUT(heap_listp + (3*WSIZE), PACK(0, 1))→ 패딩 3워드 뒤, 에필로그 헤더의 사이즈는 0, alloc bit는 1로 하겠다!- 끝을 알리는 표현입니다.
heap_listp += (2 * WSIZE)→ bp의 시작점은 항상 페이로드의 시작점이라고 했으니 2워드 뒤로 heap_listp를 옮깁시다!extend_heap(CHUNKSIZE / WSIZE) == NULL→ 뒤에서 나오겠지만 extend_heap의 파라미터는 워드 수를 인자로 받습니다. 따라서 전체 크기인 CHUNKSIZE를 WSIZE(워드 사이즈)로 나누면 워드 수가 나오게 됩니다!
extend_heap
static void *extend_heap(size_t words) {
char *bp;
size_t size;
/* Allocate an even number of words to maintain alignment */
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
if ((long) (bp = mem_sbrk(size)) == -1)
return NULL;
/* Initialize free block header/footer and the epilogue header */
PUT(HDRP(bp), PACK(size, 0)); /* Free block header */
PUT(FTRP(bp), PACK(size, 0)); /* Free block footer */
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); /* New epilogue header */
/* Coalesce if the previous block was free */
return coalesce(bp);
}extend_heap은 현재 가용 리스트(free list)에서 적절한 블럭이 없을 경우 힙의 사이즈를 증가시켜주는 함수입니다. 즉, brk를 위로 올려주는 녀석이다~ 생각하면 됩니다!
- brk의 힙의 top을 의미합니다.
파라미터로 워드 수를 인자로 받습니다.
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE→(words % 2): 홀수라면?(words + 1) * WSIZE: 주소를 8의 배수로 맞춰주기 위해(패딩) 워크 개수를 하나 증가시켜서 사이즈 정하기!
- 짝수라면?
words * WSIZE: 이미 8의 배수이므로 워드 수 증가 없음!
bp = mem_sbrk(size)→ 사이즈만큼 brk올리고 기존 brk를 반환합니다. 즉 새로 만들어진 가용공간의 시작점을 반환합니다.PUT(HDRP(bp), PACK(size, 0))→ mem_sbrk에 의해서 새로운 가용 공간이 새로 생성되었습니다. 따라서 새로운 가용 공간에 헤더와 푸터를 넣어주어야 겠죠?- 새로운 공간 헤더에 size크기를 넣고 가용 공간 (alloc bit = 0)으로 하겠다!
PUT(FTRP(bp), PACK(size, 0))→ 새로운 공간 푸터에 size크기를 넣고 가용 공간 (alloc bit = 0)으로 하겠다!PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1))→ 명시적 가용 리스트의 끝을 알리는 에필로그 헤더를 넣어주어야 합니다! 이때 에필로그의 헤더는 다음 블럭의 헤더라고 볼 수 있겠죠?- 다음 블럭의 헤더(에필로그)에 값(사이즈)는 0, alloc bit는 1로 하겠다!
return coalesce(bp)→ 병합하게 있다면 병합해주겠다!
coalesce
일반적으로 특정 포인트를 free하고 병합을 한다고 하면 4가지 케이스가 나올 수 있습니다. (특정 포인트를 x라고 하겠습니다.)
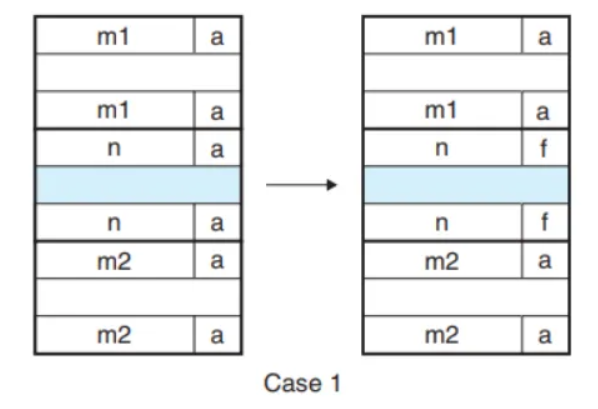
- x의 앞, 뒤 모두 할당 중이라 병합할게 없을 경우
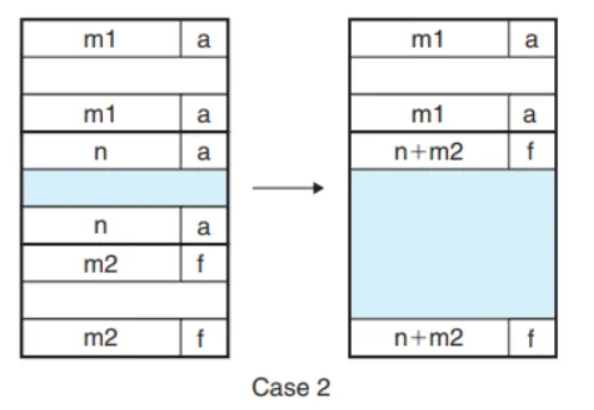
- x의 앞은 할당 중이고 뒤는 가용 가능할 경우
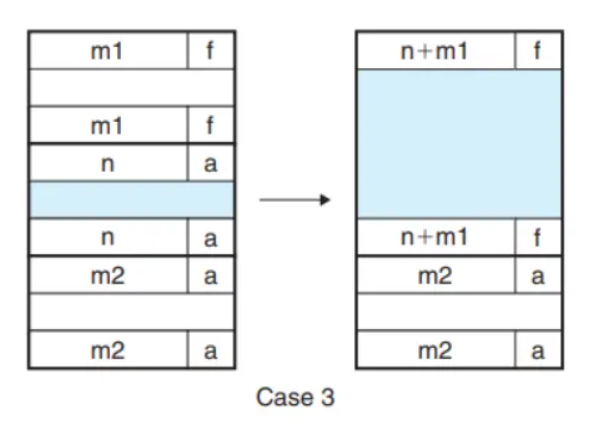
- x의 앞은 가용 가능하고 뒤는 할당 중인 경우
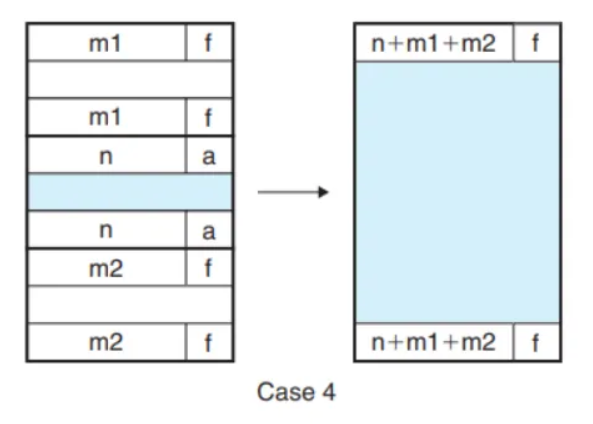
- x의 앞, 뒤 모두 가용 가능할 경우
static void *coalesce(void *bp) {
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc) {
/* Case 1 */
return bp;
}
if (prev_alloc && !next_alloc) {
/* Case 2 */
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
} else if (!prev_alloc && next_alloc) {
/* Case 3 */
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
} else {
/* Case 4 */
size += GET_SIZE(HDRP(PREV_BLKP(bp))) +
GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}코드 분석 고고씽~!
Case 1
if (prev_alloc && next_alloc) {
return bp;
}이전, 다음 블럭 모두 할당이 되어있으면 병합할게 없으니 그냥 반환!
Case 2
if (prev_alloc && !next_alloc) {
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}if (prev_alloc && !next_alloc)→ 이전 블럭은 할당되었고 다음 블록은 가용 블럭이라면size += GET_SIZE(HDRP(NEXT_BLKP(bp)))→ 다음 블럭을 합칠거니까 다음 블럭의 헤더에 사이즈를 기존 size에 더해주면 되겠죠?PUT(HDRP(bp), PACK(size, 0))→ 병합했으니 헤더 업데이트 해주어야겠죠?PUT(FTRP(bp), PACK(size, 0))→ 마찬가지로 푸터도 업데이트 해주어야 할겁니다.
Case 3
else if (!prev_alloc && next_alloc) {
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}else if (!prev_alloc && next_alloc)→ 이전 블럭은 가용 블럭이고 다음 블럭은 할당되었다면size += GET_SIZE(HDRP(PREV_BLKP(bp)))→ 이전 블럭을 합칠거니까 이전 블럭의 헤더에 사이즈를 기존 size에 더해주면 되겠죠?PUT(FTRP(bp), PACK(size, 0))→ 현재 블럭에 푸터에 사이즈를 업데이트 해줍니다.PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0))→ 병합한 블럭의 헤드는 이전 블럭에 헤드일테니 이전 블럭의 헤드를 업데이트 해줍시다.bp = PREV_BLKP(bp)→ 이제 bp는 이전 블럭의 페이로드의 시작점을 가르켜야겠죠?
Case 4
else {
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}else→ 이전, 다음 블럭 모두 가용 영역이라면size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)))→ 이전, 다음 블럭 모두 병합하는 거니까 두 블럭의 사이즈를 모두 더해줘야 할겁니다! (헤드에 사이즈가 있다는 걸 잊으면 안되겠죠?)PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0))→ 이전 블럭의 헤드가 병합한 새로운 가용 블럭의 헤드가 될 것 입니다. 업데이트 해줍시다!PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0))→ 다음 블럭의 푸터가 병합한 새로운 가용 블럭의 푸터가 될 것 입니다. 마찬가지로 업데이트 해줍시다!bp = PREV_BLKP(bp)→ 시작점을 이전 블럭의 페이로드 시작점으로 옮겨주어야겠죠? (bp는 항상 페이로드 시작점을 가르킨다는 것을 잊지 말아야 합니다!)
