
11. 네트워크 애플리케이션 (Network Applications)
웹 브라우징, 이메일 전송, 온라인 게임 등 네트워크 애플리케이션은 어디에나 있습니다. 흥미롭게도, 모든 네트워크 애플리케이션은 동일한 기본 프로그래밍 모델, 유사한 전체 논리 구조, 그리고 동일한 프로그래밍 인터페이스를 기반으로 합니다.
네트워크 애플리케이션은 이미 시스템 공부에서 배운 많은 개념(예: 프로세스, 신호, 바이트 순서(byte ordering), 메모리 매핑, 동적 저장소 할당)에 의존합니다.
물론 마스터해야 할 새로운 개념도 있습니다.
- 기본적인 클라이언트-서버 프로그래밍 모델을 이해해야 합니다.
- 인터넷이 제공하는 서비스를 사용하는 클라이언트-서버 프로그램을 작성하는 방법을 배워야 합니다.
마지막에는 이 모든 아이디어를 종합하여, 실제 웹 브라우저에 텍스트와 그래픽으로 정적(static) 및 동적(dynamic) 콘텐츠를 모두 제공할 수 있는, 작지만 기능적인 웹 서버를 개발할 것입니다.
11.1 클라이언트-서버 프로그래밍 모델 (The Client-Server Programming Model)
모든 네트워크 애플리케이션은 클라이언트-서버 모델을 기반으로 합니다. 이 모델에서 애플리케이션은 하나의 서버 프로세스(server process)와 하나 이상의 클라이언트 프로세스(client process)로 구성됩니다.
- 서버: 특정 리소스(resource)를 관리하며, 그 리소스를 조작하여 클라이언트에게 서비스를 제공합니다.
- 예 (웹 서버): 클라이언트를 대신하여 디스크 파일 세트를 검색하고 실행합니다.
- 예 (FTP 서버): 클라이언트를 위해 디스크 파일 세트를 저장하고 검색합니다.
- 예 (이메일 서버): 클라이언트를 위해 스풀 파일(spool file)을 읽고 업데이트합니다.
클라이언트-서버 트랜잭션 (Client-Server Transaction)
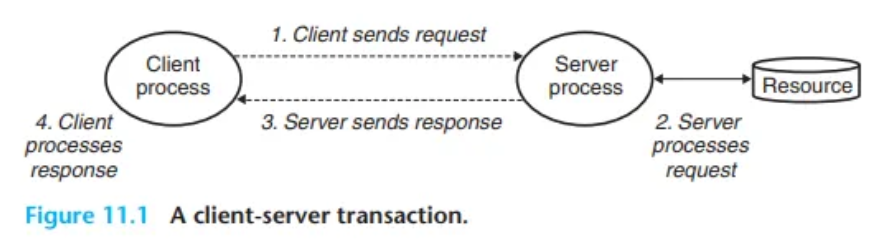
클라이언트-서버 모델의 기본 동작은 트랜잭션(transaction)입니다 (그림 11.1). 트랜잭션은 4단계로 구성됩니다.
- 클라이언트 요청 (Request)
- 클라이언트가 서비스가 필요할 때, 서버에 요청을 보내 트랜잭션을 시작합니다.
- (예: 웹 브라우저가 웹 서버에 파일을 요청)
- 서버 처리 (Process)
- 서버는 요청을 수신하고, 해석하며, 리소스를 적절한 방식으로 조작(manipulate)합니다.
- (예: 웹 서버가 디스크 파일을 읽음)
- 서버 응답 (Response)
- 서버는 클라이언트에게 응답을 보낸 후, 다음 요청을 기다립니다.
- (예: 웹 서버가 파일을 클라이언트에게 다시 보냄)
- 클라이언트 처리 (Process)
- 클라이언트는 응답을 수신하고 처리(manipulate)합니다.
- (예: 웹 브라우저가 응답으로 받은 페이지를 화면에 표시)
중요: 프로세스 vs 머신
클라이언트와 서버는 (이 문맥에서 종종 호스트(host)라고 불리는) 머신(machine)이 아니라 프로세스(process)라는 것을 인지하는 것이 중요합니다.
- 하나의 호스트(머신)는 동시에 많은 다른 클라이언트와 서버를 실행할 수 있습니다.
- 클라이언트와 서버 트랜잭션은 동일한 호스트 또는 서로 다른 호스트에서 발생할 수 있습니다.
- 클라이언트와 서버가 호스트에 어떻게 매핑(mapping)되는지와 관계없이, 클라이언트-서버 모델은 동일합니다.
11.2 네트워크 (Networks)
클라이언트와 서버는 종종 분리된 호스트에서 실행되며, 컴퓨터 네트워크의 하드웨어 및 소프트웨어 자원을 사용해 통신합니다. 네트워크는 정교한 시스템이며, 여기서는 프로그래머의 관점에서 작동 가능한 mental model을 제공하는 것이 목표입니다.
네트워크 = I/O 장치
호스트에게 네트워크는 데이터를 위한 소스(source)이자 싱크(sink) 역할을 하는 또 하나의 I/O 장치일 뿐입니다 (그림 11.2).
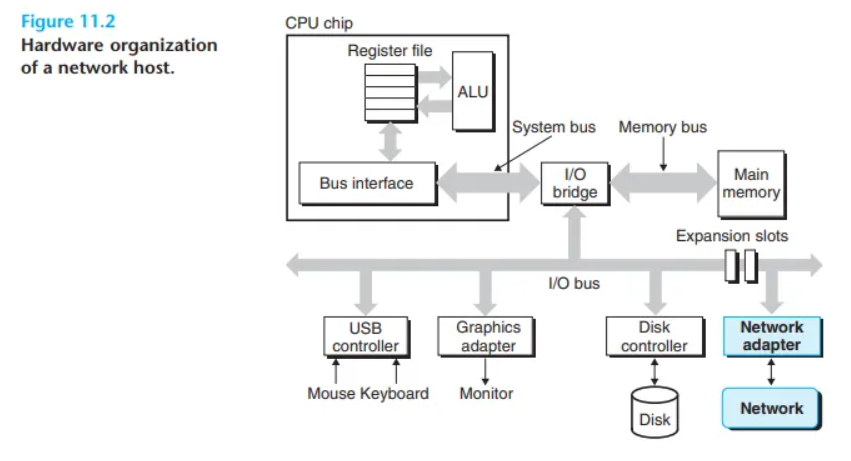
- I/O 버스의 확장 슬롯에 꽂힌 어댑터(adapter)가 네트워크로의 물리적 인터페이스를 제공합니다.
- 네트워크에서 수신된 데이터는 어댑터에서 I/O 및 메모리 버스를 거쳐 메모리로 복사됩니다 (일반적으로 DMA 전송).
- 반대로, 데이터는 메모리에서 네트워크로 복사될 수도 있습니다.
물리적 계층 구조
물리적으로 네트워크는 지리적 근접성에 따라 구성된 계층적 시스템입니다.
1. LAN (Local Area Network)
- 가장 낮은 수준은 건물이나 캠퍼스에 걸친 LAN(근거리 통신망)입니다.
- 가장 널리 쓰이는 LAN 기술은 이더넷(Ethernet)입니다. (3Mb/s에서 10Gb/s까지 발전)
2. 이더넷 세그먼트 (Ethernet Segment)
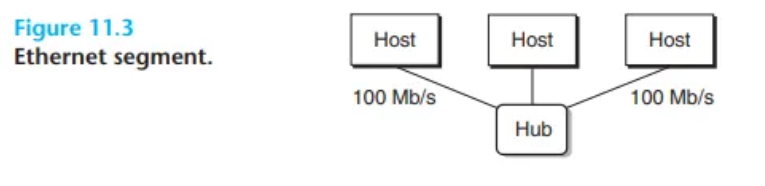
- 구성: 이더넷 세그먼트는 몇 개의 와이어(wire)와 허브(hub)라는 작은 상자로 구성됩니다 (그림 11.3).
- 허브 (Hub): 허브는 한 포트에서 수신한 모든 비트를 다른 모든 포트로 맹목적으로 복사합니다. 따라서 모든 호스트가 모든 비트를 보게 됩니다.
- 프레임 (Frame):
- 각 이더넷 어댑터는 고유한 48비트 주소(MAC 주소)를 가집니다.
- 호스트는 프레임(frame)이라는 비트 덩어리를 세그먼트 내의 다른 호스트로 보낼 수 있습니다.
- 프레임은 [헤더 (송/수신 주소, 길이), 페이로드 (데이터)]로 구성됩니다.
- 모든 호스트 어댑터가 프레임을 보지만, 오직 목적지 호스트만이 그 프레임을 실제로 읽습니다.
- Q. 이더넷이란? 이더넷(Ethernet)은 유선 근거리 통신망(LAN)을 구축하기 위한 가장 보편적인 기술 표준입니다. 우리가 흔히 "랜선"이라고 부르는 케이블을 사용하여 컴퓨터, 프린터, 스위치 등의 장치들을 서로 연결하고 데이터를 주고받을 수 있도록 하는 하드웨어 명세와 통신 규칙(프로토콜)의 집합입니다.
1. 물리적 구성 (하드웨어)
이더넷은 데이터를 전송하기 위한 물리적인 매체와 연결 장치를 정의합니다.-
케이블: 주로 UTP(Unshielded Twisted Pair, 꼬임쌍선) 케이블을 사용합니다. (이것이 우리가 "랜선"이라고 부르는 것입니다.)
-
네트워크 어댑터 (랜 카드): 모든 호스트(PC, 노트북 등)에 장착되며, 데이터를 프레임으로 만들거나 해석합니다.
-
연결 장치 (허브 vs 스위치):
- 허브 (Hub): 11.2에서 언급된 구형 장치입니다. 한 포트에서 들어온 데이터를 모든 포트로 맹목적으로 복사하여 전송합니다. (비효율적)
- 스위치 (Switch): 현재의 표준 장치입니다. 11.2의 브리지(Bridge)와 유사하게 작동하며, 각 포트에 연결된 장치의 MAC 주소를 학습합니다. 데이터가 들어오면 목적지 MAC 주소가 연결된 포트로만 프레임을 선택적으로 전송하여 효율이 매우 높습니다.
2. 프로토콜 (규칙)
이더넷은 LAN 내부에서 장치들이 "어떻게" 통신할지 정의합니다.
-
MAC 주소 (Media Access Control Address)
- 본문에서 "고유한 48비트 주소"로 언급된 것입니다.
- 전 세계 모든 네트워크 어댑터(랜 카드)를 고유하게 식별하는 하드웨어 주소입니다.
- LAN(로컬 네트워크) 내부에서 통신할 때 "누가 누구에게" 보내는지 정확히 식별하는 주소로 사용됩니다.
-
프레임 (Frame)
- 이더넷에서 데이터를 주고받는 기본 패키지 단위입니다.
- 본문 11.2에서 설명한 것처럼 [헤더 + 페이로드] 구조를 가집니다.
- 이더넷 헤더에는 목적지 MAC 주소와 출발지 MAC 주소가 포함됩니다.
- (참고: 11.2의 캡슐화 예시처럼, 인터넷 통신을 할 때는 IP 패킷이 이 이더넷 프레임의 '페이로드' 부분에 담겨서 전송됩니다.)요약하자면, 이더넷은 "같은 LAN 안에서, MAC 주소를 사용해, 프레임이라는 패키지로, 스위치를 통해 데이터를 전달하는 유선 통신 표준"입니다.
-
- Q. 스위치의 MAC 주소 학습 방법 스위치는 '우편물 분류기'처럼 행동하며, 포트로 들어오는 트래픽(프레임)을 엿보는 방식으로 MAC 주소를 학습합니다. 스위치 내부에는 'MAC 주소 테이블'(MAC Address Table)이라는 메모리 공간이 있으며, 이 테이블은
[MAC 주소 | 포트 번호]를 한 쌍으로 저장합니다. 이 학습과 처리 과정은 두 부분으로 나뉩니다.1. 학습: 출발지 주소로 배운다 (Learning)
스위치는 수동적으로 학습합니다. 누군가 스위치에 "A는 1번 포트에 있다"고 미리 알려주지 않습니다.-
네트워크의 컴퓨터 A(MAC 주소:
AA-AA)가 스위치의 1번 포트에 연결되어 있다고 가정합니다. -
A가 컴퓨터 B에게 데이터를 보내기 위해 프레임(frame)을 생성합니다. 이 프레임의 헤더에는 [출발지:
AA-AA| 목적지:BB-BB]가 기록됩니다. -
프레임이 1번 포트로 들어오는 순간, 스위치는 프레임 헤더를 엿봅니다.
-
스위치는 '출발지(Source) MAC 주소'인
AA-AA를 확인합니다. -
스위치는 "아,
AA-AA라는 MAC 주소는 1번 포트에 연결되어 있구나!"라는 사실을 알게 됩니다. -
이 정보를 자신의 MAC 주소 테이블에 즉시 기록(갱신)합니다.
MAC 주소 포트 번호 AA-AA 1
2. 전달: 목적지 주소로 보낸다 (Forwarding)
학습의 목적은 데이터를 효율적으로 전달하기 위함입니다.
-
이제 컴퓨터 B(MAC 주소:
BB-BB, 포트: 2번)가 A에게 답장을 보낸다고 가정합니다. -
B가 보낸 프레임 [출발지:
BB-BB| 목적지:AA-AA]가 2번 포트로 들어옵니다. -
(학습) 스위치는 출발지
BB-BB를 보고 "아,BB-BB는 2번 포트에 있구나!"라고 테이블에 기록합니다. -
(전달) 스위치는 '목적지(Destination) MAC 주소'인
AA-AA를 봅니다. -
스위치가 자신의 MAC 주소 테이블을 검색합니다.
-
테이블에
AA-AA는 1번 포트에 있다고 기록되어 있습니다. -
스위치는 이 프레임을 다른 모든 포트가 아닌 오직 1번 포트로만 정확하게 전송(Forwarding)합니다. (허브처럼 모든 곳에 뿌리지 않습니다.)
만약 목적지를 모른다면? (Flooding)
맨 처음, 스위치의 MAC 주소 테이블은 비어있습니다.
이때 A(
AA-AA)가 B(BB-BB)에게 프레임을 보내면, 스위치는AA-AA가 1번 포트에 있음을 학습합니다.하지만 목적지인
BB-BB가 테이블에 없습니다. 스위치는 이 프레임을 어디로 보내야 할지 모릅니다. 이때 스위치는 허브(Hub)처럼 작동합니다.프레임이 들어온 1번 포트를 제외한 모든 포트로 이 프레임을 복제해서 뿌립니다 (Flooding).
B를 제외한 모든 컴퓨터는 "이거 내 거 아니네" 하고 프레임을 무시하지만, B는 "내 거다!" 하고 프레임을 받습니다. 그리고 B가 답장을 보내는 순간, 스위치는 B의 위치(
BB-BB는 2번 포트)를 학습하게 됩니다.이 MAC 주소 테이블에 대해 더 궁금한 점이나, IP 주소와 MAC 주소가 함께 작동하는 방식(ARP)에 대해 이어서 설명해 드릴까요?
-
- Q. IP 주소와 MAC 주소가 함께 작동하는 방식 : ARP ARP는 Address Resolution Protocol (주소 결정 프로토콜)의 약자입니다. 가장 간단하게 말해서, 같은 동네(로컬 네트워크)에서 특정 IP 주소를 가진 컴퓨터의 MAC 주소가 무엇인지 물어보는 "탐정" 같은 역할을 합니다.
IP 주소 → MAC 주소 찾는 프로토콜
ARP가 왜 필요한가요? (IP와 MAC의 관계)
이전 대화에서 스위치는 MAC 주소를 기반으로 데이터를 전달한다고 배웠습니다. MAC 주소는 하드웨어의 "물리적 주소"입니다. 하지만 사용자는 보통192.168.0.10같은 IP 주소를 사용합니다. 이것은 "논리적 주소"입니다. 문제가 발생합니다:
제 컴퓨터(A)가192.168.0.10(B)에게 데이터를 보내고 싶은데, 스위치에게 데이터를 전달하려면 B의 MAC 주소를 알아야만 이더넷 프레임 [헤더]에 적어 보낼 수 있습니다. ARP의 역할:
이때 컴퓨터 A가 "IP 주소192.168.0.10을 쓰시는 분, MAC 주소가 어떻게 되시나요?"라고 물어보는 데 사용하는 프로토콜이 바로 ARP입니다.ARP 동작 방식 (Request & Reply)
ARP는 "요청(Request)"과 "응답(Reply)" 두 단계로 작동합니다. [ 시나리오: PC A (192.168.0.5)가 PC B (192.168.0.10)에게 데이터를 보내려 함 ]-
ARP 캐시 확인 (Cache Check)
- PC A는 먼저 자신의 ARP 캐시(최근에 알아낸 IP-MAC 매핑 정보가 저장된 작은 메모리)를 확인합니다.
- "내가
192.168.0.10의 MAC 주소를 이미 알고 있나?" - (알고 있다면): 바로 그 MAC 주소를 사용해 데이터를 전송합니다. (ARP 과정 끝)
- (모른다면): 2단계로 진행합니다.
-
ARP Request (Broadcast)
- PC A가 브로드캐스트(Broadcast) 패킷을 만듭니다.
- 내용: "IP
192.168.0.10을 가진 분, 당신의 MAC 주소를192.168.0.5(나)에게 알려주세요." - 목적지 MAC 주소:
FF:FF:FF:FF:FF:FF(이것이 "모두에게"라는 뜻의 특수 주소입니다.) - 스위치는 이 브로드캐스트 프레임을 받으면, 프레임이 들어온 포트를 제외한 연결된 모든 포트로 이 요청을 뿌립니다(Flooding).
-
수신 및 응답 결정
- 네트워크상의 모든 컴퓨터(PC B, C, D...)가 이 요청을 받습니다.
- PC C, D: "이거 내 IP 주소(
192.168.0.10) 찾는 거 아니네." ➔ 요청을 무시(discard)합니다. - PC B: "어, 내 IP 주소(
192.168.0.10)를 찾네!" ➔ 응답(Reply)을 준비합니다.
-
ARP Reply (Unicast)
- PC B가 유니캐스트(Unicast) 패킷을 만듭니다. (브로드캐스트가 아님)
- 내용: "네, 제가
192.168.0.10이고, 제 MAC 주소는BB-BB-BB-BB-BB-BB입니다." - 목적지 MAC 주소: PC A의 MAC 주소 (요청 패킷의 '출발지 MAC'을 보고 이미 알고 있음)
- 스위치는 이 유니캐스트 프레임을 받으면, 테이블을 참조하여 오직 PC A가 연결된 포트로만 정확히 전달합니다.
-
캐시 저장 및 통신 시작
- PC A는 응답을 받고, 자신의 ARP 캐시에[192.168.0.10 = BB-BB-BB-BB-BB-BB]라고 기록합니다.
- 이제 PC A는 PC B의 MAC 주소를 알았으므로, 원래 보내려던 데이터를 이더넷 프레임에 담아 (목적지 MAC:BB-BB...) 전송을 시작합니다.
- PC B 역시 PC A의 MAC 주소를 ARP 테이블에 캐싱합니다.
ARP 캐시 (ARP Cache)
- ARP는 매번 물어보면 비효율적이므로, 한 번 알아낸 IP-MAC 매핑 정보를 메모리에 임시 저장합니다. 이것이 ARP 캐시입니다.
- 이 정보는 일정 시간(몇 분 정도)이 지나면 자동으로 삭제(timeout)됩니다. (혹시 B 컴퓨터의 랜카드가 바뀌어 MAC 주소가 바뀔 수도 있으니까요.)
- (윈도우
cmd나 터미널에서arp -a명령어를 치면 현재 내 PC의 ARP 캐시 목록을 볼 수 있습니다.)
-
- Q. 두 개 이상의 라우터를 거친 통신 방식은? 가장 중요한 두 가지 원칙을 먼저 기억해 주세요.
-
L3 (IP) 헤더는 불변: 패킷이 최종 목적지에 도착할 때까지 Source IP (A)와 Destination IP (B)는 절대 변하지 않습니다.
-
L2 (MAC) 헤더는 가변: 이더넷 프레임의 L2(MAC) 헤더는 각 라우터를 통과(hop)할 때마다 매번 벗겨지고 새로 포장됩니다. L2 헤더는 오직 '다음 홉(next hop)'까지만 유효합니다.
새로운 시나리오
PC A가 인터넷을 거쳐PC B에게 데이터를 보냅니다.
-
경로:
PC A→R1(A의 게이트웨이) →R2(중간 라우터) →R3(B의 게이트웨이) →PC B -
IP 패킷 (L3): [Source:
A-IP| Dest:B-IP] (이것은 절대 변하지 않음)
1️⃣ 홉 1:
PC A→R1(LAN A 내부)
-
PC A의 판단: "목적지
B-IP는 내 LAN(A)에 없다. 무조건 게이트웨이R1에게 보내야지." -
필요한 정보:
R1의 MAC 주소 -
ARP #1 (LAN A):
PC A가 LAN A에 브로드캐스트. "IPR1-IP가진 분, MAC 주소 뭐예요?" -
R1의 응답: "제 MAC은R1-MAC-A입니다." -
PC A의 프레임 포장:- L2 헤더: [Src:
A-MAC| Dest:R1-MAC-A] - L3 헤더: [Src:
A-IP| Dest:B-IP]
- L2 헤더: [Src:
-
PC A가 이 프레임을 LAN A로 전송합니다.
2️⃣ 홉 2:
R1→R2(라우터 간) -
R1의 수신:R1이 프레임을 받고, L2 헤더(목적지가R1-MAC-A임)를 벗겨냅니다. -
R1의 판단 (L3): L3 헤더를 봅니다. "최종 목적지는B-IP구나." -
라우팅 테이블 조회: "내 라우팅 테이블을 보니,
B-IP로 가려면 '다음 홉'은R2이네." -
필요한 정보:
R2의 MAC 주소 -
ARP #2 (R1-R2망):
R1이R2와 연결된 망에 ARP 요청. "IPR2-IP가진 분, MAC 주소 뭐예요?" -
R2의 응답: "제 MAC은R2-MAC입니다." -
R1의 새 프레임 포장:- L2 헤더: [Src:
R1-MAC-WAN| Dest:R2-MAC] - L3 헤더: Src:
A-IP| Dest:B-IP
- L2 헤더: [Src:
-
R1이 이 새로운 프레임을R2로 전송합니다.
3️⃣ 홉 3:
R2→R3(라우터 간)2번 과정과 완전히 동일한 로직이 반복됩니다.
-
R2의 수신: 프레임을 받고, L2 헤더(목적지가R2-MAC임)를 벗겨냅니다. -
R2의 판단 (L3): L3 헤더를 봅니다. "최종 목적지는B-IP." -
라우팅 테이블 조회: "내 테이블을 보니,
B-IP로 가려면 '다음 홉'은R3이네." -
필요한 정보:
R3의 MAC 주소 -
ARP #3 (R2-R3망):
R2가R3와 연결된 망에 ARP 요청. "IPR3-IP가진 분, MAC 주소 뭐예요?" -
R3의 응답: "제 MAC은R3-MAC입니다." -
R2의 새 프레임 포장:- L2 헤더: [Src:
R2-MAC-WAN2| Dest:R3-MAC] - L3 헤더: Src:
A-IP| Dest:B-IP
- L2 헤더: [Src:
-
R2가 이 새로운 프레임을R3으로 전송합니다.
4️⃣ 홉 4:
R3→PC B(LAN B 내부)마지막 단계입니다. 여기서 '다음 홉'은 라우터가 아닌 최종 목적지
PC B가 됩니다. -
R3의 수신: 프레임을 받고, L2 헤더(목적지가R3-MAC임)를 벗겨냅니다. -
R3의 판단 (L3): L3 헤더를 봅니다. "최종 목적지는B-IP." -
라우팅 테이블 조회: "내 테이블을 보니,
B-IP가 속한 네트워크(LAN B)는 나에게 직접 연결되어 있네!" -
R3의 결론: "이제 내가 이 패킷을PC B에게 직접 전달하면 끝이다." -
필요한 정보:
PC B의 MAC 주소 -
ARP #4 (LAN B):
R3이 LAN B에 브로드캐스트. "IPB-IP가진 분, MAC 주소 뭐예요?" -
PC B의 응답: "저예요! 제 MAC은B-MAC입니다." -
R3의 마지막 프레임 포장:- L2 헤더: [Src:
R3-MAC-B| Dest:B-MAC] - L3 헤더: Src:
A-IP| Dest:B-IP
- L2 헤더: [Src:
-
R3이 이 프레임을 LAN B로 전송하고,PC B가 최종적으로 수신합니다.요약
- 라우터는 L3(IP) 주소를 보고 최종 목적지를 확인한 뒤, 라우팅 테이블을 통해 '다음 홉(Next Hop)'을 결정합니다.
- 그 '다음 홉'이 또 다른 라우터(
R2,R3)이든, 최종 목적지(PC B)이든 상관없이, 라우터는 '다음 홉'의 MAC 주소를 알아내기 위해 ARP를 사용합니다. - 이 과정에서 L2 헤더는 계속 새롭게 포장(re-encapsulation)됩니다.
-
- Q. ARP 과정에서 테이블에 없다면 Gateway에 데이터를 보내야 한다. 이때 Gateway의 MAC 주소를 알아야 한다. 그럴려면 Gateway IP 주소를 알고 있어야 할텐데 어떻게 알고 있을까? 결론적으로 PC는 "기본 게이트웨이(Default Gateway)" 주소로 미리 알고 있습니다. 이 "기본 게이트웨이" IP 주소는 PC A가 네트워크에 연결되는 시점에 자신의 IP 주소 및 서브넷 마스크와 함께 설정됩니다.
IP 주소는 어떻게 설정되는가?
PC A가R1-IP를 알게 되는 방법(즉, 네트워크 설정)은 크게 두 가지입니다.1. 수동 설정 (Static)
-
가장 간단한 방식입니다.
-
사용자가 직접 PC의 [네트워크 설정]에 들어가서 IP 정보를 모두 키보드로 입력합니다.
- IP 주소:192.168.0.5
- 서브넷 마스크:255.255.255.0
- 기본 게이트웨이:192.168.0.1(이것이 바로R1-IP입니다)2. 자동 설정 (DHCP) - 가장 일반적인 방식
-
우리가 집이나 카페에서 Wi-Fi에 연결할 때 자동으로 IP를 받는 방식입니다.
-
DHCP (Dynamic Host Configuration Protocol) 라는 프로토콜이 사용됩니다.
-
과정:
1. PC A가 네트워크에 연결되면, "저 IP 주소 필요해요!"라고 DHCP Discover 브로드캐스트를 보냅니다.
2. 일반적으로 라우터(R1)가 이 DHCP 서버 역할을 겸합니다.
3.R1이 PC A에게 "DHCP Offer"를 보냅니다. 이 안에는 다음 정보가 모두 들어있습니다.
- IP 주소: "넌192.168.0.5를 쓰렴."
- 서브넷 마스크: "네트워크 울타리는255.255.255.0이야."
- 기본 게이트웨이: "그리고 모르는 곳(외부망)으로 갈 땐, 나(192.168.0.1)에게 보내렴." (이것이R1-IP입니다.)
- (부가 정보: DNS 서버 주소 등)
요약
- PC A는 부팅 시 DHCP를 통해
R1-IP를 "기본 게이트웨이" 주소로 미리 저장해 둡니다. - PC A가
B-IP로 통신을 시도합니다. - 서브넷 마스크 계산 결과,
B-IP가 외부망임을 확인합니다. - PC A는 "아, 외부망이니 '기본 게이트웨이'로 보내야지"라고 판단합니다.
- PC A는 저장해 둔 '기본 게이트웨이' IP 주소 (
R1-IP)를 꺼냅니다. - 바로 이 시점에 사용자님이 질문한 ARP가 시작됩니다: "좋아,
R1-IP로 보내야 하는데... 혹시R1-IP의 MAC 주소 아는 사람?" (ARP 브로드캐스트)
-
- Q. 프레임이란?
- Q. 프레임에서의 오류체크는 어떻게 할까?
3. 브리지 이더넷 (Bridged Ethernets)
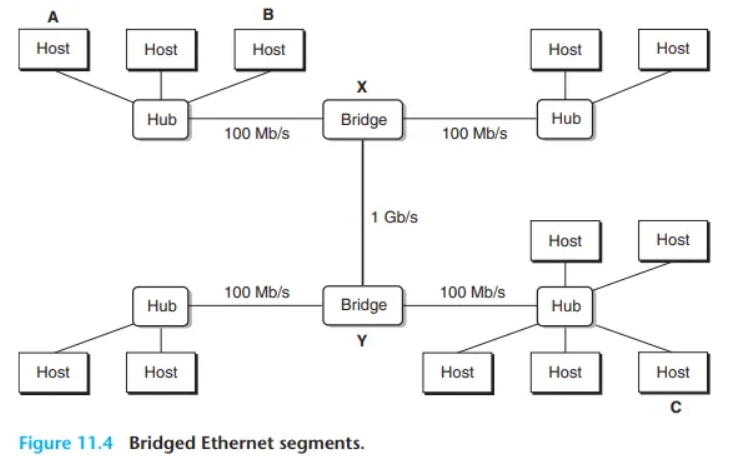
- 구성: 여러 이더넷 세그먼트는 브리지(bridge)라는 작은 상자들을 사용해 더 큰 LAN(브리지 이더넷)으로 연결될 수 있습니다 (그림 11.4).
- 브리지 (Bridge): 브리지는 허브보다 똑똑합니다.
-
영리한 분산 알고리즘을 사용해, 시간이 지남에 따라 어떤 호스트가 어느 포트에서 도달 가능한지 자동으로 학습합니다.
-
그 후 필요할 때만 프레임을 선택적으로 복사합니다.
-
(예: A가 같은 세그먼트의 B에게 보내면, 브리지는 그 프레임을 버려 다른 세그먼트의 대역폭을 절약합니다. A가 다른 세그먼트의 C에게 보내면, 브리지는 C가 연결된 포트로만 프레임을 복사합니다.)
-
- (이후 LAN 그림은 허브와 브리지를 하나의 수평선으로 단순화하여 그릴 것입니다 - 그림 11.5)
- Q. 허브는 스위치인가? 아니요, 허브는 스위치의 "더 이전 세대" 혹은 "더 단순한" 버전이라고 볼 수 있습니다.
-
허브 (Hub) - Layer 1 (물리 계층)
- 허브는 "멍청한(dumb)" 장치입니다. MAC 주소나 IP 주소를 전혀 이해하지 못합니다.
- 한 포트에서 전기 신호(데이터)가 들어오면, 그 신호를 그대로 복사해서 나머지 모든 포트로 재전송(broadcast)합니다.
- 네트워크의 모든 장치가 동일한 "충돌 도메인"에 속하게 되어, 트래픽이 많아지면 충돌이 빈번해지고 속도가 급격히 저하됩니다. (그래서 "더미 허브"라고도 부릅니다.)
-
스위치 (Switch) - Layer 2 (데이터 링크 계층)
- 스위치는 "영리한(smart)" 장치입니다. (제시해주신 텍스트의 브리지와 동일한 역할을 합니다.)
- 스위치는 각 포트에 연결된 장치의 MAC 주소를 학습합니다.
- A가 C에게 데이터를 보낼 때, 스위치는 해당 데이터를 C가 연결된 포트로만 선택적으로 전송합니다.
- 현대의 스위치(Switch)는 사실상 '멀티 포트 브리지(multi-port bridge)'입니다. 브리지의 기능을 여러 포트에서 고속으로 처리하도록 만든 장치입니다.결론: 허브는 모든 포트에 소리치는 확성기(broadcast)이고, 스위치(브리지)는 특정 대상에게만 귓속말(unicast)을 전달하는 교환원입니다.
-
- Q. Bridge가 라우터인가?
1. 브리지는 라우터인가? (A: 다릅니다)
아니요, 브리지와 라우터는 OSI 모델의 서로 다른 계층(Layer)에서 작동합니다.-
브리지 (Bridge) - Layer 2 (데이터 링크 계층)
- 브리지는 MAC 주소 (물리적 주소)를 기반으로 작동합니다.
- 주된 목적은 동일한 네트워크(LAN)를 여러 세그먼트(충돌 도메인)로 분리하여 불필요한 트래픽을 차단하는 것입니다.
- 브리지는 "이 MAC 주소는 이쪽 포트에 있다"라는 것을 학습합니다.
- IP 주소라는 개념 자체를 이해하지 못합니다.
-
라우터 (Router) - Layer 3 (네트워크 계층)
- 라우터는 IP 주소 (논리적 주소)를 기반으로 작동합니다.
- 주된 목적은 서로 다른 네트워크(예: 내 집 LAN과 인터넷 WAN)를 연결하고, 데이터 패킷이 목적지까지 갈 수 있는 최적의 경로를 찾는(routing) 것입니다.결론: 브리지는 '하나의 큰 집(LAN)'을 여러 방(segment)으로 나누는 문지기 역할이고, 라우터는 '우리 집(LAN)'과 '다른 집(Another LAN/WAN)'을 연결하는 대문이자 우체부 역할입니다.
-
- Q. Bridge는 스위치인가? 네, 현대적인 관점에서 보면 스위치(Switch)는 사실상 '멀티 포트 브리지(Multi-port Bridge)'라고 할 수 있습니다. 둘은 OSI 7계층의 2계층(데이터 링크 계층)에서 동작하며, MAC 주소를 기반으로 프레임을 선별적으로 전달(forwarding)한다는 핵심 기능이 동일합니다. 다만, 역사적으로나 기술적인 뉘앙스에서 약간의 차이가 있습니다.
-
브리지 (Bridge):
- 역사: 초창기에는 주로 두 개의 네트워크 세그먼트(예: 허브 2개)를 연결하는 장치였습니다. (포트 수가 적음)
- 처리: 종종 소프트웨어 기반으로 포워딩 결정을 처리하여 스위치보다 느릴 수 있었습니다.
-
스위치 (Switch):
- 현재: 브리지의 개념을 여러 포트(multi-port)로 확장한 장치입니다. (포트 수가 4, 8, 24개 등으로 많음)
- 처리: ASIC (주문형 반도체)라는 전용 하드웨어를 사용하여 MAC 주소 테이블 조회와 포워딩을 "와이어 스피드(wire speed, 회선 최고 속도)"로 매우 빠르게 처리합니다.결론:
오늘날 우리가 "스위치"라고 부르는 장비는 브리지의 기본 원리를 계승하여 훨씬 더 빠르고, 더 많은 포트를 가진 형태로 발전시킨 것입니다. 따라서 "스위치는 브리지의 현대적이고 고성능 버전이다"라고 이해하시면 정확합니다.
-
4. 인터넷 (Internet)
- 구성: 더 높은 계층에서, 서로 호환되지 않는 여러 LAN이 라우터(router)라는 특수한 컴퓨터에 의해 연결되어 인터넷(internet, 상호연결된 네트워크)을 형성합니다.
- 라우터 (Router): 각 라우터는 연결된 모든 네트워크에 대한 어댑터(포트)를 가집입니다.
- WAN (Wide Area Network): 라우터는 LAN보다 더 넓은 지역을 포괄하는 WAN(광역 통신망)(예: 고속 전화 연결)도 연결할 수 있습니다.
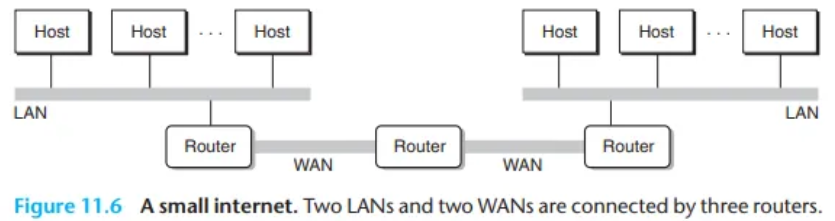
- (예: 그림 11.6은 3대의 라우터로 연결된 LAN과 WAN의 조합을 보여줍니다.)
상호연결된 네트워크 (internet)
internet(상호연결된 네트워크)의 결정적인 속성은 서로 급진적으로 다르고 호환되지 않는 기술의 LAN과 WAN으로 구성될 수 있다는 점입니다. 모든 호스트가 다른 모든 호스트와 물리적으로 연결된 것은 아닌데, 어떻게 출발지 호스트가 이 모든 호환되지 않는 네트워크를 거쳐 목적지 호스트로 데이터 비트를 보낼 수 있을까요?
해결책: 프로토콜 소프트웨어
해결책은 각 호스트와 라우터에서 실행되는 프로토콜 소프트웨어(protocol software) 계층이 서로 다른 네트워크 간의 차이점을 '없애주는(smoothes out)' 것입니다.
이 소프트웨어는 호스트와 라우터가 데이터를 전송하기 위해 어떻게 협력해야 하는지를 규율하는 프로토콜(protocol)을 구현합니다. 이 프로토콜은 두 가지 기본 기능을 제공해야 합니다.
- 이름 지정 체계 (Naming scheme)
- 서로 다른 LAN 기술들은 호스트 주소를 할당하는 방식이 제각기 다르고 호환되지 않습니다.
- 인터넷 프로토콜은 호스트 주소를 위한 통일된 형식을 정의하여 이러한 차이점을 없앱니다.
- 각 호스트는 자신을 고유하게 식별하는 하나 이상의 인터넷 주소를 할당받습니다.
- 전달 메커니즘 (Delivery mechanism)
- 서로 다른 네트워킹 기술들은 비트를 인코딩하고 프레임으로 포장하는 방식이 다릅니다.
- 인터넷 프로토콜은 데이터 비트를 패킷(packet)이라는 개별 청크로 묶는 통일된 방식을 정의하여 이러한 차이점을 없앱니다.
- 패킷(Packet): [헤더 (패킷 크기, 송/수신 호스트 주소), 페이로드 (실제 데이터 비트)]로 구성됩니다.
예제: LAN 간 데이터 전송 (그림 11.7)
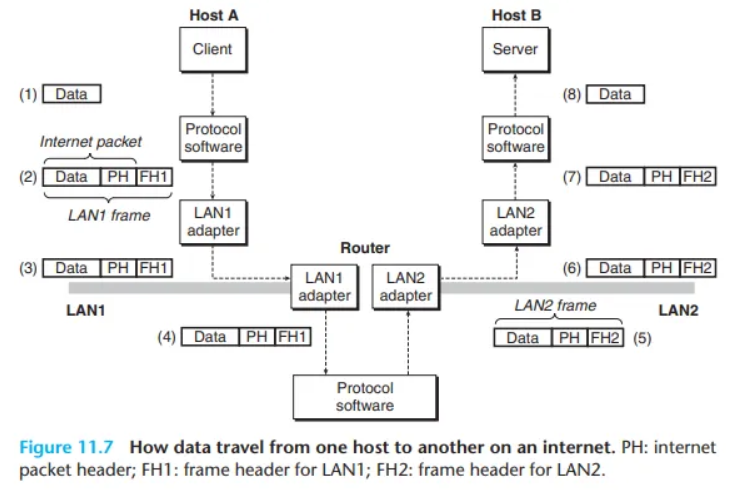
두 개의 LAN이 하나의 라우터로 연결된 인터넷 예시입니다. LAN1의 호스트 A(클라이언트)가 LAN2의 호스트 B(서버)로 데이터를 전송하는 8단계입니다.
- 호스트 A (클라이언트): 시스템 콜을 호출하여 데이터를 커널 버퍼로 복사합니다.
- 호스트 A (프로토콜): 데이터에 인터넷 헤더와 LAN1 프레임 헤더를 붙여 LAN1 프레임을 만듭니다.
- 인터넷 헤더의 목적지: (최종 목적지) 호스트 B
- LAN1 프레임 헤더의 목적지: (다음 단계) 라우터
- (이것이 캡슐화(encapsulation)의 핵심입니다. LAN1 프레임의 페이로드는 인터넷 패킷입니다.)
- 호스트 A (어댑터): 프레임을 네트워크(LAN1)로 복사(전송)합니다.
- 라우터 (LAN1 어댑터): 프레임을 수신하여 프로토콜 소프트웨어로 넘깁니다.
- 라우터 (프로토콜):
- (De-capsulation) LAN1 프레임 헤더를 벗겨냅니다.
- 인터넷 패킷 헤더를 읽어 최종 목적지(호스트 B)를 확인합니다.
- 라우팅 테이블을 참조하여 이 패킷을 LAN2로 전달해야 함을 결정합니다.
- (Re-capsulation) 새로운 LAN2 프레임 헤더를 생성하여 (목적지: 호스트 B) 패킷 앞에 붙입니다.
- 라우터 (LAN2 어댑터): 이 새로운 프레임을 네트워크(LAN2)로 복사(전송)합니다.
- 호스트 B (어댑터): 프레임을 수신하여 프로토콜 소프트웨어로 넘깁니다.
- 호스트 B (프로토콜): LAN2 프레임 헤더와 인터넷 패킷 헤더를 모두 벗겨내고, 서버가 데이터를 읽는 시스템 콜을 호출할 때 최종 데이터를 서버의 가상 주소 공간으로 복사합니다.
(물론 네트워크 최대 프레임 크기 문제, 라우팅 테이블 결정 방식, 패킷 손실 등 많은 어려운 문제를 생략했지만) 이 예제가 인터넷 아이디어의 본질을 담고 있으며, 캡슐화(Encapsulation)가 그 핵심입니다.
11.3 글로벌 IP 인터넷 (The Global IP Internet)
글로벌 IP 인터넷은 internet(상호연결된 네트워크)의 가장 유명하고 성공적인 구현체입니다. 1969년부터 어떤 형태로든 존재해왔습니다.
- 인터넷의 내부 아키텍처는 복잡하고 끊임없이 변하지만, 클라이언트-서버 애플리케이션의 구성은 1980년대 초부터 놀라울 정도로 안정적이었습니다.
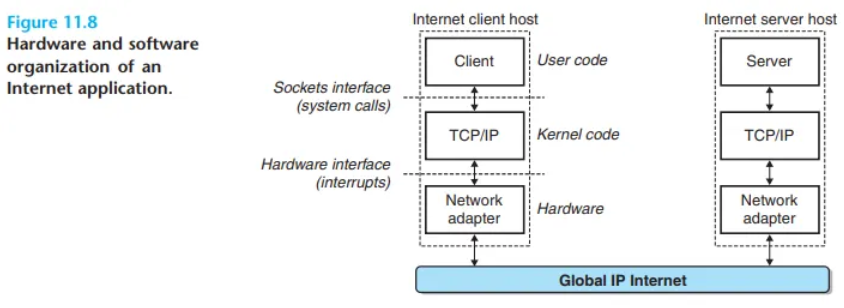
- [그림 11.8]은 인터넷 클라이언트-서버 애플리케이션의 기본 하드웨어 및 소프트웨어 구성을 보여줍니다.
TCP/IP 프로토콜
- 각 인터넷 호스트는 거의 모든 최신 컴퓨터 시스템이 지원하는 TCP/IP 프로토콜 (Transmission Control Protocol / Internet Protocol) 소프트웨어를 실행합니다.
- 인터넷 클라이언트와 서버는 소켓 인터페이스(Sockets interface) 함수와 Unix I/O 함수를 혼합하여 통신합니다. (소켓 인터페이스는 11.4절에서 설명)
- 소켓 함수는 일반적으로 커널 모드로 트랩(trap)하여 TCP/IP 커널 함수를 호출하는 시스템 콜로 구현됩니다.
TCP/IP 프로토콜 제품군 (Family)
TCP/IP는 실제로는 각기 다른 기능을 제공하는 프로토콜들의 제품군입니다.
- IP (Internet Protocol):
- 기본 이름 지정 체계(naming scheme)를 제공합니다.
- 데이터그램(datagrams)이라 불리는 패킷을 한 호스트에서 다른 호스트로 보낼 수 있는 전달 메커니즘을 제공합니다.
- 이 IP 메커니즘은 네트워크에서 데이터그램이 손실되거나 중복되더라도 복구하려 노력하지 않는다는 의미에서 신뢰할 수 없습니다(unreliable).
- UDP (Unreliable Datagram Protocol):
- IP를 약간 확장하여, 데이터그램이 호스트 대 호스트가 아닌 프로세스 대 프로세스로 전송될 수 있게 합니다.
- TCP (Transmission Control Protocol):
- IP를 기반으로 구축된 복잡한 프로토콜입니다.
- 프로세스 간에 신뢰할 수 있는(reliable) 전이중(full duplex) 연결을 제공합니다.
(논의를 단순화하기 위해, 이 책에서는 TCP/IP를 하나의 단일 프로토콜로 취급할 것입니다. UDP는 논의하지 않습니다.)
프로그래머의 관점
프로그래머의 관점에서, 인터넷은 다음과 같은 속성을 가진 전 세계적인 호스트의 집합으로 생각할 수 있습니다.
- 호스트 집합은 32비트 IP 주소 집합에 매핑됩니다.
- IP 주소 집합은 인터넷 도메인 이름(Internet domain names)이라는 식별자 집합에 매핑됩니다.
- 한 인터넷 호스트의 프로세스는 연결(connection)을 통해 다른 인터넷 호스트의 프로세스와 통신할 수 있습니다.
이어지는 섹션에서 이러한 기본적인 인터넷 아이디어를 더 자세히 논의합니다.
11.3.1 IP 주소 (IP Addresses)

IP 주소는 부호 없는 32비트 정수입니다. 네트워크 프로그램은 [그림 11.9]에 보이는 IP 주소 구조체에 IP 주소를 저장합니다.
스칼라(scalar) 주소를 구조체에 저장하는 것은 소켓 인터페이스 초기 구현의 불행한 유물입니다. IP 주소를 위한 스칼라 타입을 정의하는 것이 더 합리적이었겠지만, 이미 설치된 수많은 애플리케이션 기반 때문에 지금 바꾸기에는 너무 늦었습니다.
네트워크 바이트 순서 (Network Byte Order)
인터넷 호스트들은 서로 다른 호스트 바이트 순서(host byte order)를 가질 수 있기 때문에, TCP/IP는 패킷 헤더에 실려 네트워크를 가로지르는 IP 주소와 같은 모든 정수 데이터 항목에 대해 통일된 네트워크 바이트 순서(network byte order) (즉, 빅 엔디안(big-endian))를 정의합니다.
IP 주소 구조체(struct in_addr) 내의 주소는, 설령 호스트 바이트 순서가 리틀 엔디안(little-endian)일지라도, 항상 (빅 엔디안) 네트워크 바이트 순서로 저장됩니다.
유닉스는 호스트와 네트워크 바이트 순서를 변환하기 위해 다음 함수들을 제공합니다.
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong); // Host to Network Long
uint16_t htons(uint16_t hostshort); // Host to Network Short
// 반환 값: 네트워크 바이트 순서의 값
uint32_t ntohl(uint32_t netlong); // Network to Host Long
uint16_t ntohs(uint16_t netshort); // Network to Host Short
// 반환 값: 호스트 바이트 순서의 값htonl: 부호 없는 32비트 정수를 호스트 바이트 순서에서 네트워크 바이트 순서로 변환합니다.ntohl: 부호 없는 32비트 정수를 네트워크 바이트 순서에서 호스트 바이트 순서로 변환합니다.htons,ntohs: 부호 없는 16비트 정수에 대해 동일한 변환을 수행합니다. (64비트 값에 대한 함수는 없습니다.)
점 표기법 (Dotted-Decimal Notation)
IP 주소는 일반적으로 점 표기법(dotted-decimal notation)이라는 형태로 사람들에게 표시됩니다. 이는 각 바이트를 10진수 값으로 나타내고 점(.)으로 구분하는 방식입니다.
- (예:
128.2.194.242는0x8002c2f2의 점 표기법입니다.)
리눅스 시스템에서는 hostname -i 명령을 사용해 자신의 호스트 주소를 확인할 수 있습니다.
애플리케이션 프로그램은 inet_pton과 inet_ntop 함수를 사용해 IP 주소와 점 표기법 문자열 간의 변환을 수행할 수 있습니다.
#include <arpa/inet.h>
int inet_pton(AF_INET, const char *src, void *dst);
// 반환 값: 성공 시 1, src가 유효하지 않으면 0, 오류 시 -1
const char *inet_ntop(AF_INET, const void *src, char *dst, socklen_t size);
// 반환 값: 성공 시 점 표기법 문자열 포인터, 오류 시 NULL- (함수 이름에서 "n"은 network(네트워크)를, "p"는 presentation(표현)을 의미합니다.)
- 이 함수들은 32비트 IPv4 주소(
AF_INET)나 128-bit IPv6 주소(AF_INET6)를 조작할 수 있습니다.
inet_pton 함수는 점 표기법 문자열(src)을 네트워크 바이트 순서의 바이너리 IP 주소(dst)로 변환합니다. inet_ntop 함수는 네트워크 바이트 순서의 바이너리 IP 주소(src)를 해당하는 점 표기법 문자열로 변환하고, 그 결과를 dst에 복사합니다.
11.3.2 인터넷 도메인 이름 (Internet Domain Names)
인터넷 클라이언트와 서버는 IP 주소를 사용해 통신하지만, 사람은 32비트 정수(IP 주소)를 기억하기 어렵습니다. 따라서 인터넷은 도메인 이름(domain names)이라는 더 인간 친화적인 이름 집합과, 이 도메인 이름을 IP 주소로 매핑(mapping)하는 메커니즘을 정의합니다.
- (예:
whaleshark.ics.cs.cmu.edu)
도메인 이름 계층 (Hierarchy)
도메인 이름 집합은 계층(hierarchy)을 형성하며, 이는 트리(tree)로 표현됩니다 (그림 11.10).
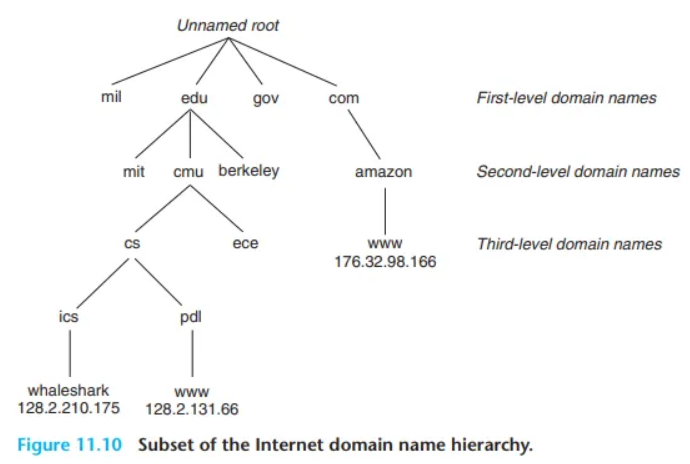
- 루트(Root): 이름 없는 루트 노드가 최상위에 있습니다.
- 1단계 (First-level): ICANN(국제인터넷주소관리기구)이라는 비영리 단체가 정의하는
com,edu,gov,org,net같은 1단계 도메인입니다. - 2단계 (Second-level):
cmu.edu와 같이 ICANN의 공인된 에이전트가 (선착순으로) 할당하는 2단계 도메인입니다. - 하위 도메인 (Subdomain): 2단계 도메인을 할당받은 조직은
cs.cmu.edu와 같이 자신의 하위 도메인 내에서 자유롭게 새 도메인 이름을 생성할 수 있습니다.
매핑: DNS (Domain Name System)
도메인 이름과 IP 주소 간의 매핑은 1988년까지는 HOSTS.TXT라는 단일 텍스트 파일로 관리되었습니다.
- 이후, 이 매핑은 DNS(Domain Name System)라는 전 세계적인 분산 데이터베이스에서 유지 관리됩니다.
- DNS 데이터베이스는 수백만 개의 호스트 항목(host entry)으로 구성되며, 각 항목은 도메인 이름 집합과 IP 주소 집합 간의 매핑을 정의합니다. (수학적으로는, 도메인 이름과 IP 주소의 동치 클래스(equivalence class)로 생각할 수 있습니다.)
DNS 매핑의 속성 (nslookup 예시)
리눅스 nslookup 프로그램으로 DNS 매핑의 속성을 탐색할 수 있습니다.
-
localhost:Bash
- 모든 호스트는
localhost라는 로컬 도메인 이름을 가지며, 이는 항상 루프백 주소(loopback address)127.0.0.1로 매핑됩니다. - (동일 머신에서 실행되는 클라이언트/서버 디버깅에 유용합니다.)
linux> nslookup localhost Address: 127.0.0.1 - 모든 호스트는
-
1:1 매핑 (One-to-one):Bash
- 가장 단순한 경우, 하나의 도메인 이름이 하나의 IP 주소로 매핑됩니다.
linux> nslookup whaleshark.ics.cs.cmu.edu Address: 128.2.210.175 -
다:1 매핑 (Many-to-one):Bash
- 여러 도메인 이름이 동일한 하나의 IP 주소로 매핑될 수 있습니다.
linux> nslookup cs.mit.edu Address: 18.62.1.6 linux> nslookup eecs.mit.edu Address: 18.62.1.6 -
다:다 매핑 (Many-to-many):Bash
- 가장 일반적인 경우, 여러 도메인 이름이 여러 개의 IP 주소 집합으로 매핑될 수 있습니다.
linux> nslookup www.twitter.com Address: 199.16.156.6 Address: 199.16.156.70 Address: 199.16.156.102 Address: 199.16.156.230 -
매핑 없음 (No mapping):Bash
edu나ics.cs.cmu.edu처럼, 유효한 도메인 이름임에도 불구하고 IP 주소에 매핑되지 않는 경우도 있습니다.
linux> nslookup edu *** Can’t find edu: No answer
11.3.3 인터넷 연결 (Internet Connections)
인터넷 클라이언트와 서버는 연결(connections)을 통해 바이트 스트림을 주고받으며 통신합니다. 연결은 다음과 같은 속성을 가집니다.
- 점대점 (Point-to-point): 한 쌍의 프로세스를 연결합니다.
- 전이중 (Full duplex): 데이터가 양방향으로 동시에 흐를 수 있습니다.
- 신뢰성 (Reliable): (케이블 절단과 같은 치명적인 장애를 제외하고) 출발지 프로세스가 보낸 바이트 스트림이 결국 목적지 프로세스에 전송된 순서와 동일한 순서로 수신됩니다.
소켓 (Socket)
- 소켓(Socket)은 연결의 종단점(end point)입니다. 각 소켓은 인터넷 주소(IP)와 16비트 정수 포트(port)로 구성된 고유한 소켓 주소(socket address)를 가지며,
address:port표기법으로 나타냅니다. - 클라이언트 포트: 클라이언트가 연결을 요청할 때 커널에 의해 자동으로 할당되며, 임시 포트(ephemeral port)라고 알려져 있습니다.
- 서버 포트: 일반적으로 해당 서비스와 영구적으로 연관된 잘 알려진 포트(well-known port)입니다.
- (예: 웹 서버는 80번, 이메일 서버는 25번 포트를 사용합니다.)
- 잘 알려진 서비스 이름: 잘 알려진 포트에는
http(웹),smtp(이메일)와 같이 대응하는 잘 알려진 서비스 이름이 있습니다. (/etc/services파일에 매핑이 포함됩니다.)
소켓 페어 (Socket Pair)
연결은 두 종단점의 소켓 주소에 의해 고유하게 식별됩니다. 이 소켓 주소 쌍을 소켓 페어(socket pair)라고 하며, 다음과 같은 튜플(tuple)로 표기합니다.
(cliaddr:cliport, servaddr:servport)
(cliaddr: 클라이언트 IP, cliport: 클라이언트 포트, servaddr: 서버 IP, servport: 서버 포트)
-
예시 (그림 11.11): 웹 클라이언트와 웹 서버 간의 연결
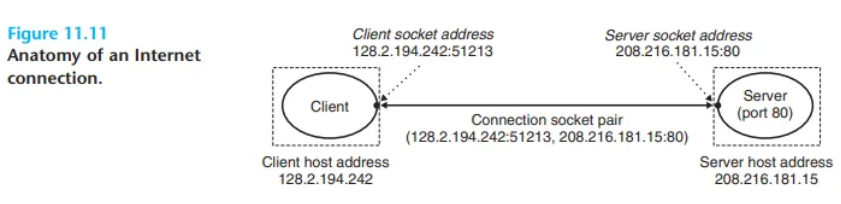
- 클라이언트 소켓 주소:
128.2.194.242:51213(51213은 커널이 할당한 임시 포트) - 서버 소켓 주소:
208.216.181.15:80(80은 웹 서비스의 잘 알려진 포트) - 이 연결을 식별하는 소켓 페어:
(128.2.194.242:51213, 208.216.181.15:80)
- 클라이언트 소켓 주소:
11.4 소켓 인터페이스 (The Sockets Interface)
소켓 인터페이스는 Unix I/O 함수들과 함께 네트워크 애플리케이션을 구축하는 데 사용되는 함수들의 집합입니다.
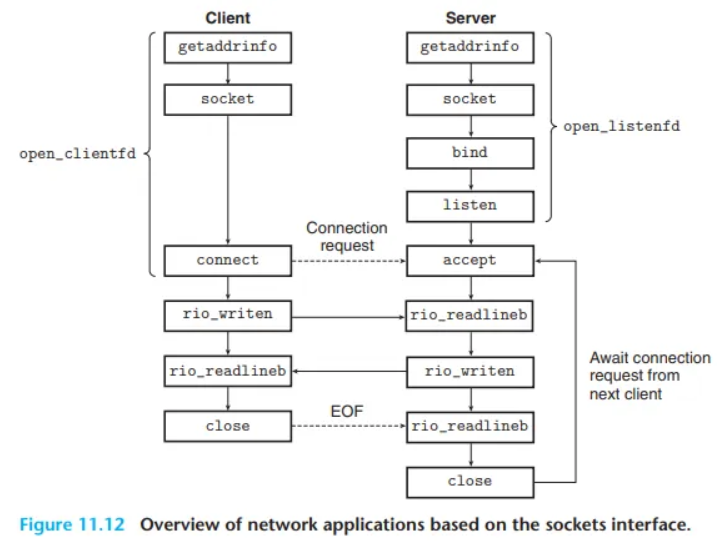
- 이는 모든 유닉스 변종은 물론, 윈도우와 매킨토시 시스템을 포함한 대부분의 현대 시스템에 구현되어 있습니다.
- [그림 11.12]는 일반적인 클라이언트-서버 트랜잭션의 관점에서 소켓 인터페이스의 개요를 보여줍니다.
- (이어지는 개별 함수들을 논의할 때 이 그림을 로드맵으로 사용해야 합니다.)
11.4.1 소켓 주소 구조체 (Socket Address Structures)
- 리눅스 커널의 관점에서, 소켓은 통신의 종단점(end point)입니다.
- 리눅스 프로그램의 관점에서, 소켓은 해당 디스크립터를 가진 열린 파일입니다.

인터넷 소켓 주소는 [그림 11.13]에 보이는 sockaddr_in 타입의 16바이트 구조체에 저장됩니다. 인터넷 애플리케이션의 경우, 필드 값은 다음과 같습니다.
sin_family:AF_INET(프로토콜 패밀리)sin_port: 16비트 포트 번호 (네트워크 바이트 순서)sin_addr: 32비트 IP 주소 (네트워크 바이트 순서)
제네릭 sockaddr 구조체
connect, bind, accept 함수들은 프로토콜에 특화된(protocol-specific) 소켓 주소 구조체에 대한 포인터를 요구합니다.
소켓 인터페이스 설계자들의 과제는 이 함수들이 어떤 종류의 소켓 주소 구조체든(예: IPv4, IPv6 등) 받아들일 수 있도록 정의하는 것이었습니다. (오늘날 C라면 제네릭 void * 포인터를 사용했겠지만, 당시에는 void *가 존재하지 않았습니다.)
그들의 해결책은 소켓 함수들이 제네릭 sockaddr 구조체([그림 11.13])에 대한 포인터를 받도록 정의한 다음, 애플리케이션이 sockaddr_in 같은 프로토콜별 구조체 포인터를 이 제네릭 sockaddr 구조체로 캐스트(cast)하도록 요구하는 것이었습니다.
(코드 예제를 단순화하기 위해, 스티븐스(Stevens)의 선례를 따라 다음 타입을 정의합니다:
typedef struct sockaddr SA;이후 sockaddr_in 구조체를 제네릭 sockaddr 구조체로 캐스트해야 할 때마다 이 SA 타입을 사용할 것입니다.)
11.4.2 The socket Function
클라이언트와 서버는 socket 함수를 사용하여 소켓 디스크립터를 생성합니다.
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);- 반환 값: 성공 시 0 이상의 디스크립터, 오류 시 -1
만약 이 소켓이 연결(connection)의 종단점이 되기를 원한다면, 다음과 같이 하드코딩된 인자들로 socket을 호출할 수 있습니다:
clientfd = Socket(AF_INET, SOCK_STREAM, 0);
AF_INET: 우리가 32비트 IP 주소를 사용함을 나타냅니다.SOCK_STREAM: 이 소켓이 연결(connection)의 종단점이 될 것임을 나타냅니다.
하지만, 코드가 프로토콜에 독립적(protocol-independent)이 되도록 getaddrinfo 함수(11.4.7절)를 사용하여 이 파라미터들을 자동으로 생성하는 것이 최선의 방법입니다. (11.4.8절에서 getaddrinfo를 socket 함수와 함께 사용하는 방법을 보여줄 것입니다.)
socket에 의해 반환된 clientfd 디스크립터는 부분적으로만 열린(partially opened) 상태이며, 아직 읽기/쓰기에 사용될 수 없습니다.
소켓 열기를 완료하는 방법은 우리가 클라이언트인지 서버인지에 따라 다릅니다. 다음 섹션은 클라이언트인 경우 소켓 열기를 완료하는 방법을 설명합니다.
11.4.3 The connect Function
클라이언트는 connect 함수를 호출하여 서버와 연결을 수립합니다.
#include <sys/socket.h>
int connect(int clientfd, const struct sockaddr *addr, socklen_t addrlen);- 반환 값: 성공 시 0, 오류 시 -1
connect 함수는 소켓 주소 addr에 있는 서버와 인터넷 연결을 시도합니다 (여기서 addrlen은 sizeof(sockaddr_in)입니다).
connect 함수는 연결이 성공적으로 수립되거나 오류가 발생할 때까지 블록(blocks)됩니다.
성공하면, clientfd 디스크립터는 이제 읽기/쓰기가 준비된 상태가 되며, 이 연결은 다음 소켓 페어(socket pair)로 식별됩니다.
(x:y, addr.sin_addr:addr.sin_port)
(여기서 x는 클라이언트의 IP 주소이고, y는 클라이언트 호스트에서 클라이언트 프로세스를 고유하게 식별하는 임시 포트(ephemeral port)입니다.)
socket 함수와 마찬가지로, connect의 인자들을 제공하기 위해 getaddrinfo를 사용하는 것이 최선의 방법입니다 (11.4.8절 참조).
11.4.4 The bind Function
bind, listen, accept 등 나머지 소켓 함수들은 서버가 클라이언트와 연결을 수립하기 위해 사용됩니다.
#include <sys/socket.h>
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);- 반환 값: 성공 시 0, 오류 시 -1
bind 함수는 커널에게 addr에 있는 서버의 소켓 주소를 소켓 디스크립터 sockfd와 연결(associate)하도록 요청합니다. addrlen 인자는 sizeof(sockaddr_in)입니다.
socket, connect와 마찬가지로, bind의 인자들을 제공하기 위해 getaddrinfo를 사용하는 것이 최선의 방법입니다 (11.4.8절 참조).
11.4.5 The listen Function
클라이언트는 연결 요청을 시작하는(initiate) 능동적인 주체입니다. 서버는 클라이언트의 연결 요청을 기다리는(wait) 수동적인 주체입니다.
기본적으로 커널은 socket 함수로 생성된 디스크립터가 (클라이언트 측의) 능동 소켓(active socket) 이라고 가정합니다. 서버는 listen 함수를 호출하여, 해당 디스크립터가 클라이언트가 아닌 서버에 의해 사용될 것임을 커널에 알립니다.
#include <sys/socket.h>
int listen(int sockfd, int backlog);- 반환 값: 성공 시 0, 오류 시 -1
listen 함수는 sockfd를 능동 소켓에서, 클라이언트의 연결 요청을 받을 수 있는 수신 소켓(listening socket)으로 변환합니다.
backlog 인자는 커널이 요청을 거부하기 시작하기 전에 대기열(queue)에 쌓아둘 보류 중인 연결 요청의 수에 대한 힌트(hint)입니다. (backlog의 정확한 의미는 TCP/IP에 대한 이해가 필요하므로 이 책의 범위를 벗어납니다. 일반적으로 1,024와 같은 큰 값으로 설정합니다.)
- Q. backlog란?
backlog인자에 대해 더 자세히 설명해 드릴게요. 이 큐가 왜 필요하고, 커널 내부에서 실제로 어떻게 동작하는지 알려면 TCP 3-Way Handshake 과정과 커널의 두 가지 큐(Queue)를 이해해야 합니다.backlog는 서버가accept()를 호출하여 연결을 가져갈 때까지, 이미 3-Way Handshake를 완료한 연결들을 잠시 보관하는 '완료 연결 큐'의 최대 크기를 지정하는 힌트입니다.1. SYN Queue (미완료 연결 큐)
클라이언트가 서버에 접속을 시도하면(3-Way Handshake 시작), 다음과 같이 동작합니다.- 클라이언트 → 서버:
SYN- 클라이언트가 "연결 요청합니다"라는
SYN패킷을 보냅니다.
- 클라이언트가 "연결 요청합니다"라는
- 커널의 처리:
- 서버 커널은 이
SYN을 받으면, 해당 연결 정보를 SYN Queue에 넣습니다. - 이 큐의 연결들은 "아직 핸드셰이크가 완료되지 않은" (half-open) 상태입니다.
- 서버 커널은 이
- 서버 → 클라이언트:
SYN-ACK- 커널은
SYN-ACK로 응답하며 클라이언트의 마지막ACK를 기다립니다.
- 커널은
-
이
SYN Queue의 크기는backlog값이 아니라, 리눅스 시스템의net.ipv4.tcp_max_syn_backlog같은 시스템 전역 설정에 의해 제어됩니다.2. Accept Queue (완료 연결 큐)
-
클라이언트 → 서버:
ACK- 클라이언트가
SYN-ACK를 받고, "알겠습니다"라는 마지막ACK를 서버에 보냅니다.
- 클라이언트가
-
커널의 처리:
- 서버 커널이 이 마지막ACK를 받으면, 3-Way Handshake가 성공적으로 완료된 것입니다.
- 커널은 이 연결을SYN Queue에서 꺼내어, Accept Queue로 옮깁니다.
- 이 큐의 연결들은 "완전히 연결되었으며,accept()함수가 자신을 가져가기만 기다리는" 상태입니다.
backlog의 정확한 역할listen(sockfd, backlog)에서backlog인자는 바로 이 2번 큐, 즉Accept Queue의 최대 크기를 지정합니다.
-
listen(sockfd, 1024)를 호출하면, 커널은 "핸드셰이크가 완료된 연결을 최대 1024개까지Accept Queue에 보관할 수 있다"고 설정합니다."힌트(hint)"라고 부르는 이유
본문에서 "힌트"라고 표현한 이유는, 프로그래머가
backlog값을 1024로 설정하더라도 커널이 그 값을 그대로 사용하지 않을 수 있기 때문입니다. -
커널에는 시스템 전체에서 허용하는
Accept Queue의 최대 크기 제한(net.core.somaxconn)이 따로 있습니다. -
만약
net.core.somaxconn이 512로 설정되어 있는데 프로그래머가backlog를 1024로 요청하면, 커널은 이 값을 512로 조정(clamp)합니다. -
따라서
backlog는 "이만큼 필요합니다"라는 요청(힌트)이며, 실제 크기는 커널의 정책에 따라 결정됩니다.만약
Accept Queue가 꽉 차면?서버 프로그램이
accept()를 충분히 빨리 호출하지 못해서Accept Queue가backlog크기만큼 꽉 차버리면 어떻게 될까요? -
이때 클라이언트로부터 마지막
ACK가 도착해도, 커널은 이 연결을Accept Queue에 넣을 수 없습니다. -
커널은 이
ACK를 일단 무시(drop)합니다. (연결을SYN Queue에 그대로 둡니다.) -
클라이언트 입장에서는
ACK가 유실된 것으로 보이므로, 잠시 후ACK를 재전송합니다. -
이것이 바로
Accept Queue가 가득 찼을 때 서버가 새로운 연결 수립을 지연시키는 방식입니다. (SYN Queue까지 가득 차면, 그때는SYN패킷 자체를 무시하여 클라이언트에게 "Connection refused"가 발생합니다.)요약:
backlog는 서버 프로그램이accept()로 처리하는 속도(소비 속도)와 클라이언트가 연결을 요청하는 속도(생산 속도) 사이의 버퍼(buffer) 크기를 지정하는 중요한 값입니다.
- 클라이언트 → 서버:
11.4.6 The accept Function
서버는 accept 함수를 호출하여 클라이언트의 연결 요청을 기다립니다.
#include <sys/socket.h>
int accept(int listenfd, struct sockaddr *addr, int *addrlen);- 반환 값: 성공 시 0 이상의 연결된 디스크립터(connected descriptor), 오류 시 -1
accept 함수는 수신 디스크립터(listening descriptor) listenfd로 클라이언트의 연결 요청이 도착하기를 기다립니다.
요청이 도착하면, addr에 클라이언트의 소켓 주소를 채워 넣습니다.
그런 다음, Unix I/O 함수를 사용해 클라이언트와 통신하는 데 사용할 수 있는 연결된 디스크립터를 반환합니다.
수신 디스크립터 vs 연결 디스크립터
- 수신 디스크립터(Listening Descriptor)와 연결된 디스크립터(Connected Descriptor)의 구분은 많은 학생들을 혼란스럽게 합니다.
- 수신 디스크립터 (Listening Descriptor)
- 클라이언트 연결 요청을 위한 종단점 (일종의 '접수 창구') 역할을 합니다.
- 일반적으로 서버의 생명주기 동안 한 번만 생성되어 계속 존재합니다.
- 연결된 디스크립터 (Connected Descriptor)
- 클라이언트와 서버 간에 수립된 실제 연결의 종단점 (일종의 '전용 통화선')입니다.
- 서버가 연결 요청을 수락(accept)할 때마다 새로 생성됩니다.
- 서버가 해당 클라이언트를 서비스하는 동안에만 존재합니다.
연결 과정 (그림 11.14)
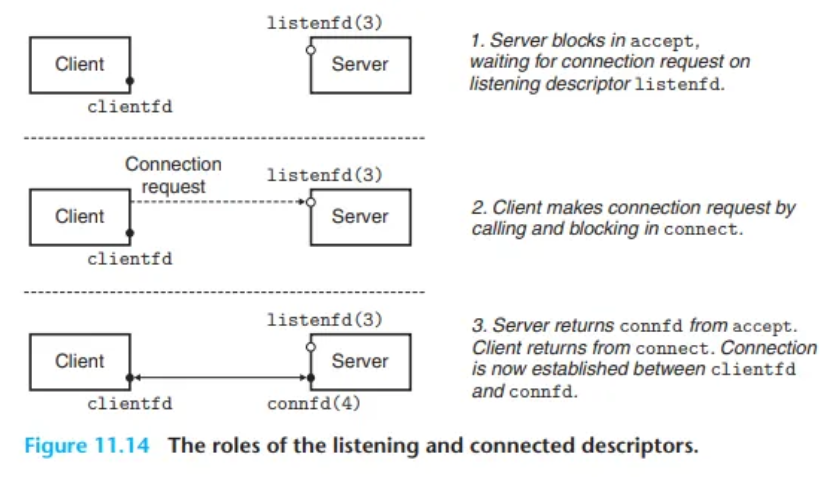
- 서버는
listenfd(예: 디스크립터 3 - 0~2는 표준 파일용)에 대해accept를 호출하고 대기(wait)합니다. - 클라이언트는
connect함수를 호출하여, 서버의listenfd로 연결 요청을 보냅니다. accept함수는:- 새로운 연결된 디스크립터
connfd(예: 디스크립터 4)를 엽니다. clientfd와connfd간의 연결을 수립합니다.connfd(4)를 서버 애플리케이션에 반환합니다.
- 새로운 연결된 디스크립터
- 클라이언트도
connect함수에서 반환됩니다. 이 시점부터 클라이언트와 서버는 각각clientfd와connfd에 데이터를 읽고 쓰면서 통신할 수 있습니다.
11.4.7 호스트 및 서비스 변환 (Host and Service Conversion)
리눅스는 getaddrinfo와 getnameinfo라는 강력한 함수들을 제공합니다.
이 함수들은 바이너리 소켓 주소 구조체(binary socket address structures)와, 호스트 이름, 호스트 주소, 서비스 이름, 포트 번호의 문자열 표현(string representations) 간의 상호 변환을 수행합니다.
이 함수들을 소켓 인터페이스와 함께 사용하면, IP 프로토콜의 특정 버전에 독립적인(protocol-independent) 네트워크 프로그램을 작성할 수 있습니다.
11.4.7 호스트 및 서비스 변환 (Host and Service Conversion)
리눅스는 바이너리 소켓 주소 구조체와, 호스트 이름/주소, 서비스 이름/포트 번호의 문자열 표현 간의 상호 변환을 수행하는 getaddrinfo 및 getnameinfo 함수를 제공합니다.
이 함수들은 소켓 인터페이스와 함께 사용될 때, IP 프로토콜의 특정 버전에 독립적인(protocol-independent) 네트워크 프로그램을 작성할 수 있게 해줍니다.
The getaddrinfo Function
getaddrinfo 함수는 호스트 이름, 호스트 주소, 서비스 이름, 포트 번호의 문자열 표현을 소켓 주소 구조체로 변환합니다.
- 이는 더 이상 사용되지 않는(obsolete)
gethostbyname,getservbyname함수를 대체하는 현대적인 함수입니다. getaddrinfo는 재진입 가능(reentrant)하며(12.7.2절 참조) 모든 프로토콜(IPv4/IPv6)과 함께 작동합니다.
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
int getaddrinfo(const char *host, const char *service,
const struct addrinfo *hints,
struct addrinfo **result);
// 반환 값: 성공 시 0, 오류 시 0이 아닌 에러 코드
void freeaddrinfo(struct addrinfo *result);
// 반환 값: 없음 (할당된 메모리 해제)
const char *gai_strerror(int errcode);
// 반환 값: 에러 메시지 문자열getaddrinfo는 host(호스트)와 service(서비스)를 입력받아, result가 addrinfo 구조체의 연결 리스트(linked list)를 가리키도록 반환합니다. 이 리스트의 각 노드는 host와 service에 해당하는 소켓 주소 구조체를 가리킵니다 (그림 11.15).
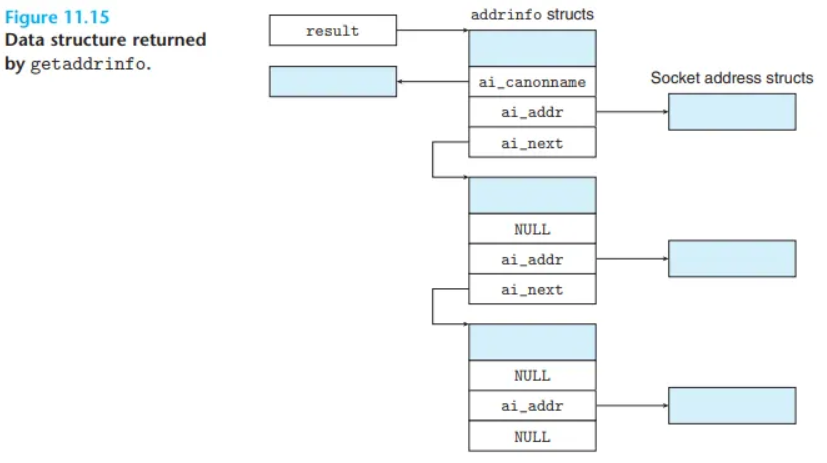
- 클라이언트:
getaddrinfo호출 후,socket과connect가 성공할 때까지 이 리스트를 순회하며 각 소켓 주소를 시도합니다. - 서버:
socket과bind가 성공할 때까지 이 리스트를 순회하며 각 소켓 주소를 시도합니다. - 메모리 누수 방지: 애플리케이션은 작업 완료 후 반드시
freeaddrinfo를 호출하여 리스트 메모리를 해제해야 합니다. - 오류 처리:
getaddrinfo가 0이 아닌 에러 코드를 반환하면,gai_strerror를 호출하여 메시지 문자열로 변환할 수 있습니다.
getaddrinfo 인자 상세
-
host: 도메인 이름 (www.google.com) 또는 숫자 주소 (128.2.194.242)가 될 수 있습니다. (NULL 가능) -
service: 서비스 이름 (http) 또는 10진수 포트 번호 (80)가 될 수 있습니다. (NULL 가능) -
(단,
host와service중 적어도 하나는 지정되어야 합니다.) -
hints(옵션):getaddrinfo가 반환할 소켓 주소 리스트를 제어하기 위한addrinfo구조체입니다 ([그림 11.16] 참조).
hints인자로 사용할 때는ai_family,ai_socktype,ai_protocol,ai_flags필드만 설정할 수 있습니다. (나머지는 0 또는 NULL이어야 함)- (실제로는
memset으로 구조체 전체를 0으로 초기화한 뒤, 필요한 필드만 설정합니다.)
-
hints의 주요 필드 설정:ai_family:- 기본값: IPv4와 IPv6 주소 모두 반환.
AF_INET: 리스트를 IPv4 주소로 제한.AF_INET6: 리스트를 IPv6 주소로 제한.
ai_socktype:- 기본값: 각 주소마다 최대 3개(connection, datagram, raw)의
addrinfo구조체를 반환할 수 있음. SOCK_STREAM: 리스트를 연결(connection)의 종단점으로 사용될 수 있는 소켓 주소(즉, TCP)로 제한합니다. (이 책의 모든 예제 프로그램에 해당)
- 기본값: 각 주소마다 최대 3개(connection, datagram, raw)의
ai_flags: (비트 마스크)AI_ADDRCONFIG: (연결 사용 시 권장) 로컬 호스트가 IPv4로 설정된 경우에만 IPv4 주소를 반환합니다 (IPv6도 마찬가지).AI_CANONNAME: 설정 시, 리스트의 첫 번째addrinfo구조체의ai_canonname필드가host의 공식(canonical) 이름을 가리키도록 합니다.AI_NUMERICSERV:service인자가 서비스 이름("http")이 아닌 반드시 포트 번호 문자열("80")이어야 하도록 강제합니다.AI_PASSIVE: (서버용)getaddrinfo가 (클라이언트의connect용) 능동 소켓 주소 대신, (서버의bind용) 수신 소켓 주소를 반환하도록 지시합니다.- 이 플래그 사용 시,
host인자는NULL이어야 합니다. - 결과로 반환되는 소켓 주소 구조체 내의 주소는 와일드카드 주소(wildcard address)가 됩니다. 이는 서버가 이 호스트의 모든 IP 주소로 오는 요청을 수락하겠다는 의미입니다. (이 책의 모든 서버 예제에 해당)
- 이 플래그 사용 시,
결과 (Result) 및 프로토콜 독립성
getaddrinfo가 생성하는 addrinfo 구조체 리스트의 각 필드는 다음과 같습니다.
ai_addr: 소켓 주소 구조체(sockaddr_in등)를 가리킵니다.ai_addrlen:ai_addr이 가리키는 구조체의 크기입니다.ai_next: 리스트의 다음addrinfo노드를 가리킵니다.
getaddrinfo의 강력한 점은, 반환된 addrinfo 구조체의 필드들이 애플리케이션 코드의 추가 조작 없이 소켓 인터페이스 함수에 직접 전달될 수 있다는 것입니다.
- 예:
ai_family,ai_socktype,ai_protocol➔socket()함수에 직접 전달 - 예:
ai_addr,ai_addrlen➔connect()또는bind()함수에 직접 전달
이 강력한 속성 덕분에, 우리는 IP 프로토콜의 특정 버전에 독립적인(protocol-independent) 클라이언트와 서버를 작성할 수 있습니다.
