
1. CSAPP 2.2
2.2 정수의 표현 (Integer Representations)
이 섹션에서는 비트를 사용하여 정수를 인코딩하는 두 가지 방법을 설명합니다. 하나는 음수가 아닌 수(0과 양수)만 표현하는 방식이고, 다른 하나는 음수, 0, 양수를 모두 표현하는 방식입니다.
1. 정수형 데이터 타입 (Integral Data Types)
C언어는 정수의 유한한 범위를 표현하는 다양한 정수형 데이터 타입을 지원합니다. 각 타입은 char, short, long 같은 키워드로 크기를 지정할 수 있으며, unsigned 키워드를 통해 음수가 없는 수만 표현할지, 아니면 기본값인 부호 있는 수로 사용할지 결정할 수 있습니다.
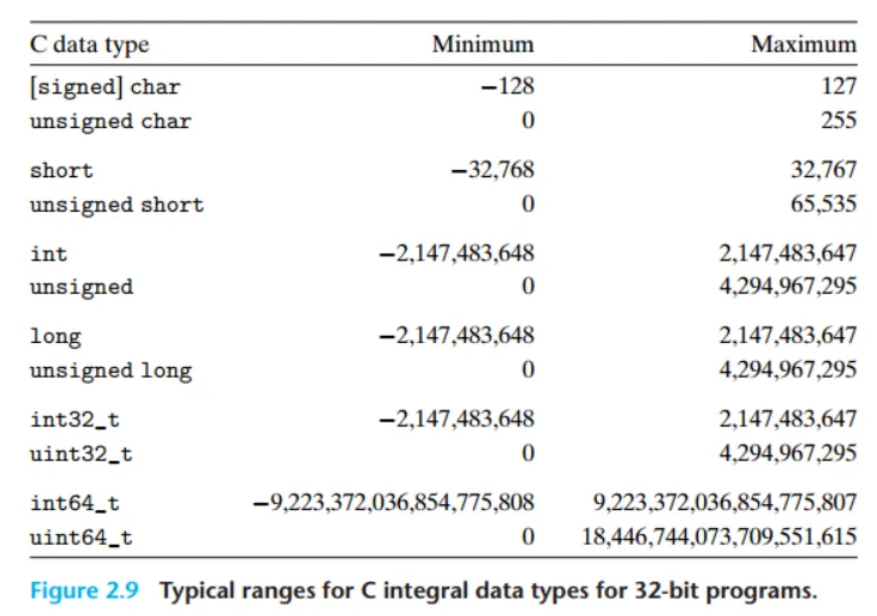
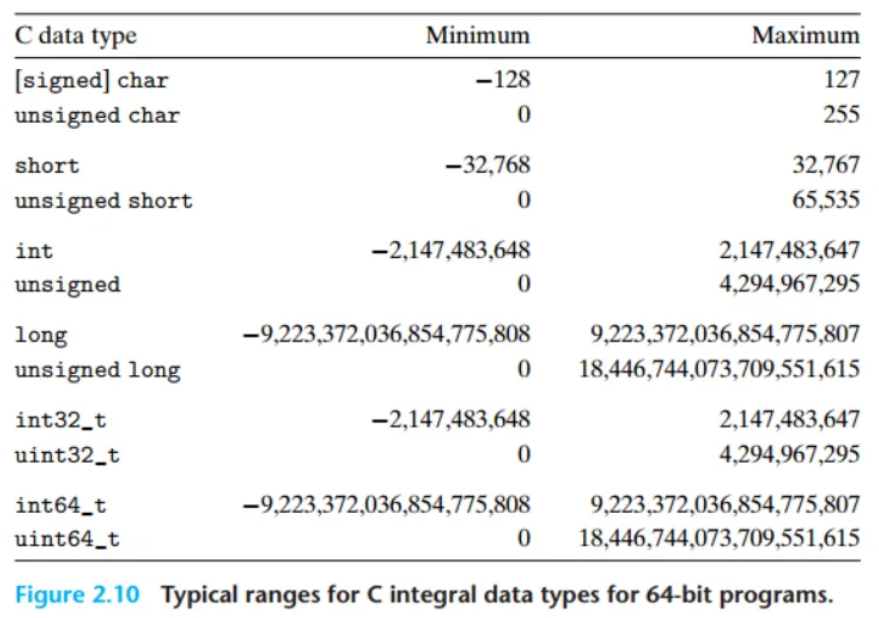
일반적인 32비트/64비트 프로그램에서의 정수 표현 범위
C언어 자료형의 실제 크기와 표현 범위는 프로그램이 32비트용인지 64비트용인지에 따라 달라질 수 있습니다.
- 32비트 프로그램과 64비트 프로그램의 주요 차이점:
long타입: 32비트 프로그램에서는 보통 4바이트, 64비트 프로그램에서는 8바이트를 사용합니다. 이 때문에 64비트 프로그램의long타입이 훨씬 더 넓은 범위의 수를 표현할 수 있습니다.- 포인터 타입 (
char *등): 32비트에서는 4바이트, 64비트에서는 8바이트입니다. (이전 섹션 내용) int타입: 64비트 프로그램에서도 보통 32비트와의 호환성을 위해 4바이트를 유지합니다.
- 중요한 특징 (비대칭적 범위):
char,short,int,long과 같은 부호 있는(signed) 정수형의 표현 범위를 보면, 음수의 범위가 양수의 범위보다 1만큼 더 넓습니다. (예:char는 -128 ~ +127) 이 이유는 음수를 표현하는 방식 때문이며, 이후 섹션에서 자세히 다뤄집니다.
C 표준이 보장하는 최소 범위
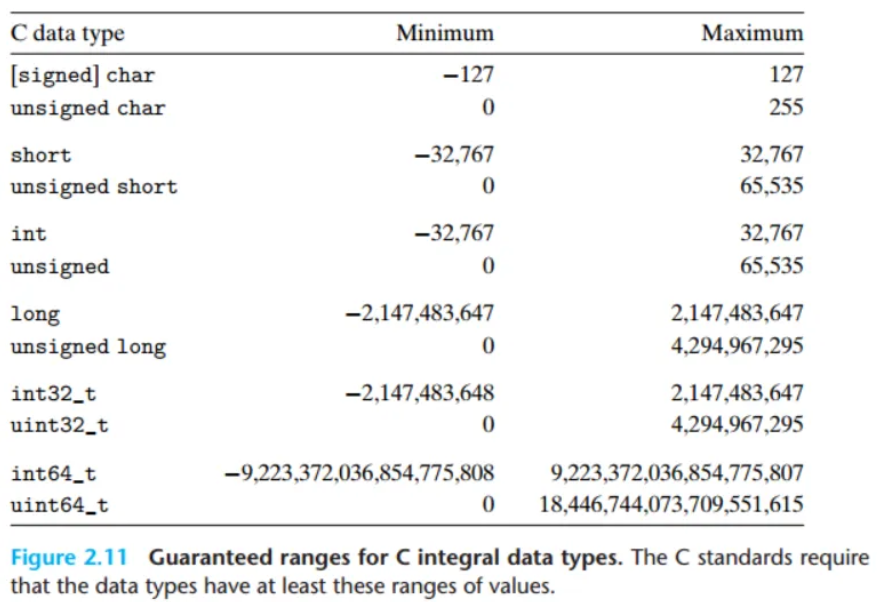
C언어 표준은 각 데이터 타입이 '최소한 이 범위는 보장해야 한다'고 정의합니다. 실제 대부분의 컴퓨터는 이 최소 보장 범위보다 더 넓은 범위를 지원합니다.
- 최소 보장 범위의 특징:
- 부호 있는 정수형에 대해 대칭적인 범위를 요구합니다. (예:
int는 최소 -32,767 ~ +32,767) int가 2바이트로 구현될 수도 있음을 허용하는데, 이는 16비트 머신 시절의 흔적입니다.long이 4바이트로 구현될 수 있음을 허용하며, 32비트 프로그램에서는 실제로 그렇게 구현됩니다.
- 부호 있는 정수형에 대해 대칭적인 범위를 요구합니다. (예:
결론적으로, 프로그래머는 int나 long 같은 기본 자료형의 크기가 컴파일 환경에 따라 변할 수 있다는 점을 인지해야 하며, 크기에 의존하지 않는 프로그램을 작성하거나 int32_t, int64_t 같은 고정 크기 자료형을 사용하여 이식성을 높이는 것이 좋습니다.
2.2.2 부호 없는 수의 인코딩 (Unsigned Encodings)
w비트 정수 데이터 타입을 생각해 봅시다. 비트 벡터 를 [$x_{w-1}$, $x_{w-2}$, ..., $x_0$] 와 같이 각 비트로 표현할 때, 이를 이진법 표기법으로 취급하면 부호 없는(unsigned) 정수 값을 얻을 수 있습니다.
1. 부호 없는 인코딩의 정의
w비트로 이루어진 비트 벡터 를 부호 없는 정수로 변환하는 함수 (Binary to Unsigned)는 다음과 같이 정의됩니다.
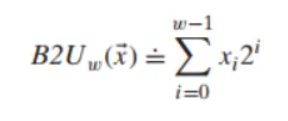
이 수식은 각 비트 위치 i의 비트 값(, 0 또는 1)에 그 자릿값()을 곱한 것을 모두 더한다는 의미입니다. 즉, 우리가 흔히 아는 2진수를 10진수로 변환하는 방법과 같습니다.
- 예시 (w=4):
B2U₄([0001])= 0⋅8+0⋅4+0⋅2+1⋅1=1B2U₄([0101])= 0⋅8+1⋅4+0⋅2+1⋅1=5B2U₄([1011])= 1⋅8+0⋅4+1⋅2+1⋅1=11B2U₄([1111])= 1⋅8+1⋅4+1⋅2+1⋅1=15
2. 표현 가능한 값의 범위
w비트를 사용한 부호 없는 인코딩으로 표현할 수 있는 값의 범위는 다음과 같습니다.
- 최소값: 모든 비트가 0인
[00...0]이며, 정수 값은 0입니다. - 최대값: 모든 비트가 1인
[11...1]이며, 정수 값 는 입니다.- 4비트의 경우, = = 15
- 8비트의 경우, = = 255
3. 부호 없는 인코딩의 유일성 (Bijection)
부호 없는 이진 표현 방식의 중요한 특징은 0부터 까지의 모든 정수가 각각 고유한 w비트 인코딩을 가진다는 점입니다. 즉, 하나의 숫자를 표현하는 비트 패턴은 단 하나뿐이며, 그 반대도 마찬가지입니다.
이를 수학적으로 '전단사 함수(bijection)'라고 합니다. 이는 정수를 비트 벡터로, 또는 비트 벡터를 정수로 언제든지 유일하게 상호 변환할 수 있음을 의미합니다.
- : w비트 이진수 → 부호 없는 정수
- : 부호 없는 정수 → w비트 이진수 (의 역함수)
2.2.3 2의 보수 인코딩 (Two’s-Complement Encodings)
음수를 포함한 정수를 표현하기 위해 컴퓨터에서 가장 널리 사용되는 방식은 2의 보수(two's-complement) 형태입니다. 이 방식은 최상위 비트(MSB)를 음수의 가중치로 해석하는 것이 핵심입니다.
1. 2의 보수 인코딩의 정의
w비트 벡터 를 2의 보수 정수로 변환하는 함수 (Binary to Two's-complement)는 다음과 같이 정의됩니다.
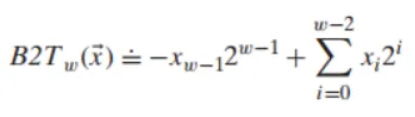
- 최상위 비트 (): 부호 비트(sign bit)라고 부릅니다.
- 부호 비트가 1이면 그 값은 음수가 됩니다. (가중치가 이기 때문)
- 부호 비트가 0이면 그 값은 음수가 아닌 수(0 또는 양수)가 됩니다.
- 나머지 비트들은 부호 없는 인코딩과 동일하게 양수의 가중치를 가집니다.
- 예시 (w=4):
B2T₄([0101])= −0⋅8+1⋅4+0⋅2+1⋅1=5B2T₄([1011])= −1⋅8+0⋅4+1⋅2+1⋅1=−8+3=−5B2T₄([1111])= −1⋅8+1⋅4+1⋅2+1⋅1=−8+7=−1
2. 표현 가능한 값의 범위
w비트 2의 보수 숫자로 표현할 수 있는 값의 범위는 다음과 같습니다.
- 최소값 (): 부호 비트만 1이고 나머지는 모두 0인
[10...0]입니다. 값은 입니다. - 최대값 (): 부호 비트는 0이고 나머지는 모두 1인
[01...1]입니다. 값은 입니다.- 4비트의 경우: = -8, = 7
- 8비트의 경우: = -128, = 127
3. 2의 보수 표현의 특징
- 비대칭적 범위: 표현 가능한 음수의 범위가 양수의 범위보다 1만큼 더 넓습니다 (
|TMin| = TMax + 1). 이는 0이 음수가 아닌 수에 포함되기 때문에 발생하며, 미묘한 프로그램 버그의 원인이 될 수 있습니다. - 1과 0의 표현:
- 1은 모든 비트가 1인
[11...1]로 표현됩니다. 이는 부호 없는 수의 최대값(UMax)과 비트 패턴이 동일합니다. - 0은 모든 비트가 0인
[00...0]으로 표현됩니다.
- 1은 모든 비트가 1인
- C언어와 Java:
- C언어 표준은 부호 있는 정수를 반드시 2의 보수로 표현하도록 강제하지는 않지만, 거의 모든 현대 컴퓨터는 2의 보수 방식을 사용합니다.
- Java는 정수 자료형을 2의 보수로 명확히 정의하여, 어떤 머신에서 실행되더라도 동일하게 동작하도록 보장합니다.
4. 2의 보수 인코딩의 유일성 (Uniqueness)
원칙: 함수 는 전단사 함수(bijection)이다.
이 원칙은 w비트로 표현 가능한 2의 보수 정수 범위 내의 모든 숫자는 각각 고유한 비트 패턴을 가진다는 것을 의미합니다. 즉, 하나의 숫자를 표현하는 비트 패턴은 단 하나뿐이며, 그 반대도 마찬가지입니다.
1. 전단사 함수(Bijection)의 의미
'전단사'란 두 집합 사이의 완벽한 '일대일 대응' 관계를 말합니다.
- w비트로 만들 수 있는 모든 비트 패턴의 집합과
- w비트 2의 보수로 표현 가능한 모든 정수의 집합(
TMin부터TMax까지)
이 두 집합은 원소의 개수가 개로 정확히 같으며, 서로 하나씩 빠짐없이, 겹치지 않게 짝을 이룹니다. 이 덕분에 데이터 변환 시 모호함이나 손실이 전혀 없습니다.
2. 역함수 의 존재
$B2T_w$ 함수가 완벽한 일대일 대응 관계(전단사)이므로, 그 관계를 거꾸로 되돌리는 역함수가 반드시 존재합니다. 이 역함수를 (Two's-complement to Binary)라고 정의합니다.
- (Binary → Two's-complement):
비트 패턴을 2의 보수 정수로 해석(decode)하는 함수입니다.
(예:[1111]→1) - (Two's-complement → Binary):
2의 보수 정수를 비트 패턴으로 인코딩(encode)하는 함수입니다.
(예:1→[1111])
2.2.4 부호 있는 정수와 부호 없는 정수 간의 변환
C언어는 서로 다른 숫자 자료형 간의 형 변환(casting)을 허용합니다. 부호 있는 int를 unsigned로 바꾸거나, 그 반대의 경우 어떤 일이 일어날까요?
C언어는 수학적인 관점(음수는 0으로 변환)이 아니라, 비트 수준(bit-level)의 관점에서 형 변환을 처리합니다.
1. 형 변환의 기본 원칙: 비트 패턴은 그대로, 해석만 바뀐다.
같은 워드 크기를 가진 부호 있는(signed) 정수와 부호 없는(unsigned) 정수 사이의 형 변환에서, 숫자 값은 바뀔 수 있지만 기저의 비트 패턴은 절대 변하지 않습니다.
- 예시 1: signed → unsigned
short int v = -12345;
unsigned short uv = (unsigned short) v;
// 출력: v = -12345, uv = 53191short 타입 -12345의 16비트 2의 보수 표현은 [1100111111000111] (0xCFC7)입니다. 이 비트 패턴을 부호 없는 정수로 해석하면 숫자 53191이 됩니다. 형 변환은 이 해석 방식만 바꾼 것입니다.
- 예시 2: unsigned → signed
unsigned u = 4294967295u; // 32비트 부호 없는 정수의 최댓값
int tu = (int) u;
// 출력: u = 4294967295, tu = -132비트 부호 없는 정수 4294967295의 비트 표현은 모든 비트가 1인 [11...1]입니다. 이 비트 패턴을 부호 있는 정수(2의 보수)로 해석하면 숫자 -1이 됩니다.
2. 변환 관계의 수학적 표현
이러한 변환 관계는 수학적으로 다음과 같이 표현할 수 있습니다.
2의 보수 → 부호 없는 수 (T2U)
2의 보수 값 x를 부호 없는 값으로 변환할 때:
음수 는 를 더한 큰 양수가 됩니다. (예: -1 → -1 + $2^w$ = $UMax_w$)
양수와 0은 그대로 유지됩니다.
부호 없는 수 → 2의 보수 (U2T)
부호 없는 값 를 2의 보수 값으로 변환할 때:
(표현 가능한 최대 양수)보다 작거나 같은 수는 그대로 유지됩니다.
보다 큰 수는 를 뺀 음수가 됩니다.
결론적으로 C언어에서 부호 있는 타입과 없는 타입 간의 형 변환은 메모리에 있는 0과 1의 비트 패턴을 그대로 둔 채, 그 비트를 해석하는 숫자 체계(부호 없음 vs. 2의 보수)만 바꾸는 방식으로 동작합니다. 이 때문에 예상치 못한 큰 양수가 되거나 음수가 될 수 있어 주의가 필요합니다.
2.2.5 C언어에서의 부호 있는(Signed) vs. 부호 없는(Unsigned)
C언어는 모든 정수 자료형에 대해 부호 있는 연산과 부호 없는 연산을 모두 지원합니다. 별다른 지정이 없으면 모든 정수는 기본적으로 부호 있는(signed) 것으로 간주됩니다. 12345U처럼 숫자 뒤에 U나 u를 붙이면 부호 없는(unsigned) 상수가 됩니다.
1. 형 변환 규칙 (명시적/암묵적)
C언어에서는 부호 있는 값과 없는 값 사이의 변환이 가능합니다. 대부분의 시스템은 이 변환을 할 때, 기저의 비트 패턴은 그대로 유지하고 해석 방식만 바꾸는 규칙을 따릅니다.
이러한 형 변환은 두 가지 경우에 발생합니다.
- 명시적 형 변환 (Explicit Casting): 프로그래머가
(unsigned)나(int)처럼 직접 타입을 지정하는 경우입니다.
int tx;
unsigned ux;
tx = (int) ux;- 암묵적 형 변환 (Implicit Casting): 한 타입의 값을 다른 타입의 변수에 할당할 때 자동으로 발생합니다.
int ty;
unsigned uy;
uy = ty; // ty(signed)가 uy(unsigned)에 할당되면서 암묵적으로 unsigned로 변환됨`printf 함수는 %d(signed), %u(unsigned), %x(hex) 지시자를 통해 값을 출력하며, 변수의 실제 타입과 상관없이 지정된 지시자에 따라 비트 패턴을 해석합니다.
2. 부호 혼용 시 발생하는 문제 (⭐ 중요)
C언어에서 부호 있는 값과 부호 없는 값을 함께 사용하는 연산이 수행될 때, 프로그래머가 예상치 못한 결과가 발생할 수 있습니다.
규칙: 연산에 참여하는 두 값 중 하나라도 unsigned이면, C는 나머지 signed 값을 강제로 unsigned로 변환한 뒤 연산을 수행합니다.
이 규칙은 덧셈이나 곱셈 같은 산술 연산에서는 큰 문제가 없지만, <나 > 같은 관계 연산자(비교 연산자)에서는 직관에 어긋나는 결과를 만듭니다.
- 예시:C
1 < 0U- 사람의 예상:
1은0보다 작으므로 참(True)일 것이다. - 컴퓨터의 실제 동작:
0U가unsigned이므로,1을unsigned int로 암묵적 형 변환합니다.1의 비트 패턴(111...1)을unsigned로 해석하면 매우 큰 양수(4,294,967,295)가 됩니다.- 결과적으로
4294967295U < 0U를 비교하게 됩니다.
- 최종 결과: 거짓(False)
이처럼 부호 있는 값과 없는 값을 비교할 때는 음수가 의도치 않게 거대한 양수로 변환되어 비교 결과가 뒤바뀔 수 있으므로 각별한 주의가 필요합니다.
2.2.6 숫자의 비트 표현 확장하기
작은 데이터 타입의 정수를 큰 데이터 타입으로 변환하는 것은 값의 손실 없이 항상 가능해야 합니다. 이 과정은 부호 없는 수와 부호 있는 수에 따라 서로 다른 규칙을 따릅니다.
1. 부호 없는 수의 확장: 0 확장 (Zero Extension)
부호 없는(unsigned) 숫자를 더 큰 데이터 타입으로 변환할 때는, 비어있는 상위 비트들을 단순히 0으로 채웁니다. 이를 '0 확장'이라고 합니다.
- 원칙: 원래의
w비트 패턴[uw-1, ..., u0]을 더 큰w'비트로 확장하면[0, ..., 0, uw-1, ..., u0]이 됩니다. - 이유: 새로 추가된 0들은 숫자 값에 아무런 영향을 주지 않으므로, 원래의 값이 그대로 유지됩니다.
2. 2의 보수(부호 있는 수)의 확장: 부호 확장 (Sign Extension)
2의 보수(signed) 숫자를 더 큰 데이터 타입으로 변환할 때는, 원래 숫자의 최상위 비트(부호 비트)를 복사하여 비어있는 상위 비트들을 채웁니다. 이를 '부호 확장'이라고 합니다.
- 원칙: 원래의
w비트 패턴[xw-1, ..., x0]을 더 큰w'비트로 확장하면[xw-1, ..., xw-1, xw-1, ..., x0]이 됩니다. - 이유: 양수(부호 비트 0)는 0으로 채워지고, 음수(부호 비트 1)는 1로 채워져 원래의 숫자 값이 수학적으로 정확하게 유지됩니다.
예시: short를 int로 확장하기
16비트 short를 32비트 int로 확장하는 예시를 통해 두 규칙의 차이를 명확히 볼 수 있습니다.
- 16비트 원본 데이터:
short sx = -12345;→ 16진수CFC7unsigned short usx = 53191;→ 16진수CFC7
(두 값은 16비트에서는 동일한 비트 패턴을 가집니다.)
- 32비트로 확장한 결과:
int x = sx;(signed 확장)sx의 부호 비트(C의 첫 비트, 즉1)가 앞 16비트에 복사됩니다.- 결과:
FFFFCFC7(값은 여전히 -12345)
unsigned ux = usx;(unsigned 확장)usx는 부호가 없으므로 앞 16비트가0으로 채워집니다.- 결과:
0000CFC7(값은 여전히 53191)
C언어의 형 변환 순서 (⭐ 중요)
C언어에서 크기와 부호가 동시에 변하는 형 변환이 일어날 때, 크기 변경이 먼저, 그 다음 부호 변경이 일어납니다.
short sx = -12345;
unsigned int uy = sx; // short -> unsigned int이 코드는 다음과 같이 두 단계를 거쳐 실행됩니다.
- 크기 변경 (short → int):
sx(-12345)가 먼저signed int로 확장됩니다. 부호 확장이 일어나 32비트 값FFFFCFC7(-12345)가 됩니다. - 부호 변경 (int → unsigned int): 이 32비트 값
FFFFCFC7의 해석 방식만unsigned로 바뀝니다. 따라서uy는 매우 큰 양수인4,294,954,951이 됩니다.
만약 부호 변경 후 크기 변경이 일어났다면((unsigned short)로 먼저 변환), 결과는 53191이 되었을 것입니다. 하지만 C 표준은 크기 변경을 우선하도록 규정하고 있습니다.
2.2.7 숫자 잘라내기 (Truncating Numbers)
숫자를 더 큰 데이터 타입으로 확장하는 것과 반대로, 더 작은 데이터 타입으로 변환하여 비트의 수를 줄이는 경우가 있습니다. 이를 '잘라내기(Truncation)'라고 합니다.
예를 들어, 32비트 int를 16비트 short로 형 변환하면 상위 16개의 비트는 버려지고 하위 16개의 비트만 남게 됩니다.
int x = 53191; // 32비트: 0000 0000 0000 0000 1100 1111 1100 0111
short sx = (short) x; // 상위 16비트를 잘라냄. sx = -12345
// 16비트: 1100 1111 1100 0111
int y = sx; // 부호 확장으로 다시 32비트 int로 변환. y = -12345
// 32비트: 1111 1111 1111 1111 1100 1111 1100 0111이처럼 숫자를 잘라내면 원래의 값이 바뀔 수 있는데, 이는 일종의 오버플로우입니다.
1. 부호 없는 수의 잘라내기
w비트의 부호 없는 정수 x를 k비트로 잘라낸 결과 는 원래 값 x에 2k로 나눈 나머지와 같습니다.
- 원리: 잘려나가는 상위 비트들은 모두 2k보다 큰 자릿값(2k,2k+1,...)을 가집니다. 2k로 나눈 나머지를 구하는 연산에서 이 자릿값들은 모두 0이 되기 때문에, 결국 하위 k개의 비트 값만 남게 됩니다.
2. 2의 보수(부호 있는 수)의 잘라내기
w비트의 2의 보수 정수 x를 k비트로 잘라낸 결과 는, 먼저 x를 2k로 나눈 나머지를 구한 뒤, 그 결과를 k비트 2의 보수로 해석한 값과 같습니다.
- 원리: 를 계산하면 0부터 사이의 부호 없는 값이 나옵니다. 이 값의 비트 패턴은 원래 숫자의 하위 k개 비트와 동일합니다. 이 비트 패턴을 k비트 2의 보수로 다시 해석하면 최종 결과가 나옵니다.
- 예시:
intx = 53191을short(16비트)로 잘라낼 때-
53191
-
53191의 16비트 패턴은
11001111 11000111입니다. -
이 비트 패턴을 16비트 2의 보수로 해석(
U2T₁₆)하면 12,345가 됩니다.
-
결론적으로, 숫자를 더 작은 비트 크기로 잘라낼 때는 상위 비트들이 버려지면서 원래의 값과 전혀 다른 값이 될 수 있으며, 그 결과는 나머지(modulo) 연산으로 예측할 수 있습니다.
2.2.8 부호 있는(Signed) vs. 부호 없는(Unsigned) 수에 대한 조언
앞서 보았듯이, C언어에서 부호 있는 수가 부호 없는 수로 암묵적으로 형 변환될 때 직관에 어긋나는 동작이 발생할 수 있습니다. 이러한 동작은 버그의 원인이 되기 쉬우며, 특히 코드에 명확한 표시 없이 일어나기 때문에 프로그래머가 놓치기 쉽습니다.
1. unsigned 사용을 피해야 하는 이유
이러한 미묘한 버그를 피하는 한 가지 방법은 부호 없는(unsigned) 숫자를 아예 사용하지 않는 것입니다.
실제로 C/C++를 제외한 대부분의 프로그래밍 언어는 부호 없는 정수를 지원하지 않습니다. 다른 언어 설계자들은 부호 없는 정수가 유용함보다는 문제를 더 많이 일으킨다고 판단한 것입니다. 예를 들어, Java는 부호 있는 정수만 지원하며, 2의 보수 방식으로 구현하도록 명시하고 있습니다.
2. unsigned가 유용한 경우
그럼에도 불구하고, 부호 없는 값은 다음과 같은 특정 상황에서 매우 유용합니다.
- 비트 집합으로 사용할 때: 숫자의 의미 없이, 단지 여러 개의 비트 묶음으로 데이터를 다루고 싶을 때 유용합니다. 예를 들어, 하나의 워드에 여러 개의 ON/OFF 상태(플래그)를 저장하는 경우가 해당됩니다.
- 메모리 주소를 다룰 때: 메모리 주소는 본질적으로 음수 값을 갖지 않으므로, 시스템 프로그래머들은
unsigned타입을 유용하게 사용합니다. - 모듈러 연산 및 다중 정밀도 연산 구현: 수학 패키지에서 를 법으로 하는 모듈러 연산을 구현하거나, 매우 큰 숫자를 워드의 배열로 표현하여 계산할 때 부호 없는 산술 연산이 필요합니다.
2. 우선순위 큐
우선순위 큐를 구현하는 방법은 많지만 대표적으로 힙으로 구현할 수 있다.
힙은 완전 이진 트리이며 노드의 값이 부모 >= 자식 조건이 충족해야한다.
삽입
마지막 노드에 넣고 위 조건을 만족하도록 노드를 스왑해준다. 이를 업 힙이라고 하며 시간복잡도는 O(logN)이 된다.
삭제
루트 노드를 없애고 마지막 노드를 루트노드로 대체한다. 이후 다운 힙을 적용하며 힙 조건을 만족시키도록 한다. 이 역시 시간복잡도는 O(logN)이 된다.
따라서 힙으로 구현된 우선순위 큐에 경우 입력, 출력 모두 O(logN)이 된다는 것을 알 수 있다.
