
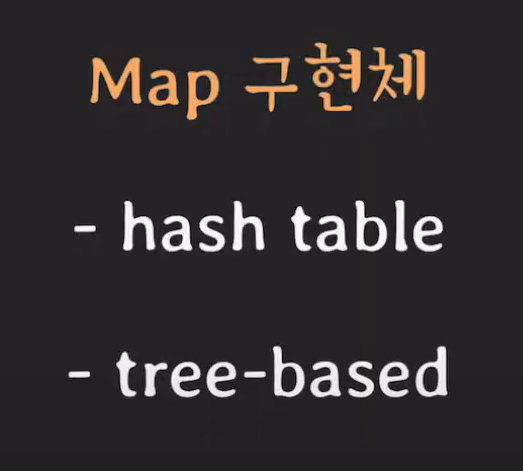
✏️ HashTable




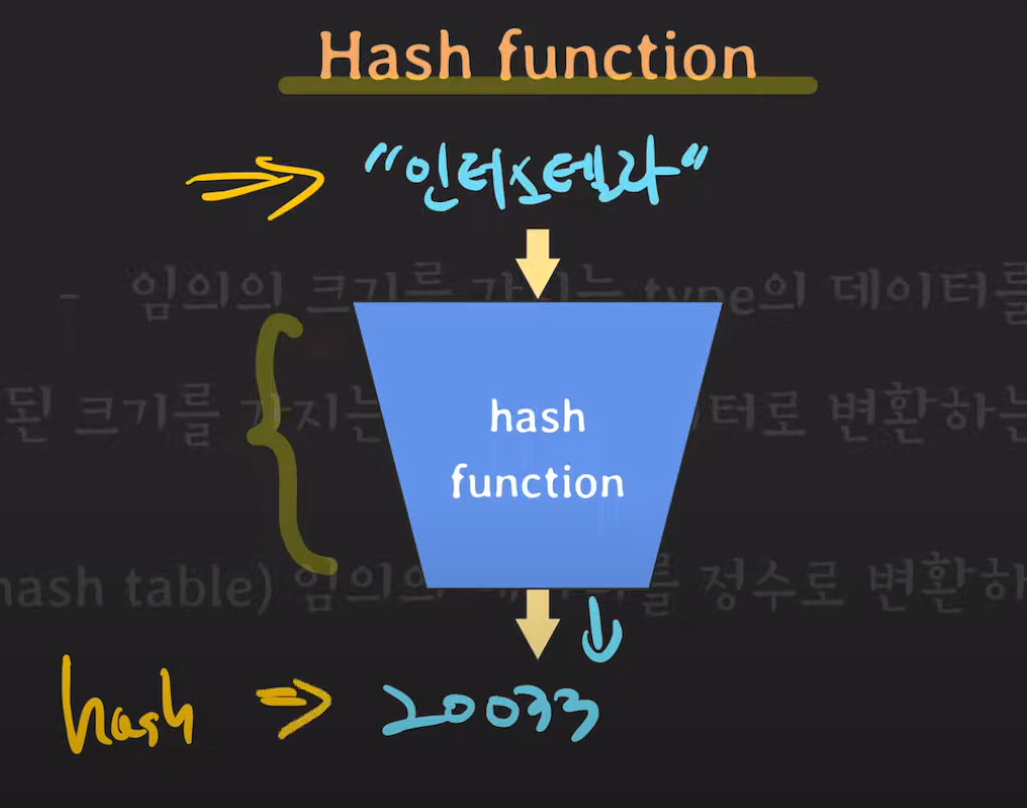
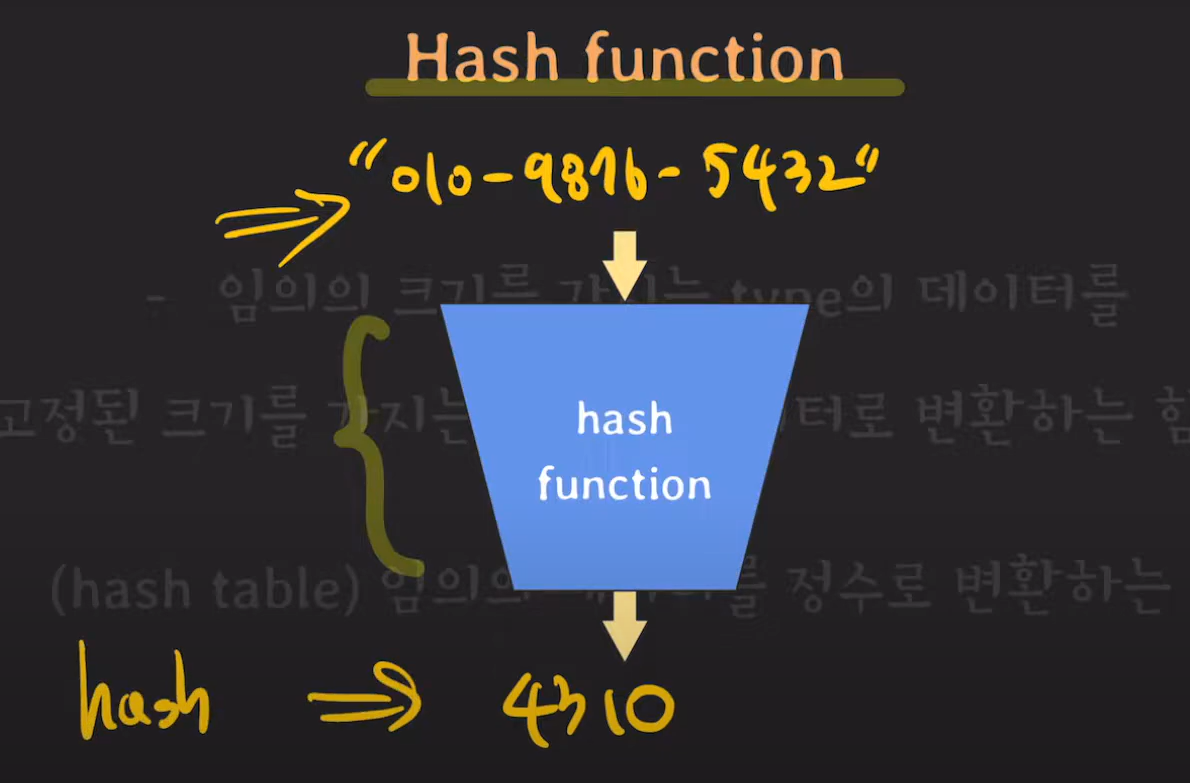


input을 축약하는 것이 Hash Function의 역할이기 때문에 Hash값은 겹칠 수 밖에 없습니다. 따라서 Output을 균등하게 만드는 것이 Hash Function을 구현할 때 중요한 점입니다.

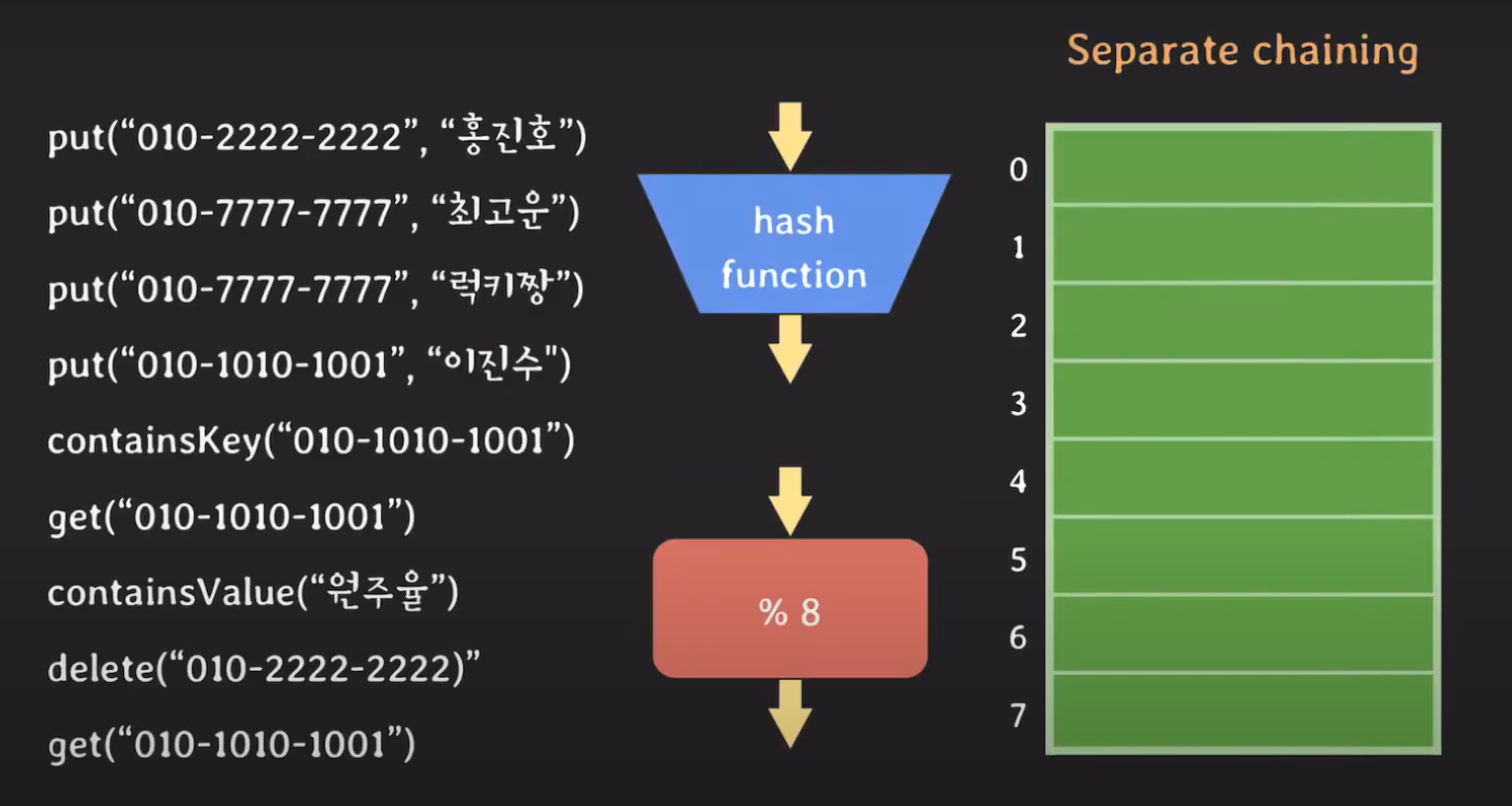
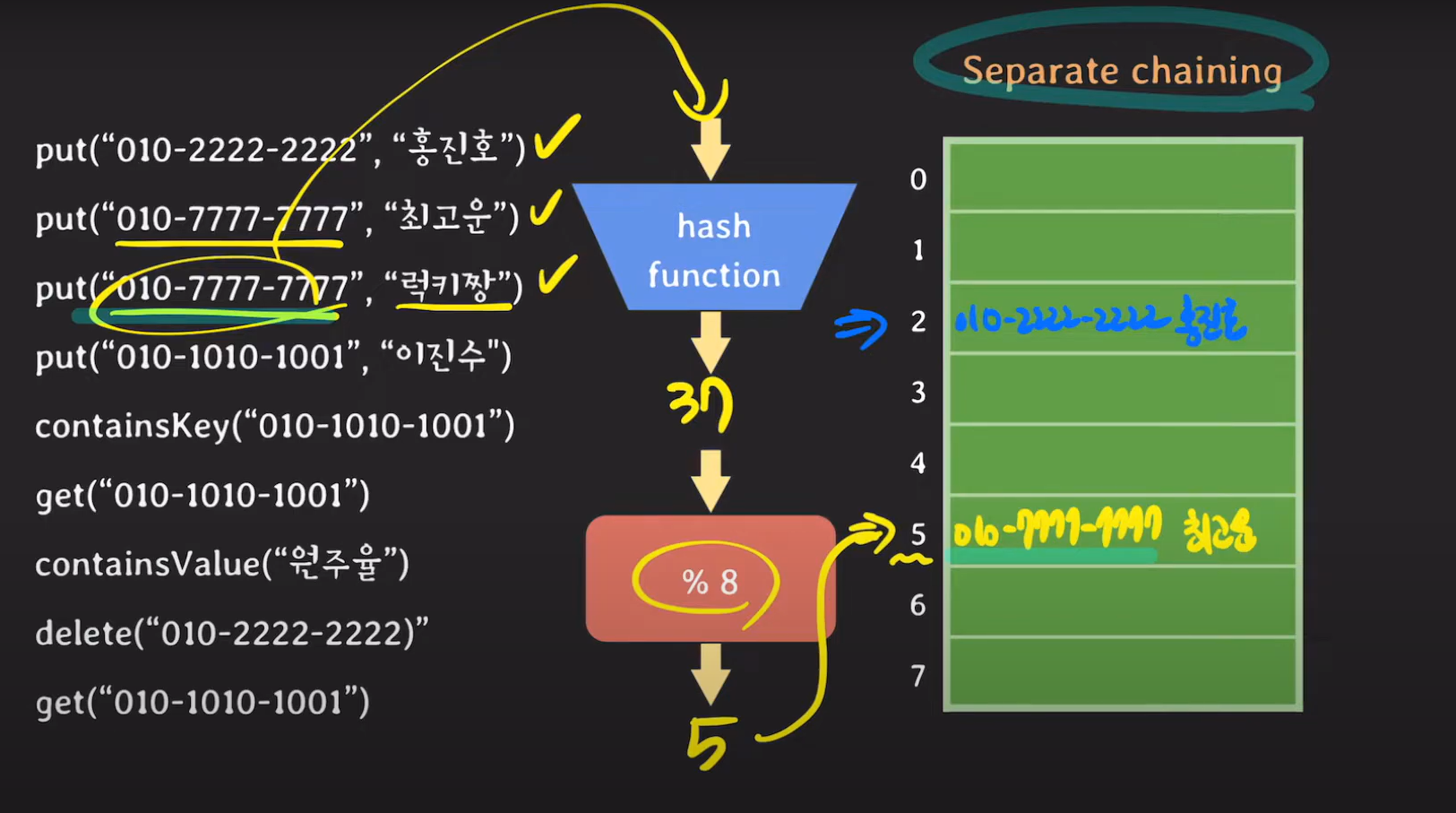
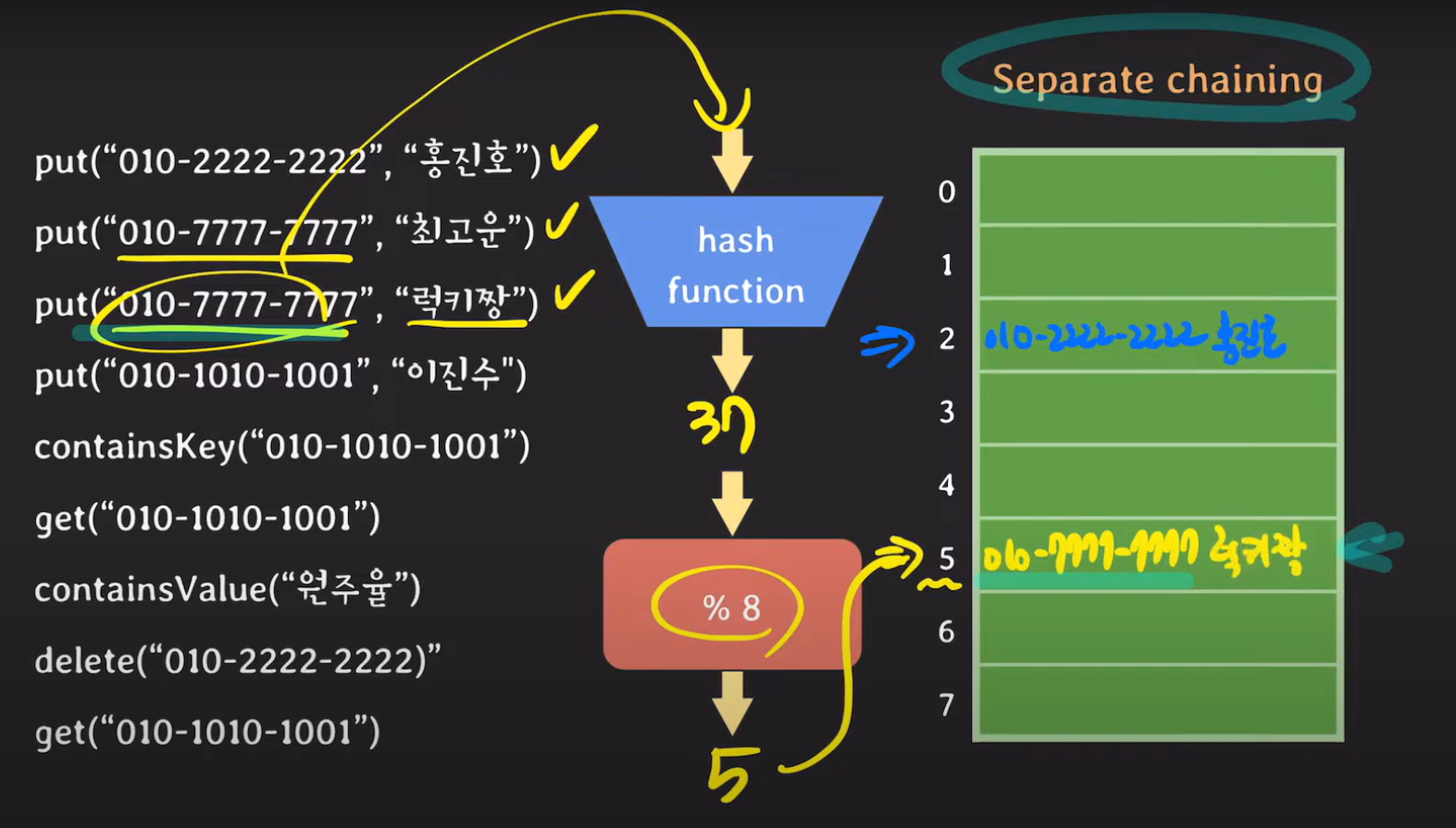
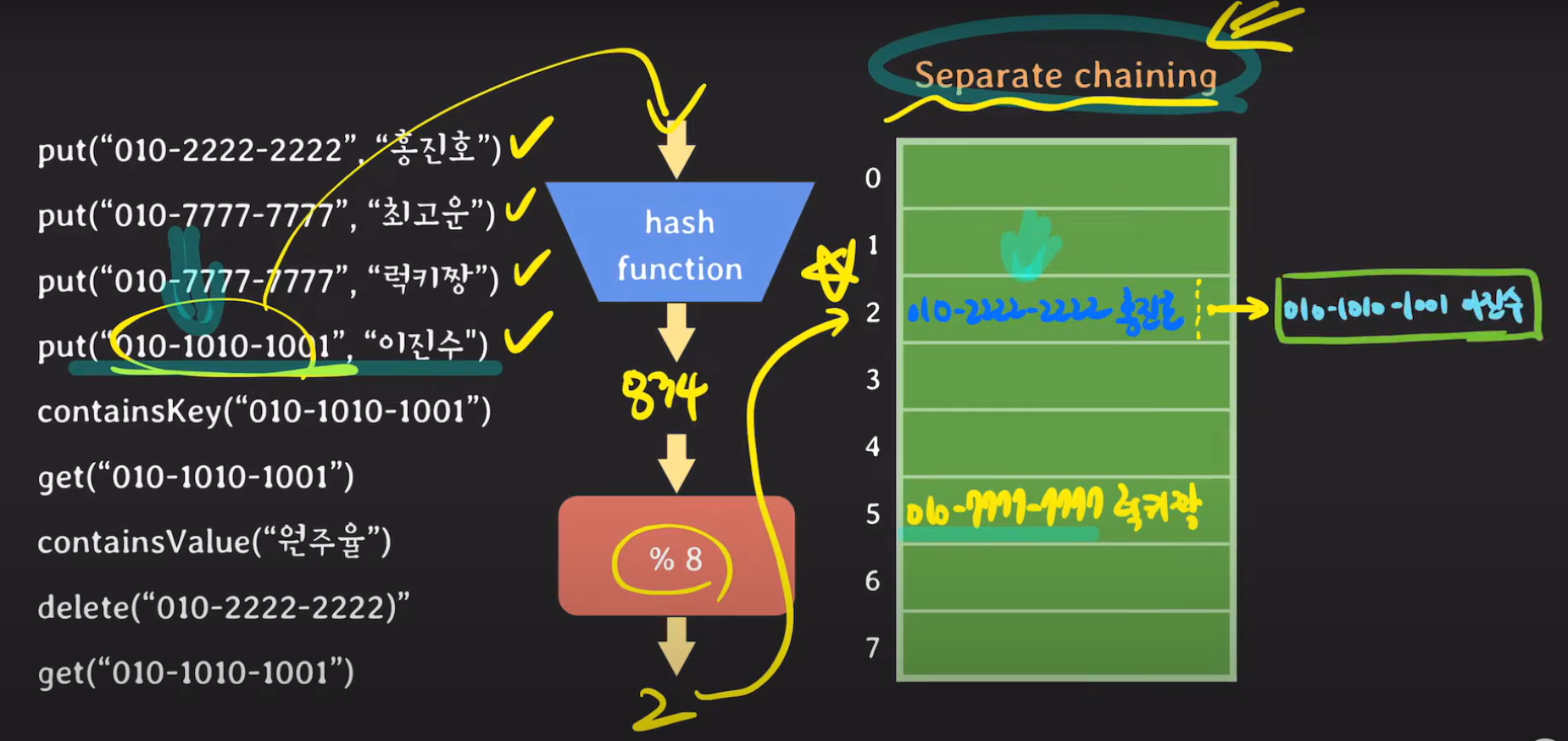
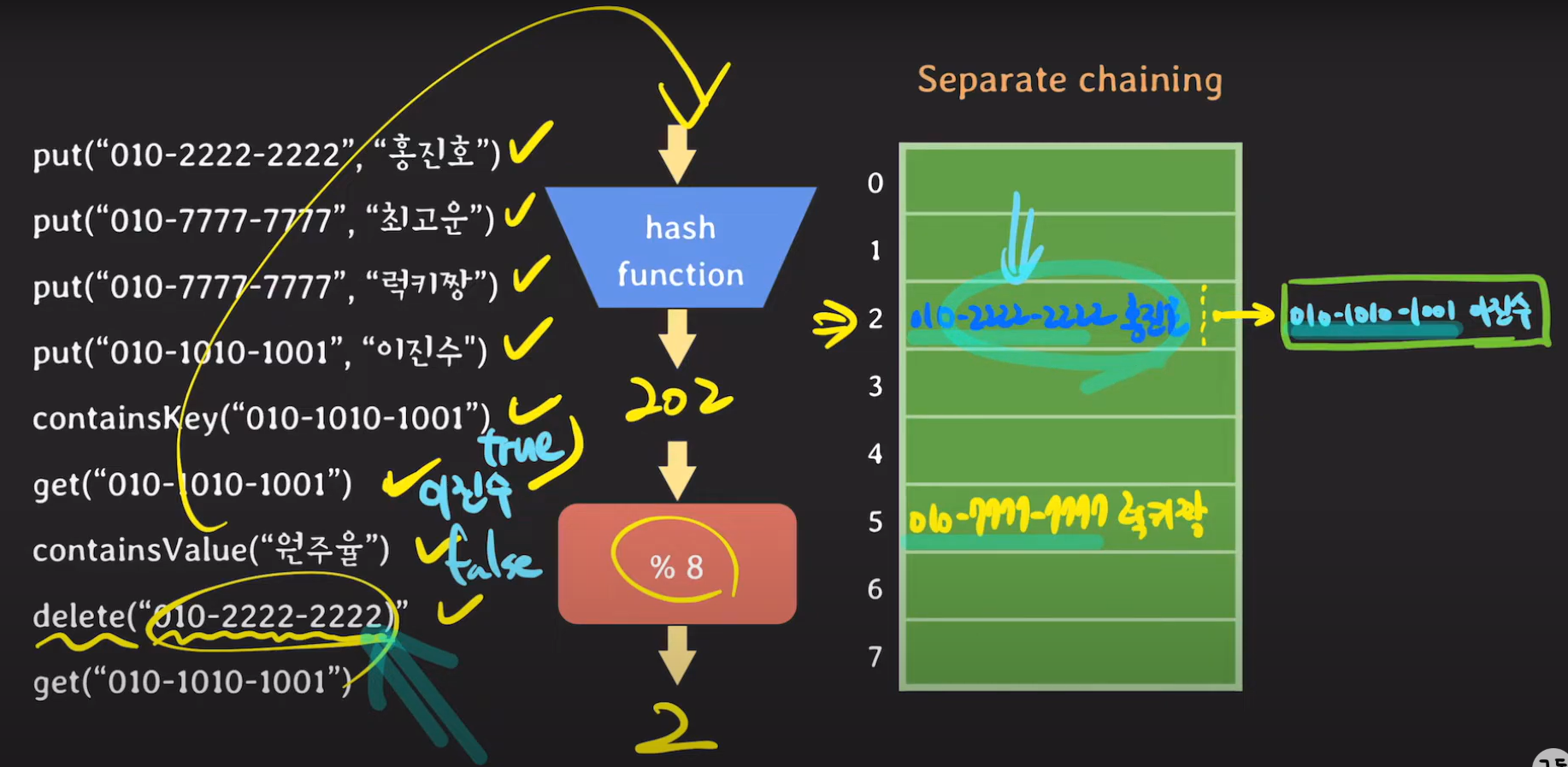
key 값이 달라 Hash Collision이 일어났다면 Separate chaining 방식에서는 연결 리스트로 데이터를 저장합니다.
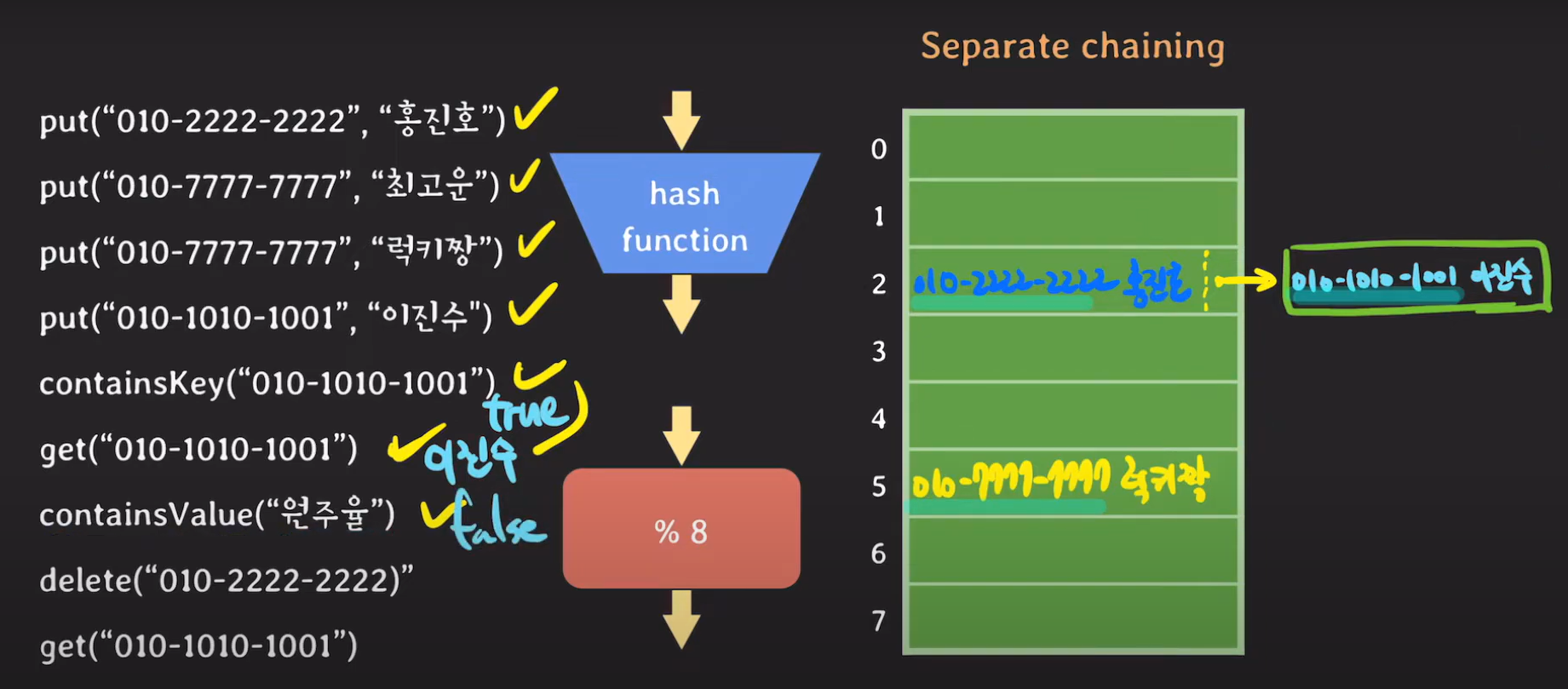
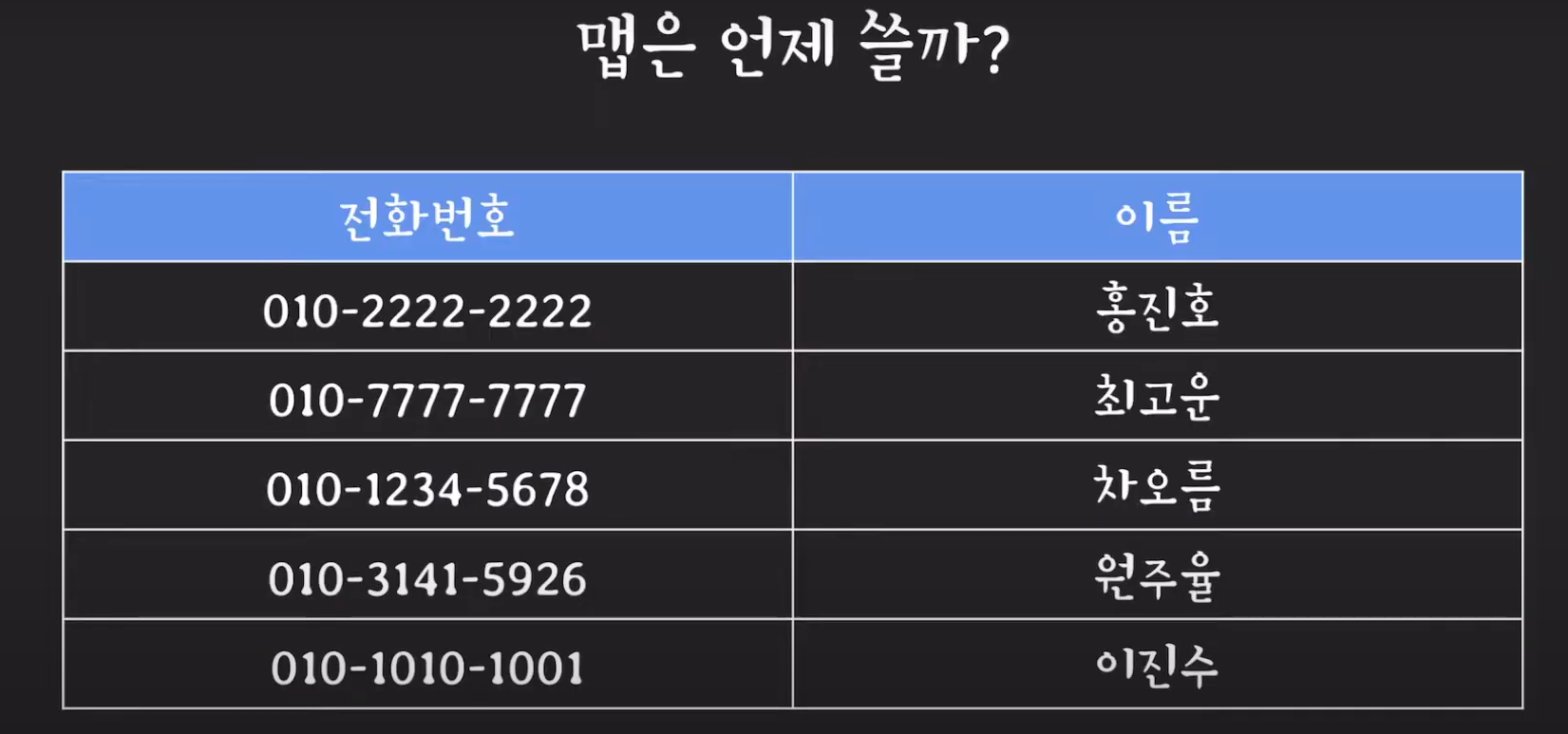
containsValue는 해당 값이 해시 테이블에 존재하는지 모두 확인한다. 지금은 "원주율"이 없기 때문에 false를 반환합니다.
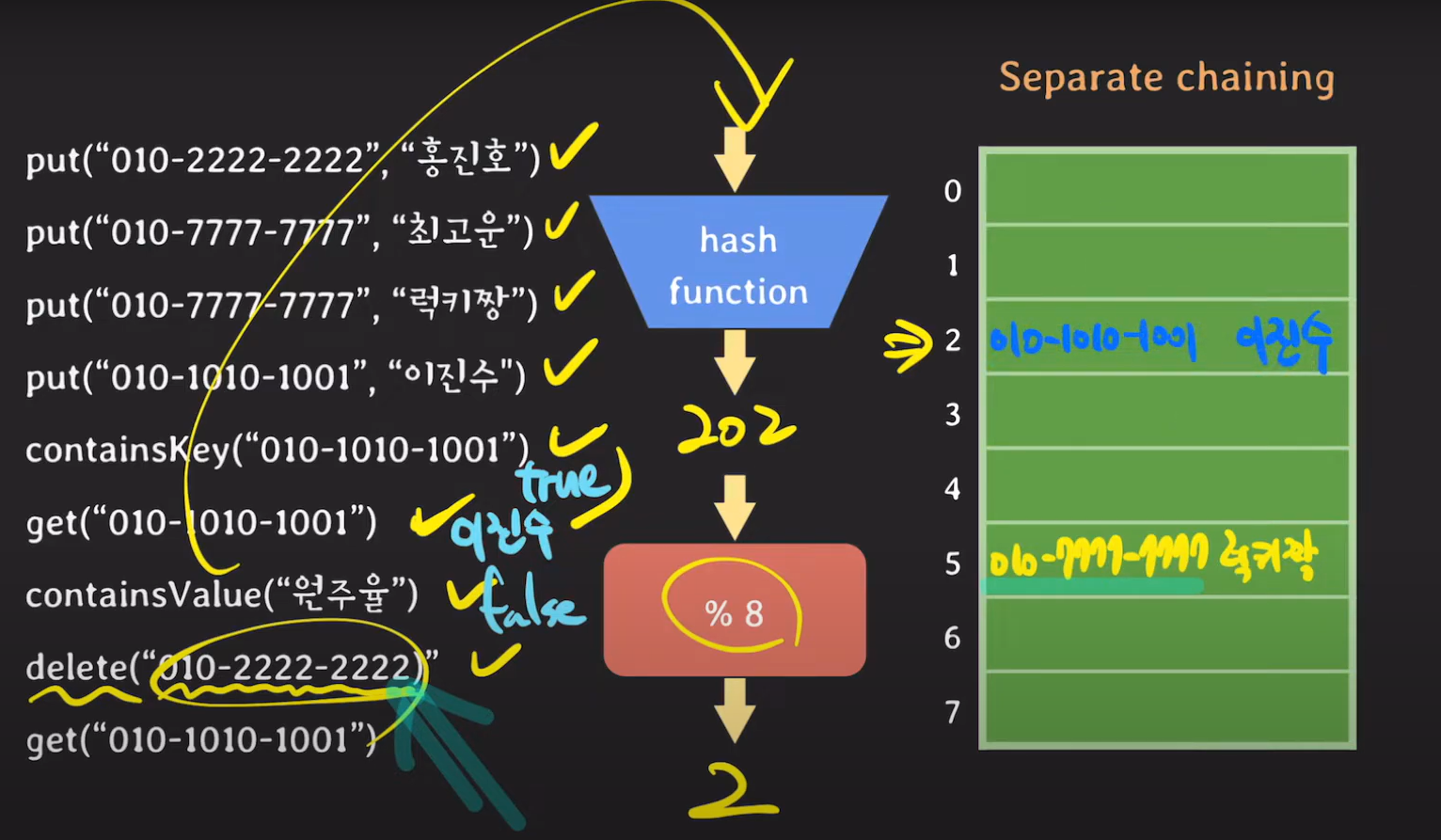
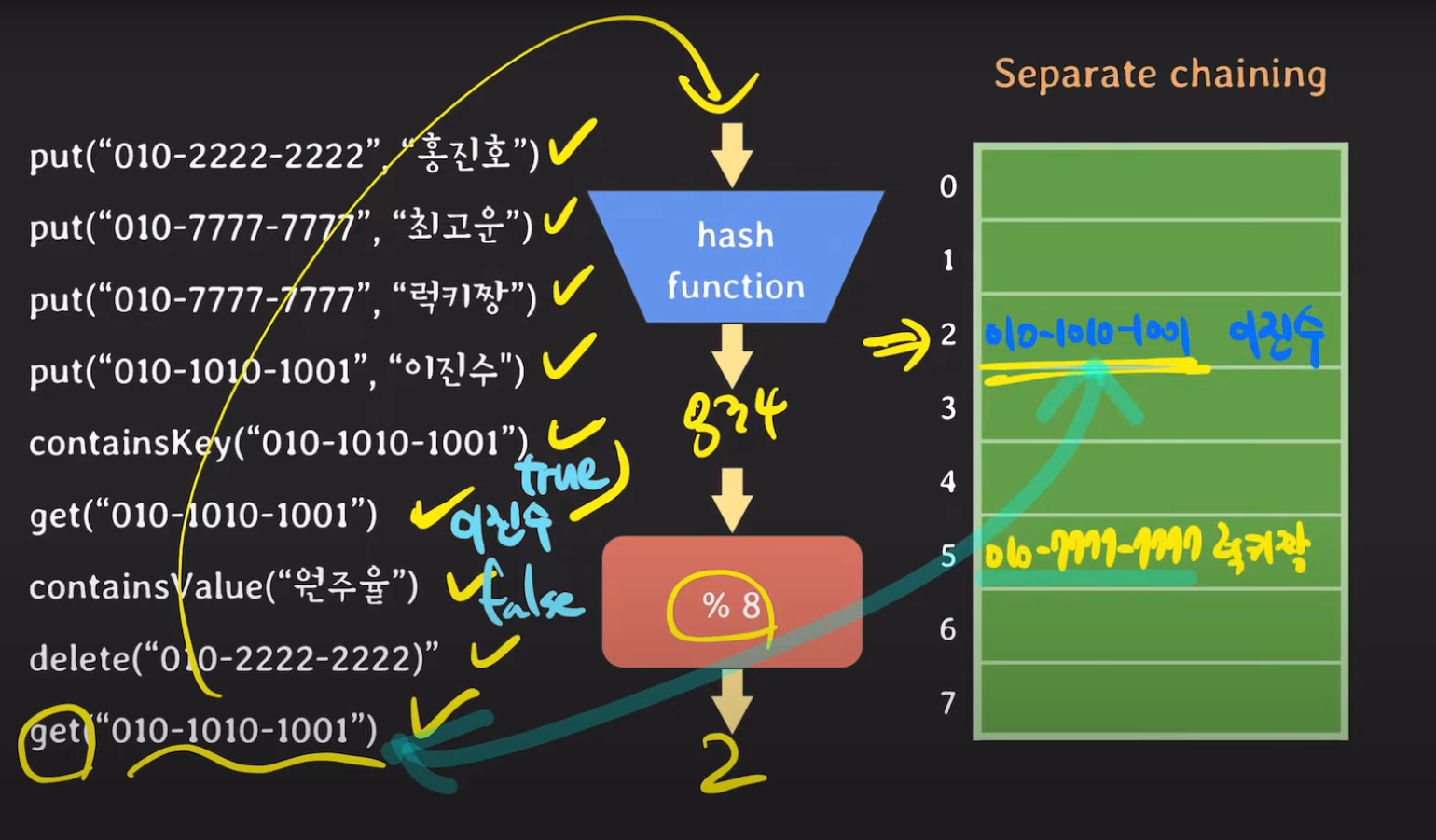
delete에 해당하는 키 값이 해시 테이블에 존재하기 때문에 해당 데이터를 삭제합니다. 이후에 chaning으로 존재하던 데이터가 해시 테이블에 저장됩니다.
Open addressing 방식은 Hash Collistion이 발생했을 때 Hash Table의 비어있는 공간을 활용합니다. 이때 linear probing의 경우 다음 칸에 데이터를 저장합니다.
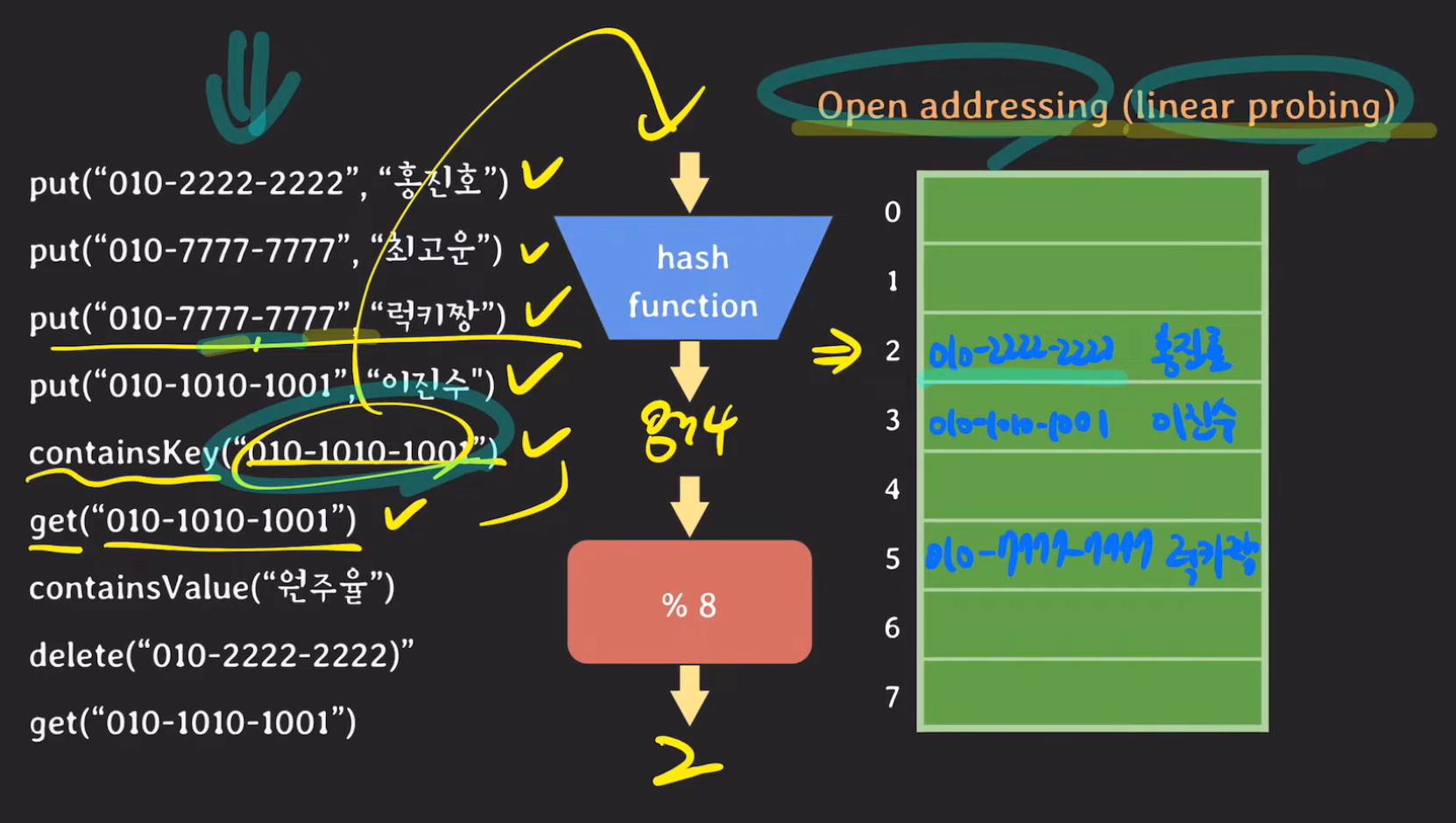
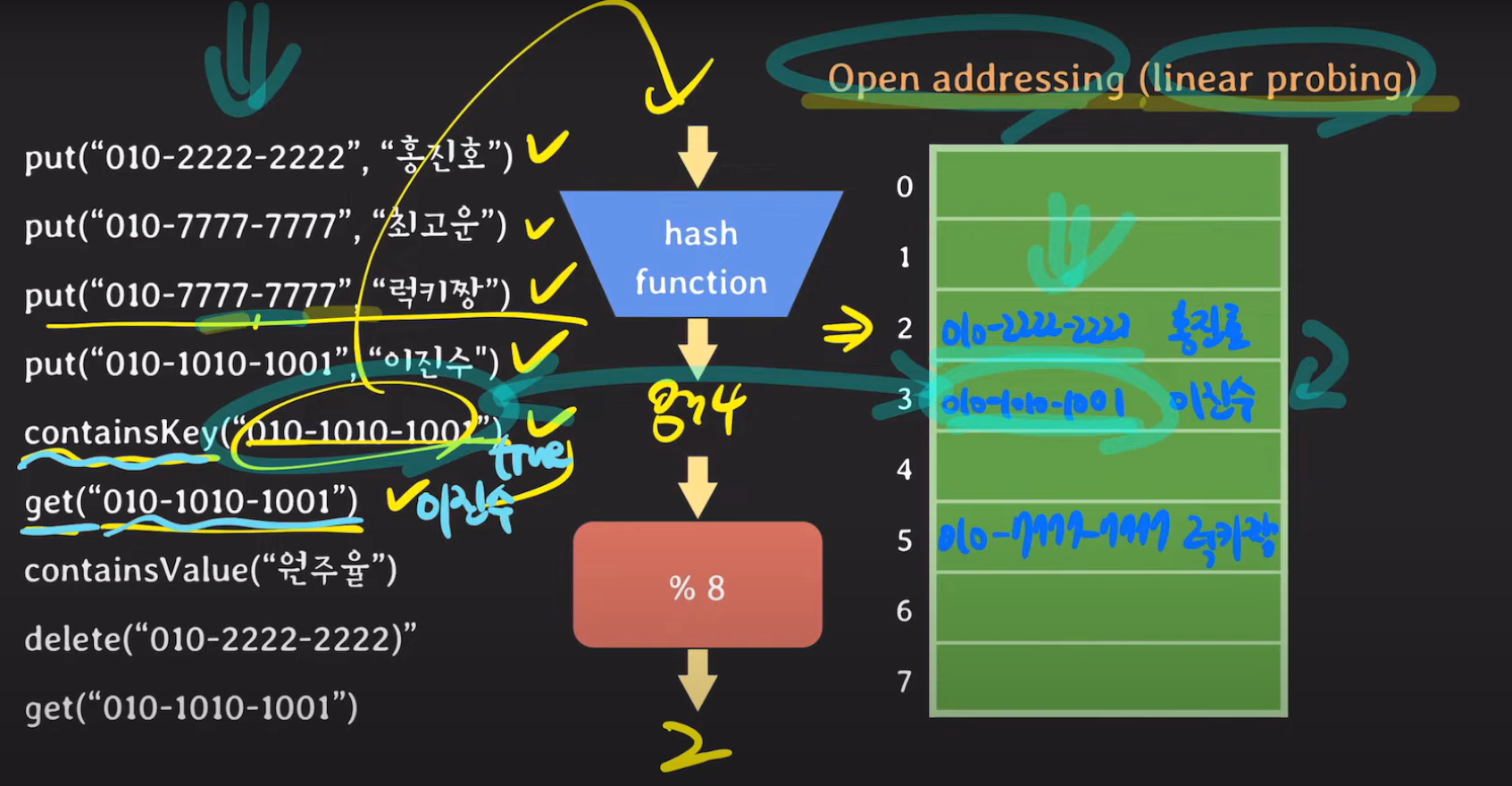
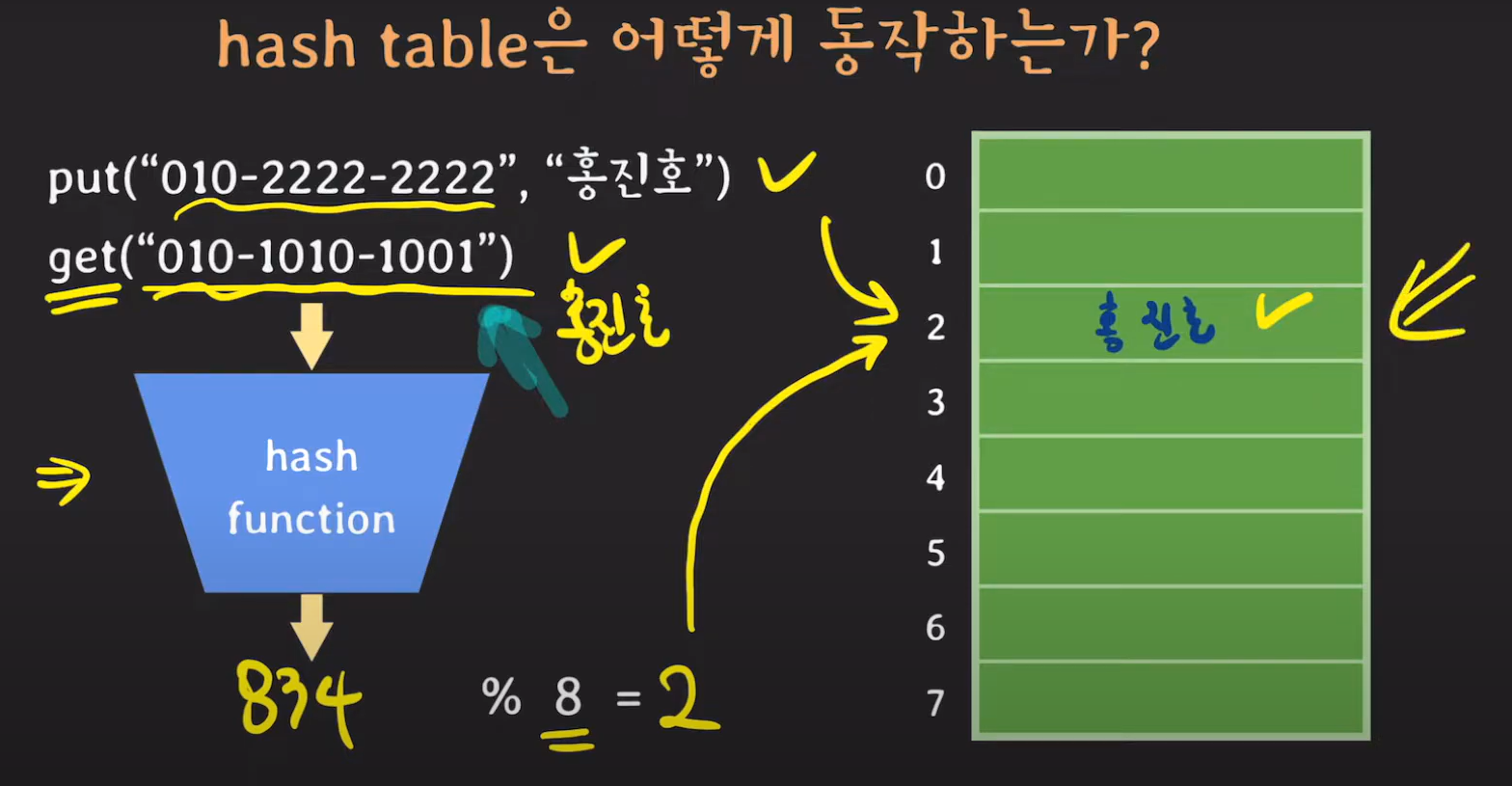
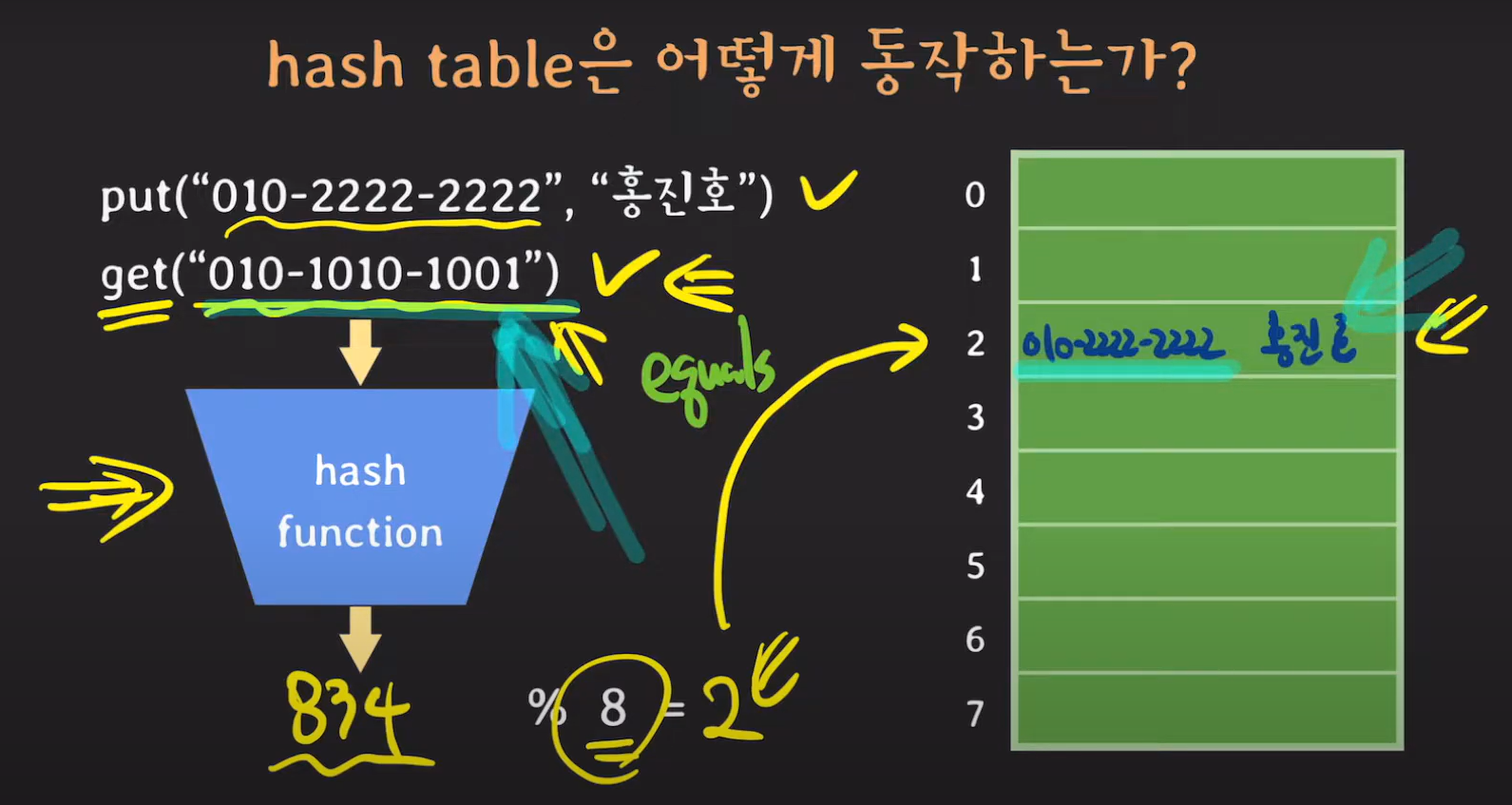
containsKey, get의 경우 모듈러 값에 있는 키와 파라미터로 들어온 키를 비교합니다. 이때 다른 값이라면 다른 버킷에 존재할 수 있기 때문에 다음 버킷을 확인합니다.
containsValue의 경우 Hash Table에 있는 모든 값을 확인합니다.
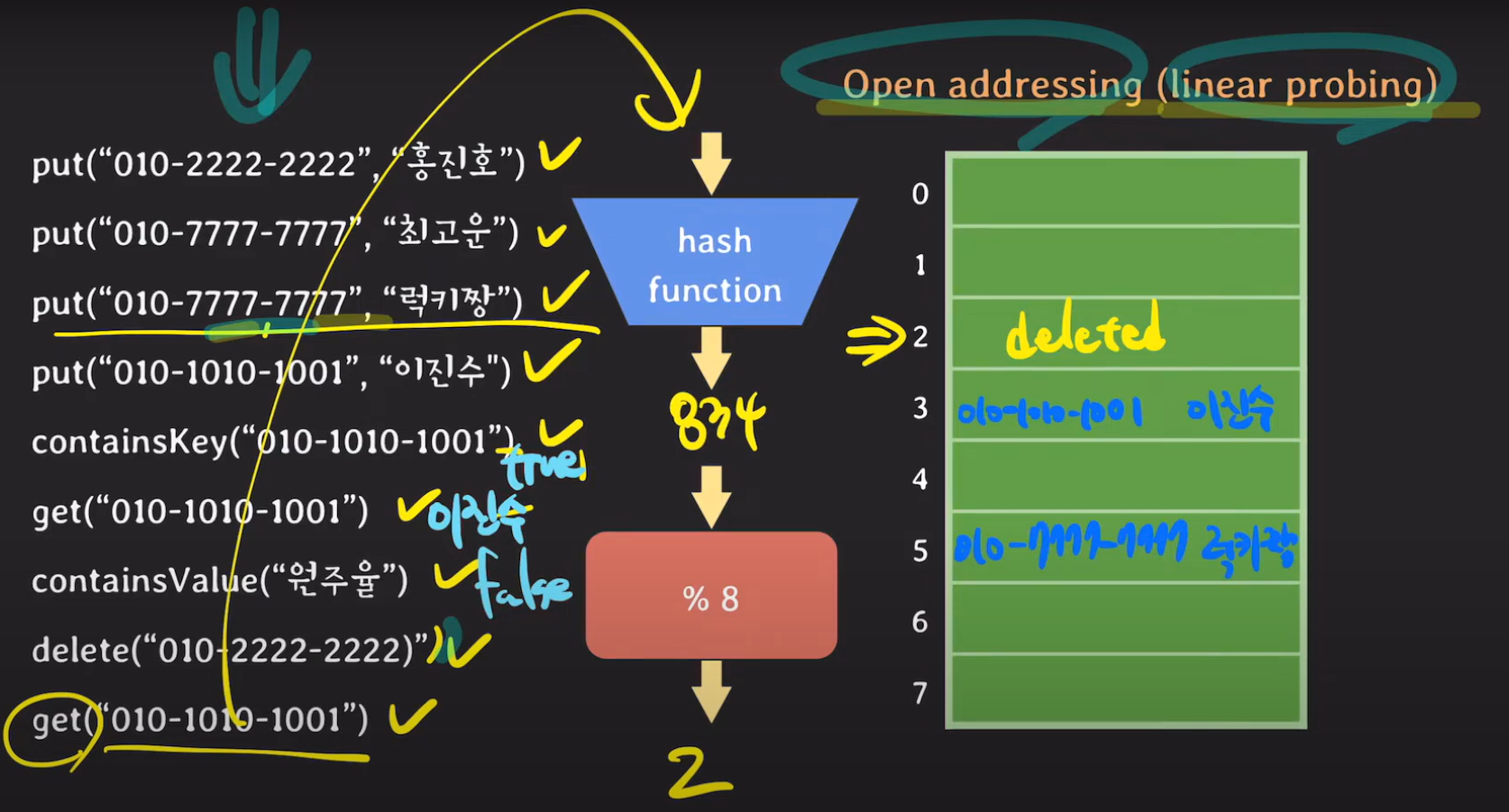
delete의 경우 Open addressing 방식에서 무작정 제거해서는 안됩니다. 이 경우 삭제되었다는 뜻의 더미 데이터를 넣어두던가 linear probing에 의해서 다음 인덱스로 넘어갔던 데이터를 복원시켜줘야 합니다.
그 이유는 다음 메서드인 get에서 설명하도록 하겠습니다.
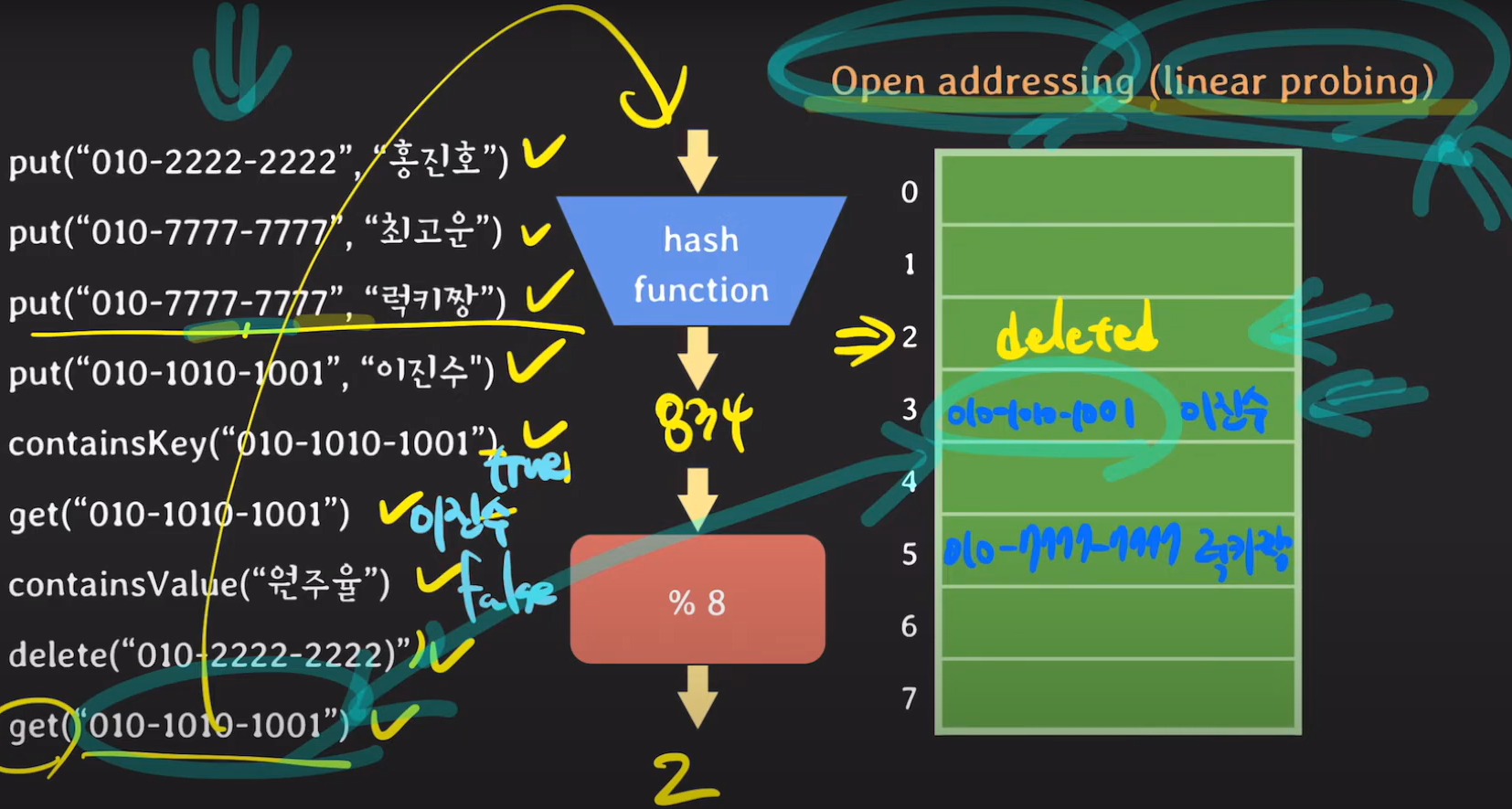
get을 호출했는데 더미 데이터로 채워지지 않았다면 데이터가 없다고 반환할 수 있습니다. 그러나 더미 데이터가 있다면 현재 우리가 Open addressing 방식 중 linear probing 방식을 사용하고 있으니 다음 버킷을 찾아보자고 생각할 수 있을 겁니다.

따라서 get파라미터로 받았던 키와 해쉬 테이블에 존재하는 키를 비교해서 이진수를 반환 할 수 있습니다.

자바의 경우 테이블의 75%가 채워지면 크기를 2배로 늘립니다. 이때 Hash 값을 같이 저장해놓고 있기 때문에 모듈러 연산(8 -> 16)을 빠르게 진행하여 데이터를 저장할 수 있습니다.


삽입 시 모든 데이터에 대해 Collision이 발생할 경우 O(n)이 될 수 있습니다.
자바에서 Separate chaining 방식에서 연결 리스트만 사용하는 것이 아니라 연결 리스트와 Red/Black Tree를 혼용해서 사용합니다.
정정 : "파이썬 3.2.x 까지는 dictionary의 유효한 데이터 수가 5만개 이상이면 유효 데이터 수의 두 배를, 그렇지 않다면 네 배를 새로운 capacity 크기로 결정하구요, 현재 파이썬 3.10.x 기준으로는 일반적으로 (dictionary의 유효 데이터 수 x 3)과 같거나 큰 수 중에서 가장 작은 2의 배수를 새로운 capacity 크기로 결정합니다"
hash table capacity가 항상 2의 제곱에 해당하는지 생각해보자.
HashTable 구현
#import 생략
class MyHashData:
def __init__(self, key, value):
self.key = key
self.value = value
class MyHashTable:
def __init__(self):
# 10개의 DoublyLinkedList 버킷 초기화
self.arr = [MyDoublyLinkedList() for _ in range(10)]
def hash_function(self, number):
# 간단한 해시 함수: key를 10으로 나눈 나머지
return number % 10
def set(self, key, value):
hash_index = self.hash_function(key)
bucket = self.arr[hash_index]
# 기존에 같은 키가 있다면 제거
current_node = bucket.head
while current_node:
if current_node.value.key == key:
bucket.remove_value(current_node.value)
break
current_node = current_node.next
# 새 데이터를 리스트에 추가
bucket.add_at_index(0, MyHashData(key, value))
def get(self, key):
hash_index = self.hash_function(key)
bucket = self.arr[hash_index]
# 해당 key를 가진 데이터 검색
current_node = bucket.head
while current_node:
if current_node.value.key == key:
return current_node.value.value
current_node = current_node.next
return None
def remove(self, key):
hash_index = self.hash_function(key)
bucket = self.arr[hash_index]
# 해당 key를 가진 데이터 제거
current_node = bucket.head
while current_node:
if current_node.value.key == key:
bucket.remove_value(current_node.value)
return current_node.value.value
current_node = current_node.next
return None
# 테스트 코드
if __name__ == "__main__":
hash_table = MyHashTable()
# 데이터 삽입
hash_table.set(1, "이운재")
hash_table.set(4, "최진철")
hash_table.set(20, "홍명보")
hash_table.set(6, "유상철")
hash_table.set(22, "송종국")
hash_table.set(21, "박지성")
hash_table.set(5, "김남일")
hash_table.set(10, "이영표")
hash_table.set(8, "최태욱")
hash_table.set(9, "설기현")
hash_table.set(14, "이천수")
# 데이터 가져오기
print(f"1: {hash_table.get(1)}") # 출력: "이운재"
print(f"21: {hash_table.get(21)}") # 출력: "박지성"
# 데이터 제거
hash_table.remove(1)
print(f"1: {hash_table.get(1)}") # 출력: None
결과
1: 이운재
21: 박지성
1: None✏️ Set

cf) 사실 ADT 관점에서 "데이터 조회(search)가 List 보다 빠름"이라는 설명은 옳지 않습니다. 왜냐하면, ADT는 구현은 다루지 않고 동작이나 특성만 다루는 개념인데, "데이터 조회가 Set이 더 빠르다"는 것은 구현을 해야만 알 수 있는 부분이라 앞 뒤가 맞지 않습니다.
그럼에도 이런 언급을 한 것은, 흐름 상 '서두에 같이 설명하는 것이 좋겠다' 싶어서 이 타이밍에 언급하게 됐습니다. 참고하시기 바랍니다.
언제 Set을 사용해야 할까?
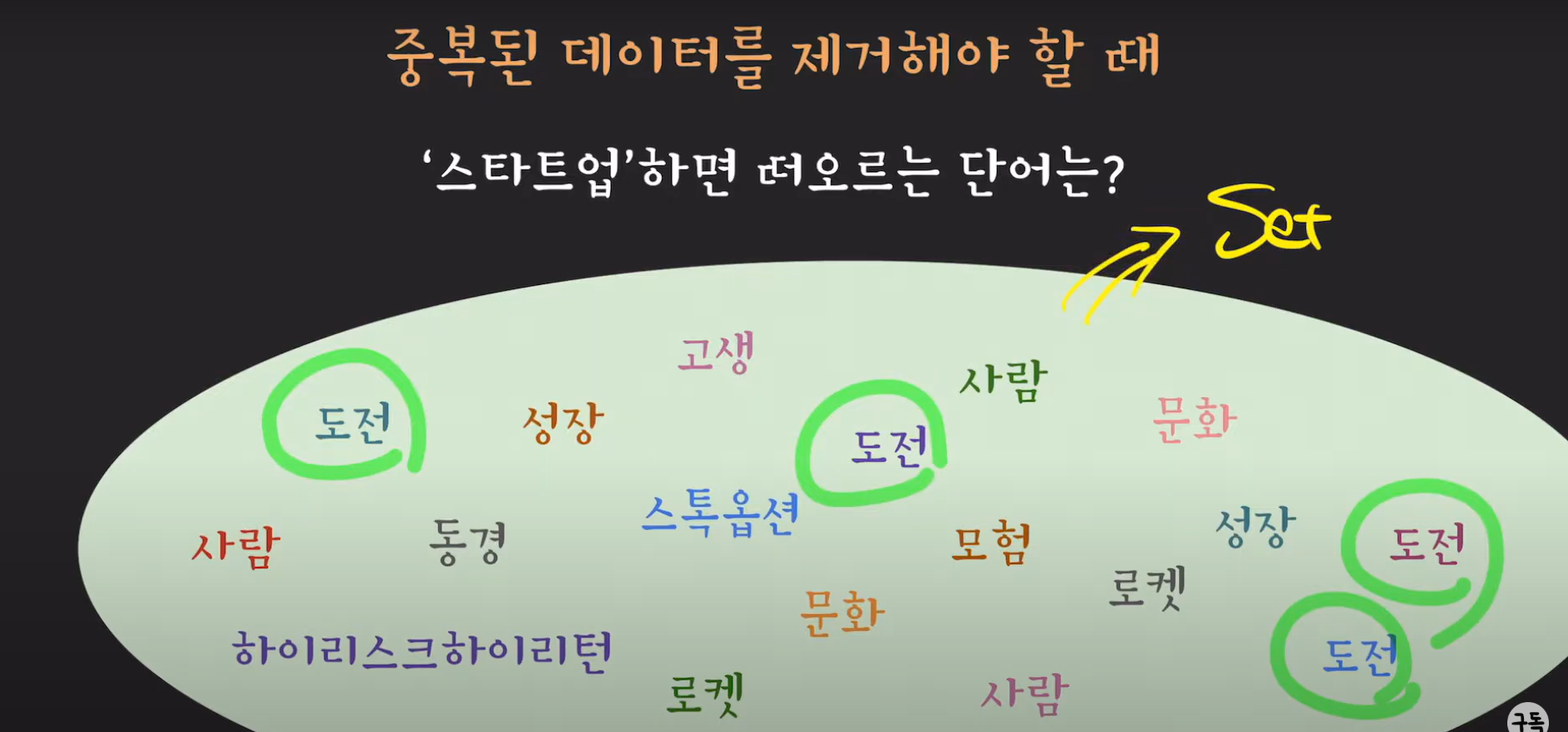

다음과 같은 상황에서 경기도 사업 지원 수혜자를 리스트로 처리할 경우 용인시 사업 지원자 하나당 경기도 사업 지원 수혜자 리스트의 원소를 모두 탐색해야 할 겁니다. 따라서 List 보다 더 빠른 Set을 사용하여 탐색하면 더 빠른 속도로 문제를 해결 할 수 있습니다.


이때 HashSet은 HashTable의 value값은 사용하지 않고 key만 사용합니다. key가 key임 동시에 data로 쓰이는 것입니다.
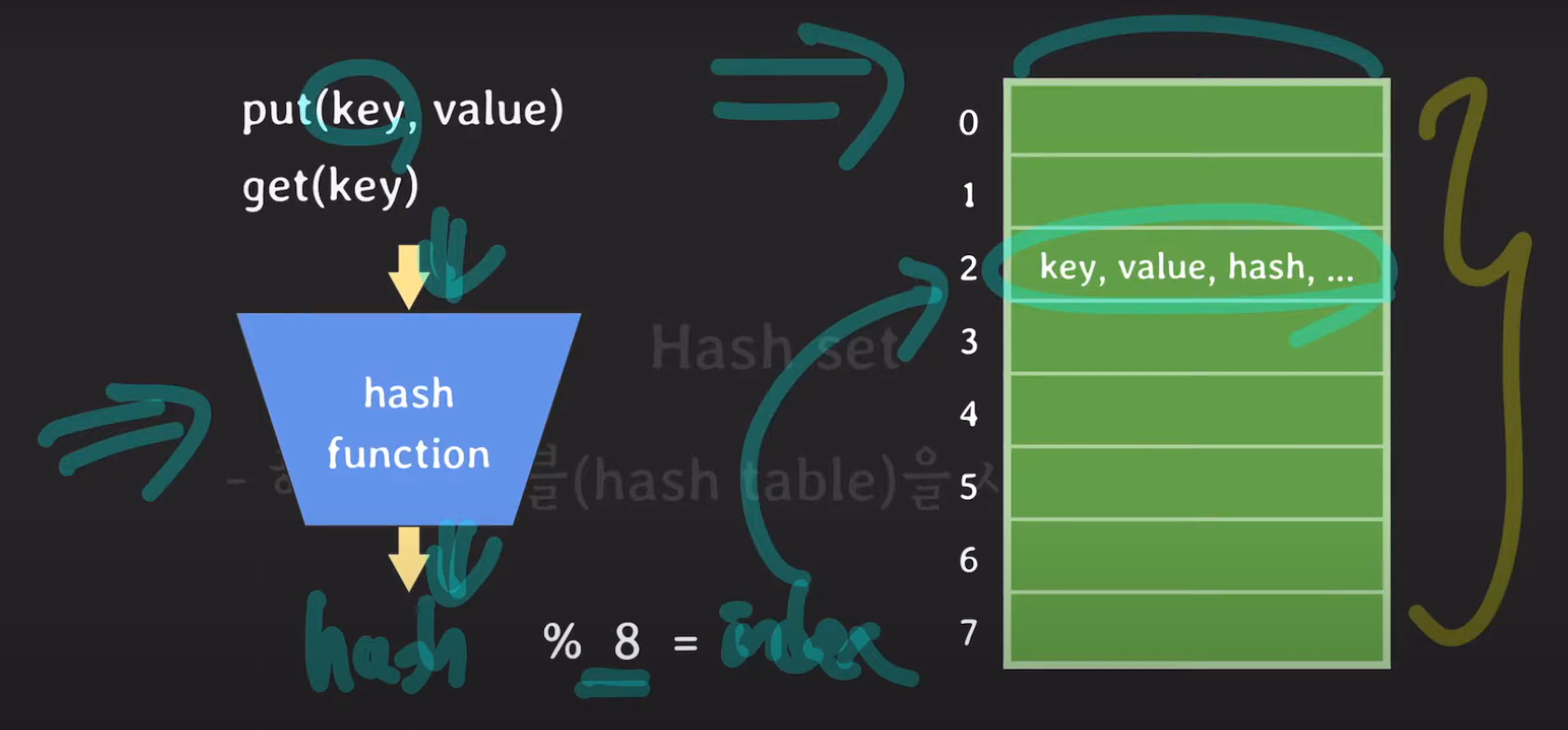
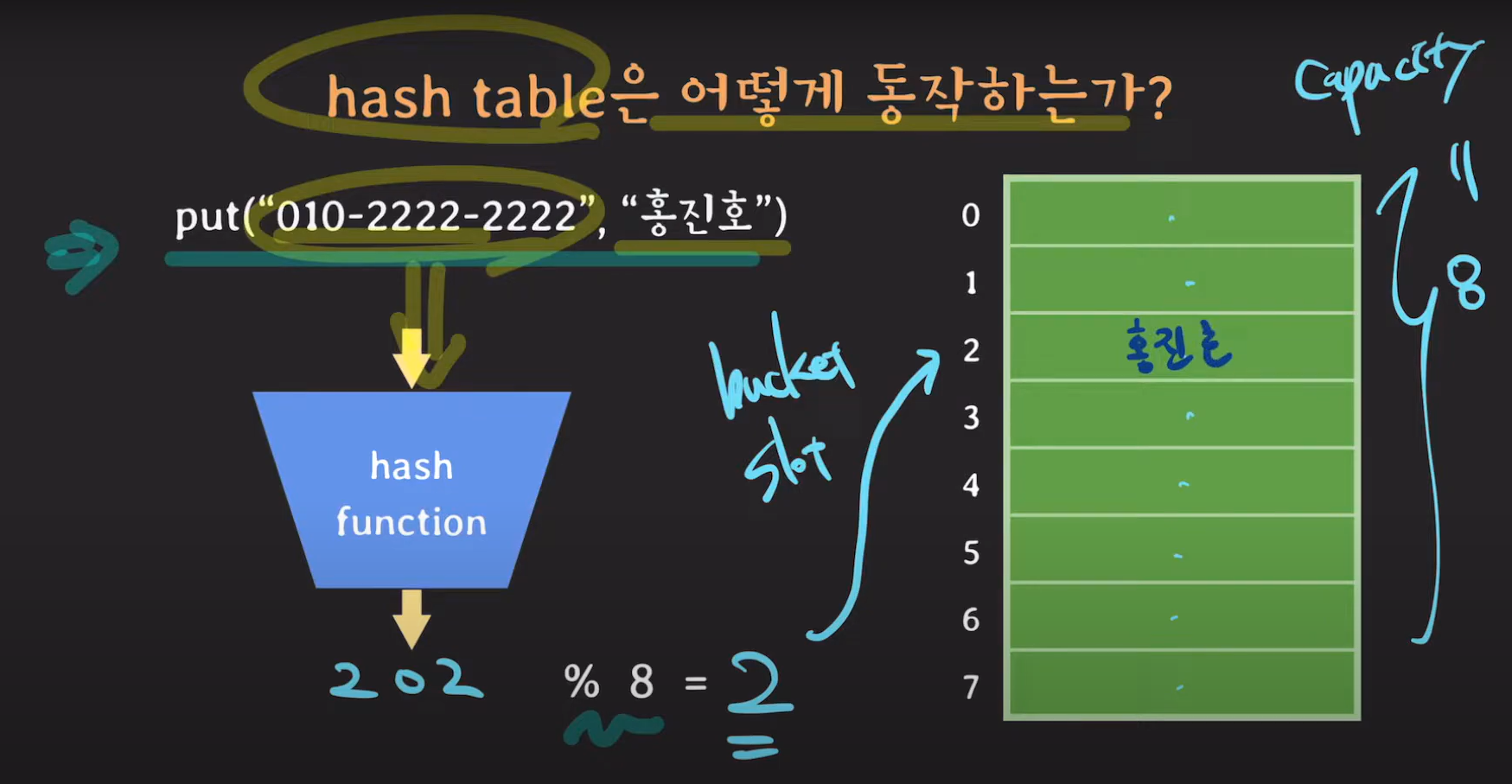
해시 테이블은 key를 hash Function에 넣고 나온 정수값을 배열의 크기로 모듈러 연산을 한 값을 index로 하여 배열에 저장하는 구조였습니다.

정리하면 해시 테이블은 다음과 같은 성질을 갖고 있습니다.


HashSet 생성자를 보면 내부적으로 HashMap을 사용하는 것을 확인 할 수 있습니다.
add의 경우도 map에 데이터를 넣는 구조이며 이때 value값은 빈 오브젝트 객체임을 확인할 수 있습니다.
조회를 할 때에는 map의 key가 있는지 확인하는 코드로 구성된다.



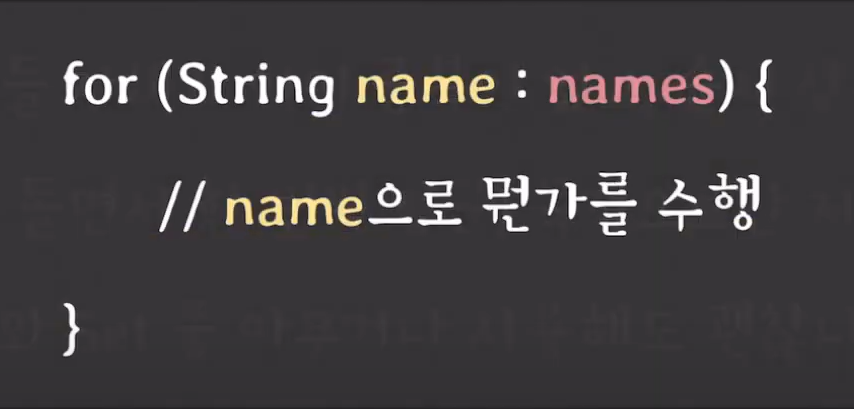
이를 코드적으로 생각해볼 때 여기에 names에는 중복과 순서가 상관없는 상황이라고 하면 Set과 List중 아무거나 사용해도 괜찮은가?에 대한 질문입니다.

ArrayList나 LinkedList는 hash를 저장하지 않기 때문에 Set에 비해 메모리를 적게 사용할 것입니다.
반면, HashSet의 경우 hash를 저장합니다. TreeSet의 경우 hash를 저장하진 않지만 자식 노드를 가리키기 위한 레퍼런스 변수를 저장해야 하기 때무에 더 많은 메모리를 사용하게 됩니다.
또한 리스트는 구조가 단순하기 때문에 하나씩 순회하면 되는데 HashSet의 경우 내부적으로 HashMap을 사용하기 때문에 배열의 일부분들이 비어있을 것이고 이 비어있는 값까지 모두 검사해야 하기 때문에 추가적인 오버헤드가 발생할 것입니다.
따라서 HashTable을 이용해 구현한 HashSet의 경우 iteration이 더 오래 걸린다.
이 문제를 해결하기 위해 자바에서는 LinkedHashSet이 존재합니다.
LinkedHashSet은 유효한 자료끼리 링크로 연결해주는 구현체입니다. 따라서 순회할 때 더 빠르게 순회 할 수 있도록 해주었습니다.
LinkedList를 추가적으로 구현하였기 때문에 HashSet보다 퍼포먼스적으로 약간 떨어지며 메모리 사용량이 증가한다는 단점이 있습니다.
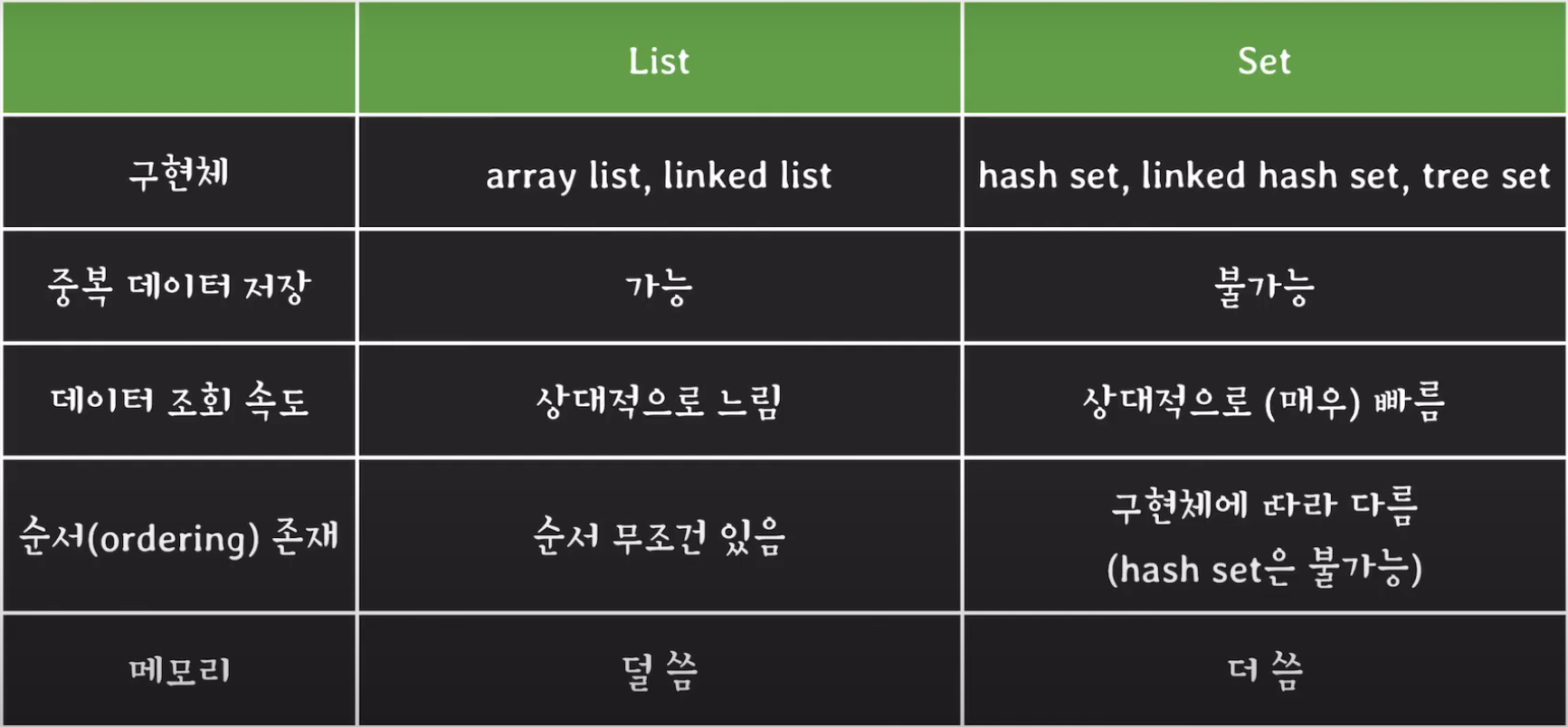
여기서의 조회 속도는 검색을 의미합니다.
cf) 인덱스 참조가 아닙니다.
TreeSet은 정렬 순서대로 저장되지만 HashSet보다 조회 속도가 느립니다.
HashSet 구현
#import 생략
class MyHashSet:
def __init__(self):
self.hash_table = MyHashTable()
def add(self, value):
if self.hash_table.get(value) is None:
self.hash_table.set(value, -1)
def is_contain(self, value):
return self.hash_table.get(value) is not None
def remove(self, value):
self.hash_table.remove(value)
def clear(self):
for i in range(len(self.hash_table.arr)):
self.hash_table.arr[i] = []
def is_empty(self):
for bucket in self.hash_table.arr:
if len(bucket) > 0:
return False
return True
def print_all(self):
for bucket in self.hash_table.arr:
for data in bucket:
print(data.key)
# 테스트 코드
if __name__ == "__main__":
hash_set = MyHashSet()
print("isEmpty:", hash_set.is_empty())
print("===== 데이터 삽입 =====")
hash_set.add(1)
hash_set.add(1)
hash_set.add(123)
hash_set.add(512)
hash_set.print_all()
print("isEmpty:", hash_set.is_empty())
print("===== 데이터 체크1 =====")
print("isContain:", hash_set.is_contain(1))
print("===== 데이터1 제거 =====")
hash_set.remove(1)
hash_set.print_all()
print("isEmpty:", hash_set.is_empty())
print("===== 데이터 체크2 =====")
print("isContain:", hash_set.is_contain(1))
print("===== clear =====")
hash_set.clear()
hash_set.print_all()
print("isEmpty:", hash_set.is_empty())