- 이해를 위한 배경 지식
(1) 인덱스를 직접 마주한 적이 있다고?
어렸을 때, 국어사전을 봤던 적을 꽤 자주 보곤 했습니다. 현재는 디지털화가 되어서 찾기가 편해졌지만, 그 당시에 단어를 찾을 때 의존할거는 첫째 글자 자음 글자, 모음 글자, 받침 글자 순으로 비교해가면서 찾았던 기억이 있습니다. 예를 들어,'산'을 찾으려고 하면, 첫소리 ㅅ을 찾은 뒤에 가운데 소리(모음) ㅏ를 찾고 끝소리(받침) ㄴ을 찾곤 했습니다. 저는 이 경험을 바탕으로 인덱스의 개념을 이해해보려고 했습니다. 밑에서도 이 경험을 빗대어 설명할 수 있다면 활용하고자 합니다.
(2) 데이터베이스의 성능을 결정하는 요소
데이터베이스의 성능은 디스크 I/O를 최적화시키는 것에서 시작합니다. 디스크 I/O는 디스크 원판을 돌려 데이터가 저장된 위치로 디스크 헤더를 이동시켜서 데이터를 읽는 일련의 과정을 말하는데요. 원판을 돌리는데 걸리는 시간을 탐색 시간이라고 하는데, 전송시간과 회전 지연시간을 합쳐도 이 탐색시간에 못미친다고 합니다. 그만큼 탐색시간을 짧게 가져가면 성능이 높아진다고 합니다.
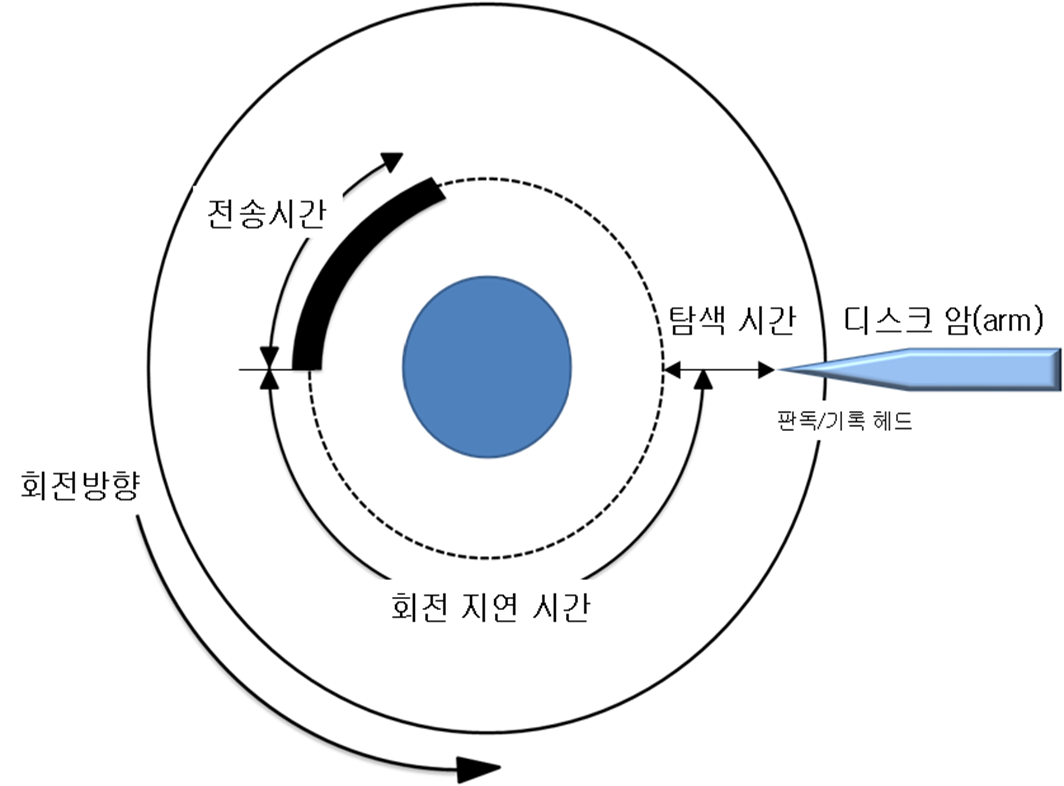
[1] 그래서 인덱스가 뭐라고?
사전적인 의미로 먼저 알아보겠습니다. 인덱스를 번역하면 색인입니다. 그러면 색인이 뭔가요?
(1) 어떤 것을 뒤져서 찾아내거나 필요한 정보를 밝힘.
(2) 책 속의 내용 중에서 중요한 단어나 항목을 쉽게 찾아볼 수 있도록 일정한 순서에 따라 배열한 목록
-> 특정 데이터를 찾을 때 보다 쉽고 빠르게 찾을 수 있도록 도움을 주는 요소 라고 느껴집니다.

책 단어를 편하게 찾기 위한 색인
그러면 데이터베이스에서의 인덱스는 뭔지 풀어보겠습니다.
특정 레코드를 빠르고 쉽게 찾기 위한 레코드의 주소가 책에서의 페이지라고 생각하면 되겠습니다.
위 사진을 보면 알파벳 순서로 찾을 수 있게 표시가 되어 있듯이, 데이터베이스에서의 인덱스 또한 항상 정렬된 상태로 유지됩니다.
규모가 큰 서비스들은 셀수없이 많은 레코드들이 데이터베이스에 쌓여있을거고, 그 중에서 찾고자 하는 정보를 어떻게 빨리 찾느냐가
개발자들의 관심사중 하나라고 생각합니다. 그 방법 중 하나가 인덱스입니다.
-> Q: 와 그러면 모든 필드(속성)을 인덱스로 설정해두면 좋겠네요?
A: 그렇지 않습니다.
데이터베이스에서 DML(Data Manipulation Language)에는 Select, Update, Delete, Insert 네 가지 주요 조작어가 있습니다. 많은 개발자들이 Select 문을 자주 사용하기 때문에, 인덱스를 통해 Select 문 성능을 개선하려고 합니다. 하지만 인덱스를 추가하면 Update, Delete, Insert 문 성능에 부정적인 영향을 미칠 수 있습니다.
인덱스를 유지하려면 새로운 데이터가 들어오거나, 삭제되거나, 인덱스가 걸린 필드가 업데이트될 때마다 인덱스를 정렬된 상태로 유지해야 합니다. 이는 레코드를 추가하는 작업 외에도 인덱스 데이터를 생성해야 하기 때문입니다.
이를 책으로 비유해보겠습니다. 초판 책에서 307페이지에 "solution"이라는 단어가 새로 들어갔다고 가정해봅시다. 그러면 s로 시작하는 부분에 해당 단어를 추가하여 순서가 깨지지 않도록 해야 합니다. 만약 2판에서 단어별 글자 수에도 인덱스를 걸어두었다고 가정하면, 새로운 단어가 생길 때마다 단어별 글자 수 정렬 순서에 맞게 표기해줘야 합니다. 이로 인해 책이 더 두꺼워질 것입니다.
즉, 잘 사용되지 않는 필드에까지 인덱스를 걸면 오히려 성능 저하를 초래할 수 있습니다. 따라서 필요한 필드에만 인덱스를 설정하는 것이 좋습니다.
-> 조회의 성능과 다른 쿼리의 성능간의 적절한 Trade Off가 필요하다.
[2] 인덱스의 자료구조
(1) 일반적으로 많이 쓰이는 B-Tree 인덱스 알고리즘
B-Tree 알고리즘은 아래 사진과 같이 되어있습니다. 예를 들어, 점수 필드를 이용하여 학생을 찾는 경우가 많다고 가정보겠습니다. 만약 37점을 맞은 학생을 찾고자 하면, Root에서 왼쪽을 타고 이동하고 11과 40 사이에 있으므로 가운데 블록으로 이동합니다. 리프 블록에서 37에 해당하는 레코드를 찾을 수 있습니다. 여기서 리프블록의 특징은 양방향링크로 연결되어 있다는 것입니다. 만약 37보다크고 50보다 작은 레코드는 37부터 50까지 양방향 링크를 이용하여 데이터를 읽습니다.
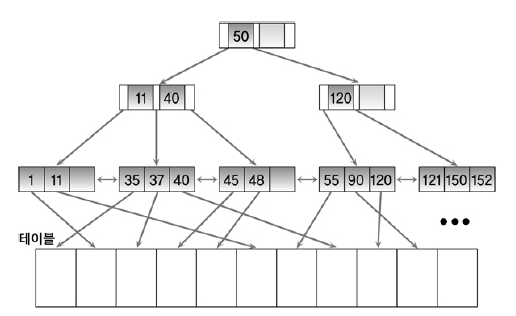
(2) Hash 인덱스 알고리즘
컬럼의 값으로 해시 값을 계산해서(37 -> AXKALSELK라는 특정 해시함수를 이용하여 해시문자열로 바꿔서 인덱스 값으로 저장) 매우 빠른 검색을 지원하지만, 해시된 문자열로는 특정 범위내에 있는 레코드를 읽는데에는 최적화되어 있지 않습니다. 한마디로 SELECT 쿼리문제에서 부등호 연산에 최적화되어 있는 알고리즘이 아닙니다.
[3] 주요 내용 정리 및 알아두면 좋을 내용
- 인덱스는 읽을 때 SELECT 쿼리의 빈도가 많고, 많이 활용되는 필드에 거는 것이 좋다. -> PK과 UNIQUE 필드에는 자동으로 걸린다. (고유한 값으로 특정 로우를 조회하는데에 많이 활용되기 때문이다.)
[4] 추가적으로 깨달았던 내용
- 필드의 도메인에 따라 인덱스 걸지 말지를 고려해야한다. 개발자로 근무할 당시에, 조회시에 자주 사용하는 필드에 인덱싱을 걸었을 때 좋은 성능을 발휘할 것이라고 기대하였는데 그 필드는 boolean으로 값의 범위가 true 혹은 false이므로 인덱싱을 거는 것이 의미가 있지 않았다!



유익한 정보를 예시로 쉽게 풀어서 설명해줘서 잘 이해되는 것 같아요!!
꾸준한 업로드 기대하겠습니다 :)