
왜 우리는 HashSet을 사용할까?
중복을 제거할 수 있기 때문이다.
1.HashSet이란?
1-1. HashSet
중복되지 않는 데이터를 순서에 상관없이 저장하는 컬렉션이다.
1-2. Hash연산
Hash 연산은 데이터를 고정된 크기의 값으로 변환하는 과정으로, 해시 함수(Hash Function)를 사용해 이뤄진다.
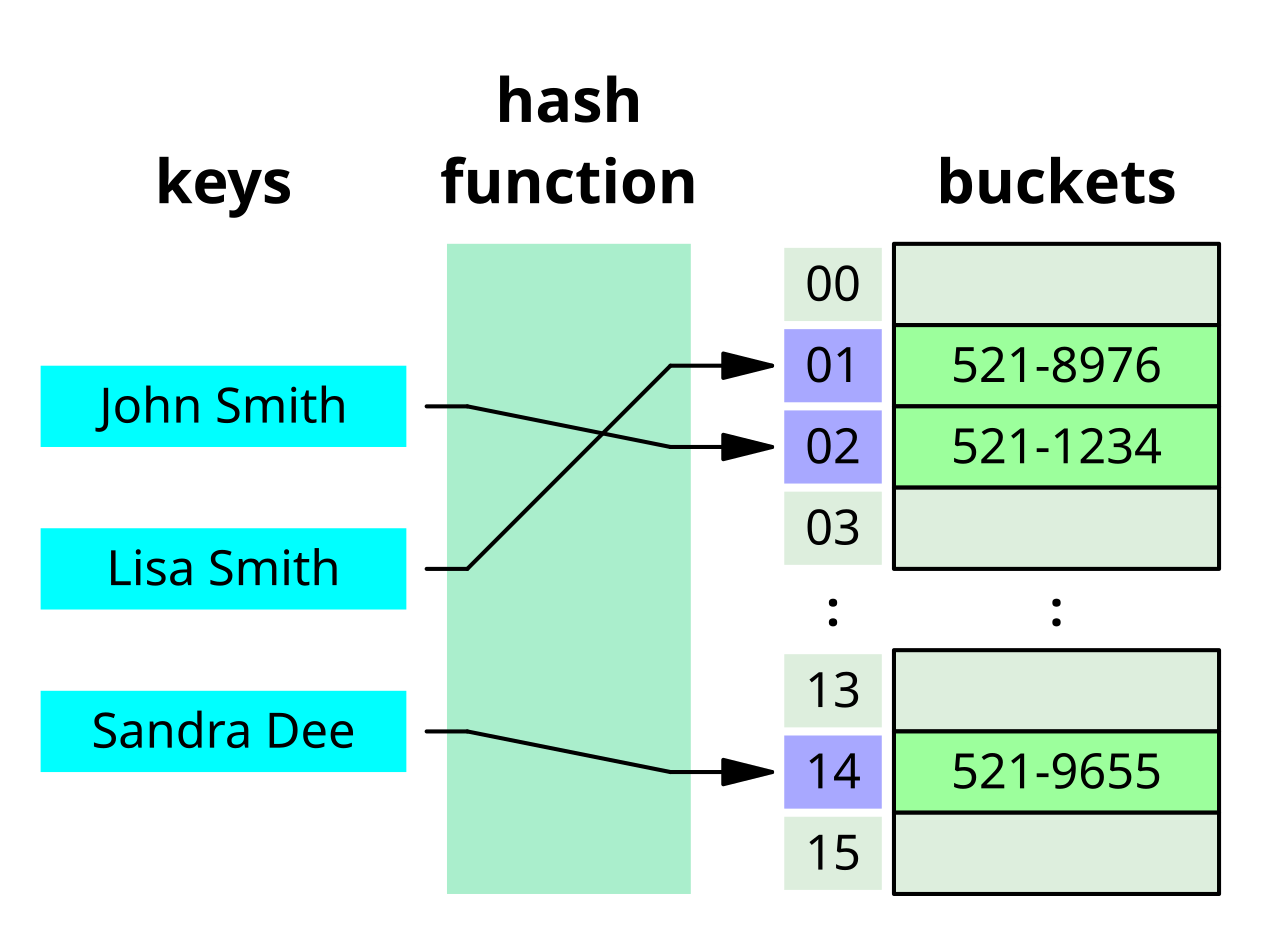
- 해시 함수 : 임의의 길이를 가진 데이터 -> 고정된 길이의 값
- 해시 함수를 사용하면 입력값에 대해 항상 동일한 규칙에 따라 고정된 길이의 해시값을 생성한다.
- 해시 함수의 설계는 충돌을 최소화하고, 빠르게 계산되도록 하는 게 중요하다.
1-3. HashSet의 특징
중복된 요소를 허용하지 않는다.이 때, 동일 객체 뿐만 아니라 동등 객체도 저장되지 않는다.- hash 연산을 통해 저장,관리 되고 있다.
- 데이터 저장 순서가 유지되지 않는다.
- 기본 연산인 add, remove, contains, size의 성능은 평균적으로
O(1)이다.
2. HashSet 사용법
2-1. HashSet 선언
// 기본 생성자
HashSet<String> hs = new HashSet<>();
// 초기 용량을 지정할 수 있는 생성자
HashSet<String> hs = new HashSet<>(int initialCapacity);
HashSet<String> hs = new HashSet<>(32);
// 초기 용량 + 로드 팩터(해시 테이블이 얼마나 차면 크기를 증가시킬지 결정) 지정
HashSet<String> hs = HashSet<>(int initialCapacity, float loadFactor)
HashSet<String> hs = new HashSet<>(32, 0.5f);
// 다른 컬렉션을 이용한 초기화
HashSet<String> hs = new HashSet<>(Collection<? extends E> c);
2-2. HashSet의 주요 메서드
| 주요 메서드 | 리턴 타입 | 설명 |
|---|---|---|
| add(E e) | boolean | 요소를 추가 (중복된 값은 추가되지 않음) |
| clear() | void | 모든 요소 삭제 |
| contains(Object o) | boolean | 특정 요소가 존재하는지 확인 |
| isEmpty() | boolean | 비어있는지 확인 |
| remove(Object o) | boolean | 특정 요소 제거 |
| size() | int | 현재 존재하는 요소의 개수를 반환 |
2-3. 주요 메서드 사용해보기
import java.util.HashSet;
public class Main {
public static void main(String[] args) {
// 1. HashSet 생성
HashSet<String> fruit= new HashSet<>();
// 2. add() : 요소 추가
fruit.add("Apple");
fruit.add("Cherry");
fruit.add("Banana");
fruit.add("Apple"); // 중복된 값 추가 (무시됨)
// 3. contains() : 요소 포함 여부 확인
// 바나나가 포함되었는지 확인
// true or false
System.out.println(fruit.contains("Banana"));
// 4. remove() : 요소 제거
fruit.remove("Cherry");
// 5. size() : HashSet의 크기 확인
System.out.println("Set 크기: " + fruit.size());
// 6. clear() : HashSet에 있는 요소 전체 삭제
fruit.clear();
// 7. isEmpty() : HashSet이 비어있는지 확인
// true or false 출력
System.out.println("Set이 비어있는가? " + fruit.isEmpty());
// 8. 반복문을 사용해 각 요소들을 출력
for (String item : fruit) {
System.out.println(item);
}
}
}
