1. 프로젝트 개요
1-1. NBTI 프로젝트란?
NBTI는 현대인의 인지 역량을 쉽고 정확하게 측정하고,
개인화된 루틴 트레이닝을 통해 생각의 힘을 키워가는 데이터 기반 두뇌 성장 플랫폼
🧐 프로젝트 배경
최근 한국인들의 사고능력이 떨어지고 있다. 정보 찾기는 쉬워졌지만, 스스로 생각하는 힘은 서서히 사라지고 있다. 이런 상황을 보며 생각하는 힘을 기를 수 있는 사이트를 만들면 어떨까 생각하게 됐다.
1-2. 프로젝트 주요 기능
프로젝트 주요 기능은 크게 사용자 중심의 기능과 관리자 기능 2가지로 분류되어 있고, 각각 간단하게 어떤 기능이 있었는지 살펴보면 다음과 같다.
(1) 사용자 기능
: 정식 검사 / 맛보기 검사, AI 분석 리포트, 학습 기능, 이의 제기 기능, 마이페이지 기록 관리
(2) 관리자 기능
: 문제 관리 페이지, 검사 이력 관리, 학습 내역 관리, 검색 및 정렬 고도화, 분야/유형 관리 페이지
1-3. 프로젝트 아키텍처
우리의 시스템 아키텍처는 다음과 같다. 자, 이제 지금부터 아키텍처의 흐름에 대한 설명과 각각의 과정에서 사용된 기술 스택을 이야기 하려고 한다.
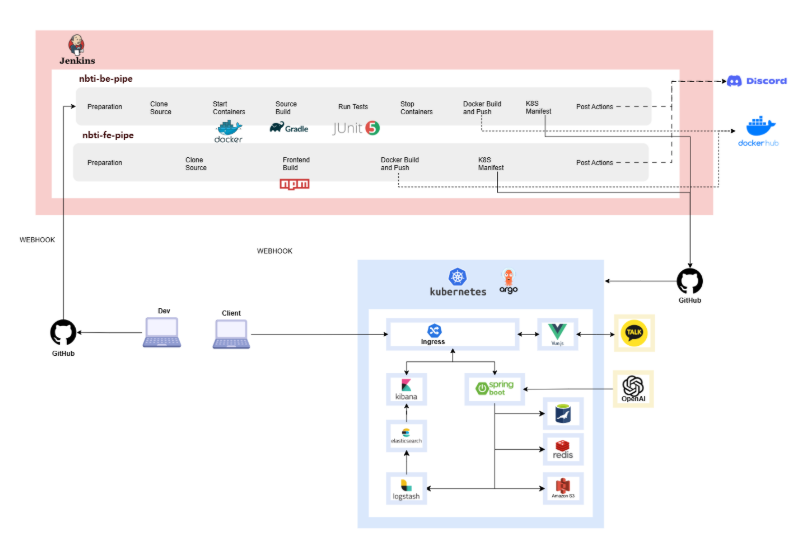
(1) 데이터베이스 & 캐시
- MariaDB : 메인 데이터베이스로 회원, 문제 등의 데이터를 저장
- Redis : 인증 캐시 서버로 활용하여 회원가입/로그인 속도 향상 및 세션 관리 최적화
(2) 백엔드
- Spring Boot 3.4 : 핵심 비즈니스 로직 및 API 서버 개발
- Swagger : API 자동 문서화
- OpenAI API : AI 기반 데이터 분석 기능 구현
- AWS S3 : 이미지 업로드 및 저장소로 활용
(3) 프론트엔드
- Vue.js : 사용자 UI 개발
- 카카오톡 API 연동 : 결과 이미지 공유를 위해 활용
(4) 컨테이너 & 배포
- Docker : 백엔드·프론트엔드 컨테이너 환경 구축
- Kubernetes(k8s) : 자동 스케일링·서비스 관리
- ArgoCD: Kubernetes 환경에서 CI/CD 배포 자동화
(5) CI/CD 파이프라인
- Jenkins
- 백엔드 파이프라인 : Docker 빌드 → 테스트(JUnit5) → K8s 배포
- 프론트엔드 파이프라인 : NPM 빌드 → Docker 빌드 → K8s 배포
- Discord 연동 : Jenkins 빌드/배포 결과를 Discord로 실시간 알림
(6) 모니터링 & 로깅
Kibana + Elasticsearch + Logstash : 로그 수집 용도로 활용
2. 프로젝트 진행 과정
2-1. 진행 과정
프로젝트는 다음과 같은 순서로 진행됐다.
기획 → DDD → 요구사항 명세서 작성 → 설계 (ERD, DB, UI) → 백엔드 개발 → 프론트엔드 개발 → 데브옵스 설정 → 프로젝트 시연
2-2. 여러 고민
프로젝트를 진행할 때마다 다양한 고민을 하게 된다. 이 프로젝트에서는 다음과 같은 부분을 팀원들과 논의했다.
(1) 팀 컨벤션 정의
- Git & GitHub 컨벤션: 브랜치 전략, 커밋 메시지 규칙, PR 템플릿 설정
- Java 코딩 컨벤션: 클래스·메서드 네이밍 통일
- 그라운드 룰: 회의 시간, 코드 리뷰 방식, 작업 시간대 공유 등 협업 기본 규칙 수립
(2) 아키텍처 및 패턴 선정
- 이전 프로젝트에서 CQRS 패턴을 적용해본 경험이 있었으나, 이번 프로젝트에서는 적용하지 않기로 결정
- 프로젝트 기간이 짧고 구현 기능이 많지 않아 Command와 Query를 굳이 분리할 필요 없음
- JPA를 사용하기로 이미 결정했기 때문에 CQRS로 나누는 것보다 단일 구조로 개발하는 것이 효율적이라고 판단
2-3. 나의 역할
(1) NBTI 정식 검사 및 맛보기 검사 기능 구현
- 회원/비회원 검사 구분
- 회원: 18문항(6카테고리 × 3문제), 포인트 차감 방식
- 비회원: 맛보기 검사 6문항(2점짜리 문제만 제공)
- 정확성 차등화
- 회원은 정식 검사 결과, 비회원은 단순 체험용 결과 제공
- 검사 기능 제한 해결
- 검사 문항 수가 적어 무제한 제공이 어려운 문제를 포인트 제도로 해결
- 결과 분석 고도화
- ChatGPT API를 활용하여 검사 결과 분석
- AI 기반 분석을 통해 신뢰성 확보 및 맞춤형 결과 제공
(2) Docker Compose 작성 및 도커 환경 구축
- 통합 로그 관리를 위해 ELK Stack(Elasticsearch, Logstash, Kibana) 도입
- 로컬 및 배포 환경에서 컨테이너 기반 서비스 실행 가능하도록 Docker Compose 작성
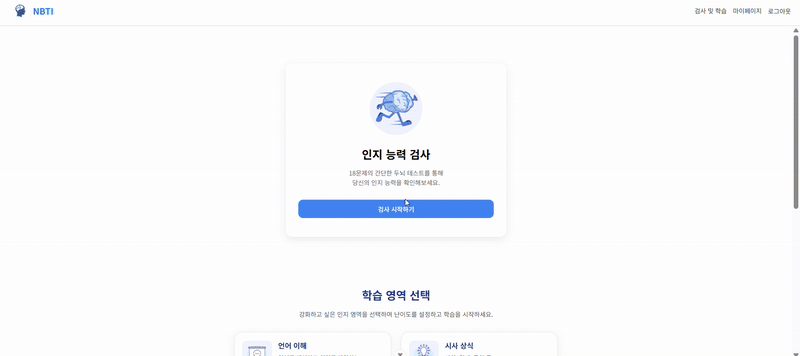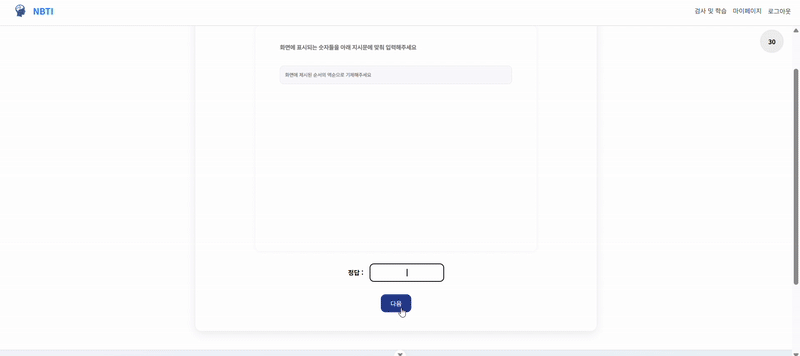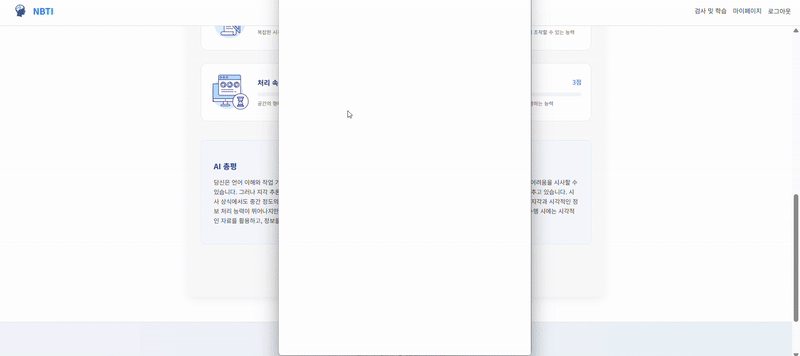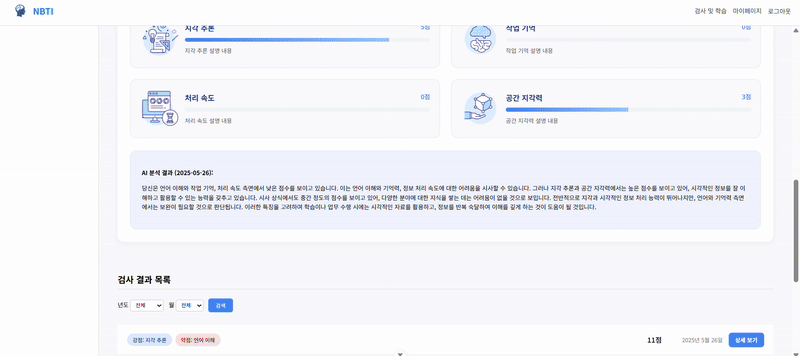
(3) 시연 준비 및 진행
해당 부분은 내가 개발한 부분이다. 문제를 풀로 그 결과까지 도출되는 모습을 보여주는 화면이다. 마지막에 나오는 AI 총평 부분이 Open AI에서 분석해준 결과이다.
3. 프로젝트 회고
3-1. 나의 트러블 슈팅
(1) 기능과 관련된 고민
이 부분은 트러블 슈팅이라기 보단, 개발을 진행하면서 좀 더 좋은 방향으로 가기 위해 고민한 것들을 이야기 할 것이다.
‼️회원/비회원 차등 기능 제공 과정에서 문항 부족 문제를 발견
이번 프로젝트에서 우리 팀이 직접 문제를 제작하거나 가져오면서 문제를 선정했다. 그렇기 때문에 문제를 무제한으로 제공할 수 없었다. 그래서 어떻게 해야 문제를 적게 제공할 수 있을지에 대한 고민을 했다. 그 결과 다음과 같이 프로젝트에 적용했다.
- 회원은
18문항의 정식 검사, 비회원은6문항맛보기 검사 포인트 시스템을 도입해 회원만 정식 검사를 이용할 수 있도록 변경- 비회원은 6문항 맛보기 검사로 전환해 회원 가입 유도
이외에도 "문항은 몇 개가 적절한지?", "비회원에게 몇 점짜리 문항을 제공하는 게 적절한지?" 등 여러 가지를 고민했다.
(2) @RequiredArgsConstructor 문제
❌ 문제 상황
코드를 밑에 처럼 작성했는데, 계속 에러가 발생
@Service
@RequiredArgsConstructor
public class TestAiAnswerServiceImpl implements TestAiAnswerService {
private final OpenAIClient client;
public TestAiAnswerServiceImpl(@Value("${openai.api-key}") String apiKey) {
this.client = OpenAIOkHttpClient.builder()
.apiKey(apiKey)
.build();
}
}위에 처럼 @RequiredArgsConstructor와 수동 생성자를 함께 정의하면 충돌이 발생하게 된다.
@RequiredArgsConstructor가 생성한 자동 생성자
public TestAiAnswerServiceImpl(OpenAIClient client) {
this.client = client;
}내가 직접 생성한 생성자
public TestAiAnswerServiceImpl(@Value("${openai.api-key}") String apiKey) {
this.client = OpenAIOkHttpClient.builder()
.apiKey(apiKey)
.build();
}결과적으로 Bean 자체 등록이 되지 않으면서 오류가 발생한 것이다.
✅ 문제 해결
@RequiredArgsConstructor 제거
→ 직접 생성자로 의존 객체를 만드는 방식을 사용
→ 이 클래스는 비즈니스 로직이 있는 게 아니라 설정을 관리하는 로직이기 때문에 @Service 어노테이션을 이용해 제작하는 것이 어색함.
그렇기 때문에, 추후 밑에와 같이 서비스 로직과 인프라 로직을 명확하게 분리해서 사용하는 방식으로 발전해야 한다.
@Configuration
public class OpenAIConfig {
@Value("${openai.api-key}")
private String apiKey;
@Bean
public OpenAIClient openAIClient() {
return OpenAIOkHttpClient.builder()
.apiKey(apiKey)
.build();
}
}그래서 이렇게 AI를 연결하는 로직은 설정에서 만들고, 서비스 로직에서 주입 받고 사용하는 것이 좋다.
(실제로 이후 API를 연결해 진행하는 프로젝트에서는 다음과 같은 방식을 적용함)
3-2. 앞으로의 과정
이번 프로젝트를 진행하면서 docker, k8s, jenkins 등 컨테이너 배포 환경과 CI/CD를 구축하는 방법과 과정에 부족함이 많은것을 깨달았다. 물론, 설정에 필요한 모든 것을 외울 필요는 없지만 어떤 과정으로 진행되고 어떤 설정을 하고 있는지에 대한 인식은 확실하게 필요한 것 같다. 그래서 이 부분에 대한 보충 공부를 많이 해야 할 것 같다.
지난 프로젝트 까지는 백엔드와 프론트엔드를 어떻게 하는지 몰라서 많이 힘들었는데, 그래도 이번 프로젝트에서는 감이 잡혀서 여러 요소를 고민할 수 있는 프로젝트였다.

프로젝트 회고 정리하고 계시군요 ㅎㅎ 잘 보고 갑니다.
1-1 중 프로젝트 배경에 오타가 하나 있네요. (따 -> 다)