✅ 데이터 전환, 검증
데이터 전환 - ETL(Extraction, Transformation, Load)
운영 중인 기존 정보 시스템에 축적된 데이터를 추출, 변환, 적재하여 새로 개발할 정보시스템으로 전환하는 것.
- 데이터 전환 계획서 : 데이터 전환 계획 기록 문서
데이터 검증
데이터 전환 과정이 정상적으로 수행되었는지 여부 확인 과정
- 검증 방법 : 로그, 기본항목, 응용 프로그램, 응용 데이터, 값 검증
- 검증 단계 : 추출, 변환, DB 적재, DB 적재 후, 전환 완료 후
오류 데이터 측정 및 정제
고품질 데이터를 운영 & 관리하기 위해 수행
- 데이터 품질 분석 -> 오류 데이터 측정 -> 오류 데이터 정제
- 상태 : Open, Assigned, Fixed, Closed, Deferred, Classified
- 데이터 정제 요청서
- 데이터 정제 보고서
✅ 데이터 베이스 ⭐️⭐️⭐️
◾️ DB 개요
◽️ 데이터 저장소
📌 데이터를 논리적인 구조로 조직화하거나, 물리적인 공간에 구축한 것.
- 논리 데이터 저장소
- 물리 데이터 저장소
◽️ 데이터베이스 ⭐️
📌 공동으로 사용될 데이터를 중복을 배제하여 통합하고 저장장치에 저장하여 항상 사용할 수 있도록 운영하는 운영데이터.
공통저운
- 공용 데이터(Shared)
- 통합된 데이터(Intergrated) : 중복 배제
- 저장된 데이터(Stored) : 저장 매체에 저장
- 운영 데이터(Operational) : 조직 업무 수행
◽️ DBMS
Database Management System.
📌 사용자의 요구에 따라 정보를 생성해주고 DB를 관리해주는 SW
- 필수 기능 3가지
- 정의 : 데이터 형, 구조, 이용방식 등을 정의&명시
- 조작(manipulation) : 데이터 검색, 삽입 등 인터페이스 제공
- 제어 : 데이터 무결성, 보안, 권한, 병행 제어 제공
◽️ 데이터의 독립성
종속성과 대비되는 말
- 논리적 독립성 : App과 DB를 독립 -> 논리적 구조가 바뀌어도 영향 X
- 물리적 독립성 : App과 기억장치를 독립 -> 디스크 추가/변경 영향 X
◽️ Schema ⭐️
📌 데이버베이스의 구조와 제약조건에 관한 전반적인 명세를 기술한 것
- 외부 스키마
사용자나 개발자가 각자 필요로 하는 DB의 논리적 구조를 정의한 것 - 개념 스키마
DB의 전체적인 논리 구조. 모든 개발자, 사용자가 필요로하는 데이터를 종합한 조직 전체의 DB. 하나만 존재. - 내부 스키마
물리적 저장장치 입장에서 본 DB 구조
◾️ DB 설계
◽️ 설계 시 고려사항
- 무결성, 일관성, 회복, 보안, 효율성, DB 확장
◽️ 설계 순서 ⭐️⭐️⭐️
- 요구 조건 분석
요구조건 명세서 작성 - 개념적 설계(정보모델링, 개념화)
현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정- 개념 스키마 모델링
- 트랜잭션 모델링
- 요구 조건 명세를 DBMS 독립적인 E-R 다이어그램으로 작성
- 논리적 설계(데이터 모델링)
현실 세계에서 발생하는 자료를 목표 DBMS에 맞는 논리적 구조로 변환(mapping) 하는 과정- 논리 스키마 설계
- 트랜잭션 인터페이스 설계
- 물리적 설계
논리적 구조로 표현된 데이터를 실제 물리적 구조의 데이터로 변환하는 과정- 실제 저장 구조, 경로, 레코드 형식 등 결정
- DB 구현
논리적 설계와 물리적 설계에서 도출한 DB 스키마를 파일로 생성하는 과정- 목표 DBMS의 DDL로 DB를 생성
- 트랜잭션 생성
- 트랜잭션 작성
✅ 데이터 모델
◾️ 개념
📌 현실 세계의 정보들을 컴퓨터에 표현하기 위해 단순화, 추상화하여 체계적으로 표현한 개념적 모형
◾️ 데이터 모델 구성요소
◽️ 개체 ⭐️
📌 DB에 표현하려는 것. 개념이나 정보 단위 같은 현실 세계의 대상체
- 속성 : 개체가 가지고 있는 특성 ex) 교수번호, 성명...
- 개체 타입 : 속성으로만 기술된 개체의 정의
- 개체 인스턴스 : 하나의 개체, 개체 Occurence라고도 함
- 개체 세트 : 개체 인스턴스의 집합
◽️ 속성 ⭐️
📌 DB를 구성하는 가장 작은 논리적 단위
- 파일 구조 상의 데이터 필드에 해당함
- 속성의 수는 차수(Degree)라 부름
- 특성에 따른 분류
- 기본(Basic) 속성 : 업무 분석을 통해 정의한 속성
- 설계(Design) 속성 : 설계 과정에서 도출해내는 속성.
- 파생(Derive) 속성 : 계산이나 변형 등의 영향을 받아 발생하는 속성
- 개체 구성 방식에 따른 분류
- 기본키 속성
- 외래키 속성
- 일반 속성
◽️ 관계 ⭐️
📌 개체와 개체 사이의 논리적인 연결. 개체 간 관계, 속성 간 관계가 있다.
- 형태
- 1:1
- 1:N
- N:M
- 종류
- 종속(Dependent) 관계 : 주&종 관계를 표현. 식별, 비식별 관계
- 중복(Rebundant) 관계 : 2번 이상의 종속 관계 발생
- 재귀(Recursive) 관계 : 자신과 관계
- 배타(Exculsive) 관계 : 속성이나 구분자를 기준으로 개체의 특성을 분할하는 관계. 배타 AND, OR 관계로 구분
◾️ 데이터 모델 종류
◽️ 개념적 데이터 모델(정보 모델링, 개념화)
- 이해를 돕기 위해 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정
- 속성으로 기술된 개체 타입과 개체 타입간 관계로 현실 세계 표현
- E-R 모델이 대표적 모델
💡E-R(개체-관계) 모델
개체와 개체 간의 관계를 기본 요소로 이용하여 현실 세계의 무질서한 데이터를 개념적인 논리 데이터로 표현하기 위한 방법
◽️ 논리적 데이터 모델(데이터 모델링)
- 개념적 모델링 과정에서 얻은 개념적 구조를 컴퓨터 세계 환경에 맞도록 변환하는 과정
- 필드로 기술된 데이터 타입과 이 데이터 타입 간 관계로 현실 세계 표현
- 단순히 데이터 모델이라 하면 보통 논리적 데이터 모델을 의미함.
- 관계 모델, 계층 모델, 네트워크 모델로 구분
◽️ 물리적 데이터 모델(데이터 구조화)
논리데이터를 사용하고자 하는 DBMS의 특성을 고려하여 데이터베이스 저장 구조로 변환하는 데이터 모델링 기법
◾️ 데이터 모델에 표시할 요소 ⭐️
◽️ 구조(Stucture)
논리적으로 표현된 개체 타입들 간의 관계로서 데이터 구조 및 정적 성질 표현
◽️ 연산(Operation)
실제 데이터를 처리하는 작업에 대한 명세
◽️ 제약조건(Constraint)
실제 데이터의 논리적인 제약 조건
✅ 관계형 DB ⭐️⭐️⭐️
◾️ 개요
📌 2차원적 표(Table)를 이용해서 데이터 상호 관계를 정의하는 데이터베이스.
- 장점 : 간결하고 보기 편리하며, 다른 DB로의 변환이 용이
- 단점 : 성능이 다소 떨어짐
◾️ 구조
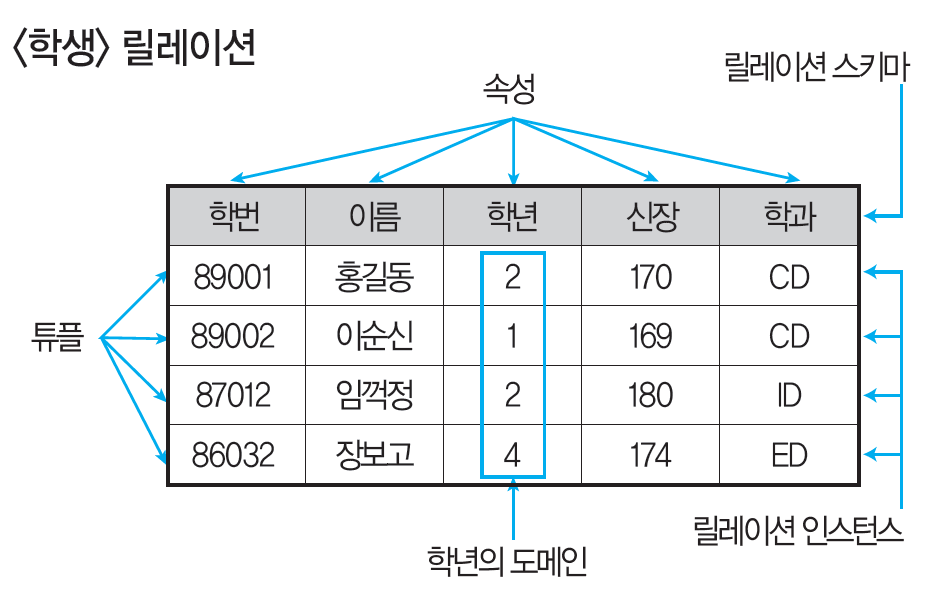
◽️ 릴레이션
데이터들을 표의 형태로 표현한 것. 릴레이션 스키마(구조)와 릴레이션 인스턴스(실제 값)으로 구성됨.
◽️ 튜플
- 릴레이션을 구성하는 각각의 행.
- 파일 구조에서 레코드와 같은 의미
- 속성의 모임
- 튜플의 수를 카디널리티 or 기수, 대응수라 부름
◽️ 속성
- DB를 구성하는 가장 작은 논리적 단위
- 파일 구조에서 데이터 필드에 해당
- 개체의 특성을 기술
- 속성의 수를 디그리(Degree) or 차수로 표현
◽️ 도메인
- 하나의 속성이 취할 수 있는 같은 타입의 원자(Atomic)값들의 집합
◾️ 관계형 데이터 모델
- 2차원적은 표(Table)을 이용해서 데이터 상호관계를 정의하는 데이터 모델
- 논리적 데이터 모델.
- 파일구조처럼 구성한 테이블들을 하나의 DB로 묶어서 테이블 내에 있는 속성 간의 관계를 설정하거나 테이블 간 관계를 설정하여 이용함.
- 계층 모델과 망 모델의 복잡한 구조를 단순화시킨 모델
◾️ 관계형 DB의 제약조건
제약조건이란 DB에 저장되는 데이터의 정확성을 보장하기 위해 key를 이용하여 입력되는 데이터를 제한하는 것. 개체 무결성 제약, 참조 무결성 제약 등이 이에 해당.
◽️ KEY
📌 DB에서 조건을 만족하는 튜플을 찾거나 순서대로 정렬할 때 기준이 되는 속성
- 후보키 : 속성 중 튜플을 유일하게 식별하기 위해 사용되는 속성들의 부분집합
- 유일성 : 하나의 키값으로 하나의 튜플만을 유일하게 식별
- 최소성 : 키를 구성하는 속성 하나를 제거하면 유일하게 식별할 수 없도록 꼭 필요한 최소한의 속성으로 구성
- 기본키 : 후보키 중에서도 특별히 선정된 Main Key
- 대체키 : 후보가 둘 이상일 때 기본키를 제외한 나머지 후보키. 보조키라고도 부름
- 슈퍼키 : 속성들의 집합으로 구성된 키. 유일성 O, 최소성 X
- 외래키 : 다른 릴레이션의 기본키를 참조하는 속성.
◽️ 무결성
-
정의
📌 DB에 저장된 데이터 값과 그것이 표현하는 현실 세계의 실제값이 일치하는 정확성. -
종류
- 개체 무결성 : 기본키를 구성하는 어떤 속성도 Null이나 중복 X
- 참조 무결성 : 릴레이션은 참조할 수 없는 외래키값 X
- 도메인 무결성 : 주어진 속성의 값이 도메인에 속한 값
- 사용자 정의 무결성 : 사용자 정의 제약 조건에 만족
- NULL 무결성 : 특정 속성 값이 NULL X 규정
- 고유 무결성 : 특정 속성 값이 각 튜플마다 서로 달라야 함
- 키 무결성 : 한 릴레이션에는 적어도 하나의 키
- 관계 무결성 : 관계의 적절성 여부를 지정한 규정
-
데이터 무결성 강화
데이터 품질에 영향을 미치기 때문에 데이터 특성에 맞는 적절한 무결성을 정의하고 강화해야 함.- 애플리케이션 단 강화
- DB 트리거 단 강화
- DB 제약 조건 단 강화
◾️ 관계대수
📌 원하는 정보와 그 정보를 검새하기 위해서 어떻게 유도하는가를 기술하는 절차적인 언어
◽️ 순수 관계 연산자
- Select(σ)
선택 조건을 만족하는 튜플의 부분집합을 구하여 새로운 릴레이션을 만드는 연산. 수평연산이라고도 함 - Project(π)
속성 리스트에 제시된 속성값만을 추출
중복 제거
수직연산 - Join(⋈)
두 개의 릴레이션을 공통 속성을 이용하여 하나로 합침
교차곱 수행 후 select를 수행한 것과 같음. - Division(÷)
포함하는 릴레이션이 포함된 릴레이션의 속성을 제외한 속성만을 구하는 연산
릴레이션 A, B가 있을 때 릴레이션 B의 조건에 맞는 것들만 릴레이션 A에서 분리하여 프로젝션을 하는 연산
◽️ 일반 집합 연산자
수학적 이론에서 사용하는 연산자
- 합집합(UNION, ∪)
R∪S = {t| t∈R V t∈S}- cardinality :
|R∪S| <= |R|+|S| - 합병조건(속성의 수가 같고 대응되는 속성별로 도메인이 같아야 함)
- 교집합(INTERSECTION,∩)
- cardinality :
|R∩S| <= MIN{|R|,|S|}
- cardinality :
- 차집합(DIFFERENCE, -)
- cardinality :
|R-S| <= |R|
- cardinality :
- 교차곱(CARTESIAN PRODUCT, ×)
- cardinality :
|R×S| = |R| x |S|
- cardinality :
◾️ 관계해석
- 관계 데이터의 연산을 표현하는 방법
- 원하는 정보가 무엇이라는 것만을 정의하는 비절차적 특성을 지님
- 관계 대수와 관계 해석은 관계형 DB를 처리하는 기능과 능력면에서 동등하며, 관계대수로 표현한 식은 관계해석으로 표현할 수 있다.
✅ 정규화 / 반정규화
◾️ 이상 / 함수적 종속
이상
정규화를 거치지 않으면 DB 내의 데이터들이 불필요하게 중복되어 릴레이션 조작 시 예기치 못한 곤란한 현상이 생긴다. 이를 이상(Anomaly)이라 한다.
- 삽입 이상
- 삭제 이상
- 갱신 이상
함수적 종속
데이터의 의미를 표현하는 것. 현실 세계를 표현하는 제약 조건이 되는 동시에 DB에서 항상 유지되어야 할 조건이다.
X -> Y 면 X가 결정자, Y가 종속자.
- 완전 함수적 종속 : 어떤 속성이 기본키에 대해 완전히 종속적일 때. Y는 X로만 결정할 수 있을 때.
- 부분 함수적 종속
◾️ 정규화(도부이결다조) ⭐️
📌 테이블들의 속성들이 상호 종속적인 관계를 맺는 특성일 이용하여 테이블을 무손실 분해하는 과정.
데이터의 중복성을 최소화하고 일관성 등의 유지를 통해 데이터베이스의 품질을 보장하는 것이 목적.
◽️ 제1 정규형
테이블에 속한 모든 속성의 도메인이 원자값만으로 구성된 정규형
◽️ 제2 정규형
테이블이 제1 정규형이고, 기본키가 아닌 모든 속성이 기본키에 대하여 완전 함수적 종속을 만족하는 정규형. (부분함수적 종속X)
◽️ 제3 정규형
기본키가 아닌 모든 속성이 기본키에 대해 이행적 함수적 종속을 만족하지 않는 정규형
◽️ BCNF
모든 결정자가 후보키(Candidate Key)인 정규형
◽️ 제4 정규형
다중 값 종속(MVD;Multi Valued Dependency) A->>B가 존재할 경우 모든 속성이 A에 함수적 종속 관계를 만족하는 정규형
- 다치 종속 : A,C에 대응하는 B값들이 A ->B이고 C->B가 아니면 A->>B임.
◽️ 제5 정규형
모든 조인 종속(JD;Join Dependency)이 후보키를 통해서만 성립되는 정규형
- 조인 종속 : 속성 부분집합 X, Y, Z. R이 자신의 프로젝션 XYZ를 모드 조인한 결과와 동일한 경우
◾️ 반정규화 ⭐️
📌 시스템 성능 향상 등의 목적으로 정규화된 데이터 모델을 의도적으로 통합, 중복, 분리하여 정규화 원칙을 위배하는 행위
◽️ 테이블 통합
- 고려하는 경우
- 테이블 간 발생하는 프로세스가 동일하게 자주 처리되는 경우
- 항상 두 개의 테이블을 이용하여 조회를 수행하는 경우
- 종류
- 1:1 관계 테이블 통합
- 1:N 관계 테이블 통합
- 슈퍼타입(상위개체)/서브타입(하위개체) 테이블 통합
◽️ 테이블 분할
테이블을 수직 or 수평으로 분할
- 수평 분할 : 레코드별 사용 빈도 차이가 큰 경우, 빈도에 따라 분할
- 수직 분할 : 속성 기준 분할. 갱신 위주 속성 분할, 빈도에 따른 분할, 크기 분할, 보안에 따른 분할 등이 있음
◽️ 중복 테이블 추가
- 고려 경우
- 여러 테이블에서 데이터를 추출해서 사용할 경우
- 다른 서버에 있는 테이블을 이용하는 경우
- 방법
- 집계 테이블 추가 : 집계 데이터를 위한 테이블 생성 + 원본 테이블에 트리거
- 진행 테이블 추가 : 이력 관리 등의 목적
- 특정 부분만을 포함하는 테이블 추가
◽️ 중복 속성 추가
조인해서 데이터를 처리할 때 데이터 조회 경로를 단축하기 위해 자주 사용하는 속성을 하나 더 추가하는 것
- 조인이 자주 발생하는 경우
- 접근 경로가 복잡한 경우
- 액세스 조건으로 자주 사용되는 속성인 경우
- 기본키 형태가 적절치 않거나 여러 개 속성으로 구성된 경우
✅ DB 요소
◾️ 시스템 카탈로그
📌 다양한 객체에 관한 정보를 포함하는 시스템 데이터베이스
DBMS에서 지원하는 모든 데이터 객체에 대한 정의나 명세에 대한 정보를 유지 관리하는 시스템 테이블. 좁은 의미로는 데이터 사전이라고도 함.
◽️ 메타데이터
시스템 카탈로그에 저장된 정보
- DB 객체정보
- 사용자 정보
- 테이블의 무결성 제약 조건 정보
◽️ 데이터 디렉터리
📌 데이터 사전에 수록된 데이터에 접근하는 데 필요한 정보를 관리 유지하는 시스템(시스템만 접근 가능)
◾️ 트랜잭션 분석
◽️ Transaction
📌 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산. 데이터 베이스 시스템 작업의 논리적 단위라고 보면 됨
- 특성
- Atomicity(원자성) : Commit(반영) 되든 Rollback(취소) 되든 해야함.
- Consistency(일관성)
- Isolation(독립성, 순차성)
- Durability(지속성)
- CRUD 분석
프로세스와 테이블간 CRUD 메트릭스를 반들어서 트랜잭션을 분석하는 것
행은 테이블, 열은 프로세스로 두고 어느 테이블이 CRUD 빈도 수가 높은지 체크 가능. - 트랜잭션 분석
단위 프로세스와 CRUD 메트릭스를 이용하여 트랜잭션을 분석함. 테이블에 저장되는 데이터 양을 유추하고 이를 근거로 DB 용량 산정 및 구조의 최적화를 목적으로 함.
◾️ 인덱스, 뷰, 클러스터, 파티션
◽️ 인덱스
📌 데이터 레코드에 빠르게 접근하기 위한 데이터 구조. <key, pointer> 쌍으로 구성됨.
삽입, 수정이 많은 경우에는 인덱스를 최소로하는 게 더 효율적임.
- 종류
- 트리 기반 인덱스 : 인덱스 저장 블록이 트리 구조
- 비트맵 인덱스 : 인덱스 컬럼 데이터를 비트로 변환하여 키로 사용
- 함수 기반 인덱스 : 컬럼에 특성 함수를 적용하여 산출된 값 사용
- 비트맵 조인 인덱스 : 다수의 조인 객체로 구성
- 도메인 인덱스 : 개발자가 인덱스를 직접 만듦
- 클러스터드 인덱스 : 인덱스 키의 순서에 따라 데이터 정렬
검색 속도 빠름 - 넌클러스터드 인덱스 : 인덱스 키값만 정렬
삽입, 삭제 발생 시 순서 유지를 위해 데이터 재정렬 필요
◽️ 뷰
📌 하나 이상의 기본 테이블로부터 유도된 가상 테이블
물리적으로는 존재X. 논리적 테이블 객체
- 장점
- 논리적 데이터 독립성을 제공
- 동일 데이터에 대해 동시에 여러 사용자의 상이한 응용이나 요구를 지원함
- 사용자 데이터 간편하게 관리
- 접근 제어를 통한 자동 보안
- 단점
- 독립적인 인덱스 X
- 뷰 정의 변경 불가
- 삽입, 갱신, 삭제 연산에 제약
◽️ 클러스터
클러스터는 비슷한 종류끼리 묶어주는 거라고 일단 이해.
📌 DB에서 클러스터는 동일한 성격의 데이터를 동일한 데이터 블록에 저장하는 물리적 저장 방법
- 조회 속도 up, 삽입 삭제 성능 down
- 데이터 분포도가 넓을 수록 유리
- 조건에 맞는 레코드 수 / 전체 레코드 수 * 100
- 인덱스는 분포도 낮은(좋은) 게 유리
- 저장 공간 절약 가능
- 처리 범위가 넓을 때는 단일 테이블 클러스터링을, 조인이 만이 발생할 때는 다중 테이블 클러스터링
◽️ 파티션
📌 대용량 테이블이나 인덱스를 작은 논리적 단위인 파티션으로 나누는 것
데이터 처리는 테이블 단위, 데이터 저장은 파티션 단위
- 장점
- 액세스 범위가 줄어 쿼리 성능 향상
- 데이터 분산으로 디스크 성능 향상
- 장애 시 데이터 손상 정도 최소화
- 데이터 가용성 향상
- 입출력 분산
- 단점
- 세심한 관리 필요
- 조인 비용 증가
- 작은 용량 테이블 파티셔닝은 오히려 성능 저하 야기
- 종류
- 범위(Range) 분할 : 지정한 열 기준으로 분할
- 해시(Hash) 분할 : 해시 함수 적용 결과 기준. 고르게 분산(주민 번호, 고객 번호 등)할 때 유용
- 조합(Composite) 분할 : 범위 분할 후 해시 분할.
✅ DB 서버의 가용성을 위한 설계 방법
◾️ 분산 DB 설계 ⭐️⭐️
◽️ DB 용량 설계
데이터가 저장될 공간을 정의
- 테이블에 저장될 데이터 양과 인덱스, 클러스더 등이 차지하는 공간 등 용량을 정확히 산정하여 디스크 저장 공간을 효과적으로 사용하고 확장성&가용성을 높임
- 디스크 입출력 부하를 분산, 채널 병목 현상 최소화
◽️ 분산 DB 설계 ⭐️
📌 논리적으로는 하나의 시스템에 속하지만 물리적으로는 네트워크를 통해 연결된 여러 개의 사이트에 분산된 DB
- 목표
- 위치 투명성(Location Transparency)
액세스 하려는 DB의 실제 위치와 상관없이 논리적 명칭만으로 액세스 - 중복 투명성(Replication Transparency)
동일 데이터가 여러 곳에 중복되어 있더라도 마치 하나의 데이터처럼 사용 - 병행 투명성(Cocurrency Transparency)
분산 DB에 다수 트랜잭션이 동시에 실현되더라도 결과에 영향 X - 장애 투명성(Failure Transparency)
장애 발생 시에도 정확한 트랜잭션 처리
- 위치 투명성(Location Transparency)
- 방법
- 테이블 위치 분산 : 테이블 분산
- 분할 : 테이블 내 데이터를 분산
- 규칙 : 완전성, 재구성, 상호중첩배제
- 방법 : 수평 분할, 수직 분할
- 할당 : 동일한 분할을 여러 개의 서버에 생성. 중복 X, 중복 O 할당으로 나뉨.
◾️ DB 이중화 / 서버 클러스터링
◽️ DB 이중화(Replication)
📌 동일한 DB를 복제하여 관리하는 것. DB 부하를 줄이고 손쉽게 백업 서버 운영이 가능하다.
- 분류
- Eager 기법 : 트랜잭션 중 DB 변경 발생 시, 즉시 변경 사항 적용
- Lazy 기법 : 트랜잭션 중 DB 변경 발생 시, 이후에 새로운 트랜잭션을 생성하여 변경 사항 적용
- 구성 방법
- 활동-대기(Active-Stanby)
- 활동-활동(Active-Active)
◽️ 클러스터링
📌 두 대 이상의 서버를 하나의 서버처럼 운영하는 기술. 서버 이중화&공유 스토리지를 사용하여 서버의 고가용성 제공
- 고가용성 클러스터링
하나의 서버에 장애가 발생하면 다른 서버(노드)가 받아 처리하여 서비스 중단을 방지 - 병렬 처리 클러스터링
전체 처리율을 높이기 위해 하나의 작업을 여러 서버에서 분산 처리
◽️ RTO/RPO
- RTO(Recovery Time Objective) : 목표 복구 시간(얼마나 빨리 복구)
ex) 장애 발생 후 6시간 내 복구 가능 - RPO(Recovery Point Objective) : 목표 복구 시점
ex) 지난주 금요일에 백업시켜 둔 복업 시점으로 복구 가능(얼마나 복구)
✅ DB 보안
◾️ DB 보안
DB에 권한이 없는 사용자가 액세스하는 것을 금지하기 위해 사용되는 기술
◽️ 암호화
Data를 보낼 때 송신자가 지정한 수신자 외에는 그 내용을 알 수 없도록 평문을 암호문으로 변환하는 것
- 개인키 암호 방식
- 공개키 암호 방식
◽️ 접근 통제 ⭐️
📌 데이터가 저장된 객체와 이를 사용하려는 주체 사이의 정보 흐름을 제한하는 것
- 접근 통제 기술
- 임의 접근 통제(DAC;Discrementary Access Control)
주체의 신원에 따라 접근 권한을 부여하는 방식
데이터 소유자가 통제 권한 지정 - 강제 접근 통제(MAC;Mandatory Access Control)
주체의 인가등급과 객체의 보안등급을 비교하여 접근 권한을 부여
시스템이 통제 권한 지정 - 역할기반 접근 통제(RBAC;Role Based Access Control)
주체의 역할에 따라 접근 권한 부여
중앙관리자가 통제 권한 지정
위 2가지 기술 단점 보완, 다중 프로그래밍 환경에 최적화된 방식
- 임의 접근 통제(DAC;Discrementary Access Control)
💡 접근 통제 3요소 : 정책, 매커니즘, 보안 모델
- 접근통제 정책
육하원칙에 따라 허용 여부 결정- 신분 기반 정책 : 주체의 신원에 근거
- IBP(Individual-Based Policy)
- GBP(Group-Based Policy)
- 규칙 기반 정책 : 주체가 갖는 권한에 근거
- MLP(Multi-Level Policy)
- CBP(Cmpartment-Based Policy)
- 역할 기반 정책 : GBP의 변형. 신분이 아니라 역할에 근거
- 신분 기반 정책 : 주체의 신원에 근거
- 접근통제 매커니즘
정의된 접근통제 정책을 구현하는 기술적인 방법- 접근 통제 목록(ACL)
- 능력 리스트(Capablity List)
- 보안 등급
- 패스워드
- 접근통제 보안모델
보안 정책을 구현하기 위한 정형화된 모델- 기밀성 모델
- 무결성 모델
- 접근통제 모델
- 접근통제 행렬(ACM)
임의 접근통제를 관리하기 위한 보안 모델. 행은 주체, 열은 객체로 권한 유형을 나타냄
- 접근통제 행렬(ACM)
- 접근통제 조건
접근통제 매커니즘의 취약점을 보완하기 위해 접근통제 정책에 부가하여 적용할 수 있는 조건- 값 종속 통제(Value-Dependent Control)
- 다중 사용자 통제(Multi-User Control)
- 컨텍스트 기반 통제(Context-Based Control)
◽️ 감사 추적
DB에 접근하여 수행한 모든 활동을 기록
✅ 스토리지 ⭐️
📌 대용량의 데이터를 저장하기 위해 서버와 저장장치를 연결하는 기술
◾️ DAS(Direct Attached Storage)
📌 서버와 저장장치를 전용 케이블로 직접 연결하는 방식
외장하드가 여기에 해당됨
- 장점 : 비용 저렴
- 단점 : 다른 서버 접근 X, 확장성+유연성이 떨어짐
◾️ NAS(Network Attached Storage)
📌 서버와 저장장치를 네트워크를 통해 연결하는 방식
NAS Storage가 내장된 저장장치를 직접 관리
- Ethernet 스위치를 통해 다른 서버에서 접근 가능
- 확장성+유연성 좋음
◾️ SAN(Storage Area Network)
📌 서버와 저장장치를 연결하는 전용 네트워크를 별도로 구성하는 방식
- 파이버 채널 스위치를 이용하여 빠른 속도로 다른 서버와 파일 공유를 할 수 있다.
- 확장성, 유연성, 가용성이 뛰어남
✅ 자료구조 / 알고리즘
◾️ 자료구조
기억장치 공간 내에 저장하는 방법, 자료 간의 관계, 처리 방법 등을 연구 분석 하는 것.
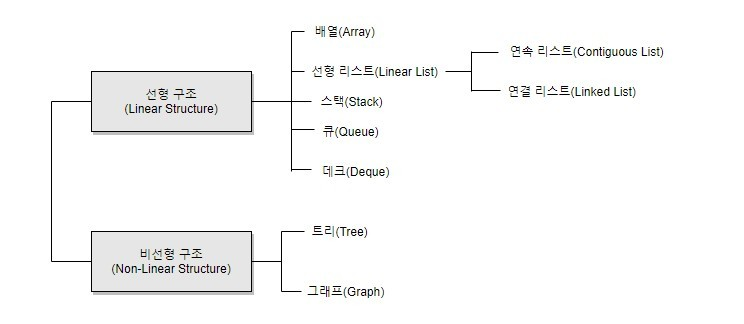
◽️ 배열
크기와 형이 동일한 자료들이 순서대로 나열된 자료의 집합
정적인 자료 구조. 기억 장소 추가가 어려움
◽️ 선형 리스트
- 연속 리스트(Contiguous List)
연속되는 기억장소에 저장되는 자료구조
삽입&삭제 시, 자료의 이동이 필요 - 연결 리스트(Linked List)
자료들을 임의의 기억공간에 기억시키되, 노드의 포인터 부분을 이용하여 서로 연결시킨 자료구조
포인터가 필요해서 기억 공간 이용 효율이 좋지 않고 접근 속도가 느리다.
◽️ 스택
리스트 한쪽 끝으로만 자료의 삽입, 삭제 작업이 이루어지는 자료구조
LIFO(후입선출) 방식
overflow, underflow가 발생할 수 있다.
◽️ 큐
리스트 한쪽에서는 삽입, 다른 한쪽에서는 삭제 작업이 이루어지는 자료구조
FIFO(선입선출)방식
- Front : 시작을 표시하는 포인터
- Rear : 끝을 표시하는 포인터
◽️ 그래프
Vertex와 Edge의 두 집합으로 이루어지는 자료구조
- 방향 그래프
최대 간선 수 :n(n-1) - 무방향 그래프
최대 간선 수 :n(n-1)/2
◾️ 트리 ⭐️
Vertex와 Branch를 이용하여 사이클을 이루지 않도록 구성한 그래프의 특수한 형태
- Node : 자료 항목과 다른 항목에 대한 가지를 합친 것.
- Root Node
- Degree : 각 노드에서 뻗어나온 가지 수
- Terminal(Leaf) Node
- Non-Terminal Node : Degree가 0이 아닌 노드
- Ancestors Node
- Son Node
- Parent Node
- Sibling Node
- Level
- Depth : 트리에서 노드가 가질 수 있는 최대 레벨
- Forest : 트리가 모여있는 것
- Degree of Tree : 노드 디그리 중 가장 큰 수
◾️ 이진트리 ⭐️
차수가 2이하인 노드들로 구성된 트리
- 최대 노드 수 : 레벨 i에서
2**i-1 - 단말 노드 수 : 차수가 2인 노드수가
n2일 때n2 + 1임.
◽️ 운행법
트리를 구성하는 각 노드들을 찾아가는 방법
- Preorder(전위순회)
Root -> Left -> Right - Inorder(중위순회)
Left -> Root -> Right - Postorder(후위순회)
Left -> Right -> Root
◽️ 수식의 표기법
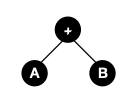
- PreFix(전위표기법) : +AB
- InFix : A+B
- PostFix : AB+
◾️ 정렬 알고리즘 ⭐️
◽️ 삽입 정렬
이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬하는 방
식
2번째 인덱스부터 시작해서 앞의 인덱스 값과 비교하여 더 작다면 삽입하는 방식
- 시간 복잡도 : O(N**2)
◽️ 선택 정렬
n개의 레코드 중 최소값을 찾아 첫 번째에 두고, 나머지 n-1개 중 다시 최소값을 찾아 두 번째 레코드 위치에 두는 방식을 반복하여 정렬
- 시간 복잡도 : O(N**2)
◽️ 버블 정렬
인접한 두 개의 레코드를 비교하여 크기에 따라 레코드를 서로 교환
- 시간 복잡도 : O(N**2)
◽️ 쉘 정렬
매개 변수 값으로 서브 파일 구성하고 각 서브 파일을 삽입 정렬 방식으로 순서 배열하는 과정을 반복
- 시간 복잡도 : O(N**1.5)
◽️ 퀵 정렬
키를 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽 서브 파일에 분해하는 과정 반복
- 평균 시간 복잡도 : O(nlog2**n)
- 최악 시간 복잡도 : O(N**1.5)
◽️ 힙 정렬
완전이진트리를 힙트리로 변환하여 정렬
- 평균, 최악 시간 복잡도 : O(nlog2**n)
◽️ 2-Way 합병 정렬(merge sort)
이미 정렬된 두 개의 파일을 한 개의 파일로 합병하는 정렬 방식
- 평균, 최악 시간 복잡도 : O(nlog2**n)
◽️ 기수 정렬(Radix Sort) = Bucket Sort
Queue를 이용하여 자릿수(Digit) 별로 정렬하는 방식
- 평균, 최악 시간 복잡도 : O(dn)
