instruction을 이해할 수 있다.
Instruction Set
instruction Set은 말 그대로 컴퓨터에서 사용되는 명령어(Instruction)들의 집합
다른 컴퓨터는 다른 Instruction Set을 가짐. (그러나 대부분 구조가 비슷함)
초창기 컴퓨터들은 매우 단순한 Instruction Set을 가지고 있었고, 현대 컴퓨터들도 매우 단순한 Set을 가짐 ->그 이후 complex Instruction Set(CCISC)방식 채택
그러나 초창기와 현대 사이에 복잡한 Instruction Set을 가지는 컴퓨터들도 있었음.(단순-복잡-단순[MIPS])
Instruction Set Architecture
HW와 SW사이의 가장 Low Level Interface
Instruction들을 이용하여 CPU는 레지스터, 메모리, I/O 장치등에 접근
ISA는 말 그대로 추상적인 인터페이스임 (구체적인 회로의 구현은 포함X)
ISA를 사용해서 생기는 장점은 인터페이스만 맞추면 회로의 구현은 자유로울 수 있음
때문에 비용과 성능에 맞춰서 다양하게 구현이 가능함 (같은 SW를 여러 CPU에서 실행 가능)
MIPS Instruction Set
MIPS 이글에서 예제로 사용.
임베디드,ARM에서 사용됨
최신 많은ISAs에 공통된 부분이 많음
- Arithmetic Operation 개요
Arithmetic Operation은 산술연산을 의미함.
add a, b, c 는 a = b + c를 의미함.
= 첫번째 나오는 a를 dethnation, 뒤에 나오는 b,c를 source라고 함
모든 산술연산은 위와 같은 형태(규칙성)을 지님.
Design Principle 1.
Simplicity Favors Regularity (규칙성을 이용해서 간단하게 만들자)
규칙적으로 만들어야 구현하기에 쉬워진다.
단순성을 추구해야 저비용으로 고성능 구조를 만들 수 있다.
예제
// C Code :
f = (g + h) - (i + j);
(바꾸는 일은 컴파일러가 함)
// MIPS Code :
add t0, g, h
add t1, i, j
sub f, t0, t1Register 개요
Arithmetic Instruction은 레지스터를 오퍼랜드(RISC<=MIPS)로 사용한다.
MIPS Architecture의 경우 32Bit의 레지스터를 32개 사용한다. (0 ~ 31번 존재)
MIPS는 32Bit Processor이기 때문에 레지스터에서 한번에 32Bit까지 처리할 수 있다.
32bits 데이터를 word라고 부른다.
많은 레지스터들이 있지만 대표적으로 t0, t1 처럼 t로 시작하는 레지스터는 temporary를 의미하고 s0, s1, $s2 처럼 s로 시작하는 레지스터는 saved value를 의미한다. (t는 가변, s는 불변이다)
Design Principle 2.
Smaller is faster (작을수록 빠르다)
- 일반적으로 메모리(RAM)은 DRAM으로 만들고, 레지스터는 SRAM으로 만듦.
- 그러나 작은 레지스터가 커다란 메모리보다 빠른 이유는 단순히 메모리가 더 용량이 크기 때문이다.
- 메모리가 레지스터보다 크기 때문에 전기적인 신호를 더 멀리 보내야한다.
- 이 때문에 메모리에 엑세스할 때 레지스터보다 Clock Cycle Time이 많이 걸린다.
- 실제로 레지스터에 엑세스하는 시간이 메모리에 엑세스 하는 시간보다 훨씬빠르다.// C Code :
f = (g + h) - (i + j);
// 정확한 MIPS Code :
// f, ..., j in $s0, ..., $s1
add $t0, $s1, $s2
add $t1, $s3, $s4
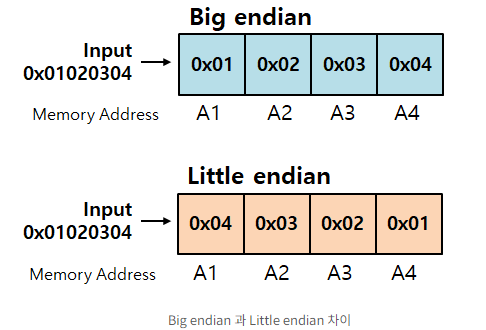
sub $s0, $t0, $t1Byte Order (Endian)
메모리를 어떻게 저장할 것인가에 따른 방식
Big Endian: Leftmost byte is word address (큰 비트가 끝으로 감)
Big Endian Processors: IBM360/370, Motorola 68k, MIPS, Sparc, HP
Little Endian: Rightmost byte is word address (작은 비트가 끝으로 감)
Little Endian Processors: Intel8086, DEC Vax, Dec Alpha (Windows NT)
즉, 레지스터에서 연산한 정보를 메모리에 다시 저장하거나, 메모리에서 레지스터로 메모리를 로드할때
어떤 순서로 데이터를 저장하고, 로드할 것인지에 대한 방식이 바로 Byte Order (Endian) 방식임
Big Endian은 말 그대로 가장 큰 비트(Big)이 끝(Endian)으로 간다는 것임.
위 그림을 보면 0x12345678가 있을 때, 가장 마지막 비트인 0x78이 가장 마지막에 저장됨
그러나 Little Endian은 0x12345678가 있을 때, 가장 앞 비트인 0x12가 가장 마지막에 저장됨
대부분 CPU는 하나의 Endian만 가능하지만, 최근 나온 ARM은 설정으로 통해 둘 중 하나를 고를 수 있음
0x12345678을 거꾸로 뒤집에서 0x87654321과 같이 저장하는 것이 아니라 Word 단위로 거꾸로 저장됨
만약 0x12345678이 32Bit Word 프로세서에서 리틀엔디안으로 저장되면 78 56 34 12로 저장됨.
Big Endian은 디버그를 편하게 해주는 장점이 있다. 사람이 숫자를 읽고 쓰는 방법과 같기 때문에 보기 편하다
Little Endian은 메모리에 저장된 값의 하위 비트만 사용할 때 별도의 계산이 필요없다는 장점이 있다.
이게 무슨말이냐면, 32비트인 0x2A를 Little Endian으로 표기하면 2A 00 00 00이 된다.
이 경우에 앞의 한, 두바이트만 가서 엑세스하여 로딩하면 바로 하위 8Bit, 16Bit를 얻을 수 있지만
이 것을 Big Endian으로 표기하면 00 00 00 2A가 되기 때문에, 변수 주소를 더 뒤로 움직여야 엑세스 가능하다.
Memory Operand
- 보통 메모리는 혼합된 데이터(배열, 구조체, 동적할당 등)을 위해 사용된다.
- Arithmetic Operation을 위해 Register Operand를 사용하려면,
- 가장 먼저 Memory의 데이터를 Register로 Load 해야한다.
- 그리고 Register에서 연산하고, 결과 값을 다시 Memory에 Store한다.
- 이런 구조를 Load - Store 구조라고 한다.
// C Code :
g = h + A[8];
// MIPS Code :
// g in $s1, h in $s2, A in $3
lw $t0, 32($s3) //lw = load Woad
add $s1, $s2, $t0배열 A의 베이스 주소가 s3)를 사용하는데, 이는 $s3의 베이스 주소에서 32Byte를 더한다는 의미이다.
4Byte씩 8번 뒤로 가면 1Word인 A[8]을 얻을 수 있고 이 값을 $t0에 로딩하는 것이다.
// C Code :
A[12] = h + A[8];
// MIPS Code :
lw $t0, 32($s3)
add $t0, $s2, $t0
sw $t0, 48($s3) //12*4lw는 Load Word, sw는 Store Word이다. sw는 말 그대로 레지스터의 데이터를 메모리에 저장하는 것이다.
먼저 A(s3)에서32만큼움직여서A[8]을 t0에 로드하고, 이 값을 h(s2)와더해서다시t0에 저장한다.
결과 값 t0를sw를 통해 48(s3) = A[12]에 저장하는 소스코드이다.
MIPS는 이렇게 Load - Store Architecture를 따르는 프로세서이다. (Instruction이 직접 Memory 엑세스 X)
Load Store 방식을 쓰면 lw, sw등 때문에 더 많은 Instruction을 사용하고, 많은 Register를 사용하게 되는데
Register를 효율적으로 사용(위처럼 다시 $t0 넣어서 공간 절약)하는 것이 굉장히 중요함.
Register vs. Memory
- 레지스터는 메모리보다 훨씬 빠르다.
- 메모리 데이터에서 작동하려면 로드 및 저장이 필요하다.(명령어를 더 써야 한다.)
-가능하면 레지스터 최대한 활용하기
-컴파일러에서는 레지스터를 최대한 줄이는 것이 가장 중요하다.
Immediate Operand
기존 Arithmetic Operand의 경우 모든 오퍼랜드가 레지스터 오퍼랜드였음.
Immediate Operand는 그 중 하나의 오퍼랜드가 상수값을 갖는 경우이다.
addi s3, s3, 4 라고 하면 s3 = s3 + 4가 된다. 상수가 오퍼랜드인 경우 addi를 사용한다.
그러나 이런 Immediate Operand의 경우 음수를 addi하는 것은 가능하지만, subi같은 것은 없다.
즉, 어떤 상수값을 빼고 싶으면 addi로 음수를 더해서 빼야한다.
Design Principle 3.
Make Common Case Fast (일반적으로 자주나오는 경우를 더 빠르게하자)
- 작은 값의 상수는 프로그래밍시 자주 사용한다. (0, 1, 2, ...)
- 그러나 Immediate Operand나 Constant Zero를 지원하지 않는다면, 작은 상수를 사용할 때에도 메모리에서 데이터를 로드해야하기 때문에 상대적으로 느릴 것이다 (lw를 한번 더 사용하기 때문에)Constant Zero
이 레지스터는 항상 0을 가지고 있다.(쓰기가 안됨)
다른 명령어들을 쓰기위해 사용.
이 0은 move Instruction을 구현하기 위해 사용된다.
add t2, s1, 0과 같이 구현하면 t2를 s1으로 옮기는 것으로 해석할 수 있다.
Binary Integers
Unsigned 의 경우 0 to +2(n -1)까지 표현됨
Signed 의 경우 -2(n -1)+1...2(n-1)까지 표현됨
음수가 한개 많은 이유는 양수쪽에는 0이 있기 때문
Signed의 경우 2의 보수를 이용하여 표현하는데, -0과 +0이 같아져서 수 1개를 더 표현할 수 있기 때문
-(-2(n -1))는 표현 못함
Signed Negation
1->0, 0->1
1에서 0으로 바꾼후, 1로 바꿀 때 1을 더해야함(반대도 마찬가지)
Sign Extension
- 비트 값이 증가할 때 어떻게 처리할 것인가?
- 목적: numeric value값을 보존
lb:load bite, lh: load halfword
beq: brunch equal, bnq: brunch not equal
비교할 때32비트로 바꿔서 8번째 값을 나머지 16도 같은 값으로 바꾼 후 비교해야 함.
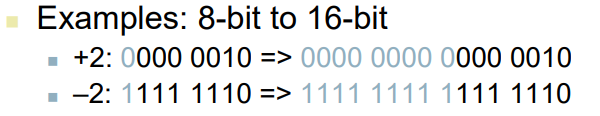
Representing Instruction
- Instruction은 binary로 되어있음
- MIPS 의 비트는 32비트로 되어있음(Regularity를 갖고 있기 때문에 고성능으로 만들기 쉬움)
MIPS R-format
프로그램은 결국엔 여러 명령어로 구성되어있고, CPU는 명령어를 한개씩 불러와서 연산을 수행한다. 그런데 MIPS에는 이러한 명령어의 3가지 Format의 명령어가 존재한다. 첫번째는 R Format 부터알아보자.
1. R Format Instruction
두개의 오퍼랜드를 가지는 레지스터 2개와 연산 결과를 저장하는 레지스터 1개를 가리키는 명령어 구조이며, 일반적으로 Arithmetic Operation이나 Logic Operation에 사용된다. (add, sub, mul, div, and, or 등)

opcode: funct와 함께 명령어의 종류를 나타낸다. (operation code)
rs: 첫번째 오퍼랜드가 들어가는 레지스터의 주소를 담고 있다. (source register)
rt: 두번째 오퍼랜드가 들어가는 레지스터의 주소를 담고 있다. (target register)
rd: 결과값이 담길 레지스터의 주소를 담고 있다. (destination register)
shamt: 얼마나 쉬프트 할지에 대한 정보를 담고있다 (shift amount)
funct: opcode와 함께 명령어의 종류를 나타낸다 opcode [확장한것](function code)
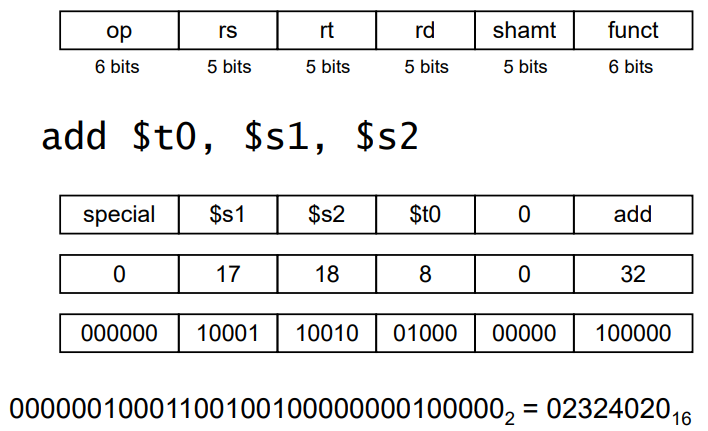
add 경우 opcode는 special, rs는 s1, rt는 s2, rd는 t0, shamt는 0, funct는 add이다.
때문에 아래와 같이 명령어가 기계어로 번역된다.
사람은 기계어를 읽기 힘들기 때문에 어셈블리어를 사용한다.
add, t0, s1, s2와 같은 MIPS Code도 어셈블리어의 일종이다.
rs, rd, rt가 5바이트인 이유는 MIPS가 32개의 레지스터를 가지기 때문이다 (25=32)
R format은 I나 J format에 비해 공간의 여유가 있기 때문에 opcode에 special 0을 쓰고
실제 명령어인 add는 funct 칸에 적고 사용한다.
2. I Format Instruction
I Format Instruction은 앞서 살펴봤던 Immediate Operation, Transfer(lw/sw 등), Branch 등을 위해 사용되는 Instruction Format이다. 때문에 상수, 혹은 주소의 위치를 오퍼랜드로 가진다. (addi, lw, sw, lb, sb, lh, sh, beq 등) I Foramt이 쓰이는 가장 중요한 이유는 레지스터가 아닌 메모리에 접근해서 무언가를 가져오거나, 상수를 반드시 써야할 때 사용된다. (레지스터가 아닌 오퍼랜드를 쓸때 I Format을 유용하게 사용한다)

op : opcde로 명령어를 나타낸다.
rs : 소스 레지스터 또는 목적지를 나타낸다
rt : 타겟 레지스터를 나타낸다.
address/immediate : 주소나 상수를 나타낸다. (rs값에 더한다)
Contact: -2 to + 2 + 2(15-1)의 범위를 나타냄.
Design Principle 4.
Good deisgn demands good compromise (좋은 디자인은 좋은 타협을 요구한다)
- immediate operation과 load-store operation을 모두 I format으로 만들었음.
- 새로운 format을 만들지 않고 어느정도 타협해서 비슷하면 묶어서 처리했음.
- 이렇게 되면 구조 자체가 단순해지고 단순성은 고성능으로 연결된다.Stored Program Computers
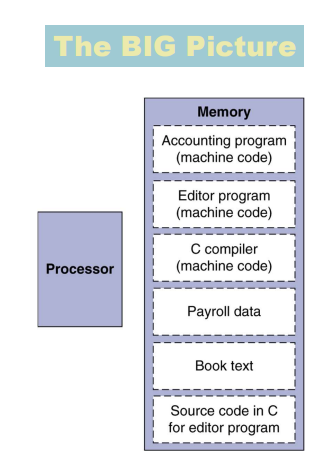
Instruction:
Instruction과 data는 메모리에 저장되어 있다.
Binary compatibility는 컴파일된 프로그램이 다른 컴퓨터에서 작동할 수 있다.(ISA)
shift Operation(left, right)
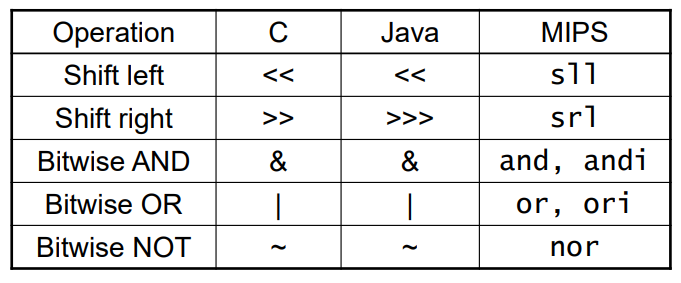
1) Shift Operation

shamt:몇비트만큼 움직일 것인가
- 왼쪽/오른쪽으로 이동하고, 빈 값에 0채운다.(i만큼 움직일 때 원래값에 2의 i승만큼 곱한다/나눈다.(오른쪽은 양수만 적용)
- srl은 unsigned number에서만 가능함. (부호비트가 오른쪽으로 움직여지면 부호가 바뀌어버림)
2) And Operation (and, andi)
and는 R format으로 우리가 흔히 알고 있는 Bitwise And연산이 맞다. andi의 경우 and의 immediate 버전이다. (당연히 I foramt이다)
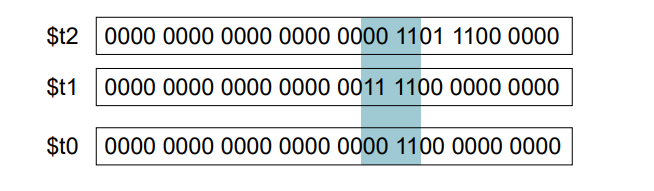
- 어떤 특정비트의 값을 뽑아낼때 and연산을 많이 사용한다.
- 예를 들어 0011 0101이라는 데이터가 있을 때 하위 네비트에서만 데이터를 뽑고 싶으면
- 0011 0101 and 0000 1111을 사용하면 0000 0101로 하위 4비트만 뽑아져 나온다.
3) Or Operation (or, ori)
or 역시 R format으로 우리가 흔히 알고 있는 Bitwise Or 연산이 맞다. ori의 경우 or의 immediate 버전이다 (당연히 I format이다)

- 특정 비트들을 전부 1로 만들고 싶을 때 사용한다.
- 예를 들어 0101 0001에서 뒤쪽 4비트를 전부 1로 만들고 싶으면
- 0101 0001 or 0000 1111을 사용하면 0101 1111로 뒤쪽 비트가 전부 1로 켜진다.
4) Not Operation (nor로 구현)
Not연산은 조금 특이한데 not이라는 명령어를 사용하지 않고 nor이라는 명령어 (not or)을 사용하여 구현한다.
A NOR b = NOT(a OR b)

- t1 or zero = t1 그대로가 된다. 그리고 여기에 not 연산을 취하면 not t1이 된다.
- not은 하나의 레지스터 오퍼랜드만 필요하지만, 규칙성을 맞춰야하기 때문에 이런식으로 구현되었다.
- 즉, not(t1 or zero) = not(t1)과 같기 때문에 R format에서 not을 사용할 수 있는 것이다.
- Simplicity favors regularity! (규칙성을 통해 단순하게)
- good design demands good compromise! (좋은디자인은 어느정도 타협을 요구함)
Conditional Operation
Conditional Operation은 if, else, goto, for, while, switch 등의 제어문을 구현하기 위해 사용된다. 대표적으로 beq(if ==), bne (if !=), j(goto)가 있다. 이들은 I format 혹은 J format 명령어들이다.
1) beq (Branch Equal)
beq는 I format instruction으로 rs와 rt에 있는 값이 같으면 특정 라벨로 이동시킨다.(L1에 있는 명령어 실행)
beq rs, rt, L1과 같이 표기한다. (L1은 특정 명령어가 포함된 주소공간이 된다)
만약 rs와 rt가 다르면 그냥 무시하고 다음 명령어를 실행하게 된다.
2) bne (Branch Not Eqaul)
bne는 I format instruction으로 rs와 rt의 값이 다르면 특정 라벨로 이동시킨다.
else를 구현하는데 용이하게 사용될 수 있다.
3) j (Jump) & J format Instruction
j는 jump로서 J format Instruction이다. J format Instruction의 구조는 다음과 같다.
J format의 구조는 매우 간단한데 opcode(jump)와 이동할 주소를 표현할 26비트의 주소필드로 구성된다.
j L1과 같이 호출하면, L1의 필드로 곧장 분기하여 점프한다.
//C code:
if (i==j) f = g+h;
else f = g-h;
//f,g,... in $s0,$s1,...
Compiled MIPS code:\
bne $s3, $s4, Else
add $s0, $s1, $s2
j Exit
Else: sub $s0, $s1, $s2
Exit: ...4) Loop Condition (While, For 등)
//C code:
while (save[i] == k) i += 1;
i in $s3, k in $s5, address of save in $s6
//Compiled MIPS code:
Loop: sll $t1, $s3, 2 //s3*4 *2의 2승은 4이기 때문
add $t1, $t1, $s6 //save[i]의 시작주소값:위의 값+t1
lw $t0, 0($t1)
bne $t0, $s5, Exit //31의값과 t0값 비교
addi $s3, $s3, 1 //같다면 1만큼 충전시킨다.
j Loop // 다시 처음 위치로 돌아간다.
Exit: save[i]:integer array
Basic Block
Basic block이란 instruction들의 순서대로 모인 집합이다.
ㆍembedded branch(일체형 분기)는 없다.(끝 부분을 제외하고. 끝에는 있을 수 있음.)
ㆍbranch target(분기 대상, labeled)은 없다.(처음 시작 부분을 제외하고. 처음에는 있을 수 있음.)!
ㆍ즉, 중간에는 branch(분기)도 없고, labeled된(점프할 곳으로 지정된) 곳도 없다. 분기가 없는 일련의 연속 작업 덩어리
*컴파일러는 최적화를 위해 이런 basic block들을 찾아낸다.
*진보된(고성능) 프로세서는 basic block들의 수행을 가속시킬 수 있다
{kind=link}
more Conditional Operation
1. slt (Set on Less Than)
R format instruction
- slt rd, rs, rt 라고 작성하면 rs < rt일때, rd의 값이 1이되고, 그렇지 않으면 0이 된다.
- slt를 이용해 if, else, while, for문 등에서 값의 대소비교를 수행할 수 있게 된다.
2. slti (Set on Less Than immediate)
- slt의 immediate 버전으로 I format instruction이다.
- slti rt, rs, constant와 같이 적으면 rs < constant이면 rt = 1이고, 그렇지 않으면 0이 된다.
3. 왜 Branch Less Than 과 같은 명령어는 없을까?
- <나 >=와 같은 연산들은 ==, != 보다 훨씬 느리기 때문에 branch equal / not equal 만 제작했다.
- ==는 sub 한 값이 0과 같으면 구현 가능, !=는 sub한 값이 sub한 값이 0과 다르면 구현 가능.
- 그러나 <를 하나의 명령어로 구현하면 매우 느려지기 때문에 구현하지 않는다.
4. sltu, sltui (unsigned number comparison)
{kind=link}
Register Usage
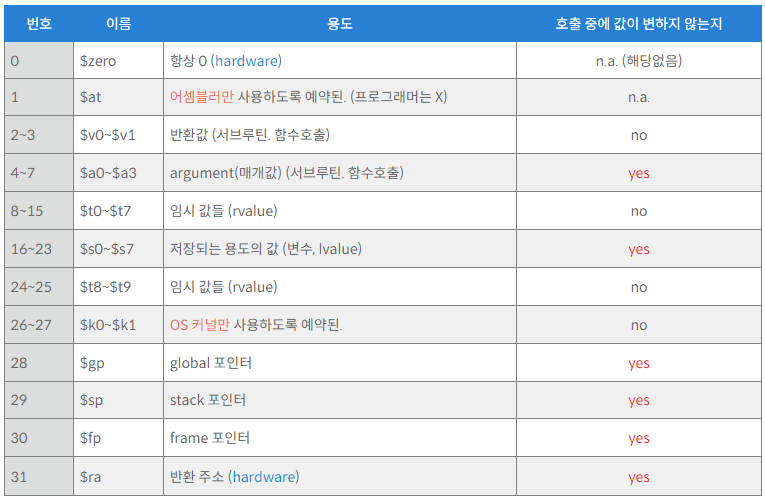
Procedure Call : jump and link (jal)
jal ProcedureLabel
*바로 다음에 올 instruction의 주소를 $ra에 담는다.(프로시저(서브루틴)가 종료되면 다음으로 진행되기 위해) *대상 주소(프로시저가 수행되기 위해 label 된)로 점프
jal 명령어는 두가지 작업을 한번에 진행함
1) 함수 호출 이후에 실행될 명령어의 주소를 $ra에 넣음
2) 해당 타겟 레이블이 있는 곳으로 점프함
jr $ra
jr 명령어는 레지스터 하나를 받는데, 해당 레지스터에 저장된 주소 값으로 점프함
즉, jr명령어를 쓰면 ra레지스터의 값을 pc(프로그램 카운터)라는 레지스터에 복사함
프로그램 카운터에는 실행중인 명령어의 메모리주소가 담겨있음 (code/text 영역)
jal명령어를 통해 Caller에서 Callee호출 이후 작업의 주소를 ra로 점프하면 함수 호출 이후의 작업들로 이어나갈 수 있는 것임
ㆍe.g., case/switch 문 등의 조건문에서도 역시 활용될 수 있음
Leaf Procedure Example
- 한 함수에서 다른 함수를 호출하지 않는 함수를 leaf procedure라고 함
- 여기에서 새로 눈여겨 볼 것은 변수를 할당하고, 반환하는 과정까지 포함되었음
- 이전 포스팅 들에서는 그냥 "변수f가 s0에 맵핑되어있다" 이런식으로 표현했는데
- 사실 addi로 스택포인터를 필요한 바이트만큼 내리고, 그 그 값을 저장하여 할당하고,
- 다시 addi로 해당 바이트 만큼 올리고 그 값을 메모리에 쓰는 과정까지 매우 자세히 나와있음
- 마지막에는 jr명령어를 통해 이전에 jal할 때 넣어둔 ra의 명령어주소로 넘어가면서 끝남!
{kind=link}
C code:
int leaf_example (int g, h, i, j)
{ int f;
f = (g + h) - (i + j);
return f;
}
Arguments g, …, j in $a0, …, $a3
f in $s0 (hence, need to save $s0 on stack)
Result in $v0Leaf Procedure Example
addi $sp, $sp, -4 //sp의 값에서 4바이트만큼 메모리를 할당
sw $s0, 0($sp) //s0를 스택(0($sp))에 복사
add $t0, $a0, $a1 //t0=a0+a1
add $t1, $a2, $a3 //t1=a2+a3
sub $s0, $t0, $t1 //s0=t0-t1
add $v0, $s0, $zero //v0=s0
lw $s0, 0($sp) //s0=스택(0($sp))
addi $sp, $sp, 4 //sp+=4
jr $ra //ra에 할당된 값으로 복원ra -> pc -> caller
Non Leaf Procedure(if문)
- Non Leaf Procedure는 스택프레임에 반드시 ra (반환 주소)를 저장해야한다. (덮어씌이기 때문에)
- 필요에 따라서 파라미터들도 덮어 쓰여질 수 있으니, 스택에 저장해야 하는 경우도 있다.
- 리턴될 때는, 메모리에서 ra를 로드한 뒤에, 다시 스택포인터를 올려주고 ra로 jump해야한다.
- recursion이 아닌 코드는 Non Leaf Procedure는 이전 글의 코드를 보면 확인할 수 있다.
fact:
addi $sp, $sp, -8 # adjust stack for 2 items
sw $ra, 4($sp) # save return address
sw $a0, 0($sp) # save argument
slti $t0, $a0, 1 # test for n < 1, t0=1
beq $t0, $zero, L1 #t0==zero ->L1
addi $v0, $zero, 1 # if so, result is 1
addi $sp, $sp, 8 # pop 2 items from stack
jr $ra # and return
L1: addi $a0, $a0, -1 # else decrement n
jal fact # recursive call
lw $a0, 0($sp) # restore original n
lw $ra, 4($sp) # and return address
addi $sp, $sp, 8 # pop 2 items from stack
mul $v0, $a0, $v0 # multiply to get result
jr $ra # and return
Activation Record in Stack
C code:
int fact (int n)
{
if (n < 1) return 1;
else return n * fact(n - 1);
}
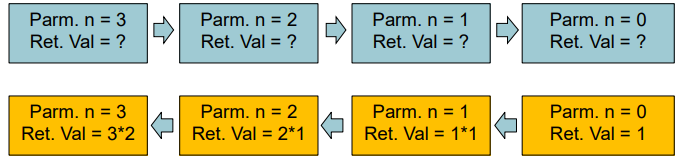
솔직히 이부분 이해안감
Local Data on the Stack
지역변수는 스택에 할당됨!
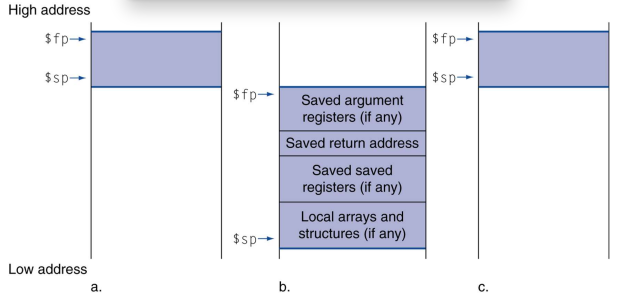
- 우리가 함수를 만들 땐, 아래와 같이 공간을 만들어야하는데 (고급언어는 자동으로 만들어짐)
- 함수마다 return address와 argument, variable등이 저장되는 공간을 통틀어서 activation record 혹은
- stack frame이라고 부른다. (우리가 고급언어에서 알고 있었던 그 스택프레임이 맞다)
- sp는 stack pointer의 줄임말로 스택 프레임의 가장 아랫부분을 가리키는 포인터로 사용되며,
- fp는 frame pointer의 줄임말로 스택 프레임의 구장 윗부분을 가리키는 포인터로 사용된다.
Memory Layout
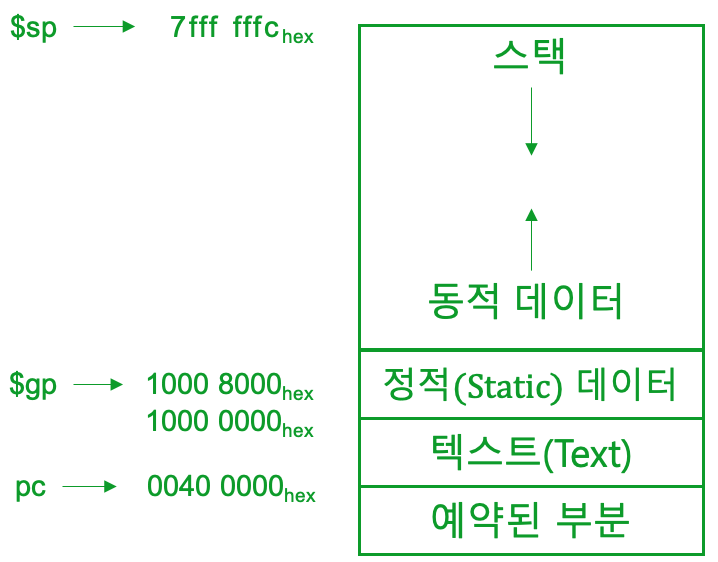
Text: 프로그램 코드(명령어)
Static data: global variables (C언어의 전역변수, $gp(글로벌포인터)segment의 중간값)
Dynamic data: heap( E.g., malloc in C, new in Java)위로 실행
Stack: automatic storage 아래로 실행!
Byte/Halfword Operations
lb / sb : 1바이트 로드/스토어
lh / sh : 하프워드 로드/스토어
로드시 : 32비트로 extend 되어서 4바이트로 로드됨, 레지스터 크기가 32비트로 고정되어 어쩔 수 없음
저장시 : rightmost 비트들만 잘라서 저장함 (sp 조금씩 움직이면서 바이트별로 저장 가능함)
예를 들어 아래처럼 스택포인터를 한칸씩 내리면서 0001 86a0을 1바이트만 저장(sb)하면
rightmost로 잘라서 a0만 저장된다. 16진수는 4비트이기 때문에 16진수 2개인 8비트(1바이트)만 저장
그리고 스택포인터를 1칸 움직이고, 다시 같은 값을 저장하면 그 바로 옆에 a0a0와 같이 저장된다.
C


