
1) 구간 분할
import pandas as pd
import numpy as np
df = pd.read_csv('./auto-mpg.csv', header = None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight','acceleration','model year', 'origin', 'name']
df['horsepower'].replace('?', np.nan, inplace = True)
# ?을 NaN 값으로 대체
df.dropna(subset = ['horsepower'], axis = 0, inplace = True)
# horsepower 내 NaN 값 drop
df['horsepower'] = df['horsepower'].astype('float')
# object 형을 float 형으로 변환
count , bin_dividers = np.histogram(df['horsepower'], bins = 3)
# np.histogram 함수로 3개의 bin으로 나누는 경계값의 리스트 구하기
print(bin_dividers)
bin_name = ['저출력', '보통출력', '고출력']
# 3개의 bin 이름 지정
df['hp_bin'] = pd.cut(x = df['horsepower'],
bins = bin_dividers,
labels = bin_name,
include_lowest = True) # 첫 경계값 포함
# pd.cut 함수로 각 데이터를 3개의 bin에 할당
print(df[['horsepower', 'hp_bin']].head(10))
2) 더미 변수
숫자 0 또는 1로 표현되는 더미 변수
특성이 있는지 없는지를 표현하는 변수
해당 특성이 존재하면 1
해당 특성이 존재하지 않으면 0
horsepower_dummies = pd.get_dummies(df['hp_bin'])
# hp_bin 열의 범주형 데이터를 더미 변수로 변환 (원핫인코딩)
print(horsepower_dummies.head(10))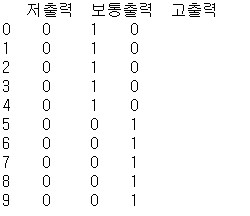
3) sklearn을 활용한 원핫인코딩
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
onehot_encoder = preprocessing.OneHotEncoder()
onehot_labeled = label_encoder.fit_transform(df['hp_bin'].head(15))
# label_encoder로 문자열 범주를 숫자형 범주로 변환
print(onehot_labeled)
onehot_reshaped = onehot_labeled.reshape(len(onehot_labeled),1)
# 2차원 행렬로 형태 변경
print(onehot_reshaped)
onehot_fitted = onehot_encoder.fit_transform(onehot_reshaped)
# 희소행렬로 변환
# (행, 열)에 데이터 값이 있음을 1.0으로 표현
print(onehot_fitted)

따또의 DA 벨로그