
1) 데이터프레임 연결
import pandas as pd
df1 = pd.DataFrame({'a' : ['a0', 'a1', 'a2', 'a3'],
'b' : ['b0', 'b1', 'b2', 'b3'],
'c' : ['c0', 'c1', 'c2', 'c3']},
index = [0,1,2,3])
df2 = pd.DataFrame({'a' : ['a2', 'a3', 'a4', 'a5'],
'b' : ['b2', 'b3', 'b4', 'b5'],
'c' : ['c2', 'c3', 'c4', 'c5'],
'd' : ['d2', 'd3', 'd4', 'd5'] },
index = [2,3,4,5])
result1 = pd.concat([df1, df2])
# 2개의 데이터프레임을 위 아래 행 방향으로 이어붙이듯 연결
print(result1)
result2 = pd.concat([df1, df2], ignore_index = True)
# 2개의 데이터프레임을 위 아래 행 방향으로 이어붙이듯 연결
# 기존 행 인덱스 무시 & 새로운 행 인덱스 설정
print(result2)
result3 = pd.concat([df1,df2], axis =1)
# 2개의 데이터프레임을 좌우 열 방향으로 이어붙이듯 연결
print(result3)
result4 = pd.concat([df1, df2], axis = 1, join = 'inner')
# 2개의 데이터프레임 내 공통으로 존재하는 데이터만 반환
print(result4)
sr1 = pd.Series(['e0', 'e1', 'e2', 'e3'], name = 'e')
sr2 = pd.Series(['f0', 'f1', 'f2'], name = 'f', index = [3,4,5])
sr3 = pd.Series(['g0', 'g1', 'g2', 'g3'], name = 'g')
result5 = pd.concat([df1, sr1], axis =1, sort = True)
# df1 데이터프레임에 e열 추가
print(result5)
result6 = pd.concat([sr1,sr3], axis =0)
print(result6)
2) 데이터프레임 병합
import pandas as pd
pd.set_option('display.max_columns', 10) # 출력할 최대 열의 개수
pd.set_option('display.max_colwidth', 20) # 출력할 열의 너비
pd.set_option('display.unicode.east_asian_width', True) # 유니코드 사용 너비 조정
df1 = pd.read_excel('./stock price.xlsx')
df2 = pd.read_excel('./stock valuation.xlsx')
merge_inner = pd.merge(df1,df2)
# df1과 df2 합치기 (교집합)
print(merge_inner)
merge_outer = pd.merge(df1,df2, how = 'outer', on = 'id')
# df1과 df2 합치기 (합집합)
# id 열을 기준으로 합침
print(merge_outer)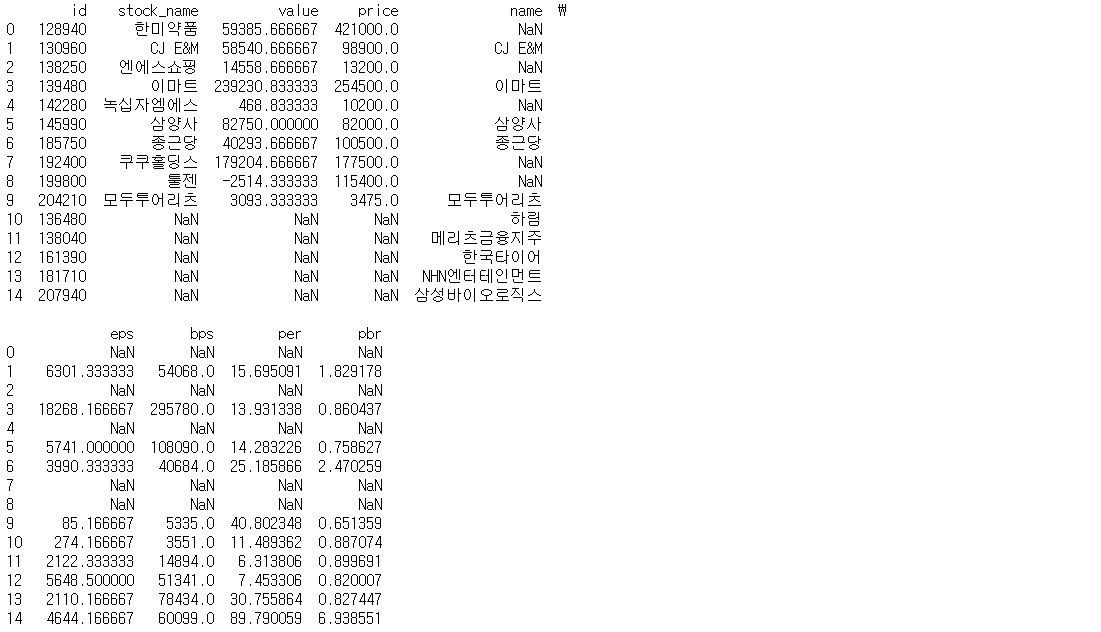
merge_left = pd.merge(df1,df2, how = 'left', left_on = 'stock_name', right_on = 'name')
# df1과 df2 합치기 (왼쪽 데이터프레임 기준)
# df1의 stock_name 열과 df2의 name 열을 기준으로 병합
print(merge_left)
merge_right = pd.merge(df1,df2, how = 'right', left_on = 'stock_name', right_on = 'name')
# df1과 df2 합치기 (오른쪽 데이터프레임 기준)
# df1의 stock_name 열과 df2의 name 열을 기준으로 병합
print(merge_right)
price = df1[df1['price'] < 50000]
# df1 중 가격이 50000 미만인 것
value = pd.merge(price, df2)
# df1 중 가격이 50000 미만이면서 df2에 존재하는 것
print(value)
3) 데이터프레임 결합
join() 메소드는 두 데이터프레임의 행 인덱스를 기준으로 결합
on = 'keys' 옵션을 사용하면 열을 기준으로 결합하는 것이 가능
import pandas as pd
pd.set_option('display.max_columns', 10) # 출력할 최대 열의 개수
pd.set_option('display.max_colwidth', 20) # 출력할 열의 너비
pd.set_option('display.unicode.east_asian_width', True) # 유니코드 사용 너비 조정
df1 = pd.read_excel('./stock price.xlsx', index_col = 'id')
df2 = pd.read_excel('./stock valuation.xlsx', index_col = 'id')
df3 = df1.join(df2)
# df1과 df2 결합
# df1을 기준으로 df2 결합(df2에 존재하지 않아도 df1에 존재하면 결합), how = 'left' 옵션이 기본으로 적용됨
print(df3)
df4 = df1.join(df2, how = 'inner')
# df1과 df2 교집합
# df1과 df2에 모두 존재하는 값만 추출
print(df4)

따또의 DA 벨로그