
1) 단순회귀분석
- 두 변수 사이에 일대일로 대응되는 확률적, 통계적 상관성을 찾는 알고리즘
- 대표적인 지도학습 유형
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('./auto-mpg.csv', header = None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration',
'model year', 'origin', 'name']
pd.set_option('display.max_columns', 10)
df['horsepower'].replace('?', np.nan, inplace=True)
df.dropna(subset=['horsepower'], axis = 0, inplace = True)
df['horsepower'] = df['horsepower'].astype('float')
ndf = df[['mpg', 'cylinders', 'horsepower', 'weight']]
ndf.plot(kind = 'scatter', x = 'weight', y = 'mpg', c = 'coral', s = 10, figsize = (10,5))
# 산점도 그리기
# x축은 weight, y축은 mpg, 산점도의 색은 코랄색, 점의 크기는 10, 그래프 사이즈는 (10,5)
plt.show()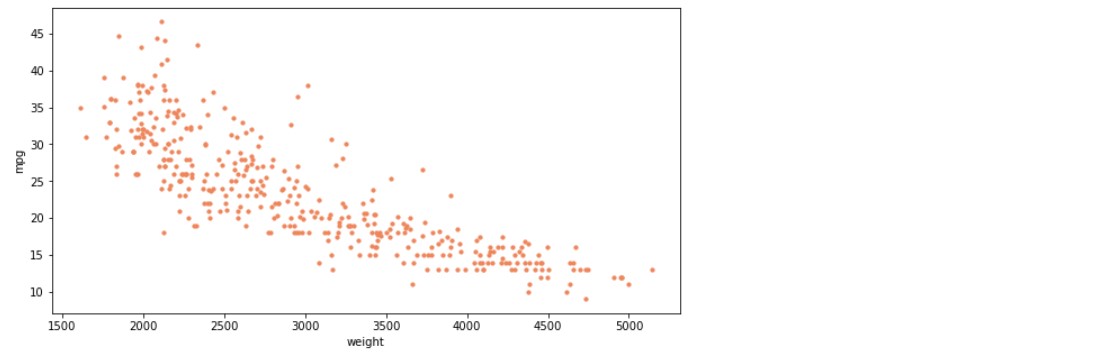
fig = plt.figure(figsize = (10,5))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
sns.regplot(x = 'weight', y = 'mpg', data = ndf, ax = ax1)
# 회귀선 표시
# regplot() 함수를 이용하여 두 변수에 대한 산점도 그리기 가능
sns.regplot(x = 'weight', y = 'mpg', data = ndf, ax = ax2, fit_reg = False)
# 회귀선 미표시
plt.show()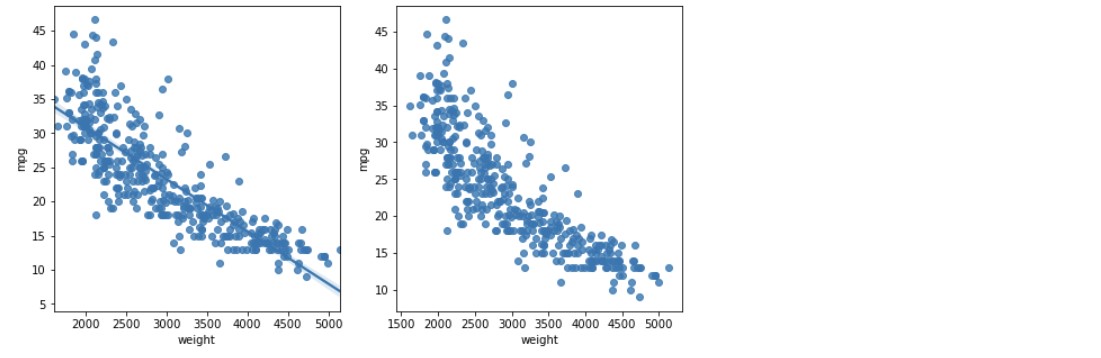
sns.jointplot(x = 'weight', y = 'mpg', data = ndf)
# 산점도, 히스토그램
# 회귀선 없음
sns.jointplot(x = 'weight', y = 'mpg', kind = 'reg', data = ndf)
# 산점도, 히스토그램
# 회귀선 있음
plt.show()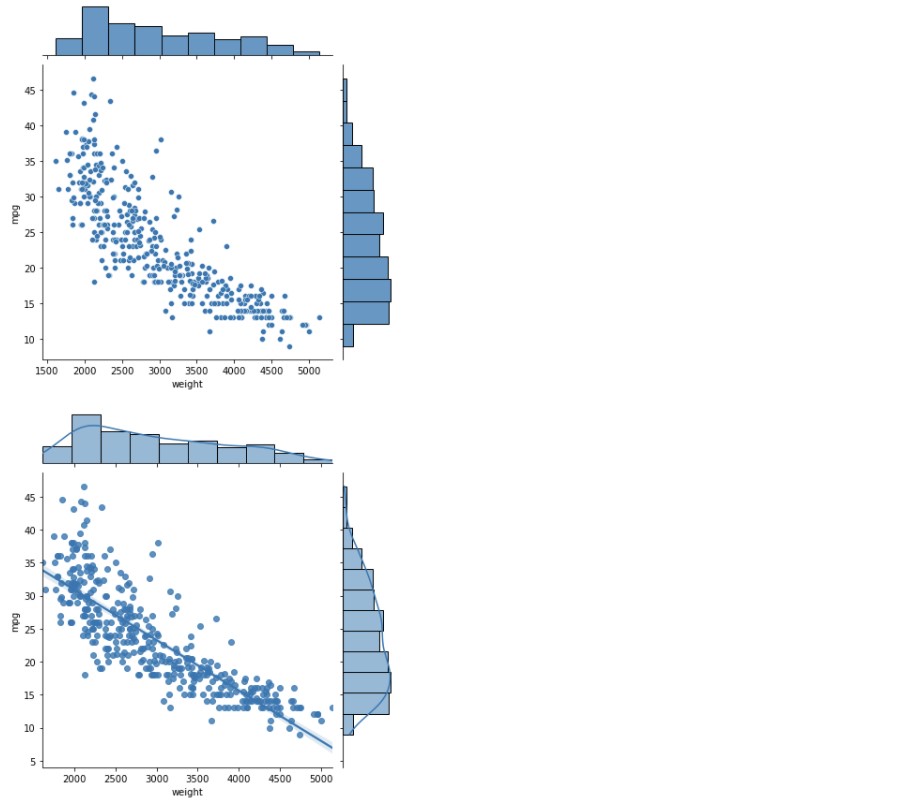
grid_ndf = sns.pairplot(ndf)
# ndf에 속한 4가지 변수에 대한 모든 경우의 수 그리기
plt.show()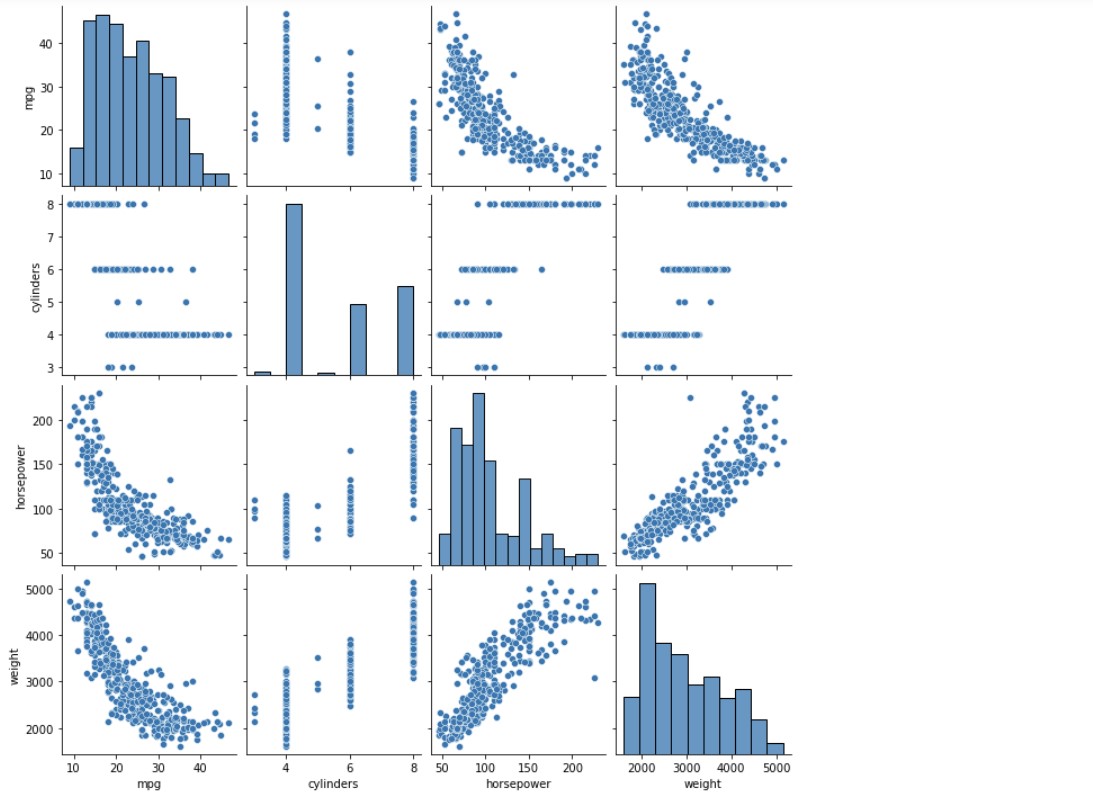
X = ndf[['weight']]
# 독립변수 weight
y = ndf['mpg']
# 종속변수 mpg
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 10)
# 전체 데이터를 test : train = 3 : 7로 나누기
lr = LinearRegression()
# 단순회귀분석 모형 객체 생성
lr.fit(X_train, y_train)
# train data를 가지고 모형 학습
print('기울기 : ', lr.coef_)
print('y 절편 : ', lr.intercept_)
y_hat = lr.predict(X)
# X를 통해 예측한 값을 y_hat에 저장
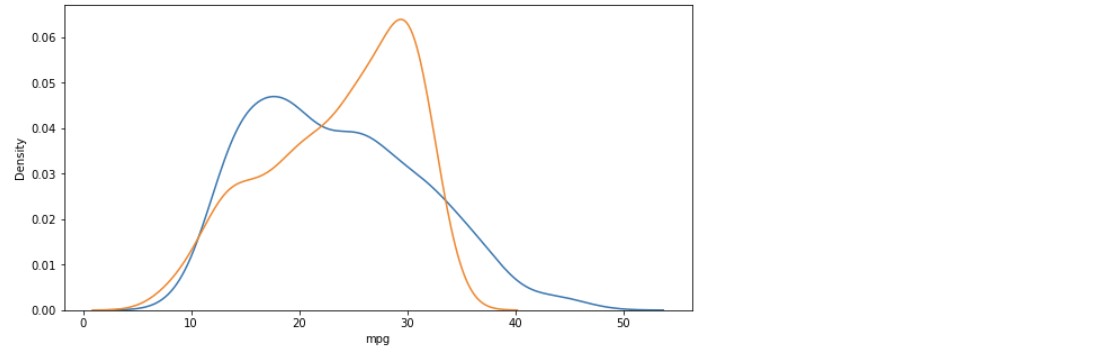
plt.figure(figsize = (10, 5))
ax1 = sns.distplot(y, hist = False, label = "y")
# 실제 y값
ax2 = sns.distplot(y_hat, hist = False, label ="y_hat", ax = ax1)
# 예측한 y값
plt.show()
2) 다항회귀분석
- 다항 함수를 사용하면 보다 복잡한 곡선 형태의 회귀선 표현 가능
- 2차함수 이상의 다항함수를 사용
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('./auto-mpg.csv', header = None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration',
'model year', 'origin', 'name']
pd.set_option('display.max_columns', 10)
df['horsepower'].replace('?', np.nan, inplace=True)
df.dropna(subset=['horsepower'], axis = 0, inplace = True)
df['horsepower'] = df['horsepower'].astype('float')
ndf = df[['mpg', 'cylinders', 'horsepower', 'weight']]
X = ndf[['weight']]
# 독립변수 weight
y = ndf['mpg']
# 종속변수 mpg
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 10)
# 전체 데이터를 test : train = 3 : 7로 나누기
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree = 2)
# 2차항 적용
X_train_poly = poly.fit_transform(X_train)
# X_train 데이터를 2차항으로 변환
pr = LinearRegression()
pr.fit(X_train_poly, y_train)
X_test_poly = poly.fit_transform(X_test)
y_hat_test = pr.predict(X_test_poly)
fig = plt.figure(figsize = (10, 5))
ax = fig.add_subplot(1,1,1)
ax.plot(X_train, y_train, 'o', label = 'Train Data')
# train 데이터 값을 o으로 표현
ax.plot(X_test, y_hat_test, 'r+', label = 'Predicted Value')
# 예측한 값을 + 로 표현
ax.legend(loc = 'best')
plt.xlabel('weight')
plt.ylabel('mpg')
plt.show()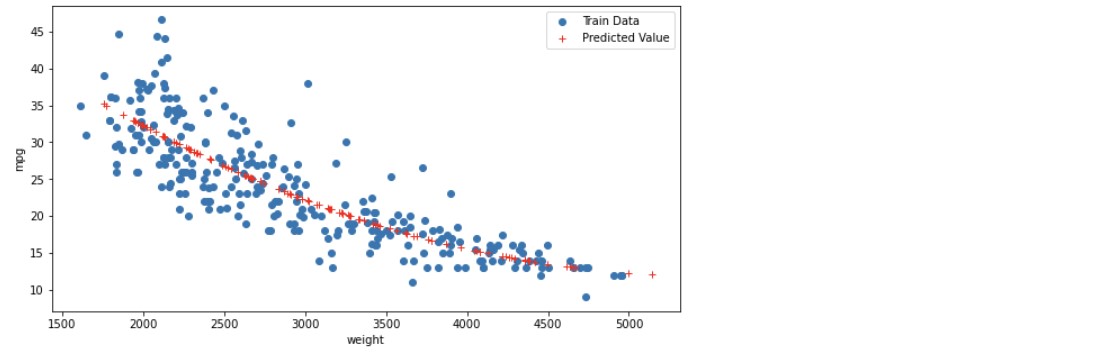
X_poly = poly.fit_transform(X)
y_hat = pr.predict(X_poly)
plt.figure(figsize = (10,5))
ax1 = sns.distplot(y, hist = False, label = "y")
# 실제 y값
ax2 = sns.distplot(y_hat, hist = False, label = "y_hat", ax = ax1)
# 예측한 y값
plt.show()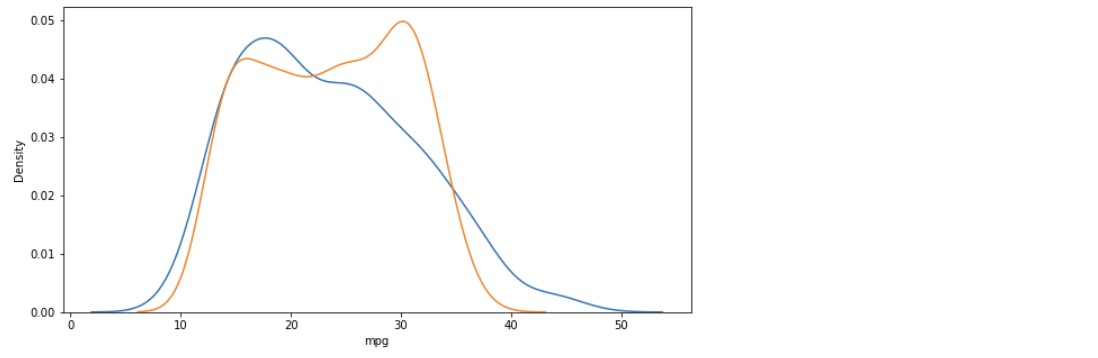
3) 다중회귀분석
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('./auto-mpg.csv', header = None)
df.columns = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration',
'model year', 'origin', 'name']
pd.set_option('display.max_columns', 10)
df['horsepower'].replace('?', np.nan, inplace=True)
df.dropna(subset=['horsepower'], axis = 0, inplace = True)
df['horsepower'] = df['horsepower'].astype('float')
ndf = df[['mpg', 'cylinders', 'horsepower', 'weight']]
X = ndf[['cylinders', 'horsepower', 'weight']]
# 독립변수 cylinders, horsepower, weight
y = ndf['mpg']
# 종속변수 mpg
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 10)
# 전체 데이터를 test : train = 3 : 7로 나누기
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
print('X 변수의 계수 a : ', lr.coef_)
print('\n')
print('상수항 b : ', lr.intercept_)
y_hat = lr.predict(X_test)
plt.figure(figsize = (10,5))
ax1 = sns.distplot(y_test, hist= False, label = "y_test")
# 실제 y값
ax2 = sns.distplot(y_hat, hist=False, label = "y_hat", ax = ax1)
# 예측한 y값
plt.show()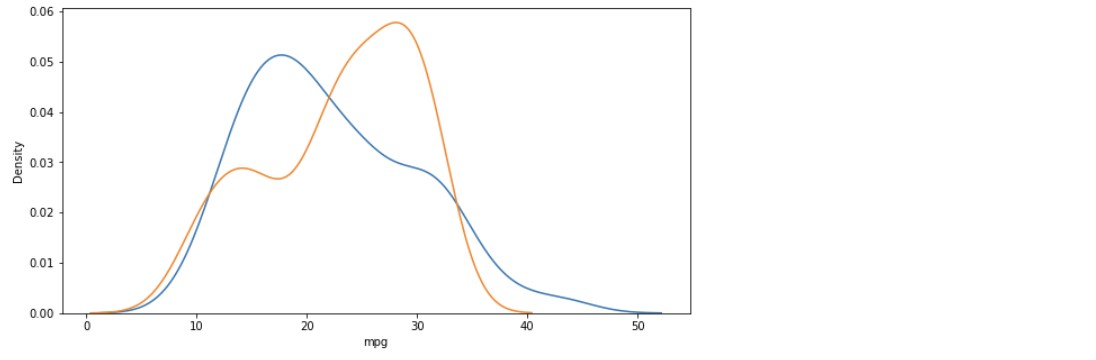
- 단순회귀분석 -> 다항회귀분석 -> 다중회귀분석으로 갈수록 데이터가 어느 한쪽으로 편향되는 경향은 그대로 남아있지만 그래프의 첨도가 약간 누그러짐

따또의 DA 벨로그