
1) k-Means
- 데이터 간의 유사성을 측정하는 기준으로 각 클러스터의 중심까지의 거리를 이용
- 벡터 공간에 위치한 어떤 데이터에 대하여 k개의 클러스터가 주어졌을 때 클러스터의 중심까지 거리가 가장 가까운 클러스터로 해당 데이터 할당
- k값에 따라 모형의 성능이 달라짐
- 일반적으로 k가 클수록 모형의 정확도가 개선되지만 k값이 너무 커지면 분석의 효과가 사라짐
2) 데이터 전처리
import pandas as pd
import matplotlib.pyplot as plt
uci_path = 'https://archive.ics.uci.edu/ml/machine-learning-databases/00292/Wholesale%20customers%20data.csv'
df = pd.read_csv(uci_path, header=0)
X = df.iloc[:,:]
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)
# 정규화3) 모델 학습 및 예측
from sklearn import cluster
kmeans = cluster.KMeans(init = 'k-means++', n_clusters = 5, n_init = 10)
# 5개의 클러스터 생성
kmeans.fit(X)
# 모델 학습
cluster_label = kmeans.labels_
# 모델 예측
df['Cluster'] = cluster_label
df.head()
4) 시각화
df.plot(kind = 'scatter', x ='Grocery', y= 'Frozen', c ='Cluster', cmap ='Set1', colorbar = False, figsize = (10,10))
# x축이 Grocery, y축이 Frozen
# 산점도 방식으로 표현
# colorbar 없이 출력
df.plot(kind = 'scatter', x = 'Milk', y = 'Delicassen', c = 'Cluster', cmap = 'Set1', colorbar = True, figsize = (10,10))
# x축이 Milk, y축이 Delicassen
# 산점도 방식으로 표현
# colorbar 출력
plt.show()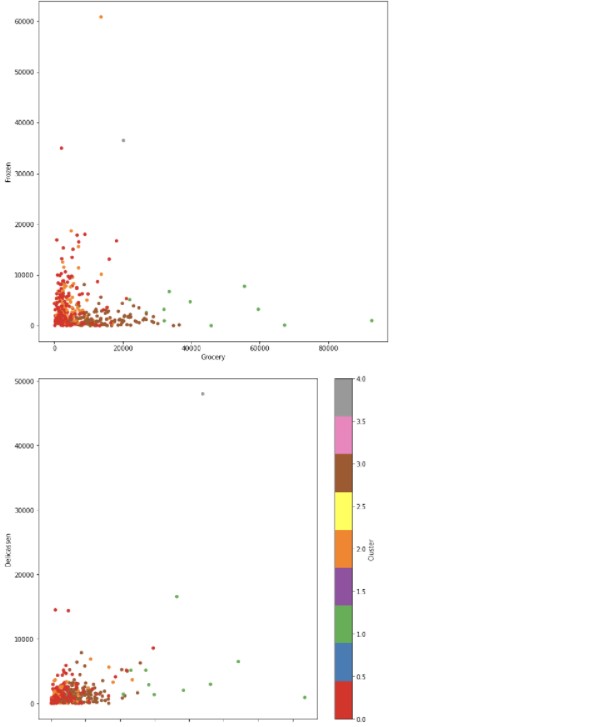

따또의 DA 벨로그