
로그 수집, 시각화 툴로 유명한 오픈소스이고
운영에서는 이미 갖추어진 환경에서 사용해 보았는데
설치부터 실제 키바나까지 데이터가 이동하는 과정을 구축해보고 싶었습니다
각 서버에 설치하는 과정에서 어떤 옵션을 설정해야하는지 정리해볼 생각입니다
로그 수집
우선 Local서버에 있는 로그를 S3에 업로드하고
S3에 로그파일이 올라오게 되면 SQS( Simple Queue Service )에서 이벤트를 보고있다가 로그파일을 Filebeat로 전달해주는 방식으로 구축
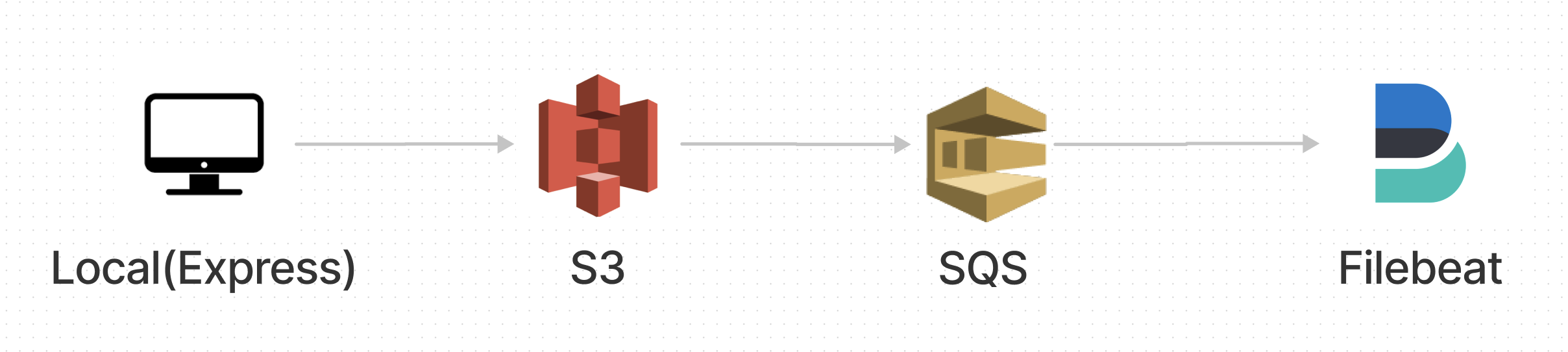
각각의 서비스에 따라 구조는 변경될 수 있겠지만
모든 로그파일은 S3에 저장, 관리하고 Queue서비스에 등록해주면
로그파일을 안정적으로 쌓을수 있지 않을까 싶어 선택했습니다
Filebeat이후 부터는 Kafka, Logstash, Elasticsearch
등등 데이터 수집방향을 잡으면 될 것 같습니다
설치 환경
OS: CentOS7
Java version: 11.0.12
User: root
일단 EC2에서 3개의 서버를 준비했고, S3와 SQS를 이용한 Message Queue 구축은 따로 정리해서 올릴 생각입니다

Elasticsearch 설치
공식문서: https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html
서명키 import
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchelasticsearch.repo 파일 생성
/etc/yum.repos.d/elasticsearch.repo 파일에 아래 내용을 복사해줍니다
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md설치
sudo yum install -y --enablerepo=elasticsearch elasticsearch설정 변경
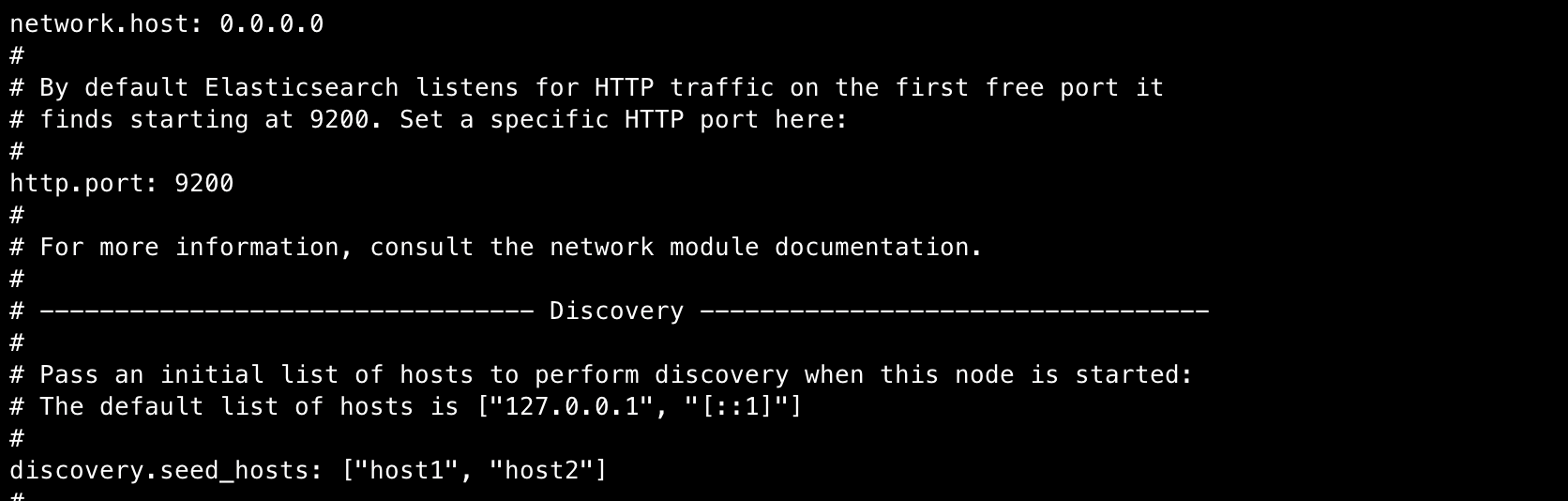
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["host1", "host2"] - 주석제거 network host는 0.0.0.0으로 외부 접속이 모두 가능하게 열어줍니다
( production레벨의 환경에서는 host를 지정하여 열어주시면 됩니다 )
실행
# Elasticsearch 실행
systemctl start elasticsearch
# Elasticsearch 상태 확인
systemctl status elasticsearchElasticsearch가 정상적으로 작동하는지 확인하고 싶다면
- 명령어를 사용하여 9200, 9300이 정상적으로 작동하는지 확인
- curl을 이용하여 정상적으로 응답이 오는지 확인
# 현재 사용중인 port 확인
ss -ntlp
# Elasticsearch 동작 확인
curl --request GET http://localhost:9200
Kibana 설치
Kibana도 마찬가지로 공식문서를 확인하여 설치해주시면 됩니다
Kibana는 Elasticsearch와는 다르게 javascript로 구성되어있고
공식문서대로 설치를 하게되면 Node를 따로 설치하지 않아도 사용가능합니다
공식문서: https://www.elastic.co/guide/en/kibana/current/rpm.html
서명키 import
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchkibana.repo 파일 생성
/etc/yum.repos.d/kibana.repo에 복사해줍니다
[kibana-7.x]
name=Kibana repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md설치
sudo yum install kibana설치된 곳이 궁금하시다면
/usr/share/kibana 여기서 확인 가능하고
설치된 곳을 보게되면 kibana 관련 디렉토리와 node디렉토리가 있는걸 확인할 수 있습니다
현재 공식홈페이지대로 설치했을경우 node는 16.13.0 버전을 사용하고있네요
16버전쓰는걸 보니 업데이트가 빠르네요
아마 LTS버전이 업데이트되면 바로 준비를 하나봅니다
설정 변경
yml파일은 /etc/kibana/kibana.yml파일을 수정해주면 됩니다
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: "http://$ElasticsearchIP:9200"엘라스틱서치와는 다르게 외부 접속허용을 한 이후에 Elasticsearch에서 데이터를 받아와야 하므로 IP, Port를 지정해주세요
실행
# Kibana 실행
systemctl start kibana
# Kibana 상태 확인
systemctl status kibanaKibana도 Elasticsearch와 마찬가지로 상태확인을 해주면 되고,
kibana server is not ready yet이라고 나오는 경우는 잠시 기다렸다 접속을 다시해주면 실행되거나 기다려도 실행이 안되는 경우는 디버깅하시면 되요
Logstash 설치
저는 filebeat와 logstash를 같은 곳에 설치예정이기 떄문에
서명키 import는 따로 안했습니다
공식문서: https://www.elastic.co/guide/en/logstash/7.16/installing-logstash.html
logstash.repo 파일 생성
/etc/yum.repos.d/logstash.repo
[logstash-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md설치
sudo yum install logstash input {
beats {
port => 5044
host => "0.0.0.0"
}
}
output {
elasticsearch {
hosts => $ElasticsearchDomain
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}실행
# Logstash 실행
systemctl start logstash
# Logstash 상태 확인
system status logstashFilebeat 설치
Filebeat와 Logstash설치 방법도 위에 방법과 똑같아서 안적어도 되지 않을까 했는데... 이왕 하는김에 한번에 정리 할게요
공식문서: https://www.elastic.co/guide/en/beats/filebeat/7.16/setup-repositories.html#_yum
서명키 import
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchelasticsearch.repo파일 생성
엘라스틱서치와 같은 인스턴스에서 성치한다면 생략해도 됩니다
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md설치
sudo yum install filebeat설정 변경
/etc/filebeat/filebeat.yml을 수정해주면 됩니다
지금 설정으로는 s3에 저장되어 있는 로그파일을 SQS에서 받아올 것이기 때문에 input값을 설정해주면 됩니다
filebeat.inputs:
- type: s3
queue_url: $SQS_URL
visibility: 300s
credential_profile_name: elastic-beats실행
# filebeat 실행
systemctl start filebeat
# Filebeat 상태 확인
system status filebeat왜 사용하지?
적용을 하다보니 궁금한게 생겼습니다
Filebeat와 Logstash가 하는 역할이 비슷한 것 같기에
Elastic에서 왜 Filebeat를 만들었을까 하는 의문이 생겼습니다
설치를 하고 적용을 하면서도 잘 몰랐습니다
항상 붙어다니기에 당연히 설치하는 것이고,
Logstash에는 필터링이 있기에 필요하다고 생각했는데
이 둘은 성능, 필터링에 있어 가장 큰 차이가 있습니다
Logstash의 성능 문제
성능
Logstash를 실행하려면 JVM 이 필요 하며 고급 필터링이 필요한 경우 메모리 소모가 상당히 컸고, 이를 해결하기 위해 나온 것이 Filebeat입니다
실제로 Production에서 사용한 경험이 없기에 어떨지는 모르겠지만
Filbeat는 로그파일은 전달하고, Logstash에서 필터링을 하여
Elasticsearch에 전달하는 식으로 사용할 것으로 보입니다
더 추가한다면 Logstash의 자원 사용량이 높기 때문에 Filbeat와 Logstash의 중간에 MessageQueue를 넣어
관리해주면 조금 더 안정적으로 운영이 가능하지 않을까 싶습니다
S3, SQS 필요한가?
구축을 해보면서 느낀 점인데
처음에는 Filebeat로 로그를 어떻게 전달하지?라는 생각에
S3로 수집하고, SQS를 이용하여 전달하는 방식을 사용했는데
정말 대규모가 아니라면 S3와 SQS는 필요하지 않을 것 같고
차라리 각각의 API Server에 Filebeat를 설치하여 로그를 전달해도 괜찮을 것 같습니다
로그 수집은?
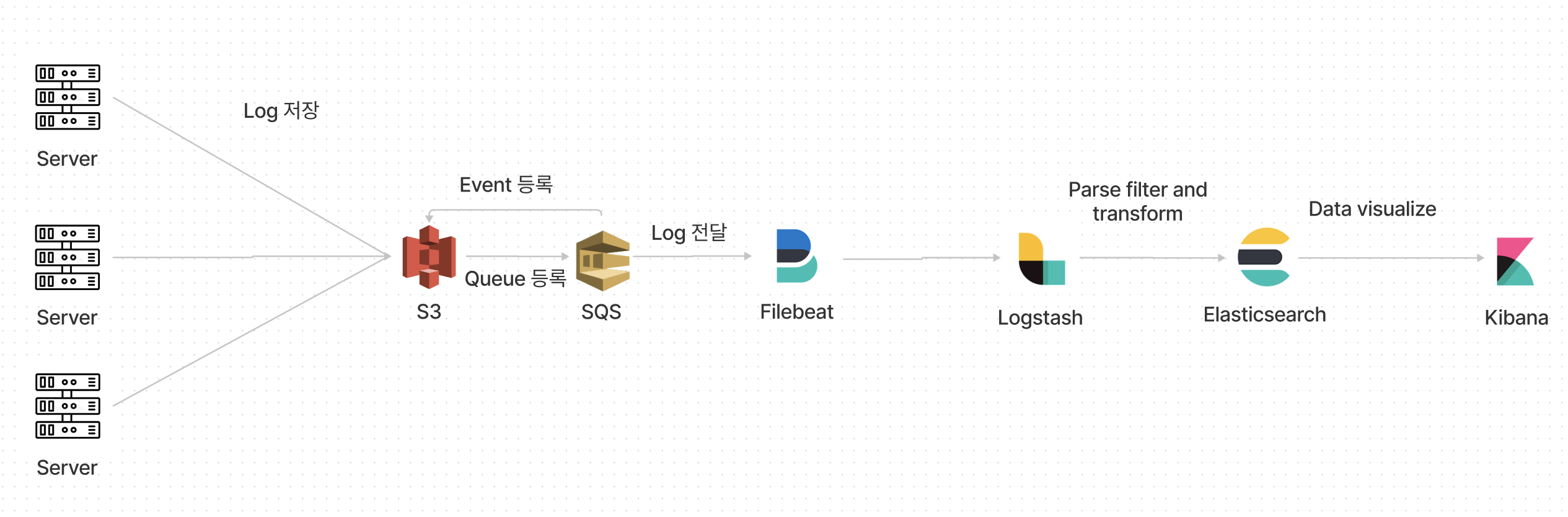
위의 그림처럼 되어있고,
작은 규모에서 로그를 저장한다면 가운데 다 없이
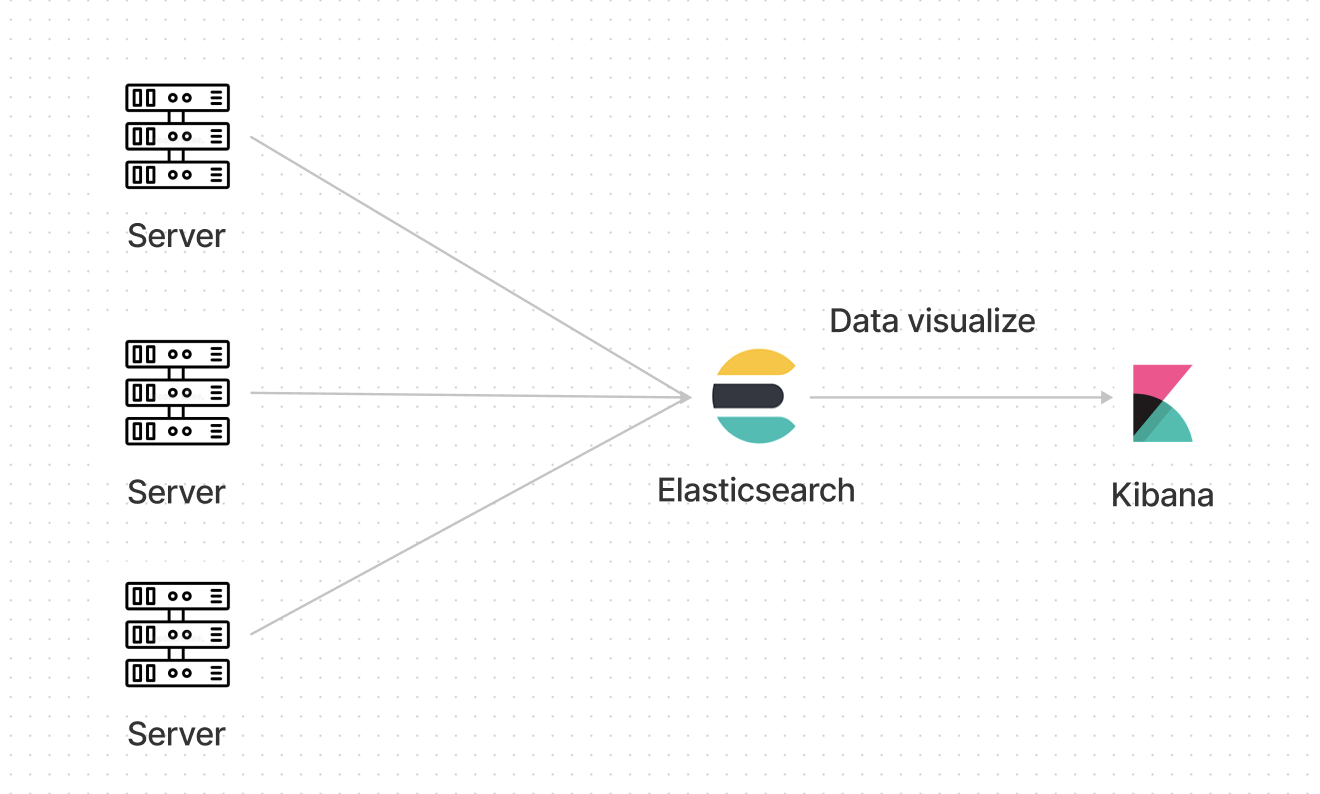
이렇게만 해도 무관할 것 같다
최종적으로 적용해 보고 싶은 아키텍쳐
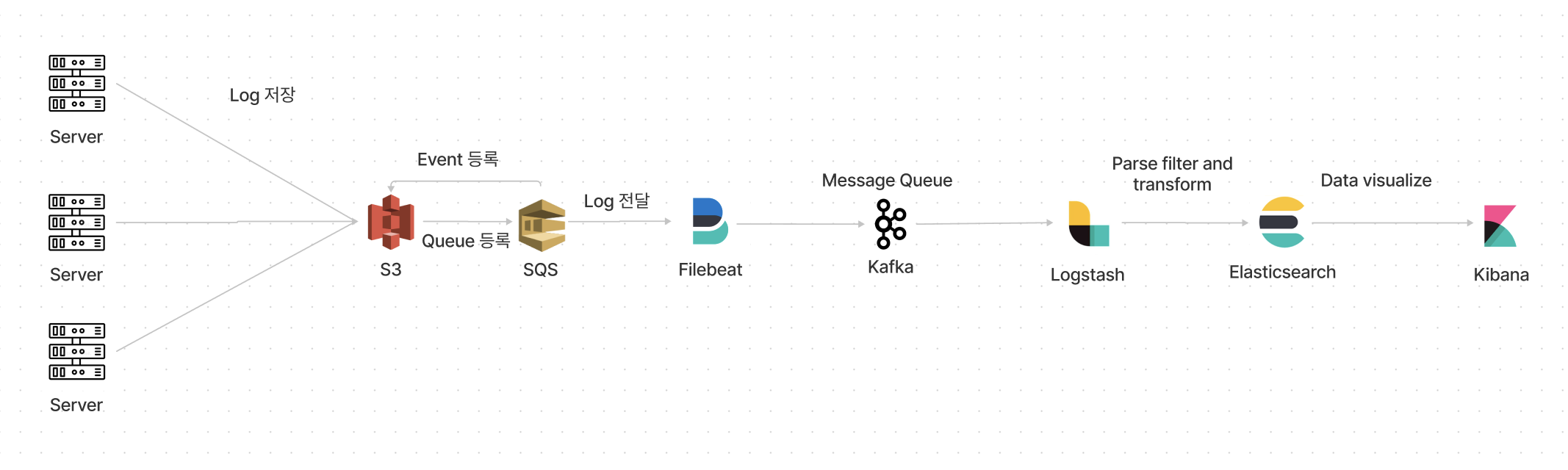
Logstash에서 처리하는 동안 Kafka에 쌓아놓고
처리하는 방식으로 적용해 보고 싶다
위 그림이 아니라면
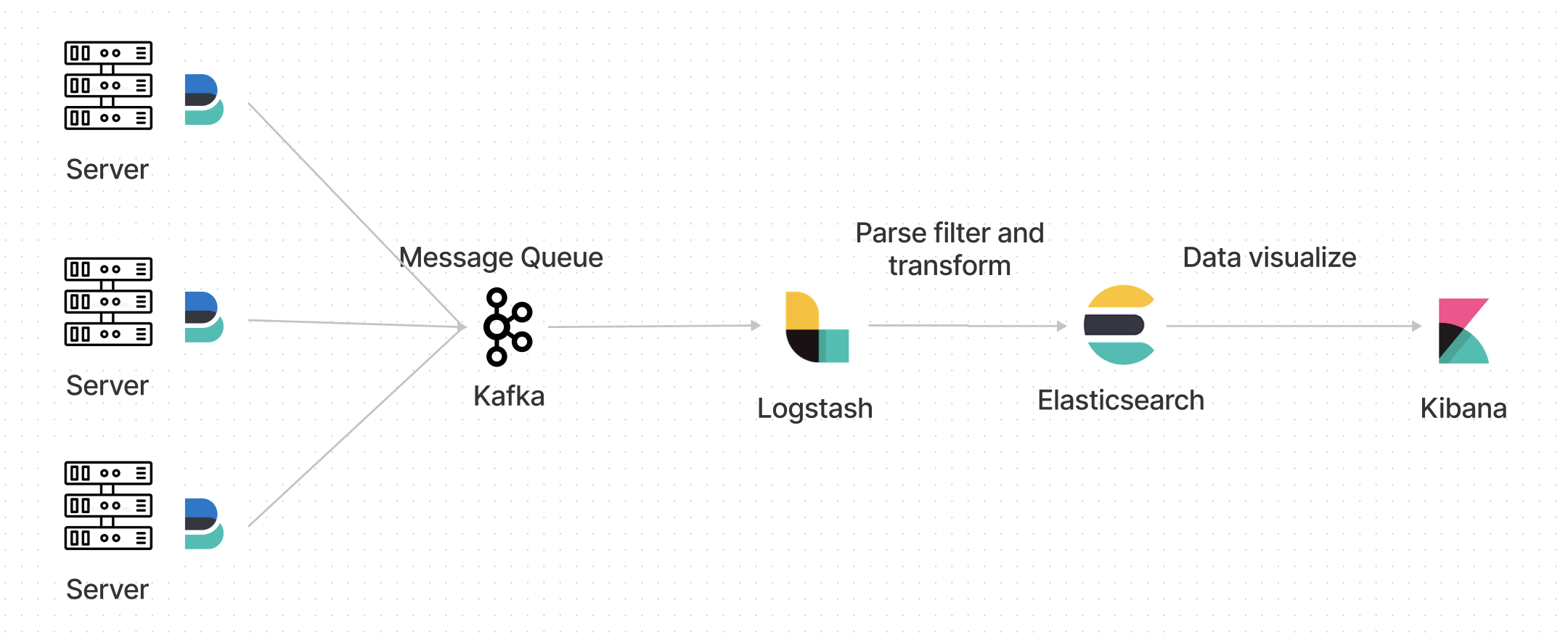
이런식으로 각각의 서버에 Filebeat를 적용해서 전달하는 방식을 사용해 보고싶다
일단 적용전에 각각의 프로그램을 어떻게 써야 효율적인지 부터 공부하고...
개인 프로젝트에 적용해 봐야겠다
