
장고 공부를 하면서 들었던 생각이기도 하고
멘토님이 얘기 해줬던 것 중에 쿼리문을 날리는데
시간이 얼마나 걸리고, 걸린시간이 길면 길수록 DB에 접촉하는 일이 많다는 것이구나
생각했고, 어떻게 개선을 할 수 있을까 생각했다
그리고 궁금하기도 했다
내가 날린 쿼리셋이 어느정도의 효율을 가지고 있고,
어떻게 하면 최적화를 할 수 있을까...
select_related
이건 블로그를 너무 많이 써서 쓸지말지 고민을 좀 했엇다
그래도 이번에 쿼리문을 몇개를 날리는지 확인을 하면서 더 자세히 알게되서 블로그에 기록하고 싶엇다
간단한 예시지만 한눈에 볼 수 있는 예시를 가지고 진행해 보려 한다
우선 데이터는 orm공부를 하면서 자주 사용했던 스타벅스 데이터를 가지고 진행했고,
100개 정도 되는 데이터여서, 데이터를 조금더 만들어서 진행할까 하다가
100개정도여도 눈에 확실하게 보이는 결과가 있어 이걸로 진행했다
Drink 와 Category는 ForeignKey 관계입니다
Drink에 있는 모든 음료의 카테고리이름과 영어이름, 한국어 이름을 가지고 오는 경우다
select_related를 사용하지 않을 경우
drinks = Drink.objects.all()
data = [
{
"korean_name" : drink.korean_name,
"english_name": drink.english_name,
"category" : drink.category.name,
}
for drink in drinks
]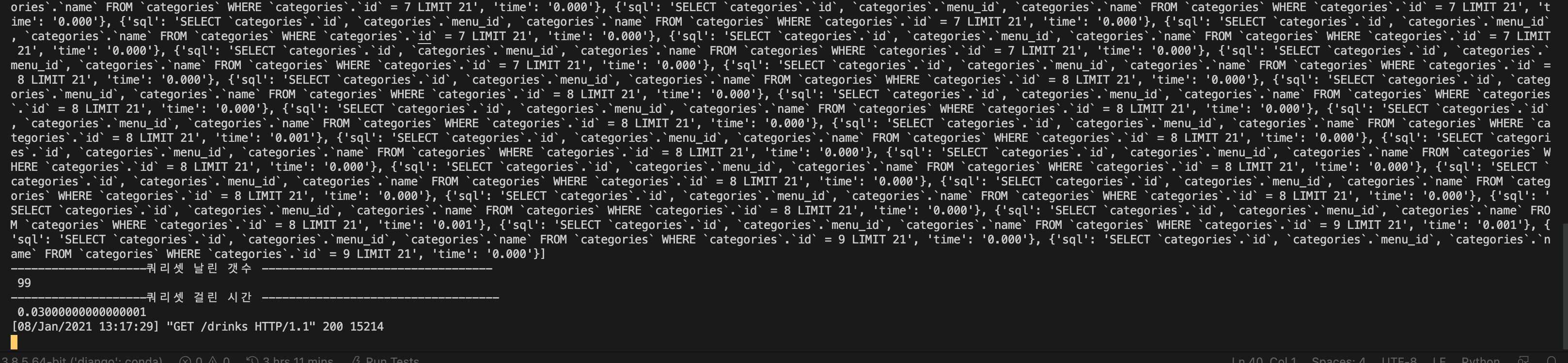
제일 첫번째는 날린 쿼리문들을 모두 불러왔고,
순서대로 쿼리문을 날린 갯수, 걸린 시간을 측정했다
딱봐도 어마어마하게 많은 양의 쿼리문을 날린다
97개정도 되는 양의 데이터인데 카테고리 이름을 가지고 오기 위해서
SELECT `categories`.`id`, `categories`.`menu_id`, `categories`.`name`
FROM `categories`
WHERE `categories`.`id` = 9 LIMIT 21'이렇게나 구성이 되어있는 많은 양의 쿼리문을 날린다
select_related를 사용한 경우
drinks = Drink.objects.all().select_related("category")
data = [
{
"korean_name" : drink.korean_name,
"english_name": drink.english_name,
"category" : drink.category.name,
}
for drink in drinks
]
단 5개의 쿼리문 만으로 음료의 모든 정보를 가지고 왔다
100개밖에 안되는 데이터이지만 시간차이는 15배정도 차이가 났고
날린 쿼리문은 90개 정도가 차이가 난다
이제는 조금 더 확실하게 왜쓰는지에 대해서 알 것 같다
prefetch_related도 마찬가지 였고,
이 외에도 영향을 미치는 요인이 뭐가 있을까 찾아봤다
Lazy Evaluation
이 부분은 성능이 향상되는데에는 크게 영향이 없지만,
알고 넘어가면 좋을 것 같아서 정리했다
장고에서는 데이터를 가지고 올때, 그 데이터가 사용되지 않으면
쿼리문을 DB에 날리지 않는다
많은 쿼리문이 오가면서 앱이 느려지기 때문에 최대한 사용하기 전까지는
DB에 요청을 하지 않는다
drinks = Drink.objects.filter(id__lte = 50)단순하게 필터만 사용해주고, 데이터를 직접적으로 사용하지 않는 경우

분명 메서드를 사용해서 필터를 해주었지만, 직접적으로 쿼리문을 날리지 않은 것을 확인할 수 있다
쿼리셋의 캐시
장고는 쿼리셋을 평가하고, 캐싱한다
장고에서는 DB에 접근을 최소한으로 하기 위해서 캐시를 포함한다
data = [
{
"korean_name" : drink.korean_name,
"english_name": drink.english_name,
"category" : drink.category.name,
}
for drink in Drink.objects.all()
]
datas = [
{
"korean_name" : drink.korean_name,
"english_name": drink.english_name,
"category" : drink.category.name,
"id":drink.id
}
for drink in Drink.objects.all()
]이렇게 두번의 같은 테이블의 데이터를 가지고 올경우를 보면
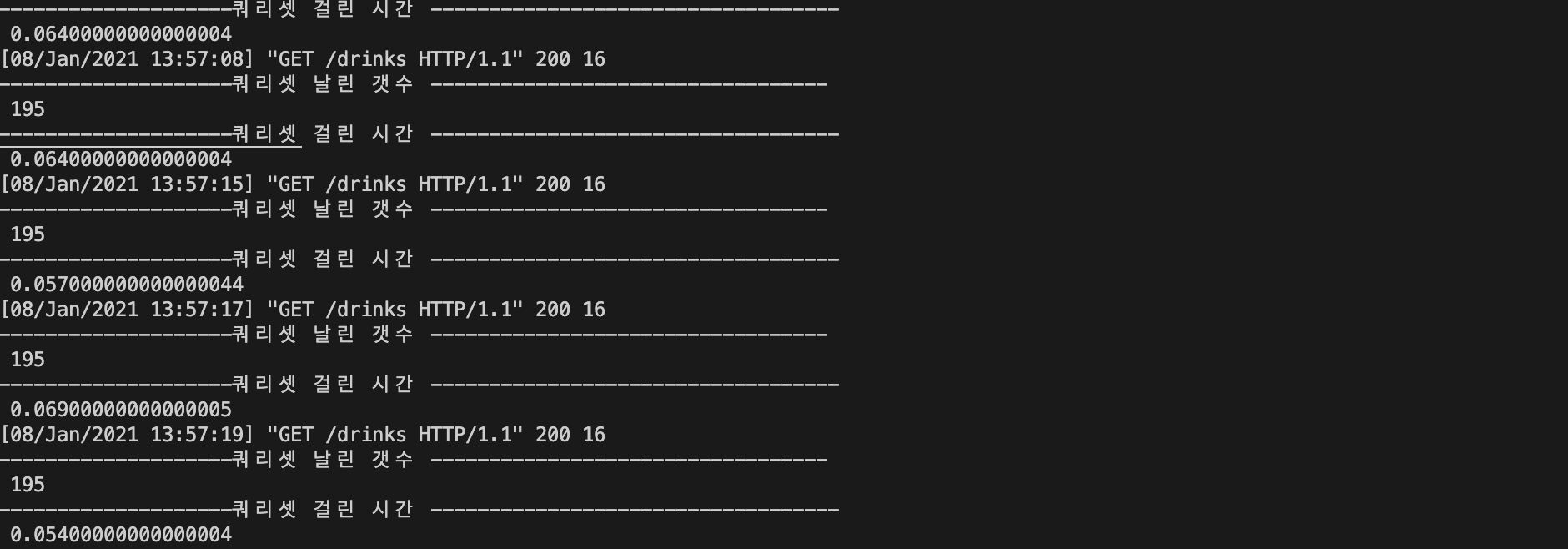
분명 같은 데이터를 가지고 오는데 쿼리문을 날리는 갯수가 2배로 늘어났다
모든데이터를 한번에 가지고 와서 실행할 경우
drinks = Drink.objects.all()
data = [
{
"korean_name" : drink.korean_name,
"english_name": drink.english_name,
"category" : drink.category.name,
}
for drink in drinks
]
datas = [
{
"korean_name" : drink.korean_name,
"english_name": drink.english_name,
"category" : drink.category.name,
"id":drink.id
}
for drink in drinks
]첫번째와는 다르게 모든 음료를 다 가지고 와서 실행한 경우 인데
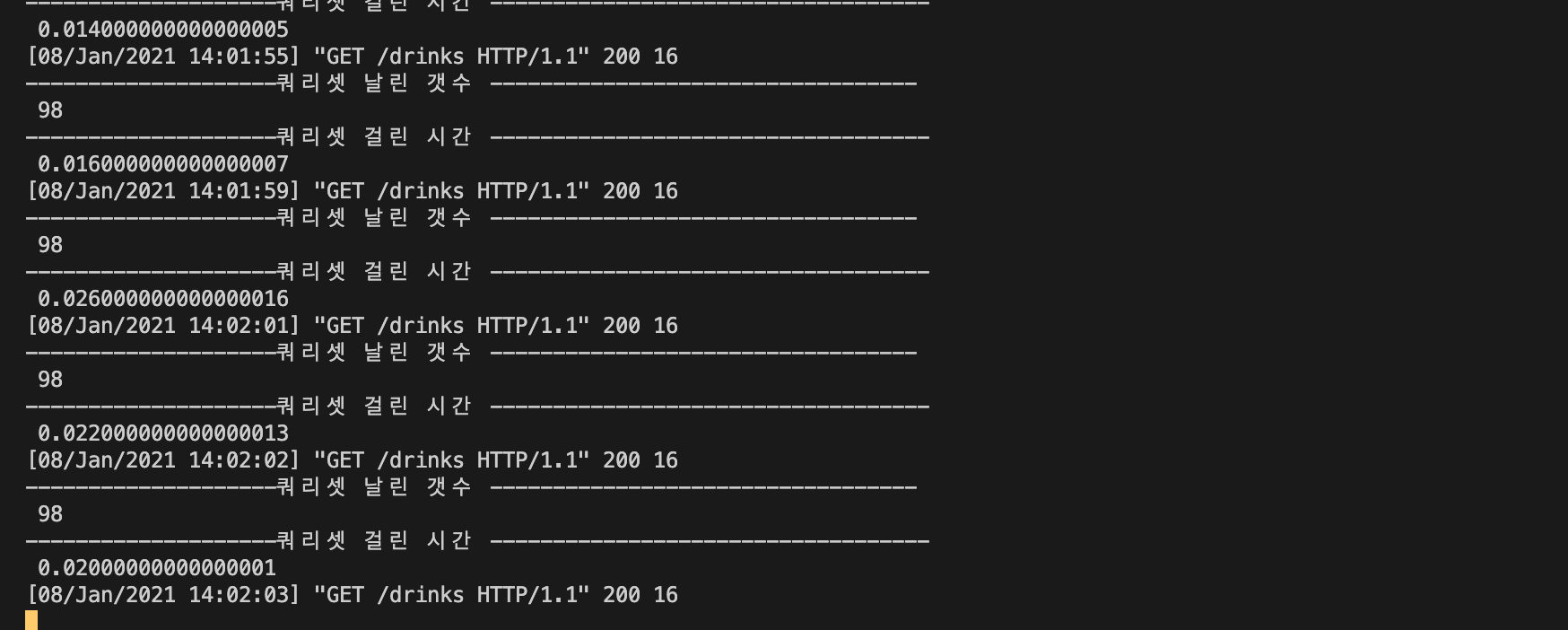
이렇게 장고에서 캐싱한 데이터를 이용해서 시간을 단축할 수 있는게 보인다
장고는 데이터를 평가할 때 캐시를 확인한다
이런 작은 습관들이 앱이 느려지는데 많은 영향을 끼치지 않나 생각한다
아직 많이 있겟지만,,,
조금더 찾아보고 어떻게 하면 내가 작성한 코드가
효율적으로 돌아갈 수 있을까... 생각해볼 시간이 필요한 것같다
여러 기능을 알고 사용하는 것도 좋은데
성능이 엉망이면 그걸 리팩토링하는데도 힘들거고 차근차근 작은 습관부터 고쳐나가야 겟다

오호 그래서 쿼리문을 쓰는군요 ㅎㅎㅎㅎㅎ너무 어렵습니다 ㅎㅎ