제1회 지역치안데이터분석경진대회 공모전 후기
23년도 첫 공모전이자 대학원 입학 전 마지막 공모전으로 경찰대학 치안정책연구소 등에서 주관한 치안 데이터 기반의 공모전 지역치안데이터분석경진대회에 참가하게 되었다. 평소 도메인 지식이 치안이나 교통쪽에 한정되어 있기도 하고, 결국 안전한 사회를 위해 데이터를 활용하고 싶다는 내 평소 가치관과 부합하기 때문에 참가하지 않을 이유가 없었다. 우리 팀은 주어진 신고데이터를 활용해 보이스피싱 범죄를 예측하고자 했는데, 운좋게도 118개 팀중 2위(최우수상) 라는 결과를 얻게 되어 연구소 소속 직원들 앞에서 발표도 하고, 뜻깊은 경험을 할 수 있었다.
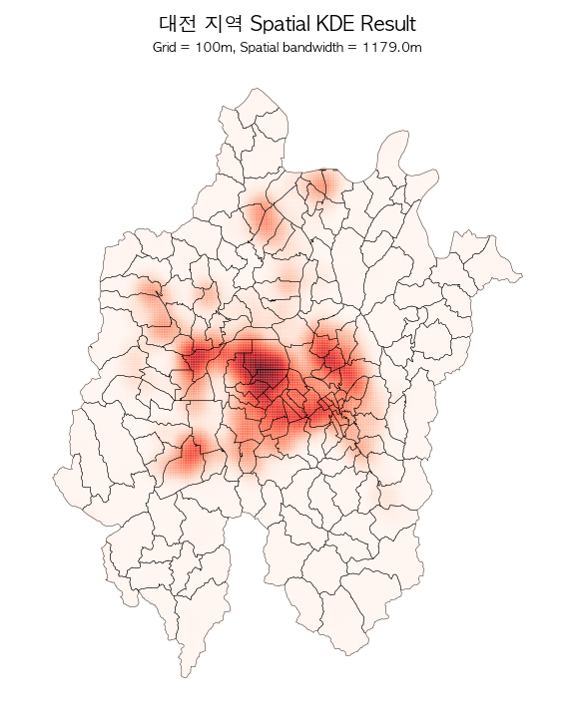
우리 팀의 분석방법은 크게 두 단계로 구성된다. 하나는 밀도분석(density estimation)이고 다른 하나는 회귀모형 설정이다. 우선 보이스피싱 범죄가 발생하는 것을 random하다고 가정할 때, 대상 지역을 격자화한 후(100m square grid) 전체 지역의 확률밀도함수를 격자 단위로 추정하였다.
이때 Spatial Kernel Density Estimation과 Spatiotemporal Kernel Density Estimation 두 가지 방법을 모두 사용했는데, 전체적인 사건 분포를 capture하는 측면에서 spatial kde(아래)가 더 적합하다고 판단하였고, 이를 바탕으로 회귀모형을 구성했다.
회귀모형은 크게 두 가지 방법으로 구성했는데, 하나는 공간회귀모형이고(Spatial Regression) 다른 하나는 머신러닝 회귀모형이다. 우선 공간회귀모형에서는 각 변수들의 Moran's I statistic을 바탕으로 어떤 외생변수에 대해 공간자기상관성이 높은지 파악하여, 기준치 이상의 변수()들에 대해 공간시차(spatial lag)를 설정하는 회귀모형을 구성했다(아래).
이때 Weight matrix 는 k-nearest-neighborhood adjacnet matrix(k=1)을 사용했으며 총 두 가지 변수에 대해 공간시차를 적용했다.
회귀에 사용가능한 머신러닝 모델들을 비교해본 결과, Gradient Boosting Regressor(GBM)가 가장 높은 성능을 보여 bayesian optimization으로 hyperparameter를 튜닝했고, 이를 바탕으로 예측모델을 생성하였다.
또한, 재현율(Recall) 측면에서 다음 그림과 같이 Recall-Grid Ratio plot을 정의해 일정 수준 재현율 도달에 필요한 격자 비율을 plotting했다.
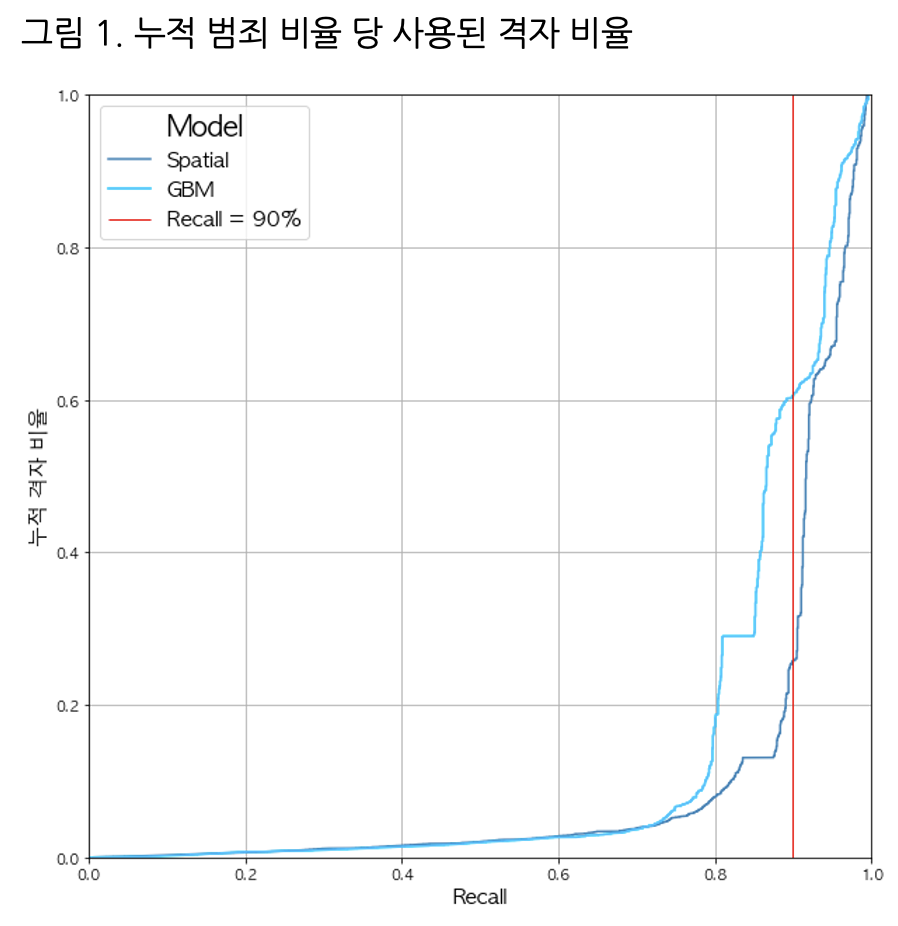
이로부터 Recall 90% 가량을 얻기 위해 Spatial Regression Model은 전체지역의 약 25%로 예측가능한 반면,GBM Model은 전체지역의 60% 가량 및 누적 추정밀도 1.0 가량을 사용해야 예측가능했다. 즉, 실제 모델 Fitting과정에서 R-squared 값은 GBM 모델이 더 높음에도 불구, 재현율 측면에서 보면 효율적인 예측 모델은 공간회귀모형이라는 것을 알 수 있었다.
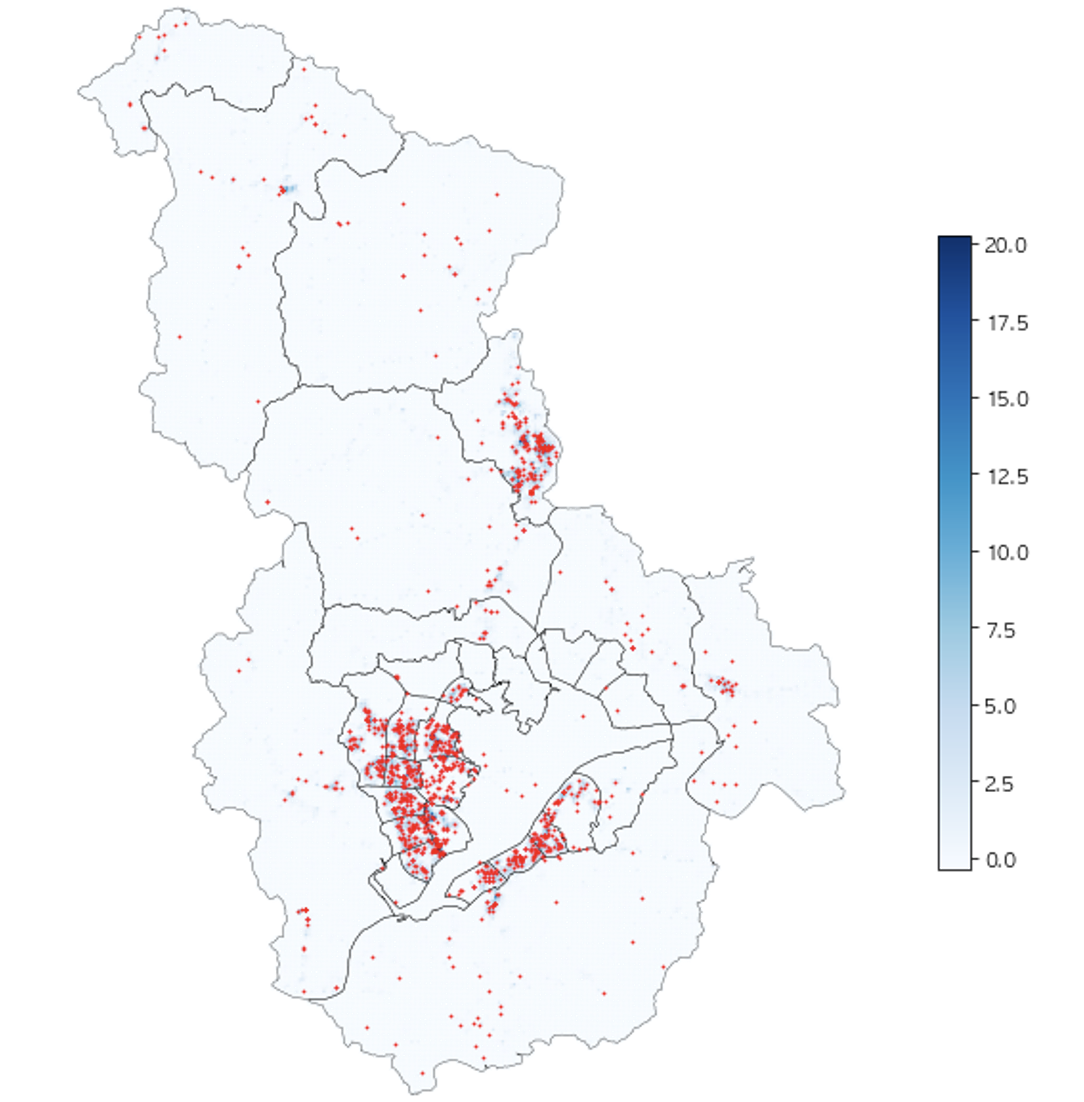
실제 신고데이터와 비교해본 결과는 다음과 같았다.